Tutorial: Criar um aplicativo Scala Maven para Apache Spark no HDInsight usando o IntelliJ
Neste tutorial, você aprenderá a criar um aplicativo Apache Spark escrito em Scala usando o Apache Maven com IntelliJ IDEA. O artigo usa o Apache Maven como o sistema de compilação. E começa com um arquétipo Maven existente para Scala fornecido pelo IntelliJ IDEA. Criar uma aplicação Scala no IntelliJ IDEA envolve os seguintes passos:
- Utilizar o Maven como o sistema de compilação.
- Atualizar o ficheiro Project Object Model (POM) (POM) para resolver dependências do módulo do Spark.
- Escrever a aplicação no Scala.
- Gerar um ficheiro jar que pode ser submetido para clusters do Spark no HDInsight.
- Utilizar o Livy para executar a aplicação no cluster do Spark.
Neste tutorial, irá aprender a:
- Instalar o plug-in do Scala para o IntelliJ IDEA
- Utilizar o IntelliJ para desenvolver uma aplicação Scala Maven
- Criar um projeto de Scala autónomo
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, veja Criar clusters do Apache Spark no Azure HDInsight.
Kit de desenvolvimento Oracle Java. Este tutorial usa Java versão 8.0.202.
Um IDE Java. Este artigo usa o IntelliJ IDEA Community 2018.3.4.
Kit de Ferramentas do Azure para IntelliJ. Consulte Instalando o Kit de Ferramentas do Azure para IntelliJ.
Instalar o plug-in do Scala para o IntelliJ IDEA
Execute as seguintes etapas para instalar o plug-in Scala:
Abra o IntelliJ IDEA.
Na tela de boas-vindas, navegue até Configurar>plug-ins para abrir a janela Plug-ins.
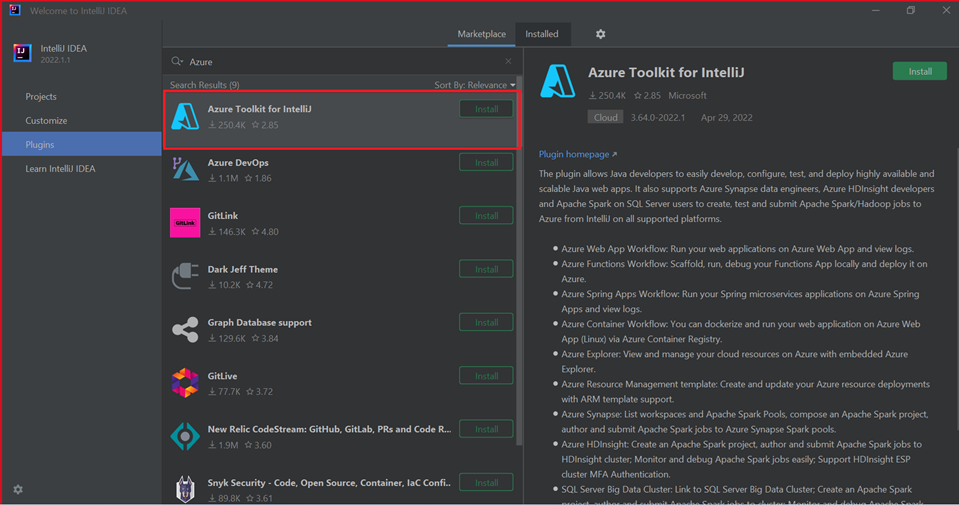
Selecione Instalar para o Kit de Ferramentas do Azure para IntelliJ.
