Executar componente de Script R
Este artigo descreve como utilizar o componente Executar Script R para executar código R no pipeline do estruturador do Azure Machine Learning.
Com o R, pode realizar tarefas que não são suportadas por componentes existentes, tais como:
- Criar transformações de dados personalizadas
- Utilizar as suas próprias métricas para avaliar predições
- Criar modelos com algoritmos que não são implementados como componentes autónomos no estruturador
Suporte da versão R
O estruturador do Azure Machine Learning utiliza a distribuição CRAN (Rede de Arquivo R Abrangente) de R. A versão atualmente utilizada é CRAN 3.5.1.
Supported R packages (Pacotes R suportados)
O ambiente R está pré-instalado com mais de 100 pacotes. Para obter uma lista completa, veja a secção Pacotes R pré-instalados.
Também pode adicionar o seguinte código a qualquer componente Execute R Script para ver os pacotes instalados.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Se o pipeline contiver vários componentes Execute R Script que necessitem de pacotes que não estejam na lista pré-instalada, instale os pacotes em cada componente.
Instalar pacotes R
Para instalar pacotes R adicionais, utilize o install.packages() método . Os pacotes são instalados para cada componente Execute R Script. Não são partilhados entre outros componentes executar Script R.
Nota
NÃO é recomendado instalar o pacote R a partir do pacote de script. É recomendado instalar pacotes diretamente no editor de scripts.
Especifique o repositório CRAN quando estiver a instalar pacotes, como install.packages("zoo",repos = "https://cloud.r-project.org").
Aviso
O componente Excute R Script não suporta a instalação de pacotes que requerem compilação nativa, como qdap o pacote que requer JAVA e drc pacote que requer C++. Isto acontece porque este componente é executado num ambiente pré-instalado com permissão de não administrador.
Não instale pacotes pré-criados no/para Windows, uma vez que os componentes do estruturador estão a ser executados no Ubuntu. Para verificar se um pacote está pré-criado nas janelas, pode aceder ao CRAN e procurar no seu pacote, transferir um ficheiro binário de acordo com o so e verificar a parte Built: no ficheiro DESCRIPTION . Segue-se um exemplo: 
Este exemplo mostra como instalar o Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Nota
Antes de instalar um pacote, verifique se já existe para não repetir uma instalação. Repetir instalações pode fazer com que os pedidos de serviço Web excedam o tempo limite.
Acesso ao conjunto de dados registado
Pode consultar o seguinte código de exemplo para aceder aos conjuntos de dados registados na área de trabalho:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Como configurar Executar Script R
O componente Executar Script R contém código de exemplo como ponto de partida.
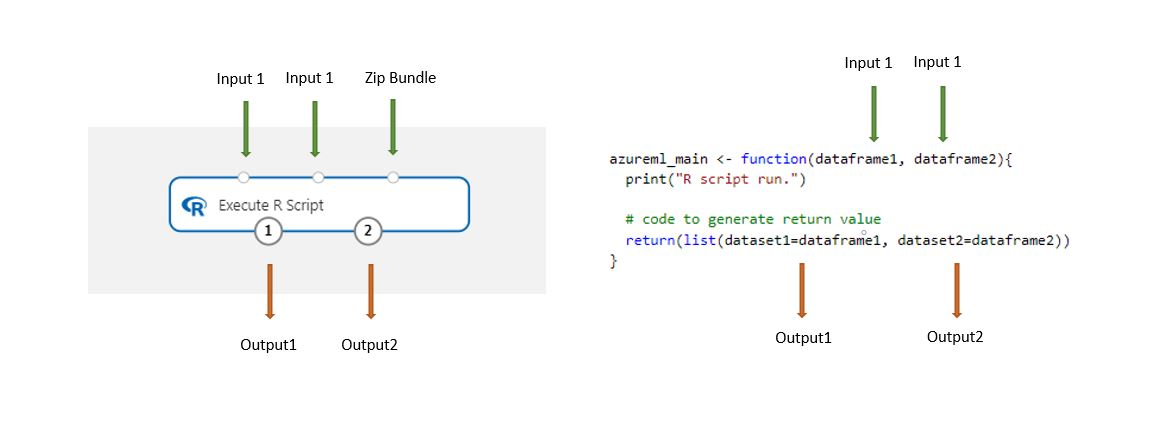
Os conjuntos de dados armazenados no estruturador são convertidos automaticamente num pacote de dados R quando carregados com este componente.
Adicione o componente Executar Script R ao pipeline.
Ligue as entradas de que o script precisa. As entradas são opcionais e podem incluir dados e código R adicional.
Conjunto de dados1: referencie a primeira entrada como
dataframe1. O conjunto de dados de entrada tem de ser formatado como um ficheiro CSV, TSV ou ARFF. Em alternativa, pode ligar um conjunto de dados do Azure Machine Learning.Conjunto de dados2: referencie a segunda entrada como
dataframe2. Este conjunto de dados também tem de ser formatado como um ficheiro CSV, TSV ou ARFF ou como um conjunto de dados do Azure Machine Learning.Pacote de Script: a terceira entrada aceita .zip ficheiros. Um ficheiro zipado pode conter vários ficheiros e vários tipos de ficheiro.
Na caixa de texto script R , escreva ou cole script R válido.
Nota
Tenha cuidado ao escrever o script. Confirme que não existem erros de sintaxe, como utilizar variáveis não declaradas ou componentes ou funções não suportados. Preste atenção à lista de pacotes pré-instaladas no final deste artigo. Para utilizar pacotes que não estão listados, instale-os no script. Um exemplo é
install.packages("zoo",repos = "https://cloud.r-project.org").Para o ajudar a começar, a caixa de texto Script R é pré-preenchida com código de exemplo, que pode editar ou substituir.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }A função de ponto de entrada tem de ter os argumentos
Param<dataframe1>de entrada eParam<dataframe2>, mesmo quando estes argumentos não são utilizados na função.Nota
Os dados transmitidos ao componente Executar Script R são referenciados como
dataframe1edataframe2, que são diferentes do estruturador do Azure Machine Learning (a referência do estruturador comodataset1,dataset2). Certifique-se de que os dados de entrada são referenciados corretamente no script.Nota
O código R existente pode precisar de pequenas alterações para ser executado num pipeline de estruturador. Por exemplo, os dados de entrada fornecidos no formato CSV devem ser explicitamente convertidos num conjunto de dados antes de poder utilizá-lo no seu código. Os tipos de dados e colunas utilizados na linguagem R também diferem de algumas formas dos tipos de dados e colunas utilizados no estruturador.
Se o script for superior a 16 KB, utilize a porta Pacote de Scripts para evitar erros como CommandLine exceder o limite de 16597 carateres.
- Agrupe o script e outros recursos personalizados a um ficheiro zip.
- Carregue o ficheiro zip como um Conjunto de Dados de Ficheiros para o estúdio.
- Arraste o componente do conjunto de dados da lista Conjuntos de dados no painel de componentes esquerdo na página de criação do estruturador.
- Ligue o componente do conjunto de dados à porta do Pacote de Scripts do componente Executar Script R .
Segue-se o código de exemplo para consumir o script no pacote de scripts:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Em Sementes Aleatórias, introduza um valor a utilizar dentro do ambiente R como o valor de seed aleatório. Este parâmetro é equivalente a chamar
set.seed(value)no código R.Submeta o pipeline.
Resultados
Os componentes Executar Script R podem devolver várias saídas, mas têm de ser fornecidos como fotogramas de dados R. O estruturador converte automaticamente os pacotes de dados em conjuntos de dados para compatibilidade com outros componentes.
As mensagens padrão e os erros do R são devolvidos ao registo do componente.
Se precisar de imprimir resultados no script R, pode encontrar os resultados impressos em 70_driver_log no separador Saídas+registos no painel direito do componente.
Scripts de exemplo
Existem várias formas de expandir o pipeline com scripts R personalizados. Esta secção fornece código de exemplo para tarefas comuns.
Adicionar um script R como entrada
O componente Executar Script R suporta ficheiros de script R arbitrários como entradas. Para utilizá-las, tem de carregá-las para a área de trabalho como parte do ficheiro de .zip.
Para carregar um ficheiro .zip que contém código R para a área de trabalho, aceda à página Recursos de conjuntos de dados . Selecione Criar conjunto de dados e, em seguida, selecione A partir do ficheiro local e a opção Tipo de conjunto de dados de ficheiros .
Verifique se o ficheiro zipado aparece em Os Meus Conjuntos de Dados na categoria Conjuntos de Dados na árvore de componentes à esquerda.
Ligue o conjunto de dados à porta de entrada Do Pacote de Scripts .
Todos os ficheiros no ficheiro .zip estão disponíveis durante o tempo de execução do pipeline.
Se o ficheiro do pacote de scripts contiver uma estrutura de diretório, a estrutura será preservada. Mas tem de alterar o código para preparar o conjunto de scripts ./Script para o caminho.
Processar dados
O exemplo seguinte mostra como dimensionar e normalizar os dados de entrada:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Ler um ficheiro de .zip como entrada
Este exemplo mostra como utilizar um conjunto de dados num ficheiro .zip como entrada para o componente Executar Script R.
- Crie o ficheiro de dados no formato CSV e dê-lhe o nomemydatafile.csv.
- Crie um ficheiro .zip e adicione o ficheiro CSV ao arquivo.
- Carregue o ficheiro zipado para a área de trabalho do Azure Machine Learning.
- Ligue o conjunto de dados resultante à entrada ScriptBundle do componente Execute R Script .
- Utilize o seguinte código para ler os dados CSV do ficheiro zipado.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replicar linhas
Este exemplo mostra como replicar registos positivos num conjunto de dados para equilibrar o exemplo:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Transmitir objetos R entre componentes Executar Script R
Pode transmitir objetos R entre instâncias do componente Executar Script R com o mecanismo de serialização interna. Este exemplo pressupõe que pretende mover o objeto R com o nome A entre dois componentes Executar Script R.
Adicione o primeiro componente Execute R Script ao pipeline. Em seguida, introduza o seguinte código na caixa de texto Script R para criar um objeto
Aserializado como uma coluna na tabela de dados de saída do componente:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }A conversão explícita para o tipo de número inteiro é feita porque a função de serialização produz dados no formato R
Raw, o que o estruturador não suporta.Adicione uma segunda instância do componente Execute R Script e ligue-a à porta de saída do componente anterior.
Escreva o seguinte código na caixa de texto Script R para extrair o objeto
Ada tabela de dados de entrada.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Pacotes R pré-instalados
Os seguintes pacotes R pré-instalados estão atualmente disponíveis:
| Pacote | Versão |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| acento circunflexo | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| classe | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| conjuntos de dados | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| genéricos | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| gráficos | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matriz | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0.8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários