Guia de início rápido: criar cluster Apache Kafka no Azure HDInsight usando o portal do Azure
Apache Kafka é uma plataforma de streaming distribuída de código aberto. É frequentemente utilizado como mediador de mensagens, uma vez que fornece funcionalidades semelhantes a uma fila de mensagens de publicação-subscrição.
Neste Guia de início rápido, você aprenderá a criar um cluster Apache Kafka usando o portal do Azure. Também vai saber como utilizar utilitários incluídos para enviar e receber mensagens com o Apache Kafka. Para obter explicações detalhadas sobre as configurações disponíveis, consulte Configurar clusters no HDInsight. Para obter informações adicionais sobre o uso do portal para criar clusters, consulte Criar clusters no portal.
Aviso
A cobrança de clusters HDInsight é rateada por minuto, quer você os use ou não. Certifique-se de excluir o cluster depois de terminar de usá-lo. Veja como excluir um cluster HDInsight.
Só os recursos dentro da mesma rede virtual podem aceder à API do Apache Kafka. Neste Guia de início rápido, você acessa o cluster diretamente usando SSH. Para ligar outros serviços, redes ou máquinas virtuais ao Apache Kafka, tem primeiro de criar uma rede virtual e, em seguida, criar os recursos dentro da rede. Para obter mais informações, veja o documento Ligar ao Apache Kafka com uma rede virtual. Para obter mais informações gerais sobre como planejar redes virtuais para o HDInsight, consulte Planejar uma rede virtual para o Azure HDInsight.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Um cliente SSH. Para obter mais informações, veja Ligar ao HDInsight (Apache Hadoop) através de SSH.
Criar um cluster do Apache Kafka
Para criar um cluster Apache Kafka no HDInsight, use as seguintes etapas:
Inicie sessão no portal do Azure.
No menu superior, selecione + Criar um recurso.
Selecione Analytics>Azure HDInsight para ir para a página Criar cluster HDInsight.
Na guia Noções básicas , forneça as seguintes informações:
