Melhorar o desempenho de cargas de trabalho do Apache Spark usando o Cache de E/S do Azure HDInsight
Nota
- O cache de E/S era suportado até o Spark 2.3 e não será suportado no Spark 2.4 (HDInsight 4.0) e no Spark 3.1.2 (HDInsight 5.0)
O Cache de E/S é um serviço de cache de dados para o Azure HDInsight que melhora o desempenho de trabalhos do Apache Spark. O cache de E/S também funciona com cargas de trabalho Apache TEZ e Apache Hive , que podem ser executadas em clusters Apache Spark . O cache de E/S usa um componente de cache de código aberto chamado RubiX. RubiX é um cache de disco local para uso com mecanismos de análise de big data que acessam dados de sistemas de armazenamento em nuvem. O RubiX é único entre os sistemas de cache, porque usa unidades de estado sólido (SSDs) em vez de reservar memória operacional para fins de cache. O serviço de Cache de E/S inicia e gerencia Servidores de Metadados RubiX em cada nó de trabalho do cluster. Ele também configura todos os serviços do cluster para uso transparente do cache RubiX.
A maioria das SSD fornece mais de 1 GByte por segundo de largura de banda. Essa largura de banda, complementada pelo cache de arquivos na memória do sistema operacional, fornece largura de banda suficiente para carregar mecanismos de processamento de computação de big data, como o Apache Spark. A memória operacional é deixada disponível para o Apache Spark processar tarefas altamente dependentes de memória, como shuffles. Ter o uso exclusivo da memória operacional permite que o Apache Spark alcance o uso ideal de recursos.
Nota
IO Cache atualmente usa RubiX como um componente de cache, mas isso pode mudar em versões futuras do serviço. Por favor, use interfaces de cache de E/S e não tome nenhuma dependência diretamente na implementação RubiX. No momento, o Cache de E/S só é suportado com o Armazenamento BLOB do Azure.
Benefícios do Cache de E/S do Azure HDInsight
O uso do Cache de E/S fornece um aumento de desempenho para trabalhos que leem dados do Armazenamento de Blobs do Azure.
Não é necessário fazer alterações nos trabalhos do Spark para ver aumentos de desempenho ao usar o Cache de E/S. Quando o Cache de E/S está desabilitado, esse código do Spark lê dados remotamente do Armazenamento de Blobs do Azure: spark.read.load('wasbs:///myfolder/data.parquet').count(). Quando o Cache de E/S é ativado, a mesma linha de código causa uma leitura em cache através do Cache de E/S. Nas leituras seguintes, os dados são lidos localmente a partir de SSD. Os nós de trabalho no cluster HDInsight são equipados com unidades SSD dedicadas conectadas localmente. O Cache de E/S do HDInsight usa esses SSDs locais para armazenamento em cache, o que fornece o menor nível de latência e maximiza a largura de banda.
Introdução
O Cache de E/S do Azure HDInsight é desativado por padrão na visualização. O Cache de E/S está disponível em clusters do Azure HDInsight 3.6+ Spark, que executam o Apache Spark 2.3. Para ativar o Cache de E/S no HDInsight 4.0, execute as seguintes etapas:
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net, ondeCLUSTERNAMEé o nome do cluster.Selecione o serviço de cache de E/S à esquerda.
Selecione Ações (Ações de serviço no HDI 3.6) e Ativar.
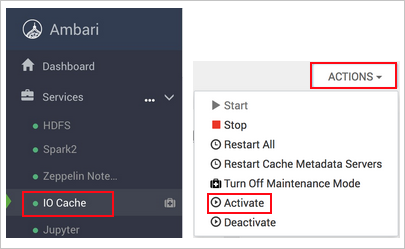
Confirme a reinicialização de todos os serviços afetados no cluster.
Nota
Embora a barra de progresso mostre ativada, o Cache de E/S não será ativado até que você reinicie os outros serviços afetados.
Resolução de Problemas
Você pode obter erros de espaço em disco executando trabalhos do Spark depois de ativar o Cache de E/S. Esses erros ocorrem porque o Spark também usa armazenamento em disco local para armazenar dados durante operações de embaralhamento. O Spark pode ficar sem espaço no SSD quando o cache de E/S estiver ativado e o espaço para o armazenamento do Spark for reduzido. A quantidade de espaço usada pelo cache de E/S é de metade do espaço total do SSD. O uso de espaço em disco para o cache de E/S é configurável no Ambari. Se você receber erros de espaço em disco, reduza a quantidade de espaço SSD usado para o cache de E/S e reinicie o serviço. Para alterar o espaço definido para o cache de E/S, execute as seguintes etapas:
No Apache Ambari, selecione o serviço HDFS à esquerda.
Selecione as guias Configurações e Avançado.
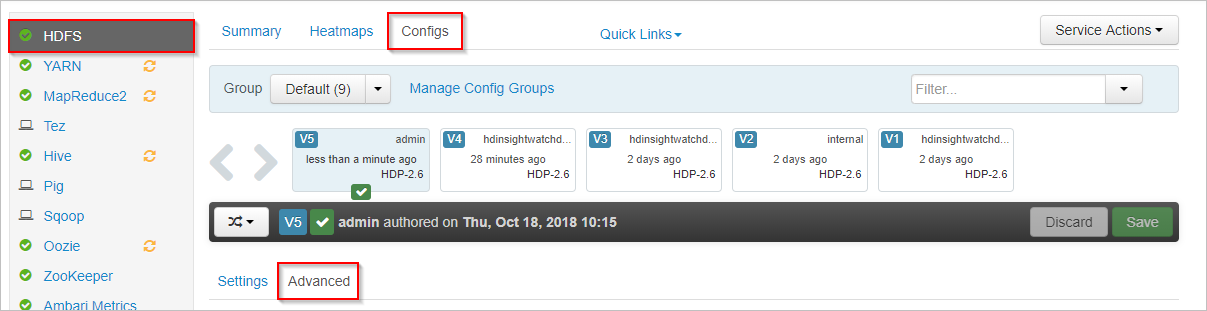
Role para baixo e expanda a área do site principal personalizado.
Localize a propriedade hadoop.cache.data.fullness.percentage.
Altere o valor na caixa.
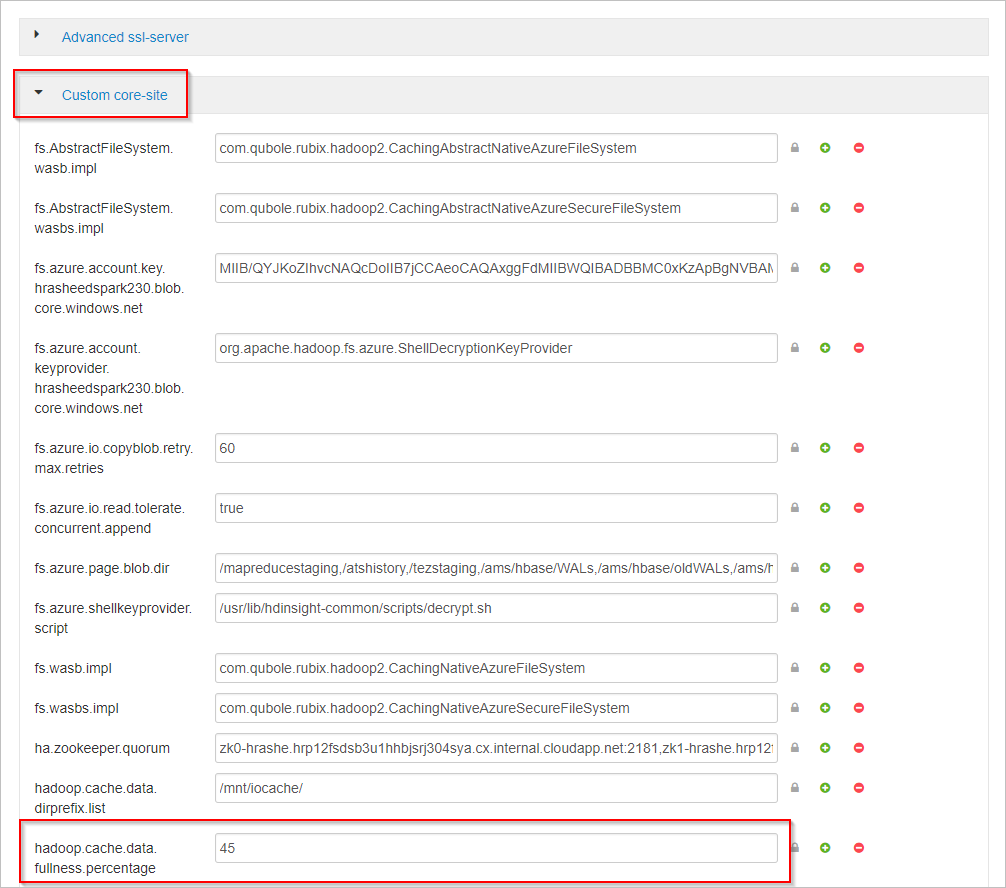
Selecione Salvar no canto superior direito.
Selecione Reiniciar>Reiniciar todos os afetados.

Selecione Confirmar Reiniciar Tudo.
Se isso não funcionar, desative o Cache de E/S.
Passos Seguintes
Leia mais sobre o Cache de E/S, incluindo benchmarks de desempenho nesta postagem de blog: Os trabalhos do Apache Spark ganham até 9x de velocidade com o Cache de E/S do HDInsight