Integrar o Apache Spark e o Apache Hive no Hive Warehouse Connector no Azure HDInsight
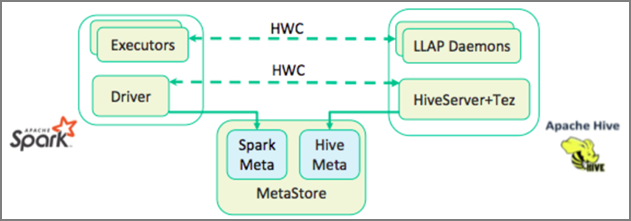
O Apache Hive Warehouse Connector (HWC) é uma biblioteca que permite trabalhar mais facilmente com o Apache Spark e o Apache Hive. Ele suporta tarefas como mover dados entre tabelas Spark DataFrames e Hive. Além disso, direcionando os dados de streaming do Spark para tabelas do Hive. O Hive Warehouse Connector funciona como uma ponte entre o Spark e o Hive. Ele também suporta Scala, Java e Python como linguagens de programação para desenvolvimento.
O Hive Warehouse Connector permite que você aproveite os recursos exclusivos do Hive e do Spark para criar aplicativos poderosos de big data.
O Apache Hive oferece suporte para transações de banco de dados que são atômicas, consistentes, isoladas e duráveis (ACID). Para obter mais informações sobre ACID e transações no Hive, consulte Transações do Hive. O Hive também oferece controles de segurança detalhados através do Apache Ranger e do Processamento Analítico de Baixa Latência (LLAP) não disponível no Apache Spark.
O Apache Spark tem uma API de Streaming Estruturado que oferece recursos de streaming não disponíveis no Apache Hive. A partir do HDInsight 4.0, o Apache Spark 2.3.1 & acima e o Apache Hive 3.1.0 têm catálogos de metastore separados, o que dificulta a interoperabilidade.
O Hive Warehouse Connector (HWC) facilita o uso do Spark e do Hive juntos. A biblioteca HWC carrega dados de daemons LLAP para executores do Spark em paralelo. Esse processo o torna mais eficiente e adaptável do que uma conexão JDBC padrão do Spark ao Hive. Isso traz dois modos de execução diferentes para HWC:
- Modo JDBC do Hive via HiveServer2
- Modo LLAP do Hive usando daemons LLAP [Recomendado]
Por padrão, o HWC é configurado para usar daemons LLAP do Hive. Para executar consultas do Hive (leitura e gravação) usando os modos acima com suas respetivas APIs, consulte APIs HWC.
Algumas das operações suportadas pelo Hive Warehouse Connector são:
- Descrição de uma tabela
- Criando uma tabela para dados formatados em ORC
- Selecionando dados do Hive e recuperando um DataFrame
- Gravando um DataFrame no Hive em lote
- Executando uma instrução de atualização do Hive
- Ler dados da tabela do Hive, transformá-los no Spark e gravá-los em uma nova tabela do Hive
- Gravando um fluxo DataFrame ou Spark no Hive usando o HiveStreaming
Configuração do Hive Warehouse Connector
Importante
- A instância do HiveServer2 Interactive instalada nos clusters do Spark 2.4 Enterprise Security Package não é suportada para uso com o Hive Warehouse Connector. Em vez disso, você deve configurar um cluster HiveServer2 Interactive separado para hospedar suas cargas de trabalho HiveServer2 Interactive. Não há suporte para uma configuração do Hive Warehouse Connector que utilize um único cluster do Spark 2.4.
- A biblioteca HWC (Hive Warehouse Connector) não é suportada para uso com clusters de consulta interativos onde o recurso WLM (Gerenciamento de Carga de Trabalho) está habilitado.
Em um cenário em que você só tem cargas de trabalho do Spark e deseja usar a Biblioteca HWC, verifique se o cluster de Consulta Interativa não tem o recurso Gerenciamento de Carga de Trabalho habilitado (hive.server2.tez.interactive.queuea configuração não está definida nas configurações do Hive).
Para um cenário em que existam cargas de trabalho nativas do Spark (HWC) e LLAP, você precisa criar dois clusters de consulta interativos separados com banco de dados de metastore compartilhado. Um cluster para cargas de trabalho LLAP nativas onde o recurso WLM pode ser habilitado com base na necessidade e outro cluster para carga de trabalho somente HWC onde o recurso WLM não deve ser configurado. É importante observar que você pode exibir os planos de recursos do WLM de ambos os clusters, mesmo que ele esteja habilitado em apenas um cluster. Não faça alterações nos planos de recursos no cluster em que o recurso WLM está desabilitado, pois isso pode afetar a funcionalidade WLM em outro cluster. - Embora o Spark suporte a linguagem de computação R para simplificar sua análise de dados, a biblioteca Hive Warehouse Connector (HWC) não é suportada para ser usada com R. Para executar cargas de trabalho HWC, você pode executar consultas do Spark para o Hive usando a API HiveWarehouseSession no estilo JDBC que suporta apenas Scala, Java e Python.
- A execução de consultas (leitura e gravação) por meio do HiveServer2 via modo JDBC não é suportada para tipos de dados complexos, como tipos Arrays/Struct/Map.
- O HWC suporta a escrita apenas em formatos de ficheiro ORC. Gravações não-ORC (por exemplo: parquet e formatos de arquivo de texto) não são suportadas via HWC.
O Hive Warehouse Connector precisa de clusters separados para cargas de trabalho do Spark e do Interactive Query. Siga estas etapas para configurar esses clusters no Azure HDInsight.
Tipos de cluster suportados e versões
| Versão HWC | Versão do Spark | Versão do InteractiveQuery |
|---|---|---|
| v1 | Faísca 2.4 | IDH 4.0 | Consulta Interativa 3.1 | IDH 4.0 |
| v2 | Faísca 3.1 | IDH 5.0 | Consulta Interativa 3.1 | IDH 5.0 |
Criar clusters
Crie um cluster HDInsight Spark 4.0 com uma conta de armazenamento e uma rede virtual personalizada do Azure. Para obter informações sobre como criar um cluster em uma rede virtual do Azure, consulte Adicionar o HDInsight a uma rede virtual existente.
Crie um cluster HDInsight Interactive Query (LLAP) 4.0 com a mesma conta de armazenamento e rede virtual do Azure que o cluster Spark.
Definir configurações de HWC
Recolher informações preliminares
Em um navegador da Web, navegue até
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEonde LLAPCLUSTERNAME é o nome do cluster de Consulta Interativa.Navegue até URL JDBC interativo Summary>HiveServer2 e anote o valor. O valor pode ser semelhante a:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Navegue até Configs>Advanced>Advanced hive-site>hive.zookeeper.quorum e anote o valor. O valor pode ser semelhante a:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Navegue até Configs>Advanced>General>hive.metastore.uris e anote o valor. O valor pode ser semelhante a:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Navegue até Configs>Advanced>Advanced hive-interactive-site>hive.llap.daemon.service.hosts e anote o valor. O valor pode ser semelhante a:
@llap0.
Definir configurações de cluster do Spark
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsonde CLUSTERNAME é o nome do cluster do Apache Spark.Expanda Faísca personalizada2-defaults.

Selecione Adicionar propriedade... para adicionar as seguintes configurações:
Configuração Value spark.datasource.hive.warehouse.load.staging.dirSe você estiver usando a conta de armazenamento ADLS Gen2, use abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Se você estiver usando a Conta de Armazenamento de Blob do Azure, usewasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp.
Defina como um diretório de preparo compatível com HDFS adequado. Se você tiver dois clusters diferentes, o diretório de preparo deverá ser uma pasta no diretório de preparo da conta de armazenamento do cluster LLAP para que o HiveServer2 tenha acesso a ele. SubstituaSTORAGE_ACCOUNT_NAMEpelo nome da conta de armazenamento que está sendo usada pelo cluster eSTORAGE_CONTAINER_NAMEpelo nome do contêiner de armazenamento.spark.sql.hive.hiveserver2.jdbc.urlO valor obtido anteriormente da URL JDBC interativa do HiveServer2 spark.datasource.hive.warehouse.metastoreUriO valor obtido anteriormente de hive.metastore.uris. spark.security.credentials.hiveserver2.enabledtruepara o modo de cluster YARN efalsepara o modo de cliente YARN.spark.hadoop.hive.zookeeper.quorumO valor obtido anteriormente de hive.zookeeper.quorum. spark.hadoop.hive.llap.daemon.service.hostsO valor obtido anteriormente de hive.llap.daemon.service.hosts. Salve as alterações e reinicie todos os componentes afetados.
Configurar o HWC para clusters ESP (Enterprise Security Package)
O Enterprise Security Package (ESP) fornece recursos de nível empresarial, como autenticação baseada no Ative Directory, suporte multiusuário e controle de acesso baseado em função para clusters Apache Hadoop no Azure HDInsight. Para obter mais informações sobre ESP, consulte Usar o pacote de segurança empresarial no HDInsight.
Além das configurações mencionadas na seção anterior, adicione a seguinte configuração para usar o HWC nos clusters ESP.
Na interface do usuário da Web Ambari do cluster Spark, navegue até Spark2>CONFIGS>Custom spark2-defaults.
Atualize a seguinte propriedade.
Configuração Value spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryonde CLUSTERNAME é o nome do cluster de Consulta Interativa. Clique em HiveServer2 Interactive. Você verá o FQDN (Nome de Domínio Totalmente Qualificado) do nó principal no qual o LLAP está sendo executado, conforme mostrado na captura de tela. Substitua<llap-headnode>por este valor.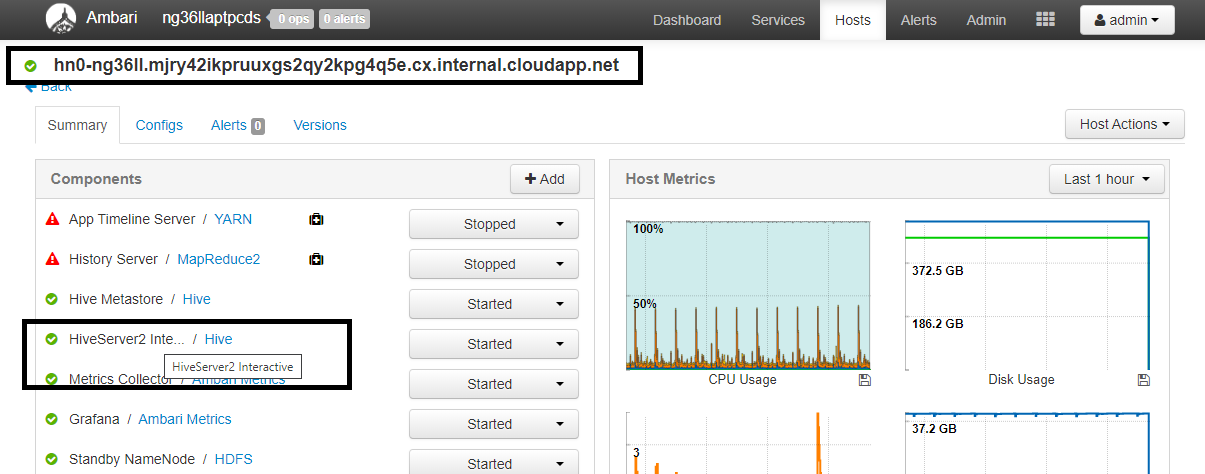
Use o comando ssh para se conectar ao cluster de Consulta Interativa. Procure
default_realmo/etc/krb5.confparâmetro no arquivo. Substitua<AAD-DOMAIN>por esse valor como uma cadeia de caracteres maiúscula, caso contrário, a credencial não será encontrada.
Por exemplo,
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Salve as alterações e reinicie os componentes conforme necessário.
Uso do Hive Warehouse Connector
Você pode escolher entre alguns métodos diferentes para se conectar ao cluster do Interactive Query e executar consultas usando o Hive Warehouse Connector. Os métodos suportados incluem as seguintes ferramentas:
Abaixo estão alguns exemplos para se conectar ao HWC do Spark.
Concha de faísca
Esta é uma maneira de executar o Spark interativamente através de uma versão modificada do shell do Scala.
Use o comando ssh para se conectar ao cluster do Apache Spark. Edite o comando abaixo substituindo CLUSTERNAME pelo nome do cluster e digite o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netNa sessão ssh, execute o seguinte comando para anotar a
hive-warehouse-connector-assemblyversão:ls /usr/hdp/current/hive_warehouse_connectorEdite o código abaixo com a versão identificada
hive-warehouse-connector-assemblyacima. Em seguida, execute o comando para iniciar o shell de faísca:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseDepois de iniciar o shell de faísca, uma instância do Hive Warehouse Connector pode ser iniciada usando os seguintes comandos:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Faísca-enviar
O Spark-submit é um utilitário para enviar qualquer programa (ou trabalho) do Spark para clusters do Spark.
O trabalho spark-submit irá configurar o Spark and Hive Warehouse Connector de acordo com nossas instruções, executar o programa que passamos para ele e, em seguida, liberar de forma limpa os recursos que estavam sendo usados.
Depois de construir o código scala/java junto com as dependências em um assembly jar, use o comando abaixo para iniciar um aplicativo Spark. Substitua <VERSION>, e <APP_JAR_PATH> pelos valores reais.
Modo Cliente YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarModo de cluster YARN
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Este utilitário também é usado quando escrevemos todo o aplicativo no pySpark e empacotamos em .py arquivos (Python), para que possamos enviar todo o código para o cluster Spark para execução.
Para aplicativos Python, passe um arquivo .py no lugar de , e adicione o arquivo de configuração abaixo (Python .zip) ao caminho de /<APP_JAR_PATH>/myHwcAppProject.jarpesquisa com --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Executar consultas em clusters ESP (Enterprise Security Package)
Use kinit antes de iniciar o spark-shell ou spark-submit. Substitua USERNAME pelo nome de uma conta de domínio com permissões para acessar o cluster e execute o seguinte comando:
kinit USERNAME
Protegendo dados em clusters ESP do Spark
Crie uma tabela
democom alguns dados de exemplo inserindo os seguintes comandos:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');Exiba o conteúdo da tabela com o seguinte comando. Antes de aplicar a política, a
demotabela mostra a coluna completa.hive.executeQuery("SELECT * FROM demo").show()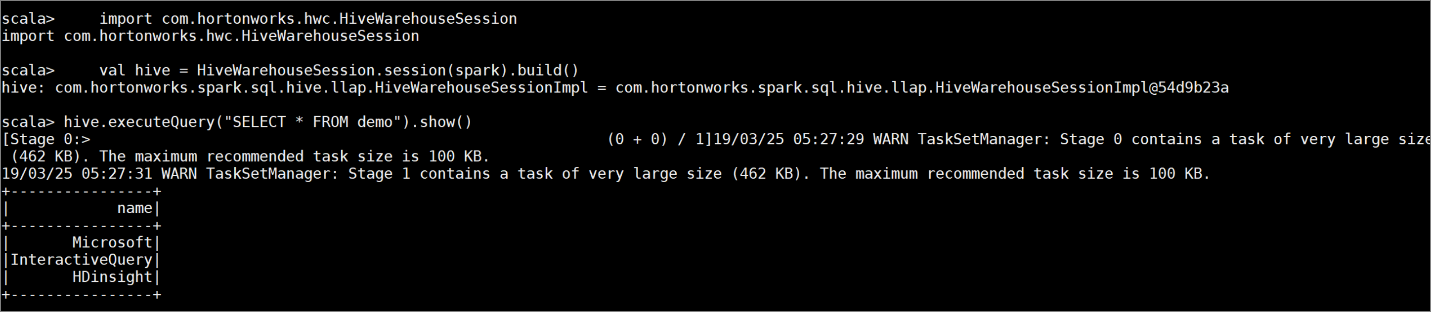
Aplique uma política de mascaramento de coluna que mostre apenas os últimos quatro caracteres da coluna.
Vá para a interface do usuário de administração da Ranger em
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/.Clique no serviço Hive para o seu cluster em Hive.
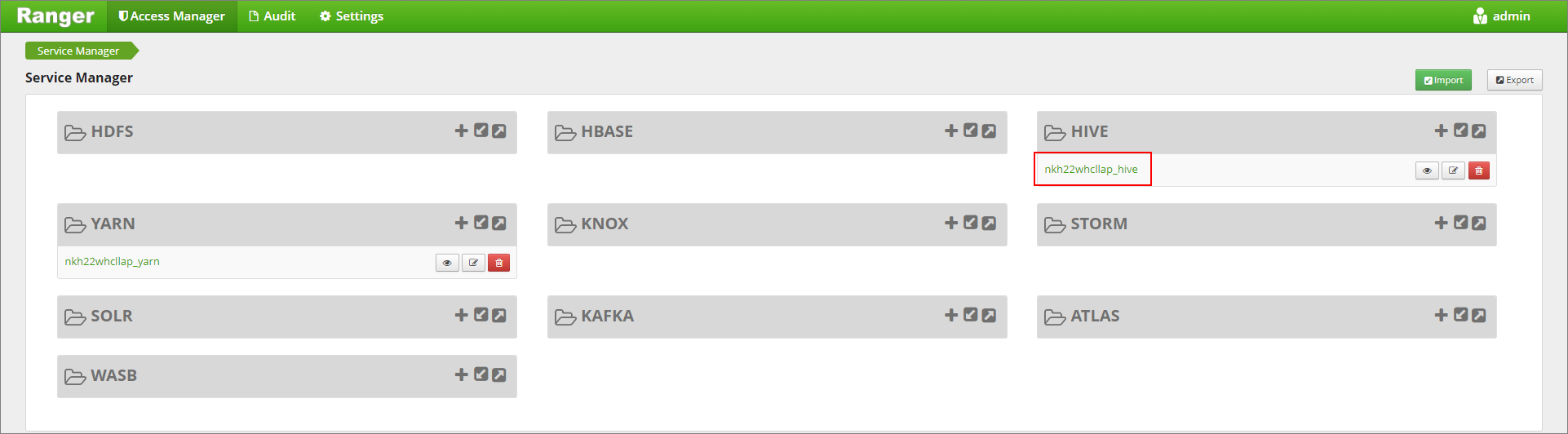
Clique no separador Mascaramento e, em seguida, em Adicionar Nova Política
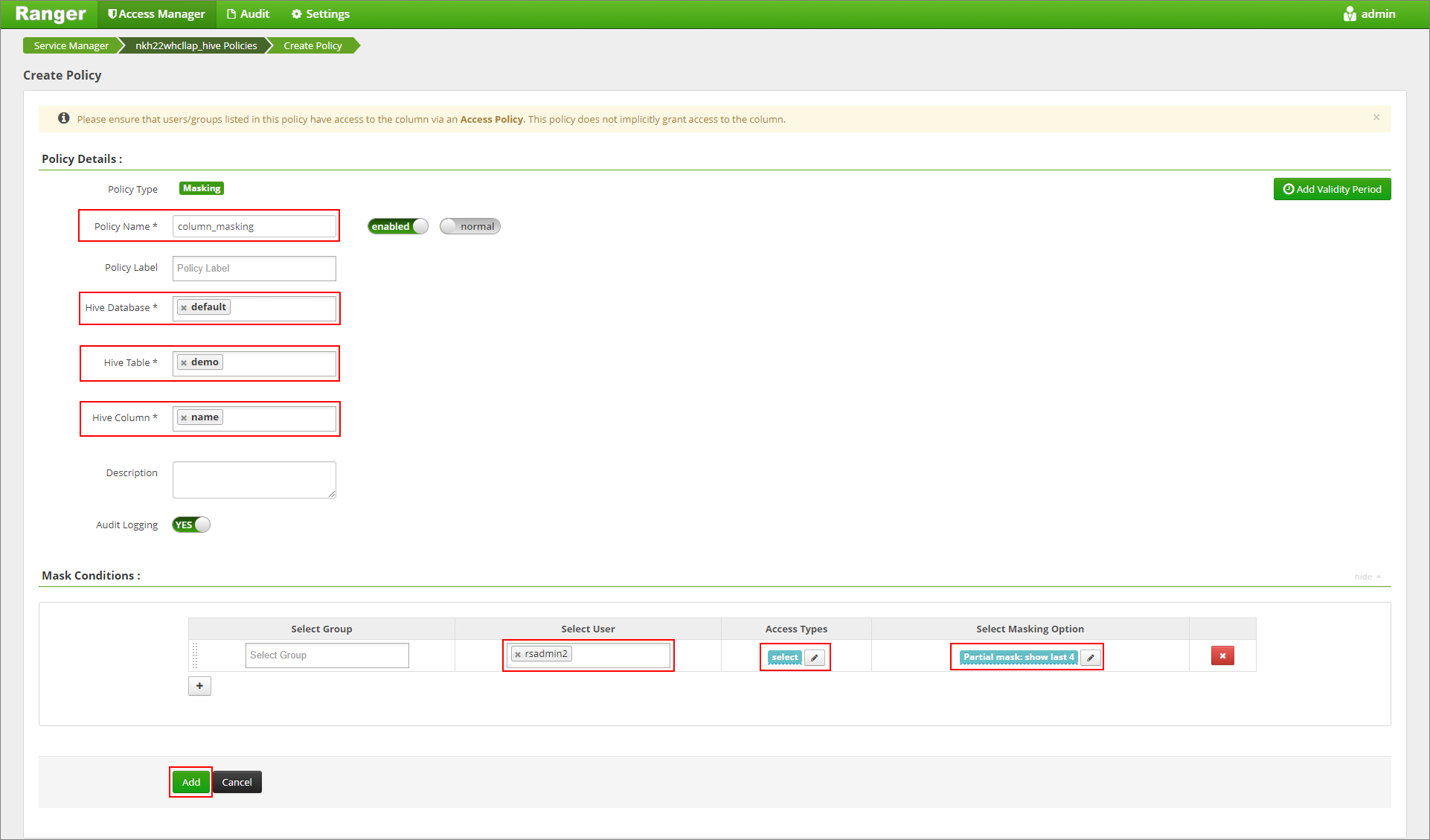
Forneça um nome de política desejado. Selecione o banco de dados: Padrão, Tabela Hive: demo, Coluna Hive: nome, Usuário: rsadmin2, Tipos de acesso: selecione e Máscara parcial: mostre os últimos 4 no menu Selecionar opção de mascaramento. Clique em Adicionar.
Exiba o conteúdo da tabela novamente. Depois de aplicar a política ranger, podemos ver apenas os últimos quatro caracteres da coluna.
