Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
APLICA-SE A: Estúdio de Aprendizado de Máquina (clássico)
Estúdio de Aprendizado de Máquina (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Estúdio de ML (clássico) terminará a 31 de agosto de 2024. Recomendamos que faça a transição para o Azure Machine Learning até essa data.
A partir de 1 de dezembro de 2021, não poderá criar novos recursos do Estúdio de ML (clássico). Até 31 de agosto de 2024, pode continuar a utilizar os recursos existentes do Estúdio de ML (clássico).
- Consulte informações sobre como mover projetos de aprendizado de máquina do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do Estúdio de ML (clássico) está a ser descontinuada e poderá não ser atualizada no futuro.
Neste artigo, você cria um experimento de aprendizado de máquina no Machine Learning Studio (clássico) que prevê o preço de um carro com base em diferentes variáveis, como marca e especificações técnicas.
Se você é novo no aprendizado de máquina, a série de vídeos Data Science for Beginners é uma ótima introdução ao aprendizado de máquina usando linguagem e conceitos do dia a dia.
Este guia de início rápido segue o fluxo de trabalho padrão para um experimento:
- Criar um modelo
- Treinar o modelo
- Avaliar e testar o modelo
Obter os dados
A primeira coisa que você precisa no aprendizado de máquina são dados. Há vários conjuntos de dados de exemplo incluídos no Studio (clássico) que você pode usar ou importar dados de várias fontes. Para este exemplo, usaremos o conjunto de dados de exemplo, Dados de preço do automóvel (Bruto), incluído no seu espaço de trabalho. Este conjunto de dados inclui entradas para vários automóveis individuais, incluindo informações como a marca, o modelo, as especificações técnicas e o preço.
Gorjeta
Você pode encontrar uma cópia de trabalho do experimento a seguir na Galeria de IA do Azure. Vá para Seu primeiro experimento de ciência de dados - Previsão de preço de automóvel e clique em Abrir no Studio para baixar uma cópia do experimento em seu espaço de trabalho (clássico) do Machine Learning Studio.
Eis como obter o conjunto de dados na sua experimentação.
Crie um novo experimento clicando em +NOVO na parte inferior da janela do Estúdio de Aprendizado de Máquina (clássico). Selecione EXPERIMENTO>Experimento em Branco.
É dado um nome predefinido à experimentação, que pode ver na parte superior da tela. Selecione este texto e renomeie-o para algo significativo, por exemplo, Previsão de preço do automóvel. O nome não tem de ser exclusivo.
À esquerda da tela da experimentação existe uma paleta de conjuntos de dados e módulos. Digite automóvel na caixa Pesquisar na parte superior desta paleta para encontrar o conjunto de dados rotulado Dados de preço do automóvel (Bruto). Arraste este conjunto de dados para a tela da experimentação.
Para ver a aparência desses dados, clique na porta de saída na parte inferior do conjunto de dados do automóvel e selecione Visualizar.
Gorjeta
Os conjuntos de dados e os módulos têm portas de entrada e de saída, representadas por pequenos círculos. As portas de entrada estão em cima e as de saída estão em baixo. Para criar um fluxo de dados através da experimentação, ligue uma porta de saída de um módulo a uma porta de entrada de outro. Pode, em qualquer altura, clicar na porta de saída de um conjunto de dados ou de um módulo para ver o aspeto dos dados nessa fase do fluxo de dados.
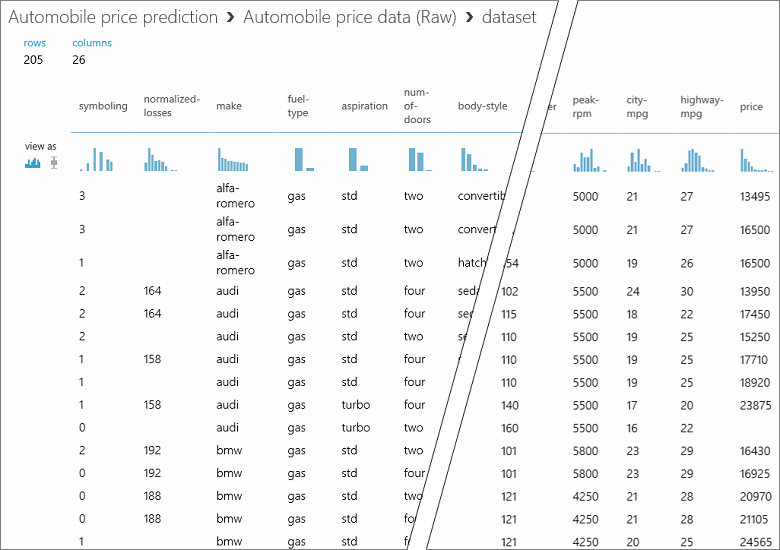
Neste conjunto de dados, cada linha representa um automóvel e as variáveis associadas a cada automóvel aparecem como colunas. Vamos prever o preço na coluna da extrema direita (coluna 26, intitulada "preço") usando as variáveis para um automóvel específico.
Feche a janela de visualização clicando no "x" no canto superior direito.
Preparar os dados
Normalmente, um conjunto de dados requer alguns pré-processamentos antes de poder ser analisado. Poderá ter reparado nos valores em falta presentes nas colunas de várias linhas. Estes valores em falta têm de ser apagados para que o modelo possa analisar os dados corretamente. Removeremos todas as linhas que tenham valores ausentes. Além disso, a coluna de perdas normalizadas tem uma grande proporção de valores ausentes, portanto, excluiremos essa coluna do modelo completamente.
Gorjeta
Apagar os valores em falta a partir dos dados de entrada é um pré-requisito para utilizar a maioria dos módulos.
Primeiro, adicionamos um módulo que remove completamente a coluna de perdas normalizadas . Em seguida, adicionamos outro módulo que remove qualquer linha que tenha dados ausentes.
Digite selecionar colunas na caixa de pesquisa na parte superior da paleta de módulos para localizar o módulo Selecionar colunas no conjunto de dados . Em seguida, arraste-o para a tela do experimento. Este módulo permite-nos selecionar quais as colunas de dados que pretendemos incluir ou excluir no modelo.
Conecte a porta de saída do conjunto de dados Automobile price data (Raw) à porta de entrada do módulo Selecionar Colunas no Conjunto de Dados.
Clique no módulo Selecionar Colunas no Conjunto de Dados e clique em Iniciar seletor de colunas no painel Propriedades .
À esquerda, clique em Com regras
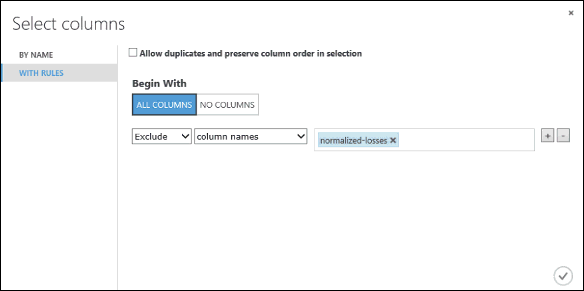
Em Começar com, clique em Todas as colunas. Essas regras direcionam Selecionar Colunas no Conjunto de Dados para passar por todas as colunas (exceto as colunas que estamos prestes a excluir).
Nas listas suspensas, selecione Excluir e nomes de colunas, e depois clique dentro da caixa de texto. É apresentada uma lista de colunas. Selecione Perdas normalizadas, e é adicionado à caixa de texto.
Clique no botão de marca de seleção (OK) para fechar o seletor de coluna (no canto inferior direito).
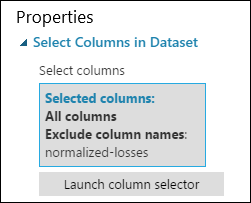
Agora, o painel de propriedades para Selecionar Colunas no Conjunto de Dados indica que ele passará por todas as colunas do conjunto de dados, exceto as perdas normalizadas.
Gorjeta
Pode adicionar um comentário a um módulo, fazendo duplo clique no módulo e introduzindo o texto. Isto pode ajudá-lo a ver rapidamente o que o módulo está a fazer na sua experimentação. Nesse caso, clique duas vezes no módulo Selecionar colunas no conjunto de dados e digite o comentário "Excluir perdas normalizadas".
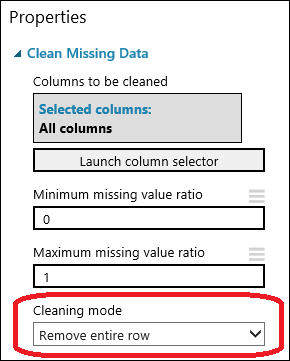
Arraste o módulo Limpar Dados Ausentes para a tela do experimento e conecte-o ao módulo Selecionar Colunas no Conjunto de Dados . No painel Propriedades , selecione Remover linha inteira em Modo de limpeza. Essas opções direcionam Limpar dados ausentes para limpar os dados removendo linhas que tenham quaisquer valores ausentes. Clique duas vezes no módulo e escreva o comentário "Remover linhas de valor em falta".
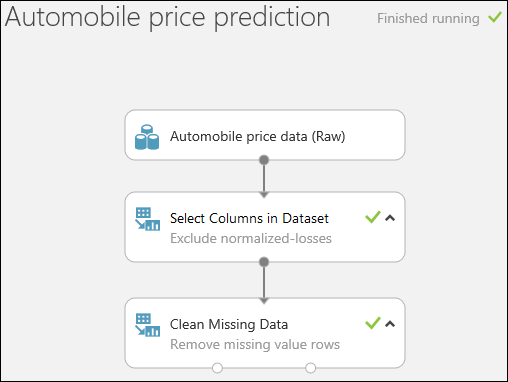
Execute a experiência clicando em EXECUTAR na parte inferior da página.
Quando a execução da experimentação estiver concluída, todos os módulos têm uma marca de verificação a verde para indicar que foram concluídos com êxito. Observe também o status Execução concluída no canto superior direito.
Gorjeta
Porque é que executámos a experimentação agora? Ao executar o experimento, as definições de coluna para nossos dados passam do conjunto de dados, através do módulo Selecionar colunas no conjunto de dados e através do módulo Limpar dados ausentes . Isso significa que todos os módulos que conectamos ao Clean Missing Data também terão essas mesmas informações.
Agora temos dados limpos. Se quiser visualizar o conjunto de dados limpo, clique na porta de saída esquerda do módulo Limpar dados ausentes e selecione Visualizar. Observe que a coluna de perdas normalizadas não está mais incluída e não há valores ausentes.
Agora que os dados foram apagados, estamos prontos para especificar quais as funcionalidades que vai utilizar no modelo preditivo.
Definir recursos
No aprendizado de máquina, os recursos são propriedades mensuráveis individuais de algo em que você está interessado. No nosso conjunto de dados, cada linha representa um automóvel e cada coluna é uma funcionalidade desse automóvel.
Encontrar um bom conjunto de funcionalidades para criar um modelo preditivo requer experimentação e conhecimentos sobre o problema que pretende resolver. Algumas funcionalidades são melhores para prever num destino do que outras. Alguns recursos têm uma forte correlação com outros recursos e podem ser removidos. Por exemplo, city-mpg e highway-mpg estão intimamente relacionados, pelo que podemos manter um e remover o outro sem afetar a predição significativamente.
Vamos criar um modelo que utiliza um subconjunto das funcionalidades no nosso conjunto de dados. Pode regressar mais tarde e selecionar funcionalidades diferentes, executar novamente a experimentação e ver se consegue obter melhores resultados. Contudo, para começar, vamos experimentar as seguintes funcionalidades:
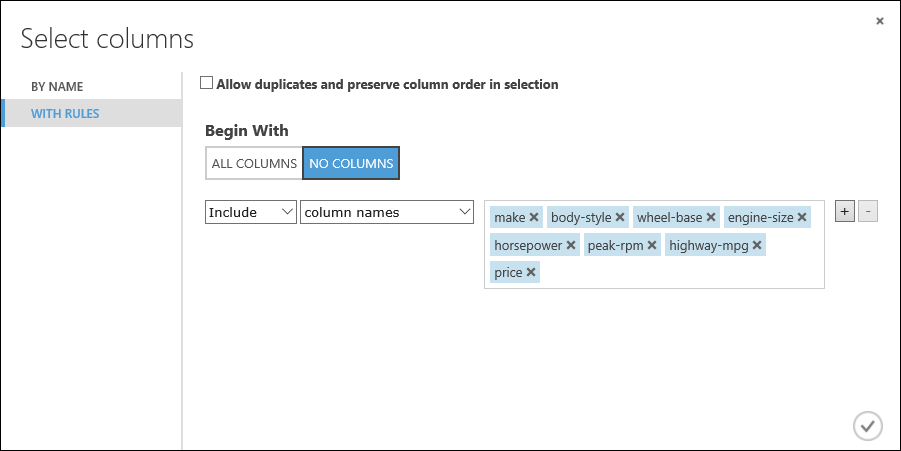
marca, carroçaria, distância entre eixos, tamanho do motor, potência, pico-rpm, auto-estrada-mpg, preço
Arraste outro módulo Selecionar Colunas no Conjunto de Dados para a tela do experimento. Conecte a porta de saída esquerda do módulo Limpar dados ausentes à entrada do módulo Selecionar colunas no conjunto de dados .
Clique duas vezes no módulo e escreva "Selecionar as funcionalidades para predição".
Clique em Lançar seletor de colunas no painel Propriedades.
Clique em Com regras.
Em Começar com, clique em Sem colunas. Na linha de filtro, selecione Incluir e nomes de colunas e selecione nossa lista de nomes de colunas na caixa de texto. Este filtro direciona o módulo para não passar por nenhuma coluna (recursos), exceto as que especificamos.
Clique no botão de marca de verificação (OK).
Este módulo produz um conjunto de dados filtrado contendo apenas os recursos que queremos passar para o algoritmo de aprendizagem que usaremos na próxima etapa. Mais tarde, pode voltar e tentar novamente com uma seleção de funcionalidades diferente.
Escolher e aplicar um algoritmo
Agora que os dados estão prontos, construir um modelo preditivo consiste em formar e testar. Utilizaremos os nossos dados para preparar o modelo e, em seguida, vamos testá-lo para ver com que exatidão consegue prever os preços.
Classificação e regressão são dois tipos de algoritmos supervisionados de aprendizado de máquina. A classificação prevê uma resposta a partir de um conjunto definido de categorias, tais como uma cor (vermelho, azul ou verde). A regressão é utilizada para prever um número.
Uma vez que queremos prever o preço, que é um número, vamos utilizar um algoritmo de regressão. Para este exemplo, usaremos um modelo de regressão linear .
Para preparar o modelo, damos-lhe um conjunto de dados que incluem o preço. O modelo analisa os dados e procura correlações entre as características e o preço de um automóvel. Depois, testamos o modelo. Damos-lhe um conjunto de características de automóveis com que estamos familiarizados e vemos a exatidão com que o modelo consegue prever o preço sabido.
Vamos utilizar os dados quer para preparar o modelo, quer para testá-lo, dividindo-os em conjuntos de dados de preparação e teste separados.
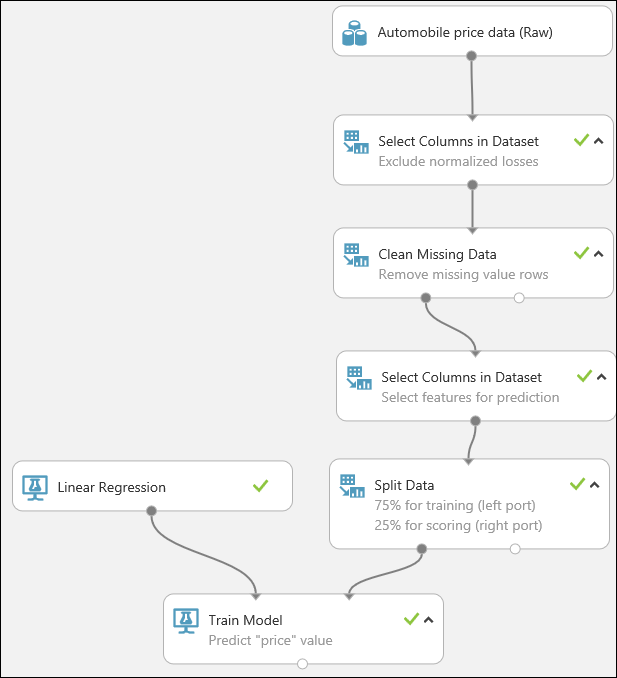
Selecione e arraste o módulo Split Data para a tela do experimento e conecte-o ao último módulo Select Columns in Dataset .
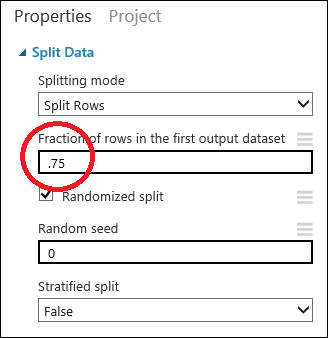
Clique no módulo Dividir dados para selecioná-lo. Localize a Fração de linhas no primeiro conjunto de dados de saída (no painel Propriedades à direita da tela) e defina-a como 0,75. Desta forma, vamos utilizar 75% dos dados para preparar o modelo e retenha 25% para fins de teste.
Gorjeta
Ao alterar o parâmetro Random seed , você pode produzir diferentes amostras aleatórias para treinamento e teste. Este parâmetro controla a propagação do gerador de número pseudo-aleatório.
Execute a experimentação. Quando o experimento é executado, os módulos Selecionar Colunas no Conjunto de Dados e Dados Divididos passam as definições de coluna para os módulos que adicionaremos a seguir.
Para selecionar o algoritmo de aprendizagem, expanda a categoria Aprendizado de Máquina na paleta de módulos à esquerda da tela e expanda Inicializar Modelo. Isto apresenta várias categorias de módulos que podem ser utilizadas para inicializar algoritmos do Machine Learning. Para este experimento, selecione o módulo Regressão Linear na categoria Regressão e arraste-o para a tela do experimento. (Para encontrar o módulo, também pode escrever “linear regression” na caixa Pesquisa da paleta.)
Localize e arraste o módulo Train Model para a tela do experimento. Conecte a saída do módulo de Regressão Linear à entrada esquerda do módulo Train Model e conecte a saída de dados de treinamento (porta esquerda) do módulo Split Data à entrada direita do módulo Train Model .
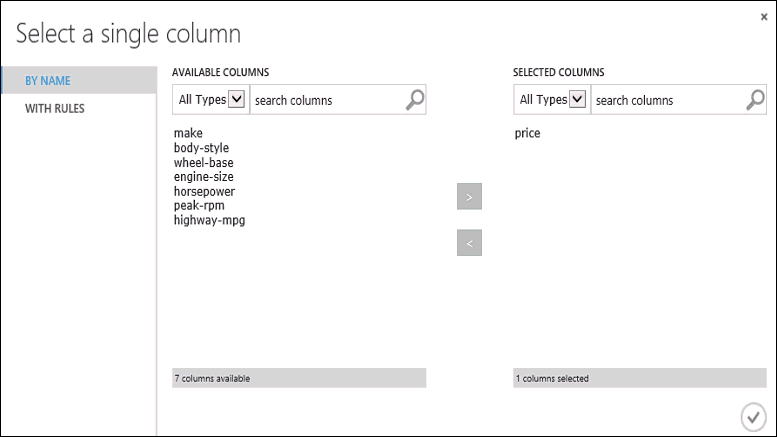
Clique no módulo Modelo de trem , clique em Iniciar seletor de coluna no painel Propriedades e selecione a coluna de preço . Preço é o valor que o nosso modelo vai prever.
Selecione a coluna de preço no seletor de colunas movendo-a da lista Colunas disponíveis para a lista Colunas selecionadas .
Execute a experimentação.
Temos agora um modelo de regressão preparado que pode ser utilizado para classificar dados de automóveis novos e fazer predições de preços.
Prever novos preços de automóveis
Agora que experimentámos o modelo, utilizando 75% dos nossos dados, podemos utilizá-lo para pontuar os outros 25% por cento dos dados para ver quão bem funciona o nosso modelo.
Localize e arraste o módulo Modelo de pontuação para a tela do experimento. Conecte a saída do módulo Train Model à porta de entrada esquerda do Score Model. Conecte a saída de dados de teste (porta direita) do módulo Split Data à porta de entrada direita do Score Model.
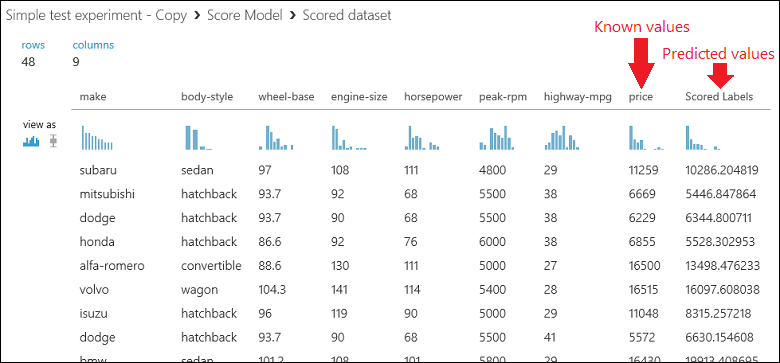
Execute o experimento e visualize a saída do módulo Score Model clicando na porta de saída do Score Model e selecione Visualizar. O resultado mostra os valores previstos para os preços e os valores conhecidos dos dados do teste.
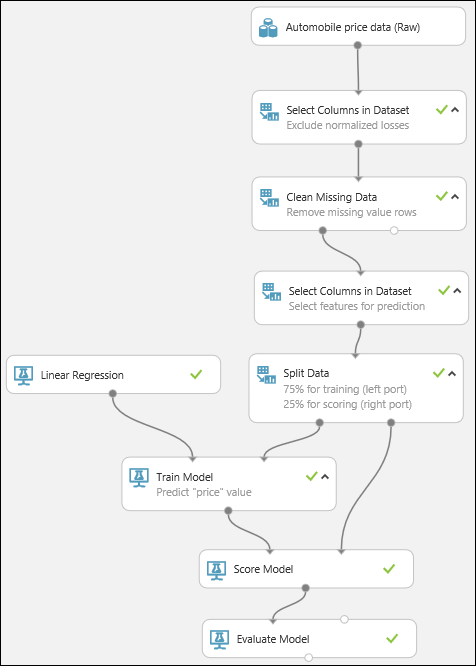
Por fim, vamos testar a qualidade dos resultados. Selecione e arraste o módulo Avaliar Modelo para a tela do experimento e conecte a saída do módulo Modelo de Pontuação à entrada esquerda de Avaliar Modelo. A experimentação final deve ter este aspeto:
Execute a experimentação.
Para exibir a saída do módulo Avaliar modelo , clique na porta de saída e selecione Visualizar.
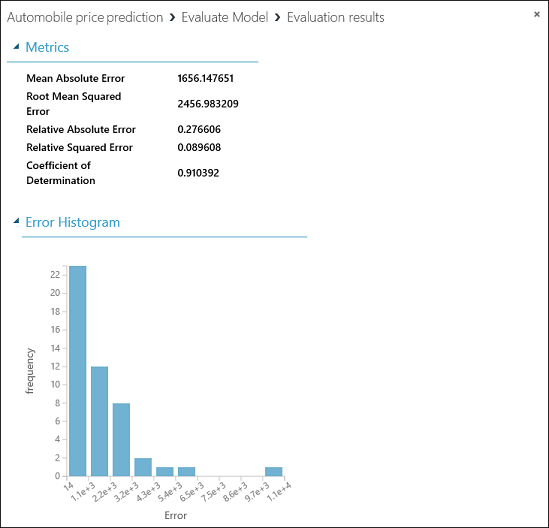
As estatísticas seguintes são apresentadas para o nosso modelo:
- Erro Absoluto Médio (MAE): A média dos erros absolutos (um erro é a diferença entre o valor previsto e o valor real).
- Erro quadrático médio da raiz (RMSE): A raiz quadrada da média de erros quadrados das previsões feitas no conjunto de dados de teste.
- Erro Absoluto Relativo: A média dos erros absolutos em relação à diferença absoluta entre os valores reais e a média de todos os valores reais.
- Erro Quadrado Relativo: A média dos erros quadrados em relação à diferença ao quadrado entre os valores reais e a média de todos os valores reais.
- Coeficiente de Determinação: Também conhecido como valor R quadrado, esta é uma métrica estatística que indica quão bem um modelo se ajusta aos dados.
Em cada uma das estatísticas de erros, quanto mais pequeno, melhor. Um valor mais pequeno indica que as predições mais detalhadas correspondem aos valores reais. Para o Coeficiente de Determinação, quanto mais próximo de um (1,0), melhores serão as previsões.
Clean up resources (Limpar recursos)
Se você não precisar mais dos recursos que criou usando este artigo, exclua-os para evitar incorrer em cobranças. Saiba como no artigo, Exportar e excluir dados do usuário no produto.
Próximos passos
Neste início rápido, você criou um experimento simples usando um conjunto de dados de exemplo. Para explorar o processo de criação e implantação de um modelo com mais profundidade, continue para o tutorial da solução preditiva.