Kernels para Jupyter Notebook em clusters Apache Spark no Azure HDInsight
Os clusters do HDInsight Spark fornecem kernels que você pode usar com o Jupyter Notebook no Apache Spark para testar seus aplicativos. Um kernel é um programa que executa e interpreta o seu código. Os três núcleos são:
- PySpark - para aplicações escritas em Python2. (Aplicável apenas para clusters de versão do Spark 2.4)
- PySpark3 - para aplicações escritas em Python3.
- Spark - para aplicações escritas em Scala.
Neste artigo, você aprenderá como usar esses kernels e os benefícios de usá-los.
Pré-requisitos
Um cluster Apache Spark no HDInsight. Para obter instruções, veja Criar clusters do Apache Spark no Azure HDInsight.
Criar um Bloco de Anotações Jupyter no Spark HDInsight
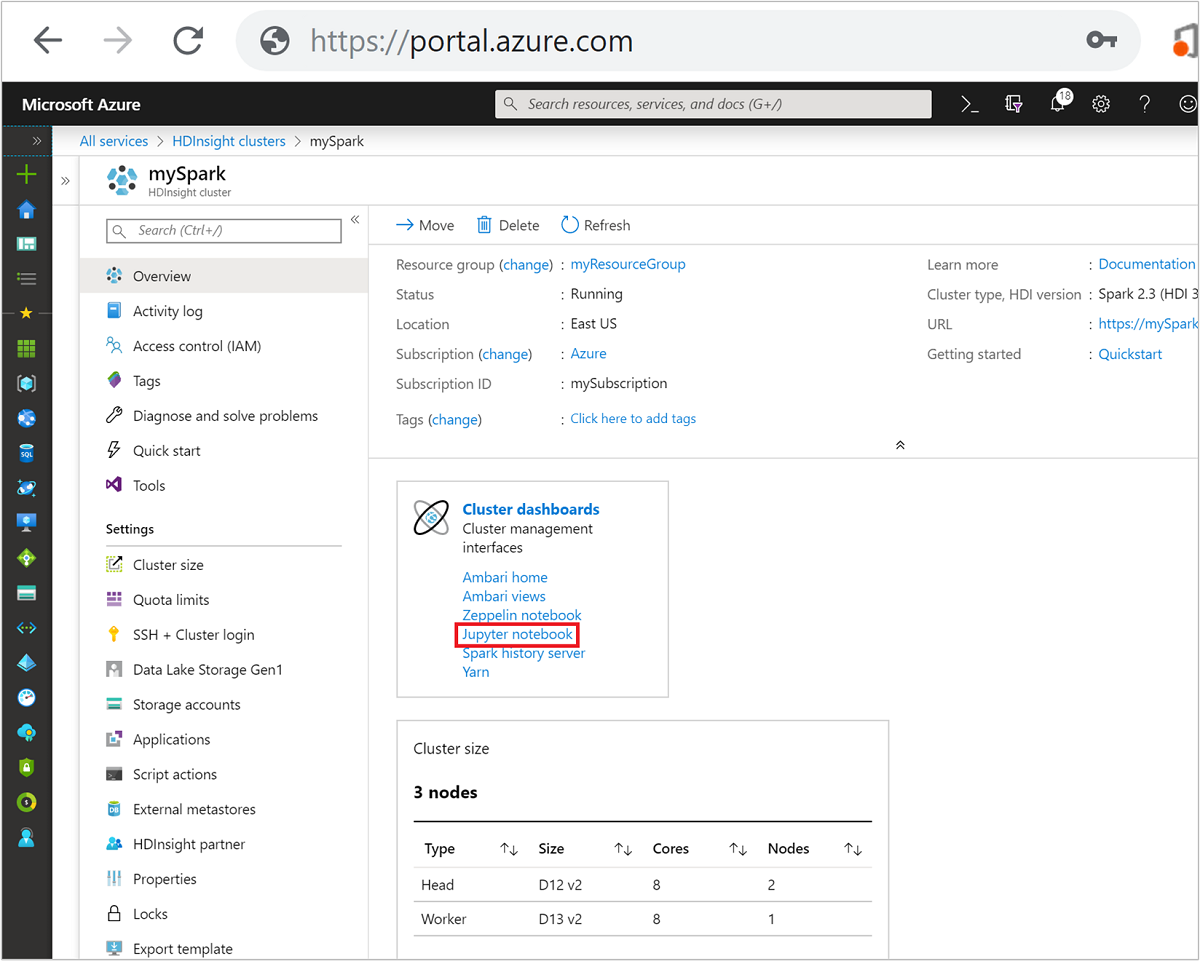
No portal do Azure, selecione seu cluster do Spark. Consulte Listar e mostrar clusters para obter as instruções. O modo de exibição Visão geral é aberto.
Na visualização Visão geral , na caixa Painéis de cluster, selecione Jupyter Notebook. Se lhe for solicitado, introduza as credenciais de administrador do cluster.
Nota
Você também pode acessar o Jupyter Notebook no cluster do Spark abrindo o seguinte URL no navegador. Substitua CLUSTERNAME pelo nome do cluster:
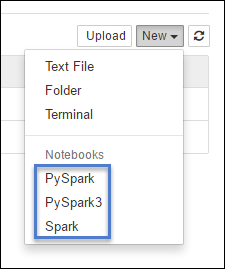
https://CLUSTERNAME.azurehdinsight.net/jupyterSelecione Novo e, em seguida, selecione Pyspark, PySpark3 ou Spark para criar um bloco de anotações. Use o kernel Spark para aplicativos Scala, o kernel PySpark para aplicativos Python2 e o kernel PySpark3 para aplicativos Python3.
Nota
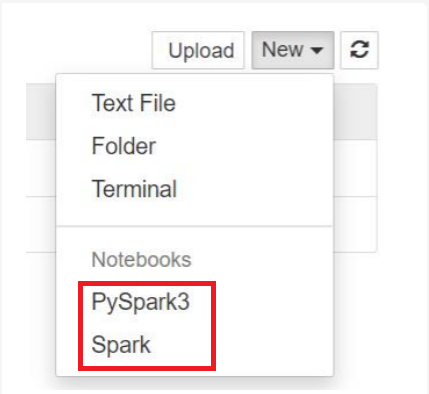
Para o Spark 3.1, apenas o PySpark3 ou o Spark estarão disponíveis.
- Um bloco de anotações é aberto com o kernel selecionado.
Benefícios do uso dos kernels
Aqui estão alguns benefícios de usar os novos kernels com o Jupyter Notebook em clusters Spark HDInsight.
Contextos predefinidos. Com o PySpark, o PySpark3 ou os kernels do Spark , você não precisa definir os contextos do Spark ou do Hive explicitamente antes de começar a trabalhar com seus aplicativos. Esses contextos estão disponíveis por padrão. Estes contextos são:
sc - para o contexto do Spark
sqlContext - para contexto Hive
Portanto, você não precisa executar instruções como as seguintes para definir os contextos:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)Em vez disso, você pode usar diretamente os contextos predefinidos em seu aplicativo.
Magias celulares. O kernel PySpark fornece algumas "magias" predefinidas, que são comandos especiais que você pode chamar (
%%por exemplo,%%MAGIC<args>). O comando magic deve ser a primeira palavra em uma célula de código e permitir várias linhas de conteúdo. A palavra mágica deve ser a primeira palavra na célula. Adicionar qualquer coisa antes da magia, até mesmo comentários, causa um erro. Para mais informações sobre magias, veja aqui.A tabela a seguir lista as diferentes magias disponíveis através dos kernels.
Magia Exemplo Description ajuda %%helpGera uma tabela de todas as magias disponíveis com exemplo e descrição informação %%infoSaídas de informações de sessão para o ponto de extremidade Livy atual configurar %%configure -f{"executorMemory": "1000M","executorCores": 4}Configura os parâmetros para criar uma sessão. O sinalizador de força ( -f) é obrigatório se uma sessão já tiver sido criada, o que garante que a sessão seja descartada e recriada. Veja o POST /sessions Request Body de Lívio para obter uma lista de parâmetros válidos. Os parâmetros devem ser passados como uma cadeia de caracteres JSON e devem estar na próxima linha após a mágica, como mostrado na coluna de exemplo.sql %%sql -o <variable name>
SHOW TABLESExecuta uma consulta do Hive em relação ao sqlContext. Se o -oparâmetro for passado, o resultado da consulta será persistido no contexto %%local Python como um dataframe Pandas .local %%locala=1Todo o código em linhas posteriores é executado localmente. O código deve ser um código Python2 válido, não importa qual kernel você esteja usando. Assim, mesmo se você selecionou kernels PySpark3 ou Spark ao criar o notebook, se você usar a %%localmagia em uma célula, essa célula só deve ter código Python2 válido.registos %%logsProduz os logs para a sessão Livy atual. delete %%delete -f -s <session number>Exclui uma sessão específica do ponto de extremidade Livy atual. Não é possível excluir a sessão iniciada para o kernel em si. limpeza %%cleanup -fExclui todas as sessões do ponto de extremidade Livy atual, incluindo a sessão deste bloco de anotações. A bandeira de força -f é obrigatória. Nota
Além das magias adicionadas pelo kernel PySpark, você também pode usar as magias IPython integradas, incluindo
%%sh. Você pode usar a%%shmagia para executar scripts e bloco de código no headnode do cluster.Visualização automática. O kernel do Pyspark visualiza automaticamente a saída de consultas Hive e SQL. Você pode escolher entre vários tipos diferentes de visualizações, incluindo Mesa, Tora, Linha, Área, Barra.
Parâmetros suportados com a mágica %%sql
A %%sql magia suporta diferentes parâmetros que você pode usar para controlar o tipo de saída que você recebe quando executa consultas. A tabela a seguir lista a saída.
| Parâmetro | Exemplo | Description |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Use este parâmetro para persistir o resultado da consulta, no contexto %%local Python, como um dataframe Pandas . O nome da variável dataframe é o nome da variável que você especificar. |
| -q | -q |
Use este parâmetro para desativar as visualizações da célula. Se você não quiser visualizar automaticamente o conteúdo de uma célula e quiser apenas capturá-lo como um dataframe, use -q -o <VARIABLE>. Se você quiser desativar visualizações sem capturar os resultados (por exemplo, para executar uma consulta SQL, como uma CREATE TABLE instrução), use -q sem especificar um -o argumento. |
| -m | -m <METHOD> |
Onde METHOD é colher ou amostra (o padrão é tomar). Se o método for take, o kernel selecionará elementos da parte superior do conjunto de dados de resultado especificado por MAXROWS (descrito posteriormente nesta tabela). Se o método for amostra, o kernel amostrará aleatoriamente os elementos do conjunto de dados de acordo com -r o parâmetro, descrito a seguir nesta tabela. |
| -r | -r <FRACTION> |
Aqui FRACTION é um número de vírgula flutuante entre 0,0 e 1,0. Se o método de exemplo para a consulta SQL for sample, o kernel amostrará aleatoriamente a fração especificada dos elementos do conjunto de resultados para você. Por exemplo, se você executar uma consulta SQL com os argumentos -m sample -r 0.01, 1% das linhas de resultados serão amostradas aleatoriamente. |
| -n | -n <MAXROWS> |
MAXROWS é um valor inteiro. O kernel limita o número de linhas de saída a MAXROWS. Se MAXROWS for um número negativo, como -1, o número de linhas no conjunto de resultados não será limitado. |
Exemplo:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
A declaração acima faz as seguintes ações:
- Seleciona todos os registros de hivesampletable.
- Como usamos -q, ele desativa a autovisualização.
- Como usamos
-m sample -r 0.1 -n 500o , ele coleta amostras aleatoriamente de 10% das linhas na tabela de amostragem e limita o tamanho do conjunto de resultados a 500 linhas. - Finalmente, porque nós usamos
-o query2ele também salva a saída em um dataframe chamado query2.
Considerações ao usar os novos kernels
Seja qual for o kernel usado, deixar os blocos de anotações em execução consome os recursos do cluster. Com esses kernels, como os contextos são predefinidos, simplesmente sair dos notebooks não mata o contexto. E assim os recursos do cluster continuam a ser usados. Uma boa prática é usar a opção Fechar e Parar no menu Arquivo do bloco de anotações quando terminar de usar o bloco de anotações. O fecho mata o contexto e, em seguida, sai do bloco de notas.
Onde estão armazenados os cadernos?
Se o cluster usar o Armazenamento do Azure como a conta de armazenamento padrão, os Blocos de Anotações Jupyter serão salvos na conta de armazenamento na pasta /HdiNotebooks . Blocos de anotações, arquivos de texto e pastas que você cria a partir do Jupyter podem ser acessados a partir da conta de armazenamento. Por exemplo, se você usar o Jupyter para criar uma pasta myfolder e um bloco de anotações myfolder/mynotebook.ipynb, poderá acessar esse bloco de anotações na /HdiNotebooks/myfolder/mynotebook.ipynb conta de armazenamento. O inverso também é verdadeiro, ou seja, se você carregar um notebook diretamente para sua conta de armazenamento no /HdiNotebooks/mynotebook1.ipynb, o notebook também estará visível no Jupyter. Os blocos de anotações permanecem na conta de armazenamento mesmo depois que o cluster é excluído.
Nota
Os clusters HDInsight com o Armazenamento Azure Data Lake como armazenamento padrão não armazenam blocos de anotações no armazenamento associado.
A forma como os blocos de notas são guardados na conta de armazenamento é compatível com o Apache Hadoop HDFS. Se você SSH no cluster, você pode usar os comandos de gerenciamento de arquivos:
| Comando | Description |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Liste tudo no diretório raiz – tudo neste diretório é visível para o Jupyter a partir da página inicial |
hdfs dfs –copyToLocal /HdiNotebooks |
# Baixe o conteúdo da pasta HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Carregue um bloco de anotações example.ipynb para a pasta raiz para que fique visível a partir do Jupyter |
Se o cluster usa o Armazenamento do Azure ou o Armazenamento do Azure Data Lake como a conta de armazenamento padrão, os blocos de anotações também são salvos no nó principal do cluster em /var/lib/jupyter.
Browser suportado
Os Notebooks Jupyter em clusters Spark HDInsight são compatíveis apenas com o Google Chrome.
Sugestões
Os novos kernels estão em fase de evolução e amadurecerão com o tempo. Assim, as APIs podem mudar à medida que esses kernels amadurecem. Gostaríamos de receber qualquer feedback que você tenha ao usar esses novos kernels. O feedback é útil para moldar a versão final desses kernels. Você pode deixar seus comentários/comentários na seção Comentários na parte inferior deste artigo.
Próximos passos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários