Pré-processar Texto
Este artigo descreve um componente no estruturador do Azure Machine Learning.
Utilize o componente Texto Pré-processamento para limpar e simplificar o texto. Suporta estas operações comuns de processamento de texto:
- Remoção de palavras de paragem
- Utilizar expressões regulares para procurar e substituir cadeias de destino específicas
- A lematização, que converte múltiplas palavras relacionadas numa única forma canónica
- Normalização de casos
- Remoção de determinadas classes de carateres, tais como números, carateres especiais e sequências de carateres repetidos, como "aaaa"
- Identificação e remoção de e-mails e URLs
Atualmente, o componente Texto Pré-processamento só suporta inglês.
Configurar Pré-processamento de Texto
Adicione o componente Texto pré-processamento ao pipeline no Azure Machine Learning. Pode encontrar este componente em Análise de Texto.
Ligue um conjunto de dados que tenha, pelo menos, uma coluna que contenha texto.
Selecione o idioma na lista pendente Idioma .
Coluna de texto a limpar: selecione a coluna que pretende pré-processar.
Remover palavras de paragem: selecione esta opção se quiser aplicar uma lista de palavras-passe predefinidas à coluna de texto.
As listas de palavras-passe são dependentes de idiomas e personalizáveis.
Lemmatização: selecione esta opção se quiser que as palavras sejam representadas na forma canónica. Esta opção é útil para reduzir o número de ocorrências exclusivas de tokens de texto semelhantes.
O processo de lemmatização é altamente dependente de linguagem.
Detetar frases: selecione esta opção se pretender que o componente insira uma marca de limite de frase ao efetuar uma análise.
Este componente utiliza uma série de três carateres
|||de pipe para representar o exterminador de frases.Executar operações opcionais de localizar e substituir com expressões regulares. A expressão regular será processada inicialmente, à frente de todas as outras opções incorporadas.
- Expressão regular personalizada: defina o texto que está a procurar.
- Cadeia de substituição personalizada: defina um único valor de substituição.
Normalizar maiúsculas/minúsculas: selecione esta opção se quiser converter carateres maiúsculos ASCII nos formulários em minúsculas.
Se os carateres não estiverem normalizados, a mesma palavra em letras maiúsculas e minúsculas é considerada duas palavras diferentes.
Também pode remover os seguintes tipos de carateres ou sequências de carateres do texto de saída processado:
Remover números: selecione esta opção para remover todos os carateres numéricos do idioma especificado. Os números de identificação são dependentes do domínio e do idioma dependente. Se os carateres numéricos forem parte integrante de uma palavra conhecida, o número poderá não ser removido. Saiba mais em Notas técnicas.
Remover carateres especiais: utilize esta opção para remover quaisquer carateres especiais não alfanuméricos.
Remover carateres duplicados: selecione esta opção para remover carateres adicionais em quaisquer sequências que se repitam mais do que duas vezes. Por exemplo, uma sequência como "aaaaa" seria reduzida a "aa".
Remover endereços de e-mail: selecione esta opção para remover qualquer sequência do formato
<string>@<string>.Remover URLs: selecione esta opção para remover qualquer sequência que inclua os seguintes prefixos de URL:
http,https, ,ftpwww
Expandir contrações verbos: esta opção aplica-se apenas a idiomas que utilizam contrações verbos; atualmente, apenas em inglês.
Por exemplo, ao selecionar esta opção, pode substituir a expressão "não ficaria aí" por "não ficaria lá".
Normalizar barras invertidas em barras: selecione esta opção para mapear todas as instâncias de
\\para/.Dividir tokens em carateres especiais: selecione esta opção se quiser quebrar palavras em carateres como
&,-e assim sucessivamente. Esta opção também pode reduzir os carateres especiais quando se repete mais do que duas vezes.Por exemplo, a cadeia
MS---WORDseria separada em três tokens,MS,-eWORD.Submeta o pipeline.
Notas técnicas
O componente de pré-processamento de texto no Studio(clássico) e o estruturador utilizam modelos de linguagem diferentes. O estruturador utiliza um modelo preparado para CNN de várias tarefas a partir de spaCy. Diferentes modelos dão um tokenizer diferente e um tagger de parte da voz, o que leva a resultados diferentes.
Seguem-se alguns exemplos:
| Configuração | Resultado de saída |
|---|---|
| Com todas as opções selecionadas Explicação: para os casos como "3test" no "WC-3 3test 4test", o estruturador remove toda a palavra "3test", uma vez que, neste contexto, o tagger de parte da voz especifica este token "3test" como numeral e, de acordo com a parte da voz, o componente remove-o. |
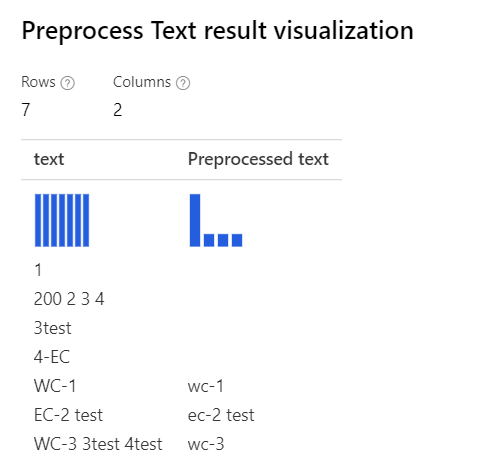
|
Com apenas Removing number a Explicação selecionada : para os casos como "3test", "4-EC", a dose de token do estruturador não divide estes casos e trata-os como tokens inteiros. Assim, não removerá os números nestas palavras. |

|
Também pode utilizar uma expressão regular para produzir resultados personalizados:
| Configuração | Resultado de saída |
|---|---|
| Com todas as opções selecionadas Expressão regular personalizada : (\s+)*(-|\d+)(\s+)*Cadeia de substituição personalizada: \1 \2 \3 |

|
Com apenas Removing number a expressão regular personalizada selecionada : (\s+)*(-|\d+)(\s+)*Cadeia de substituição personalizada: \1 \2 \3 |
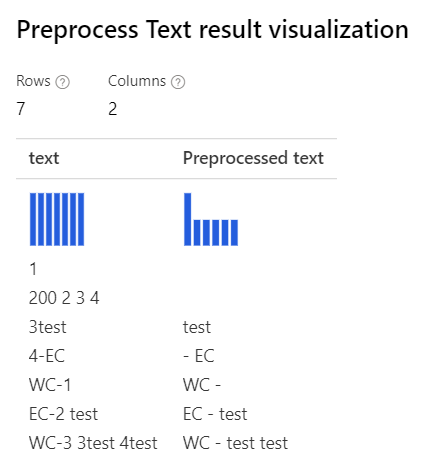
|
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.