Property Descrição Subscrição Na lista suspensa, selecione a assinatura do Azure usada para o cluster. Grupo de recursos Crie um grupo de recursos ou selecione um existente. Um grupo de recursos é um contentor de componentes do Azure. Neste caso, o grupo de recursos contém o cluster do HDInsight e a conta de armazenamento do Azure dependente. Nome do cluster Introduza um nome globalmente exclusivo. O nome pode ter até 59 caracteres, incluindo letras, números e hífenes. O primeiro e o último carateres do nome não podem ser hífenes. País/Região Na lista suspensa, selecione uma região onde o cluster é criado. Escolha uma região mais próxima de si para um melhor desempenho. Tipo de cluster Selecione Selecionar tipo de cluster para abrir uma lista. Na lista, selecione Kafka como o tipo de cluster. Versão A versão padrão para o tipo de cluster será especificada. Selecione na lista suspensa se desejar especificar uma versão diferente. Nome de utilizador e palavra-passe de início de sessão do cluster O nome de login padrão é admin. A senha deve ter pelo menos 10 caracteres e deve conter pelo menos um dígito, uma letra maiúscula e uma letra minúscula, um caractere não alfanumérico (exceto caracteres' ` "). Certifique-se de que não fornece palavras-passe comuns, comoPass@word1.Nome de utilizador de Secure Shell (SSH) O nome de usuário padrão é sshuser. Pode indicar outro nome de utilizador SSH.Usar senha de login de cluster para SSH Marque essa caixa de seleção para usar a mesma senha para o usuário SSH que você forneceu para o usuário de logon do cluster. 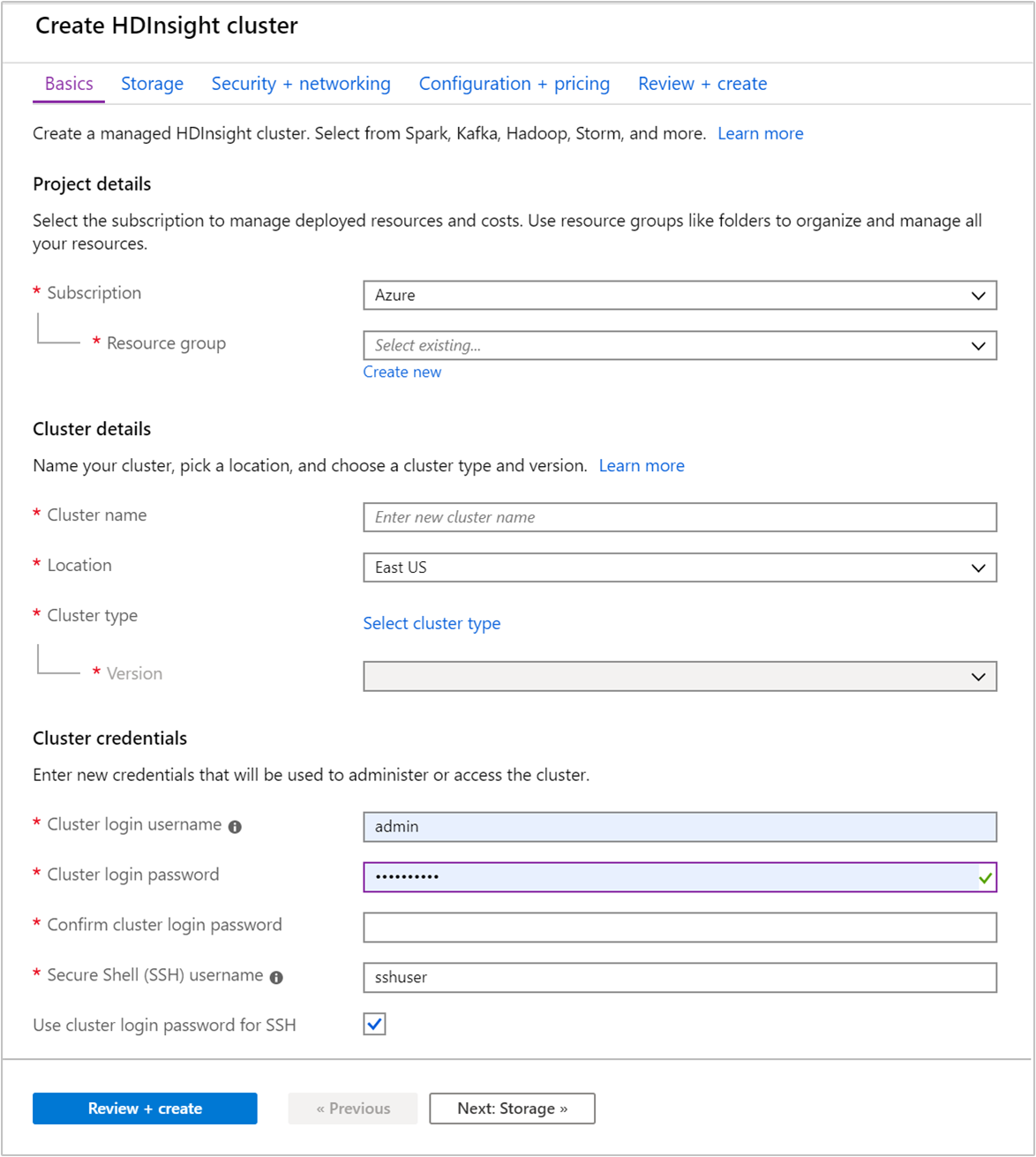
Cada região do Azure (localização) fornece domínios de falha. Um domínio de falha é um agrupamento lógico de hardware subjacente num centro de dados do Azure. Cada domínio de falha partilha um comutador de rede e uma fonte de alimentação. As máquinas virtuais e os discos geridos que implementam os nós num cluster HDInsight são distribuídos por esses domínios de falha. Esta arquitetura limita o possível impacto de falhas físicas de hardware.
Para obter uma elevada disponibilidade de dados, selecione uma região (localização) que contenha três domínios de falha. Para obter informações sobre o número de domínios de falha numa região, consulte o documento Disponibilidade das máquinas virtuais Linux.
Selecione a guia Avançar: Armazenamento >> para avançar para as configurações de armazenamento.
Na guia Armazenamento, forneça os seguintes valores:
Property Description Tipo de armazenamento primário Use o valor padrão Armazenamento do Azure. Método de seleção Use o valor padrão Selecionar da lista. Conta de armazenamento primária Use a lista suspensa para selecionar uma conta de armazenamento existente ou selecione Criar novo. Se criar uma nova conta, o nome tem de ter entre 3 e 24 carateres e pode incluir apenas números e letras minúsculas Contentor Use o valor preenchido automaticamente. 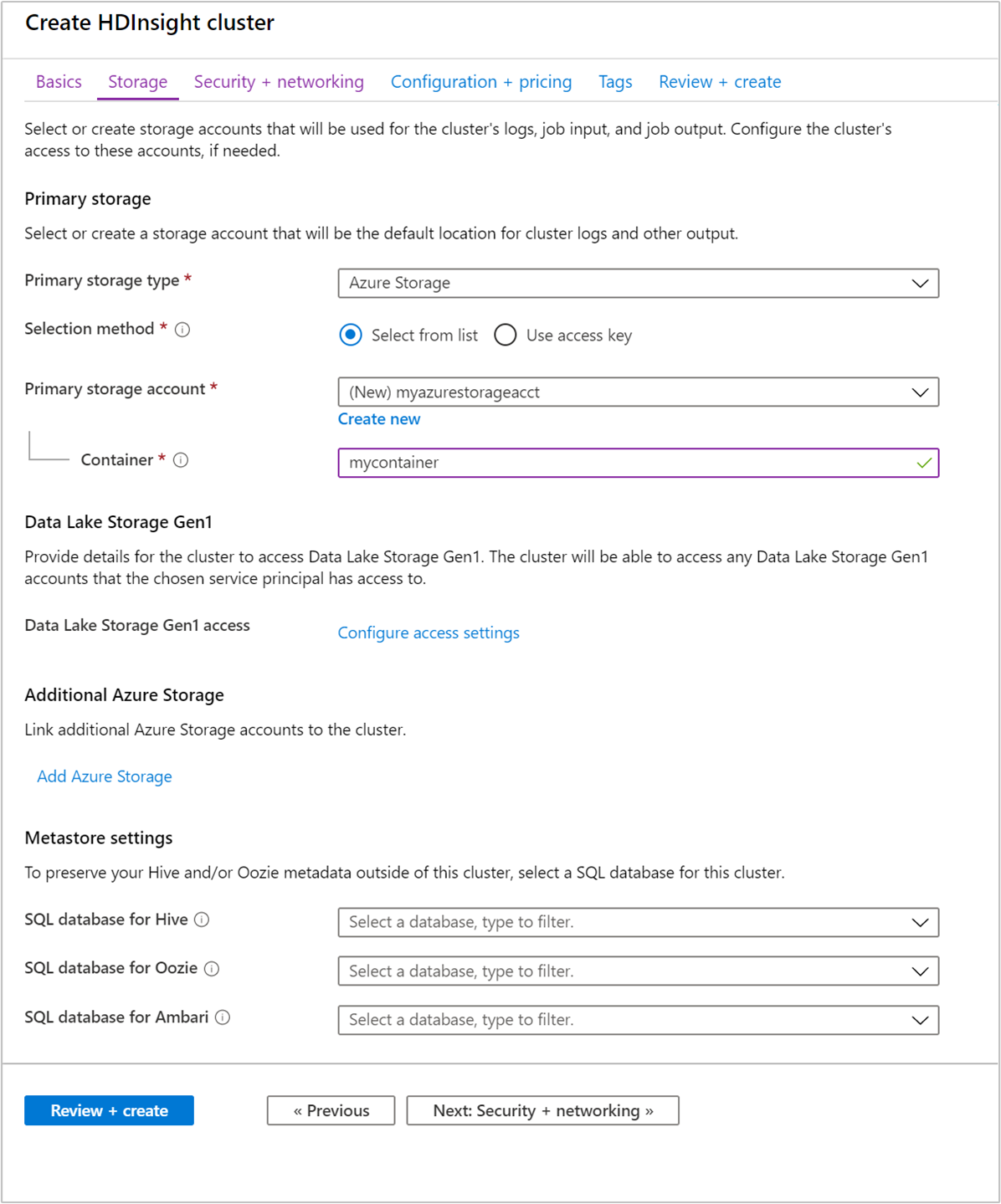
Selecione a guia Segurança + rede .
Para este Guia de início rápido, deixe as configurações de segurança padrão. Para saber mais sobre o pacote de Segurança Empresarial, visite Configurar um cluster HDInsight com o Pacote de Segurança Empresarial usando os Serviços de Domínio Microsoft Entra. Para saber como usar sua própria chave para o Apache Kafka Disk Encryption, visite Criptografia de disco de chave gerenciada pelo cliente
Se quiser ligar o seu cluster a uma rede virtual, selecione uma rede virtual na lista pendente Rede Virtual.
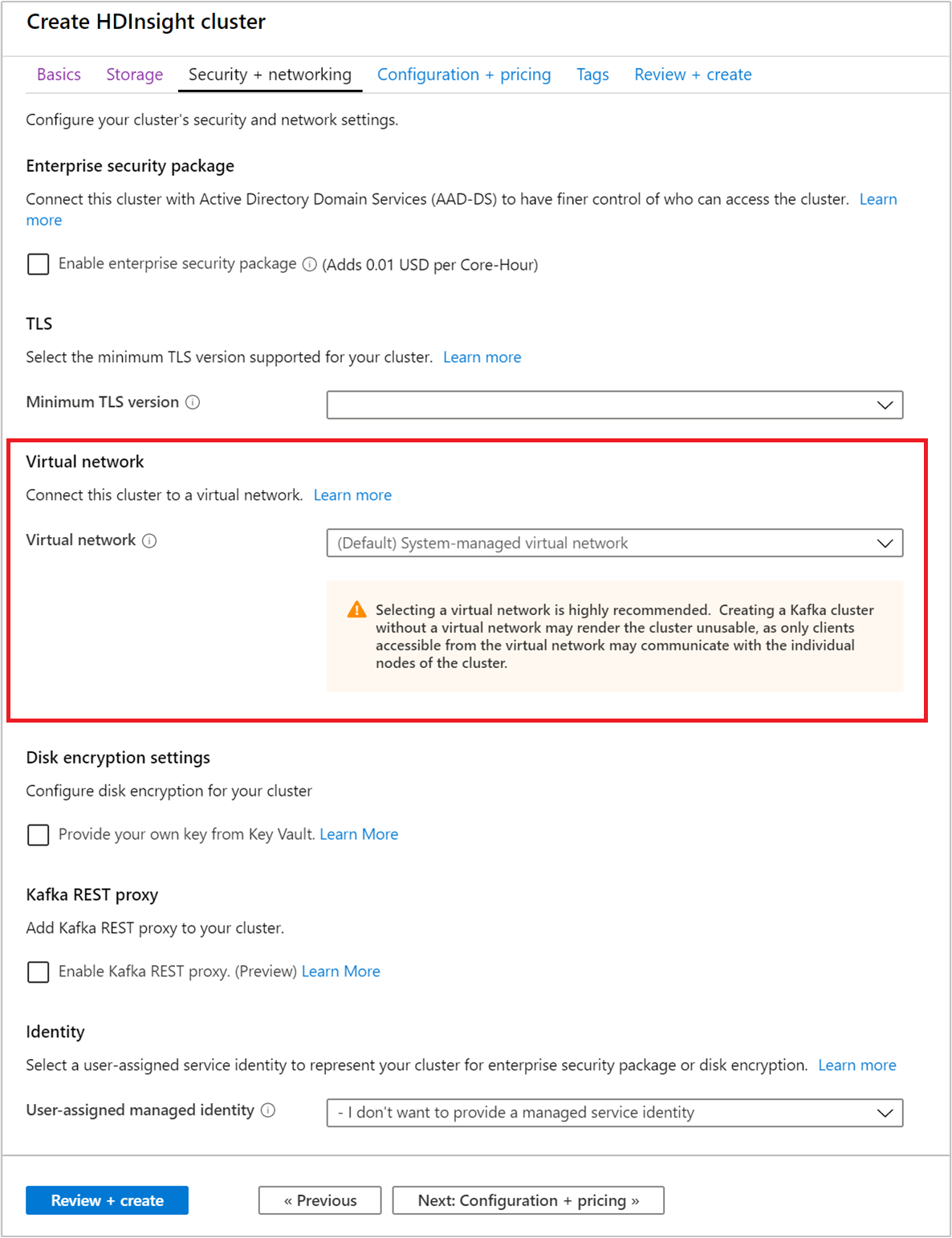
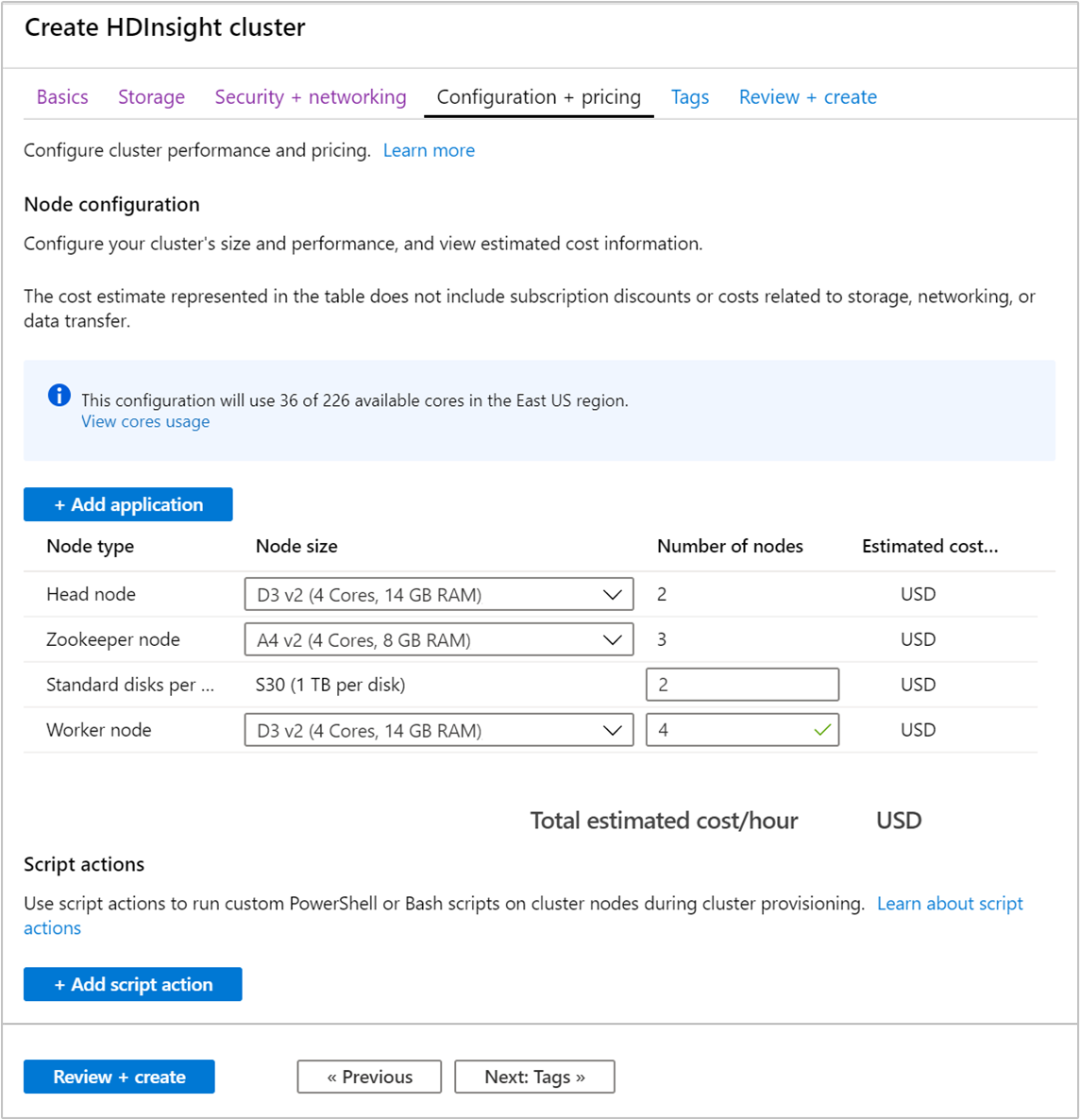
Selecione a guia Configuração + preço .
Para garantir a disponibilidade do Apache Kafka no HDInsight, o número de nós de entrada para o nó Worker deve ser definido como 3 ou superior. O valor predefinido é 4.
Os discos padrão por entrada de nó de trabalho configuram a escalabilidade do Apache Kafka no HDInsight. O Apache Kafka no HDInsight utiliza o disco local das máquinas virtuais no cluster para armazenar dados. O Apache Kafka recebe um fluxo intensivo de dados de E/S, pelo que o Azure Managed Disks é utilizado para garantir um elevado débito e uma maior capacidade de armazenamento por nó. O tipo de disco gerido pode ser Standard (HDD) ou Premium (SSD). O tipo de disco depende do tamanho da VM utilizado pelos nós de trabalho (mediadores do Apache Kafka). Os discos Premium são utilizados automaticamente com as VMs das séries DS e GS. Todos os outros tipos de VM utilizam discos Standard.
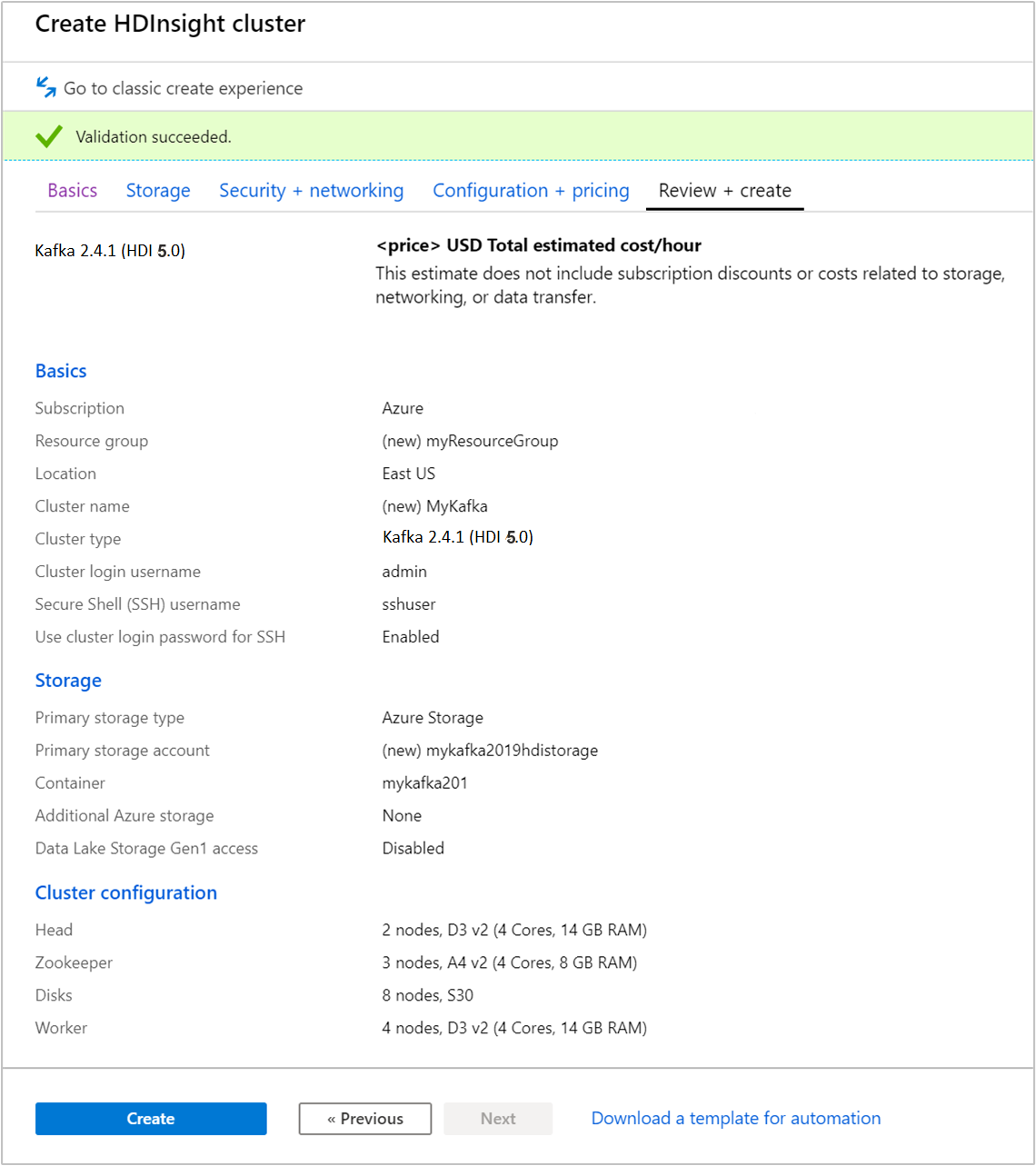
Selecione a guia Revisar + criar .
Revise a configuração do cluster. Altere todas as configurações incorretas. Por fim, selecione Criar para criar o cluster.
A criação do cluster pode demorar até 20 minutos.
Ligar ao cluster
Use o comando ssh para se conectar ao cluster. Edite o comando abaixo substituindo CLUSTERNAME pelo nome do cluster e digite o comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netQuando lhe for pedido, introduza a palavra-passe do utilizador SSH.
Quando estiver ligado, verá informações semelhantes ao texto seguinte:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Obtenha as informações do host Apache Zookeeper e Broker
Ao trabalhar com Kafka, você deve conhecer os hosts Apache Zookeeper e Broker . Estes anfitriões são utilizados com a API do Apache Kafka e com muitos dos utilitários que são enviados com o Kafka.
Nesta seção, você obtém as informações do host da API REST do Apache Ambari no cluster.
Instale jq, um processador JSON de linha de comando. Este utilitário é usado para analisar documentos JSON e é útil na análise das informações do host. A partir da conexão SSH aberta, digite o seguinte comando para instalar
jq:sudo apt -y install jqConfigure a variável de senha. Substitua
PASSWORDpela senha de login do cluster e digite o comando:export PASSWORD='PASSWORD'Extraia o nome do cluster com caixa correta. O invólucro real do nome do cluster pode ser diferente do esperado, dependendo de como o cluster foi criado. Este comando obterá o invólucro real e, em seguida, armazená-lo-á em uma variável. Introduza o seguinte comando:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Nota
Se você estiver fazendo esse processo de fora do cluster, há um procedimento diferente para armazenar o nome do cluster. Obtenha o nome do cluster em minúsculas no portal do Azure. Em seguida, substitua o nome do cluster pelo
<clustername>comando a seguir e execute-o:export clusterName='<clustername>'.Para definir uma variável de ambiente com as informações do host do Zookeeper, use o comando abaixo. O comando recupera todos os hosts do Zookeeper e, em seguida, retorna apenas as duas primeiras entradas. Isto acontece porque é desejável que exista alguma redundância para o caso de um anfitrião estar inacessível.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Nota
Este comando requer acesso Ambari. Se o cluster estiver atrás de um NSG, execute este comando a partir de uma máquina que possa acessar o Ambari.
Para verificar se a variável de ambiente está definida corretamente, utilize o comando seguinte:
echo $KAFKAZKHOSTSEste comando devolve informações semelhantes ao texto seguinte:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Para definir uma variável de ambiente com as informações do anfitrião do mediador do Apache Kafka, utilize o comando seguinte:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Nota
Este comando requer acesso Ambari. Se o cluster estiver atrás de um NSG, execute este comando a partir de uma máquina que possa acessar o Ambari.
Para verificar se a variável de ambiente está definida corretamente, utilize o comando seguinte:
echo $KAFKABROKERSEste comando devolve informações semelhantes ao texto seguinte:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Gerir tópicos do Apache Kafka
O Kafka armazena fluxos de dados em tópicos. Pode utilizar o utilitário kafka-topics.sh para gerir os tópicos.
Para criar um tópico, utilize o seguinte comando na ligação SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSEste comando se conecta ao Broker usando as informações do host armazenadas no
$KAFKABROKERS. Em seguida, cria um tópico do Apache Kafka denominado test.Os dados armazenados neste tópico estão particionados em oito partições.
Cada partição é replicada em três nós de trabalho no cluster.
Se tiver criado o cluster numa região do Azure que fornece três domínios de falha, utilize um fator de replicação de 3. Caso contrário, utilize um fator de replicação de 4.
Nas regiões com três domínios de falha, um fator de replicação de 3 permite que as réplicas sejam distribuídas pelos domínios de falha. Nas regiões com dois domínios de falha, um fator de replicação de 4 distribui as réplicas uniformemente pelos domínios.
Para obter informações sobre o número de domínios de falha numa região, consulte o documento Disponibilidade das máquinas virtuais Linux.
O Apache Kafka não está ciente dos domínios de falha do Azure. Durante a criação de réplicas de partição para tópicos, poderá não distribuir as réplicas corretamente para fins de elevada disponibilidade.
Para garantir alta disponibilidade, use a ferramenta de reequilíbrio de partições Apache Kafka. Esta ferramenta deve ser executada a partir de uma ligação SSH ao nó principal do cluster do Apache Kafka.
Para garantir a maior disponibilidade dos seus dados do Apache Kafka, deve reequilibrar as réplicas de partições do tópico quando:
Criar um novo tópico ou partição
Aumentar verticalmente um cluster
Para listar os tópicos, utilize o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSEste comando apresenta uma lista de tópicos disponíveis no cluster do Apache Kafka.
Para eliminar um tópico, utilize o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSEste comando elimina o tópico com o nome
topicname.Aviso
Se eliminar o tópico
testcriado anteriormente, tem de recriá-lo. O mesmo é utilizado por passos mais adiante neste documento.
Para obter mais informações sobre os comandos disponíveis com o utilitário kafka-topics.sh, utilize o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produzir e consumir registos
O Kafka armazena registos nos tópicos. Os registos são produzidos por produtores e consumidos por consumidores. Os produtores e consumidores comunicam com o serviço do mediador do Kafka. Cada nó de trabalho no cluster do HDInsight é um anfitrião do mediador do Apache Kafka.
Utilize os seguintes passos para armazenar os registos no tópico de teste criado anteriormente e, em seguida, leia-os através de um consumidor:
Para escrever registos no tópico, utilize o utilitário
kafka-console-producer.sha partir da ligação SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testApós este comando, chega a uma linha vazia.
Introduza uma mensagem de texto na linha vazia e carregue em Enter. Introduza algumas mensagens desta forma e, em seguida, utilize Ctrl + C para regressar à linha de comandos normal. Cada linha é enviada como um registo separado para o tópico do Apache Kafka.
Para ler registos do tópico, utilize o utilitário
kafka-console-consumer.sha partir da ligação SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningEste comando obtém os registos do tópico e apresenta-os. A utilização de
--from-beginningindica ao consumidor para iniciar a partir do início da transmissão em fluxo, para que todos os registos sejam obtidos.Se estiver a utilizar uma versão antiga do Kafka, substitua
--bootstrap-server $KAFKABROKERSpor--zookeeper $KAFKAZKHOSTS.Utilize Ctrl + C para parar o consumidor.
Também podem criar programaticamente produtores e consumidores. Para obter um exemplo de uso dessa API, consulte o documento Apache Kafka Producer and Consumer API with HDInsight .
Clean up resources (Limpar recursos)
Para limpar os recursos criados por este início rápido, pode eliminar o grupo de recursos. Ao eliminar o grupo de recursos também elimina o cluster do HDInsight associado e quaisquer outros recursos associados ao grupo de recursos.
Para remover o grupo de recursos através do Portal do Azure:
- No Portal do Azure, expanda o menu no lado esquerdo para abrir o menu de serviços e, em seguida, escolha Grupos de Recursos, para apresentar a lista dos seus grupos de recursos.
- Encontre o grupo de recursos a eliminar e, em seguida, clique com o botão direito do rato em Mais (...) no lado direito da lista.
- Selecione Eliminar grupo de recursos e, em seguida, confirme.
Aviso
A exclusão de um cluster Apache Kafka no HDInsight exclui todos os dados armazenados no Kafka.