Utilizar VMs de baixa prioridade em implementações em lotes
APLICA-SE A: Extensão v2 da CLI do Azure (atual)SDK python azure-ai-ml v2 (atual)
Extensão v2 da CLI do Azure (atual)SDK python azure-ai-ml v2 (atual)
Azure Batch Implementações suporta VMs de baixa prioridade para reduzir o custo das cargas de trabalho de inferência de lotes. As VMs de baixa prioridade permitem utilizar uma grande quantidade de poder de computação a um custo baixo. As VMs de baixa prioridade tiram partido da capacidade excedentária no Azure. Quando especifica VMs de baixa prioridade nos conjuntos, o Azure pode utilizar este excedente, quando disponível.
A desvantagem de utilizá-las é que essas VMs podem nem sempre estar disponíveis para serem alocadas ou podem ser impedidas em qualquer altura, dependendo da capacidade disponível. Por este motivo, são mais adequados para cargas de trabalho de processamento em lote e assíncronas em que o tempo de conclusão da tarefa é flexível e o trabalho é distribuído por muitas VMs.
As VMs de baixa prioridade são oferecidas a um preço significativamente reduzido em comparação com as VMs dedicadas. Para obter detalhes sobre os preços, veja Preços do Azure Machine Learning.
Como funciona a implementação em lotes com VMs de baixa prioridade
As Implementações do Batch do Azure Machine Learning fornecem várias capacidades que facilitam o consumo e beneficiam de VMs de baixa prioridade:
- As tarefas de implementação em lote consomem VMs de baixa prioridade ao executar em clusters de computação do Azure Machine Learning criados com VMs de baixa prioridade. Assim que uma implementação estiver associada a um cluster de VMs de baixa prioridade, todas as tarefas produzidas por essa implementação utilizarão VMs de baixa prioridade. A configuração por tarefa não é possível.
- As tarefas de implementação do Batch procuram automaticamente o número de VMs de destino no cluster de cálculo disponível com base no número de tarefas a submeter. Se as VMs estiverem preempidas ou indisponíveis, as tarefas de implementação em lote tentam substituir a capacidade perdida ao colocar em fila as tarefas falhadas no cluster.
- As VMs de baixa prioridade têm uma quota de vCPU separada que difere da das VMs dedicadas. Os núcleos de baixa prioridade por região têm um limite predefinido de 100 a 3,000, dependendo do tipo de oferta da subscrição. O número de núcleos de baixa prioridade por subscrição pode ser aumentado e é um valor único nas famílias de VM. Veja Quotas de computação do Azure Machine Learning.
Considerações e casos de utilização
Muitas cargas de trabalho em lote são uma boa opção para VMs de baixa prioridade. Embora isto possa introduzir novos atrasos de execução quando ocorre a desalocação de VMs, as potenciais reduções de capacidade podem ser toleradas em detrimento da execução com um custo mais baixo se houver flexibilidade no tempo que os trabalhos têm de concluir.
Ao implementar modelos em pontos finais de lote, o reagendamento pode ser feito ao nível do mini lote. Isto tem o benefício extra de que a desalocação só afeta os mini-lotes que estão atualmente a ser processados e não concluídos no nó afetado. Todos os progressos concluídos são mantidos.
Criar implementações em lote com VMs de baixa prioridade
As tarefas de implementação em lote consomem VMs de baixa prioridade ao executar em clusters de computação do Azure Machine Learning criados com VMs de baixa prioridade.
Nota
Assim que uma implementação estiver associada a um cluster de VMs de baixa prioridade, todas as tarefas produzidas por essa implementação utilizarão VMs de baixa prioridade. A configuração por tarefa não é possível.
Pode criar um cluster de computação do Azure Machine Learning de baixa prioridade da seguinte forma:
Crie uma definição YAML de computação como a seguinte:
low-pri-cluster.yml
$schema: https://azuremlschemas.azureedge.net/latest/amlCompute.schema.json
name: low-pri-cluster
type: amlcompute
size: STANDARD_DS3_v2
min_instances: 0
max_instances: 2
idle_time_before_scale_down: 120
tier: low_priority
Crie a computação com o seguinte comando:
az ml compute create -f low-pri-cluster.yml
Depois de criar a nova computação, pode criar ou atualizar a implementação para utilizar o novo cluster:
Para criar ou atualizar uma implementação no novo cluster de cálculo, crie uma YAML configuração semelhante à seguinte:
$schema: https://azuremlschemas.azureedge.net/latest/batchDeployment.schema.json
endpoint_name: heart-classifier-batch
name: classifier-xgboost
description: A heart condition classifier based on XGBoost
type: model
model: azureml:heart-classifier@latest
compute: azureml:low-pri-cluster
resources:
instance_count: 2
settings:
max_concurrency_per_instance: 2
mini_batch_size: 2
output_action: append_row
output_file_name: predictions.csv
retry_settings:
max_retries: 3
timeout: 300
Em seguida, crie a implementação com o seguinte comando:
az ml batch-endpoint create -f endpoint.yml
Ver e monitorizar a desalocação de nós
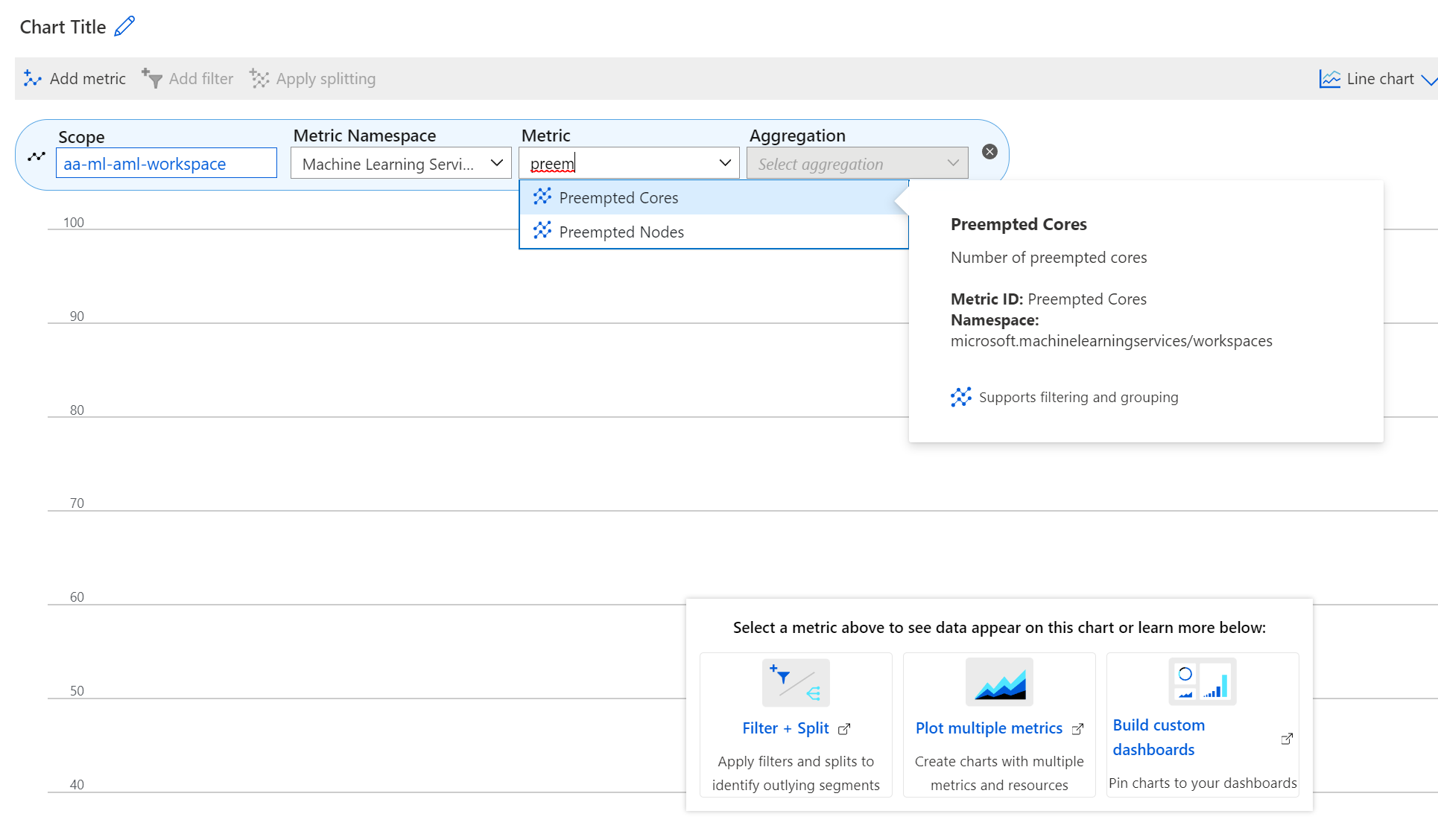
Estão disponíveis novas métricas no portal do Azure para VMs de baixa prioridade para monitorizar VMs de baixa prioridade. Estas métricas são:
- Nós preempidos
- Núcleos preempidos
Para ver estas métricas no portal do Azure
- Navegue para a área de trabalho do Azure Machine Learning no portal do Azure.
- Selecione Métricas na secção Monitorização .
- Selecione as métricas pretendidas na lista Métrica .
Limitações
- Assim que uma implementação estiver associada a um cluster de VMs de baixa prioridade, todas as tarefas produzidas por essa implementação utilizarão VMs de baixa prioridade. A configuração por tarefa não é possível.
- O reagendamento é feito ao nível do mini-lote, independentemente do progresso. Não é fornecida nenhuma capacidade de ponto de verificação.
Aviso
Nos casos em que todo o cluster é preempido (ou em execução num cluster de nó único), a tarefa será cancelada, uma vez que não existe capacidade disponível para ser executada. A reenviação será necessária neste caso.