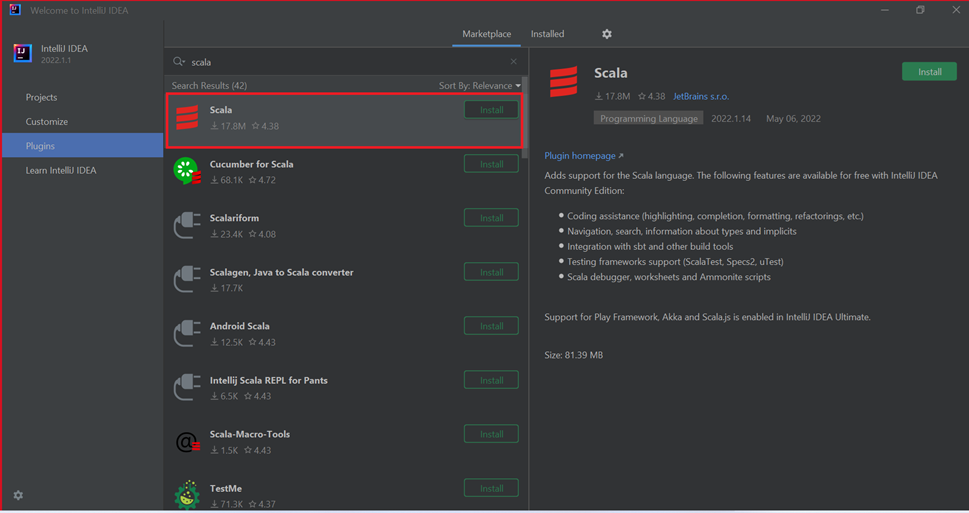
Selecione Instalar para o plug-in Scala apresentado na nova janela.
Após a instalação bem-sucedida do plug-in, tem de reiniciar o IDE.
Utilize o IntelliJ para criar uma aplicação
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto .
Selecione Apache Spark/HDInsight no painel esquerdo.
Selecione Spark Project (Scala) na janela principal.
Na lista suspensa Ferramenta de compilação, selecione um dos seguintes valores:
- Suporte ao assistente de criação de projetos Maven for Scala.
- SBT para gerenciar as dependências e construir para o projeto Scala.
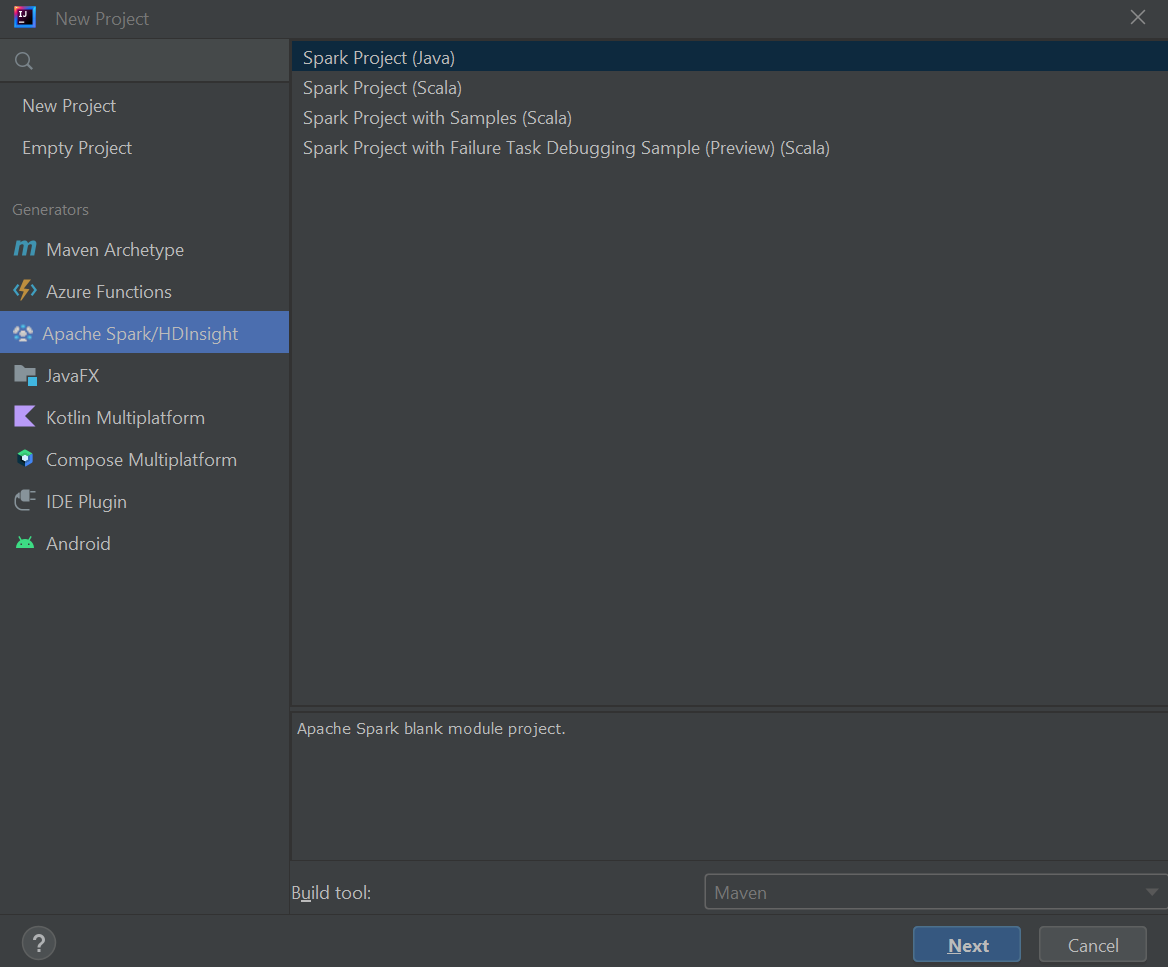
Selecione Seguinte.
Na janela Novo projeto, forneça as seguintes informações:
Property Description Nome do projeto Introduza um nome. Localização do projeto Insira o local para salvar seu projeto. SDK do projeto Este campo estará em branco na sua primeira utilização do IDEA. Selecione Novo... e navegue até o JDK. Versão Spark O assistente de criação integra a versão adequada para o SDK do Spark e o SDK do Scala. Se a versão do cluster do Spark for anterior à 2.0, selecione Spark 1.x. Caso contrário, selecione Spark2.x. Este exemplo usa o Spark 2.3.0 (Scala 2.11.8). 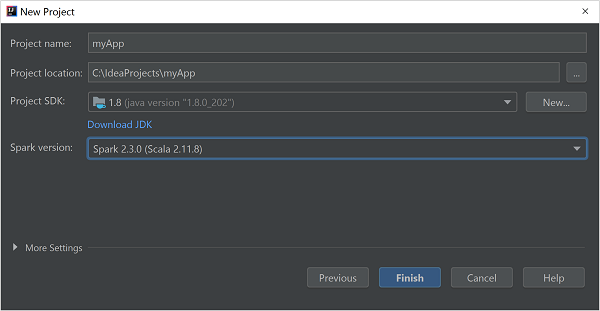
Selecione Concluir.
Criar um projeto de Scala autónomo
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto .
Selecione Maven no painel esquerdo.
Especifique um Project SDK (SDK de Projeto). Se estiver em branco, selecione Novo... e navegue até o diretório de instalação do Java.
Marque a caixa de seleção Criar a partir do arquétipo .
Na lista de arquétipos, selecione
org.scala-tools.archetypes:scala-archetype-simple. Esse arquétipo cria a estrutura de diretórios correta e baixa as dependências padrão necessárias para escrever o programa Scala.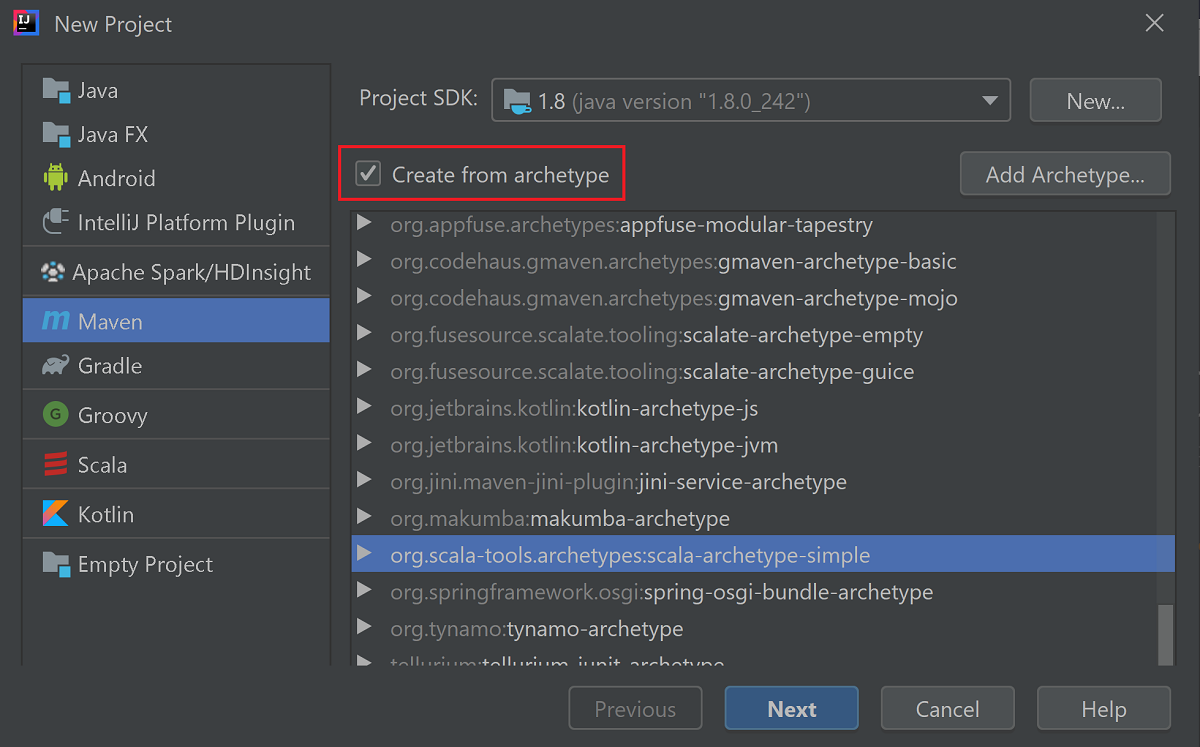
Selecione Seguinte.
Expanda Coordenadas do artefato. Forneça valores relevantes para GroupId e ArtifactId. O nome e a localização serão preenchidos automaticamente. São utilizados os seguintes valores neste tutorial:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
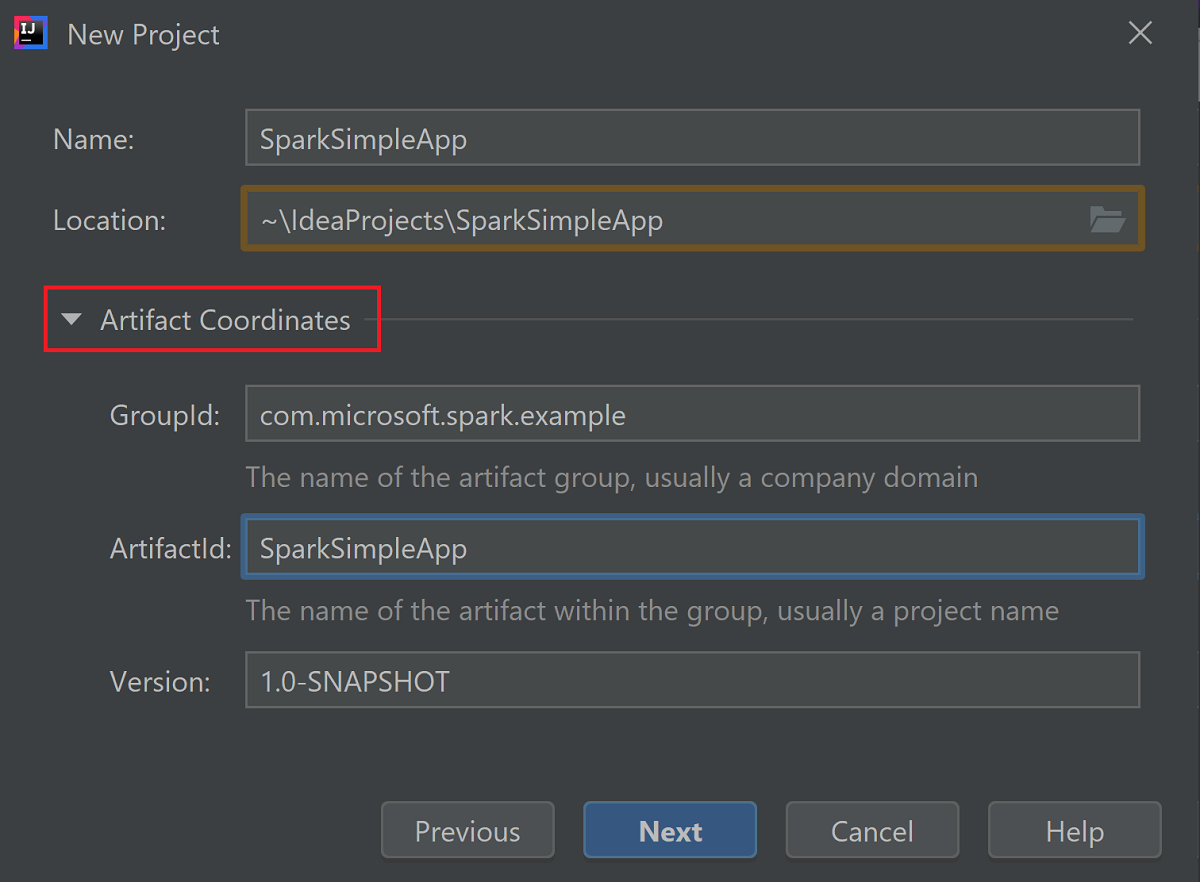
Selecione Seguinte.
Verifique as definições e selecione Next (Seguinte).
Confirme o nome e a localização do projeto e selecione Finish (Concluir). O projeto levará alguns minutos para ser importado.
Depois que o projeto for importado, no painel esquerdo navegue até SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Clique com o botão direito do mouse em MySpec e selecione Excluir.... Você não precisa desse arquivo para o aplicativo. Selecione OK na caixa de diálogo.
Nas etapas posteriores, atualize o pom.xml para definir as dependências para o aplicativo Spark Scala. Para que essas dependências sejam baixadas e resolvidas automaticamente, você deve configurar o Maven.
No menu Arquivo, selecione Configurações para abrir a janela Configurações.
Na janela Configurações, navegue até Build, Execution, Deployment>Build Tools>Maven>Importing.
Marque a caixa de seleção Importar projetos Maven automaticamente .
Selecione Aplicar e, em seguida, selecione OK. Em seguida, você retornará à janela do projeto.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::No painel esquerdo, navegue até src>main>scala>com.microsoft.spark.example e clique duas vezes em App para abrir App.scala.
Substitua o código de exemplo existente pelo seguinte código e guarde as alterações. Esse código lê os dados do HVAC.csv (disponível em todos os clusters HDInsight Spark). Recupera as linhas que têm apenas um dígito na sexta coluna. E grava a saída em /HVACOut no contêiner de armazenamento padrão para o cluster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }No painel do lado esquerdo, faça duplo clique em pom.xml.
Em
<project>\<properties>, adicione os seguintes segmentos:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Em
<project>\<dependencies>, adicione os seguintes segmentos:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Crie o ficheiro .jar. O IntelliJ IDEA permite a criação do JAR como um artefacto de um projeto. Siga os passos seguintes.
No menu Arquivo, selecione Estrutura do projeto....
Na janela Estrutura do projeto, navegue até Artefatos>o símbolo de adição +>JAR>De módulos com dependências....
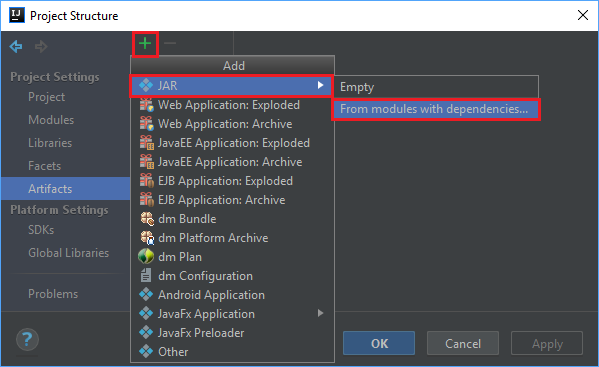
Na janela Criar JAR a partir de módulos, selecione o ícone de pasta na caixa de texto Classe principal.
Na janela Selecionar classe principal, selecione a classe que aparece por padrão e, em seguida, selecione OK.
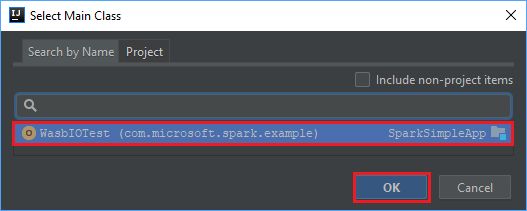
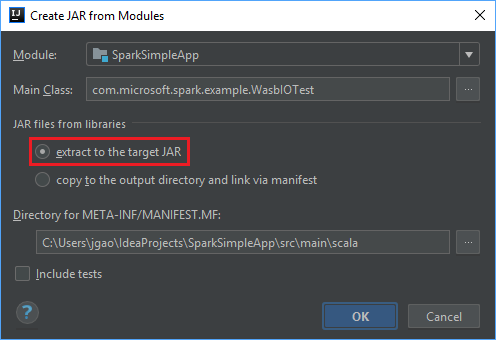
Na janela Criar JAR a partir de módulos, verifique se a opção de extração para o JAR de destino está selecionada e, em seguida, selecione OK. Esta definição cria um único JAR com todas as dependências.
A guia Layout de saída lista todos os jars incluídos como parte do projeto Maven. Pode selecionar e eliminar aqueles em que a aplicação de Scala não tem dependências diretas. Para o aplicativo, você está criando aqui, você pode remover todos, exceto o último (saída de compilação SparkSimpleApp). Selecione os frascos a serem excluídos e, em seguida, selecione o símbolo -negativo .
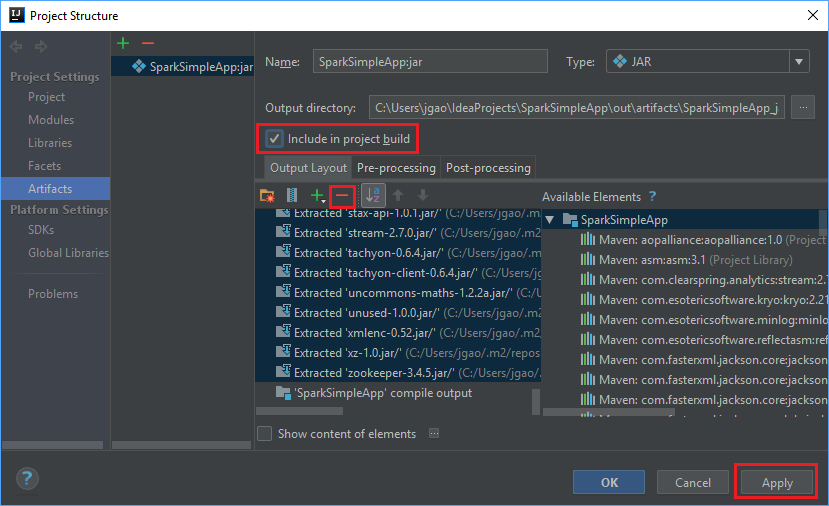
Verifique se a caixa de seleção Incluir na compilação do projeto está marcada. Essa opção garante que o jar seja criado sempre que o projeto for criado ou atualizado. Selecione Aplicar e, em seguida, OK.
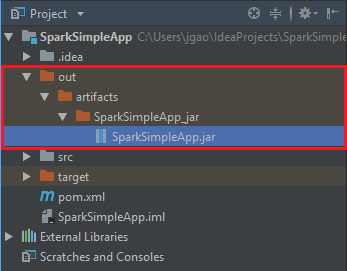
Para criar o jar, navegue até Build>Build Artifacts>Build. O projeto será compilado em cerca de 30 segundos. O jar de saída é criado em \out\artifacts.
Execute o aplicativo no cluster Apache Spark
Para executar a aplicação no cluster, pode utilizar as seguintes abordagens:
Copie o jar do aplicativo para o blob de Armazenamento do Azure associado ao cluster. Para o fazer, pode utilizar AzCopy, um utilitário de linha de comandos. Tem à sua disposição muitos outros clientes para carregar dados. Você pode encontrar mais sobre eles em Carregar dados para trabalhos do Apache Hadoop no HDInsight.
Use o Apache Livy para enviar um trabalho de aplicativo remotamente para o cluster do Spark. Os clusters do Spark no HDInsight incluem o Livy que expõe os pontos finais de REST para submeter remotamente trabalhos do Spark. Para obter mais informações, consulte Enviar trabalhos do Apache Spark remotamente usando o Apache Livy com clusters do Spark no HDInsight.
Clean up resources (Limpar recursos)
Se não pretender continuar a utilizar esta aplicação, elimine o cluster que criou com os seguintes passos:
Inicie sessão no portal do Azure.
Na caixa Pesquisar na parte superior, digite HDInsight.
Selecione Clusters HDInsight em Serviços.
Na lista de clusters HDInsight exibida, selecione o botão ... ao lado do cluster que você criou para este tutorial.
Selecione Eliminar. Selecione Yes (Sim).
Próximo passo
Neste artigo, você aprendeu como criar um aplicativo Apache Spark scala. Avance para o próximo artigo para saber como executar esta aplicação num cluster do HDInsight Spark com Livy.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários