Gerir registos de um cluster do HDInsight
Um cluster HDInsight produz vários arquivos de log. Por exemplo, o Apache Hadoop e serviços relacionados, como o Apache Spark, produzem logs de execução de tarefas detalhados. O gerenciamento de arquivos de log faz parte da manutenção de um cluster HDInsight íntegro. Também pode haver requisitos normativos para o arquivamento de logs. Devido ao número e ao tamanho dos arquivos de log, a otimização do armazenamento e do arquivamento de logs ajuda no gerenciamento de custos de serviço.
O gerenciamento de logs de cluster HDInsight inclui a retenção de informações sobre todos os aspetos do ambiente de cluster. Essas informações incluem todos os logs de Serviço do Azure associados, configuração de cluster, informações de execução de trabalho, quaisquer estados de erro e outros dados, conforme necessário.
As etapas típicas no gerenciamento de logs do HDInsight são:
- Etapa 1: Determinar políticas de retenção de logs
- Etapa 2: Gerenciar logs de configuração de versões de serviço de cluster
- Etapa 3: Gerenciar arquivos de log de execução de tarefas de cluster
- Etapa 4: Prever os tamanhos e custos de armazenamento do volume de log
- Etapa 5: Determinar políticas e processos de arquivamento de logs
Etapa 1: Determinar políticas de retenção de logs
A primeira etapa na criação de uma estratégia de gerenciamento de log de cluster HDInsight é coletar informações sobre cenários de negócios e requisitos de armazenamento do histórico de execução de tarefas.
Detalhes do cluster
Os detalhes do cluster a seguir são úteis para ajudar a coletar informações em sua estratégia de gerenciamento de logs. Reúna essas informações de todos os clusters HDInsight que você criou em uma conta específica do Azure.
- Nome do cluster
- Região de cluster e zona de disponibilidade do Azure
- Estado do cluster, incluindo detalhes da última alteração de estado
- Tipo e número de instâncias do HDInsight especificadas para os nós principal, principal e de tarefa
Você pode obter a maioria dessas informações de nível superior usando o portal do Azure. Como alternativa, você pode usar a CLI do Azure para obter informações sobre o(s) seu(s) cluster(s) HDInsight:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Você também pode usar o PowerShell para exibir essas informações. Para obter mais informações, consulte Apache Manage Hadoop clusters in HDInsight using Azure PowerShell.
Compreender as cargas de trabalho em execução em seus clusters
É importante entender os tipos de carga de trabalho em execução no(s) cluster(s) do HDInsight para projetar estratégias de log apropriadas para cada tipo.
- As cargas de trabalho são experimentais (como desenvolvimento ou teste) ou de qualidade de produção?
- Com que frequência as cargas de trabalho de qualidade de produção normalmente são executadas?
- Alguma das cargas de trabalho consome muitos recursos e/ou é de longa duração?
- Alguma das cargas de trabalho usa um conjunto complexo de serviços Hadoop para o qual vários tipos de logs são produzidos?
- Alguma das cargas de trabalho tem requisitos de linhagem de execução regulatória associados?
Exemplo de padrões e práticas de retenção de logs
Considere manter o rastreamento de linhagem de dados adicionando um identificador a cada entrada de log ou por meio de outras técnicas. Isso permite rastrear a fonte original dos dados e da operação e acompanhar os dados através de cada estágio para entender sua consistência e validade.
Considere como você pode coletar logs do cluster ou de mais de um cluster e agrupá-los para fins como auditoria, monitoramento, planejamento e alerta. Você pode usar uma solução personalizada para acessar e baixar os arquivos de log regularmente e combiná-los e analisá-los para fornecer uma exibição de painel. Você também pode adicionar outros recursos para alertar sobre segurança ou deteção de falhas. Você pode criar esses utilitários usando o PowerShell, os SDKs do HDInsight ou o código que acessa o modelo de implantação clássico do Azure.
Considere se uma solução ou serviço de monitoramento seria um benefício útil. O Microsoft System Center fornece um pacote de gerenciamento do HDInsight. Você também pode usar ferramentas de terceiros como Apache Chukwa e Ganglia para coletar e centralizar logs. Muitas empresas oferecem serviços para monitorar soluções de big data baseadas em Hadoop, por exemplo:
Centerity, Compuware APM, Sematext SPM e Zettaset Orchestrator.
Etapa 2: gerenciar versões de serviço de cluster e exibir logs
Um cluster HDInsight típico usa vários serviços e pacotes de software de código aberto (como Apache HBase, Apache Spark e assim por diante). Para algumas cargas de trabalho, como bioinformática, pode ser necessário manter o histórico de logs de configuração de serviço, além dos logs de execução de tarefas.
Exibir definições de configuração de cluster com a interface do usuário do Ambari
O Apache Ambari simplifica o gerenciamento, a configuração e o monitoramento de um cluster HDInsight fornecendo uma interface do usuário da Web e uma API REST. O Ambari está incluído em clusters HDInsight baseados em Linux. Selecione o painel Painel de Cluster na página HDInsight do portal do Azure para abrir a página de link Painéis de Cluster. Em seguida, selecione o painel do painel do cluster HDInsight para abrir a interface do usuário do Ambari. Ser-lhe-ão solicitadas as credenciais de início de sessão do cluster.
Para abrir uma lista de modos de exibição de serviço, selecione o painel Modos de Exibição Ambari na página do portal do Azure para HDInsight. Essa lista varia, dependendo de quais bibliotecas você instalou. Por exemplo, você pode ver o Gerenciador de filas do YARN, o modo de exibição do Hive e o modo de exibição Tez. Selecione qualquer link de serviço para ver as informações de configuração e serviço. A página Ambari UI Stack and Version fornece informações sobre a configuração dos serviços de cluster e o histórico de versões do serviço. Para navegar até esta seção da interface do usuário do Ambari, selecione o menu Admin e, em seguida, Pilhas e versões. Selecione a guia Versões para ver as informações de versão do serviço.
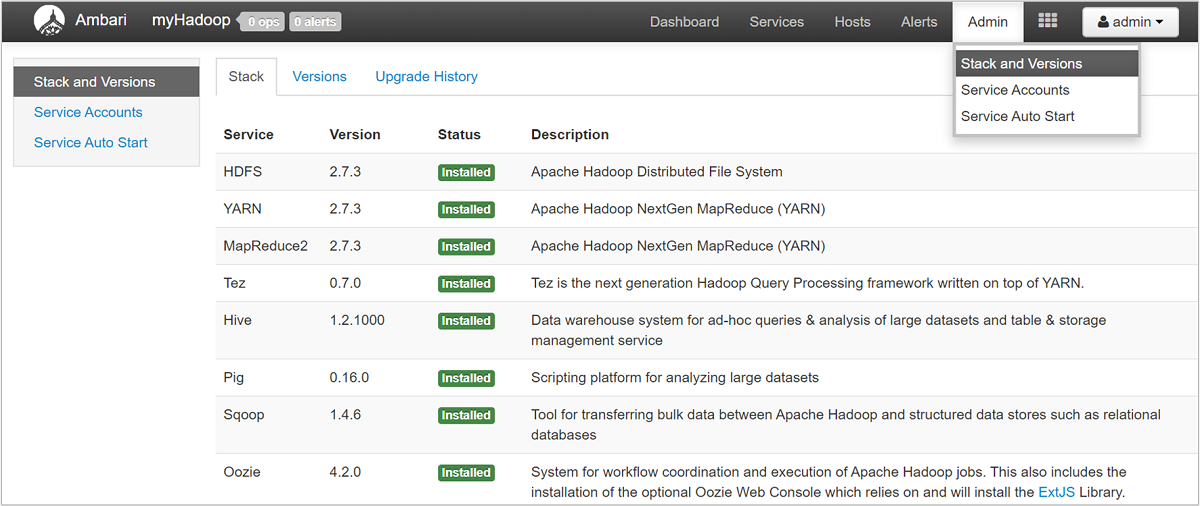
Usando a interface do usuário do Ambari, você pode baixar a configuração para qualquer (ou todos) os serviços em execução em um host (ou nó) específico no cluster. Selecione o menu Hosts e, em seguida, o link para o host de interesse. Na página desse host, selecione o botão Ações do Host e faça Download das Configurações do Cliente.
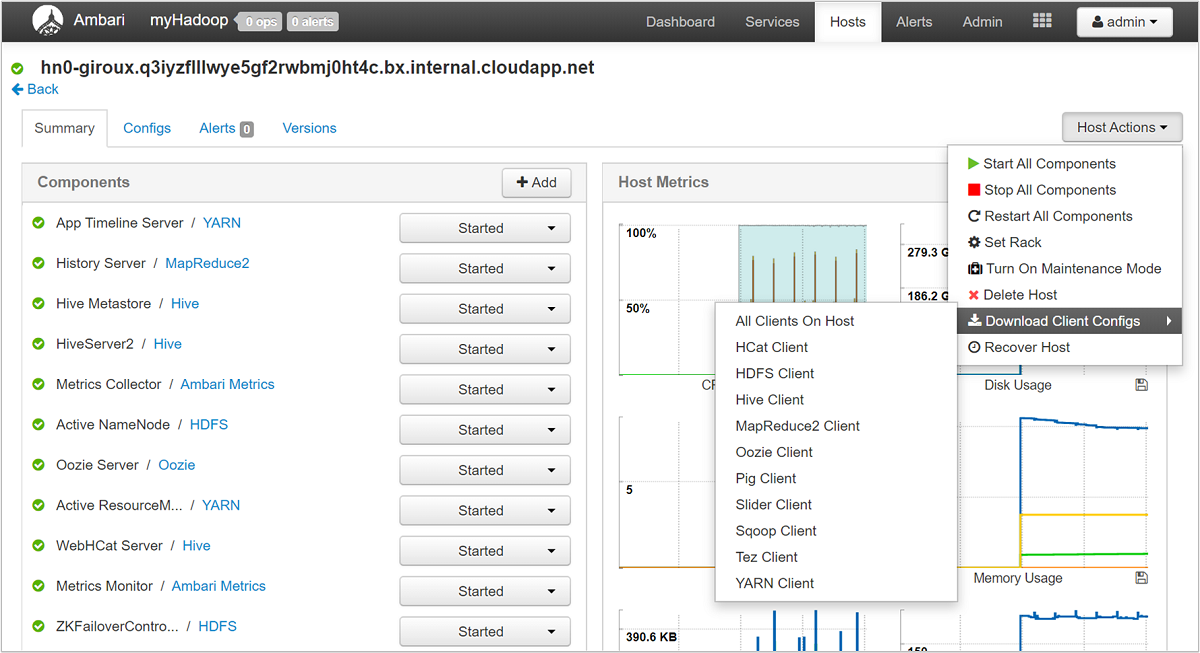
Exibir os logs de ação de script
As ações de script do HDInsight executam scripts em um cluster, manualmente ou quando especificado. Por exemplo, as ações de script podem ser usadas para instalar outro software no cluster ou para alterar as definições de configuração dos valores padrão. Os logs de ação de script podem fornecer informações sobre erros que ocorreram durante a instalação do cluster e também alterações de definições de configuração que podem afetar o desempenho e a disponibilidade do cluster. Para ver o status de uma ação de script, selecione o botão ops na interface do usuário do Ambari ou acesse os logs de status na conta de armazenamento padrão. Os logs de armazenamento estão disponíveis em /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Ver registos de estado de alertas Ambari
O Apache Ambari grava alterações de status de alerta no ambari-alerts.log. O caminho completo é /var/log/ambari-server/ambari-alerts.log. Para habilitar a depuração para o log, altere uma propriedade em Alterar e, em /etc/ambari-server/conf/log4j.properties. seguida, a entrada em # Log alert state changes de:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Etapa 3: Gerenciar os arquivos de log de execução de tarefas de cluster
A próxima etapa é revisar os arquivos de log de execução de trabalho para os vários serviços. Os serviços podem incluir Apache HBase, Apache Spark e muitos outros. Um cluster Hadoop produz um grande número de logs detalhados, portanto, determinar quais logs são úteis (e quais não são) pode ser demorado. Compreender o sistema de registro em log é importante para o gerenciamento direcionado de arquivos de log. A imagem a seguir é um arquivo de log de exemplo.
Acessar os arquivos de log do Hadoop
O HDInsight armazena seus arquivos de log no sistema de arquivos de cluster e no Armazenamento do Azure. Você pode examinar arquivos de log no cluster abrindo uma conexão SSH com o cluster e navegando no sistema de arquivos ou usando o portal Hadoop YARN Status no servidor de nó principal remoto. Você pode examinar os arquivos de log no Armazenamento do Azure usando qualquer uma das ferramentas que podem acessar e baixar dados do Armazenamento do Azure. Exemplos são AzCopy, CloudXplorer e o Visual Studio Server Explorer. Você também pode usar o PowerShell e as bibliotecas do Cliente de Armazenamento do Azure, ou os SDKs do Azure .NET, para acessar dados no armazenamento de blobs do Azure.
O Hadoop executa o trabalho dos trabalhos como tentativas de tarefas em vários nós no cluster. O HDInsight pode iniciar tentativas de tarefas especulativas, encerrando quaisquer outras tentativas de tarefas que não sejam concluídas primeiro. Isso gera uma atividade significativa que é registrada nos arquivos de log do controlador, stderr e syslog em tempo real. Além disso, várias tentativas de tarefas são executadas simultaneamente, mas um arquivo de log só pode exibir resultados linearmente.
Logs do HDInsight gravados no armazenamento de Blob do Azure
Os clusters HDInsight são configurados para gravar logs de tarefas em uma conta de armazenamento de Blob do Azure para qualquer trabalho enviado usando os cmdlets do Azure PowerShell ou as APIs de envio de trabalho do .NET. Se você enviar trabalhos por meio de SSH para o cluster, as informações de log de execução serão armazenadas nas Tabelas do Azure, conforme discutido na seção anterior.
Além dos principais arquivos de log gerados pelo HDInsight, serviços instalados como o YARN também geram arquivos de log de execução de tarefas. O número e o tipo de arquivos de log dependem dos serviços instalados. Os serviços comuns são Apache HBase, Apache Spark e assim por diante. Investigue os arquivos de execução do log de tarefas de cada serviço para entender os arquivos de log gerais disponíveis no cluster. Cada serviço tem seus próprios métodos exclusivos de registro em log e locais para armazenar arquivos de log. Como exemplo, os detalhes para acessar os arquivos de log de serviço mais comuns (do YARN) são discutidos na seção a seguir.
Logs do HDInsight gerados pelo YARN
O YARN agrega logs em todos os contêineres em um nó de trabalho e armazena esses logs como um arquivo de log agregado por nó de trabalho. Esse log é armazenado no sistema de arquivos padrão após a conclusão de um aplicativo. Seu aplicativo pode usar centenas ou milhares de contêineres, mas os logs de todos os contêineres executados em um único nó de trabalho são sempre agregados a um único arquivo. Há apenas um log por nó de trabalho usado pelo seu aplicativo. A agregação de registos está ativada por predefinição nos clusters da versão 3.0 ou superior do HDInsight. Os registos agregados estão localizados no armazenamento predefinido do cluster.
/app-logs/<user>/logs/<applicationId>
Os logs agregados não são diretamente legíveis, pois são escritos em um TFile formato binário indexado por contêiner. Use os logs do YARN ResourceManager ou as ferramentas da CLI para exibir esses logs como texto sem formatação para aplicativos ou contêineres de interesse.
Ferramentas YARN CLI
Para usar as ferramentas da CLI do YARN, você deve primeiro se conectar ao cluster HDInsight usando SSH. Especifique as <applicationId>informações , <user-who-started-the-application>, <containerId>e <worker-node-address> ao executar esses comandos. Você pode exibir os logs como texto sem formatação com um dos seguintes comandos:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Interface do usuário do Gerenciador de Recursos do YARN
A interface do usuário do YARN Resource Manager é executada no nó principal do cluster e é acessada por meio da interface do usuário da Web do Ambari. Use as seguintes etapas para exibir os logs do YARN:
- Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net. Substitua CLUSTERNAME pelo nome do cluster do HDInsight. - Na lista de serviços à esquerda, selecione YARN.
- Na lista suspensa Links Rápidos, selecione um dos nós principais do cluster e selecione Logs do Gerenciador de Recursos. É apresentada uma lista de links para logs do YARN.
Etapa 4: Prever os tamanhos e custos de armazenamento do volume de log
Depois de concluir as etapas anteriores, você entenderá os tipos e volumes de arquivos de log que o(s) cluster(s) do HDInsight estão produzindo.
Em seguida, analise o volume de dados de log em locais de armazenamento de log de chaves durante um período de tempo. Por exemplo, você pode analisar o volume e o crescimento em períodos de 30-60-90 dias. Registe estas informações numa folha de cálculo ou utilize outras ferramentas como o Visual Studio, o Explorador de Armazenamento do Azure ou o Power Query para Excel. ```
Agora você tem informações suficientes para criar uma estratégia de gerenciamento de logs para os logs de chave. Use sua planilha (ou ferramenta de escolha) para prever o crescimento do tamanho do log e os custos do serviço do Azure de armazenamento de logs no futuro. Considere também quaisquer requisitos de retenção de logs para o conjunto de logs que você está examinando. Agora você pode prever novamente os custos futuros de armazenamento de log, depois de determinar quais arquivos de log podem ser excluídos (se houver) e quais logs devem ser retidos e arquivados no Armazenamento do Azure mais barato.
Etapa 5: Determinar políticas e processos de arquivamento de logs
Depois de determinar quais arquivos de log podem ser excluídos, você pode ajustar os parâmetros de log em muitos serviços Hadoop para excluir automaticamente os arquivos de log após um período de tempo especificado.
Para determinados arquivos de log, você pode usar uma abordagem de arquivamento de arquivos de log de preço mais baixo. Para logs de atividade do Azure Resource Manager, você pode explorar essa abordagem usando o portal do Azure. Configure o arquivamento dos logs do Gerenciador de Recursos selecionando o link Log de Atividades no portal do Azure para sua instância do HDInsight. Na parte superior da página de pesquisa Registro de atividades, selecione o item de menu Exportar para abrir o painel Exportar registro de atividades. Preencha a assinatura, a região, se deseja exportar para uma conta de armazenamento e quantos dias deve reter os logs. Nesse mesmo painel, você também pode indicar se deseja exportar para um hub de eventos.
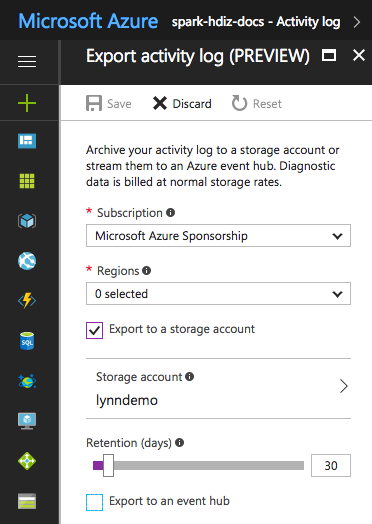
Como alternativa, você pode criar scripts de arquivamento de logs com o PowerShell.
Aceder a métricas de Armazenamento do Azure
O Armazenamento do Azure pode ser configurado para registrar operações de armazenamento e acesso. Você pode usar esses logs detalhados para monitoramento e planejamento de capacidade e para auditar solicitações de armazenamento. As informações registradas incluem detalhes de latência, permitindo que você monitore e ajuste o desempenho de suas soluções. Você pode usar o SDK do .NET para Hadoop para examinar os arquivos de log gerados para o Armazenamento do Azure que contém os dados de um cluster HDInsight.
Controle o tamanho e o número de índices de backup para arquivos de log antigos
Para controlar o tamanho e o número de arquivos de log retidos, defina as seguintes propriedades do RollingFileAppender:
maxFileSizeé o tamanho crítico do arquivo, que o arquivo é rolado. O valor padrão é 10 MB.maxBackupIndexEspecifica o número de arquivos de backup a serem criados, padrão 1.
Outras técnicas de gerenciamento de logs
Para evitar ficar sem espaço em disco, você pode usar algumas ferramentas do sistema operacional, como logrotate , para gerenciar o processamento de arquivos de log. Você pode configurar logrotate para ser executado diariamente, compactando arquivos de log e removendo os antigos. Sua abordagem depende de seus requisitos, como por quanto tempo manter os arquivos de log nos nós locais.
Você também pode verificar se o log de depuração está habilitado para um ou mais serviços, o que aumenta consideravelmente o tamanho do log de saída.
Para coletar os logs de todos os nós para um local central, você pode criar um fluxo de dados, como ingerir todas as entradas de log no Solr.