Extrair Funcionalidades de N-Grama da referência de componentes de Texto
Este artigo descreve um componente no estruturador do Azure Machine Learning. Utilize o componente Extrair Funcionalidades de N-Grama do Texto para apresentar dados de texto não estruturados.
Configuração do componente Extrair Funcionalidades de N-Grama do Texto
O componente suporta os seguintes cenários para utilizar um dicionário de n gramas:
Crie um novo dicionário n-grama a partir de uma coluna de texto livre.
Utilize um conjunto existente de funcionalidades de texto para apresentar uma coluna de texto livre.
Classificar ou implementar um modelo que utilize n-gramas.
Criar um novo dicionário n-grama
Adicione o componente Extrair Funcionalidades de N-Grama do Texto ao pipeline e ligue o conjunto de dados que tem o texto que pretende processar.
Utilize a coluna Texto para escolher uma coluna do tipo de cadeia que contém o texto que pretende extrair. Uma vez que os resultados são verbosos, só pode processar uma única coluna de cada vez.
Defina o modo vocabulário como Criar para indicar que está a criar uma nova lista de funcionalidades de n gramas.
Defina o tamanho de N-Gramas para indicar o tamanho máximo dos n-gramas a extrair e armazenar.
Por exemplo, se introduzir 3, serão criados unigramas, bigrams e trigramas.
A função de ponderação especifica como criar o vetor de funcionalidades do documento e como extrair vocabulário de documentos.
Peso Binário: atribui um valor de presença binária aos n-gramas extraídos. O valor de cada n-grama é 1 quando existe no documento e 0 de outra forma.
Peso TF: atribui uma classificação de frequência de termo (TF) aos n-gramas extraídos. O valor de cada n-grama é a frequência de ocorrência no documento.
Peso do IDF: atribui uma classificação inversa da frequência do documento (IDF) aos n-gramas extraídos. O valor para cada n-grama é o registo do tamanho do corpus dividido pela respetiva frequência de ocorrência em todo o corpus.
IDF = log of corpus_size / document_frequencyPeso TF-IDF: atribui uma classificação de frequência/frequência inversa de documentos (TF/IDF) aos n-gramas extraídos. O valor para cada n-grama é a classificação de TF multiplicada pela respetiva classificação de IDF.
Defina Comprimento mínimo da palavra para o número mínimo de letras que podem ser utilizadas em qualquer palavra num n-grama.
Utilize o Comprimento máximo da palavra para definir o número máximo de letras que podem ser utilizadas em qualquer palavra num n-grama.
Por predefinição, são permitidos até 25 carateres por palavra ou token.
Utilize a frequência absoluta mínima do documento de n gramas para definir as ocorrências mínimas necessárias para que quaisquer n-gramas sejam incluídas no dicionário n-grama.
Por exemplo, se utilizar o valor predefinido de 5, qualquer n-grama tem de aparecer pelo menos cinco vezes no corpus para ser incluído no dicionário n-grama.
Defina a proporção máxima de documentos n-gramas para a proporção máxima do número de linhas que contêm um determinado n-grama, em relação ao número de linhas no corpus geral.
Por exemplo, uma proporção de 1 indicaria que, mesmo que um n-grama específico esteja presente em cada linha, o n-grama pode ser adicionado ao dicionário n-grama. Normalmente, uma palavra que ocorre em cada linha seria considerada uma palavra de ruído e seria removida. Para filtrar palavras irrelevantes dependentes do domínio, experimente reduzir esta proporção.
Importante
A taxa de ocorrência de palavras específicas não é uniforme. Varia de documento para documento. Por exemplo, se estiver a analisar comentários de clientes sobre um produto específico, o nome do produto poderá ser muito frequente e próximo de uma palavra de ruído, mas ser um termo significativo noutros contextos.
Selecione a opção Normalizar vetores de funcionalidades de n gramas para normalizar os vetores de funcionalidades. Se esta opção estiver ativada, cada vetor de funcionalidade de n gramas é dividido pela respetiva norma L2.
Submeta o pipeline.
Utilizar um dicionário n-grama existente
Adicione o componente Extrair Funcionalidades de N-Grama do Texto ao pipeline e ligue o conjunto de dados que tem o texto que pretende processar à porta do Conjunto de Dados .
Utilize a coluna Texto para selecionar a coluna de texto que contém o texto que pretende apresentar. Por predefinição, o componente seleciona todas as colunas do tipo cadeia. Para obter os melhores resultados, processe uma única coluna de cada vez.
Adicione o conjunto de dados guardado que contém um dicionário n-gram gerado anteriormente e ligue-o à porta vocabulário de entrada . Também pode ligar o resultado do vocabulário de uma instância a montante do componente Extrair Funcionalidades de N-Grama do Texto.
Para o modo vocabulário, selecione a opção ReadOnly update na lista pendente.
A opção ReadOnly representa o corpus de entrada para o vocabulário de entrada. Em vez de calcular frequências de termos do novo conjunto de dados de texto (na entrada esquerda), os pesos n-gramas do vocabulário de entrada são aplicados tal como estão.
Dica
Utilize esta opção quando estiver a classificar um classificador de texto.
Para todas as outras opções, veja as descrições de propriedades na secção anterior.
Submeta o pipeline.
Criar um pipeline de inferência que utiliza n gramas para implementar um ponto final em tempo real
Um pipeline de preparação que contém Extrair Funcionalidade de N-Gramas do Texto e Modelo de Classificação para fazer predições no conjunto de dados de teste é incorporado na seguinte estrutura:
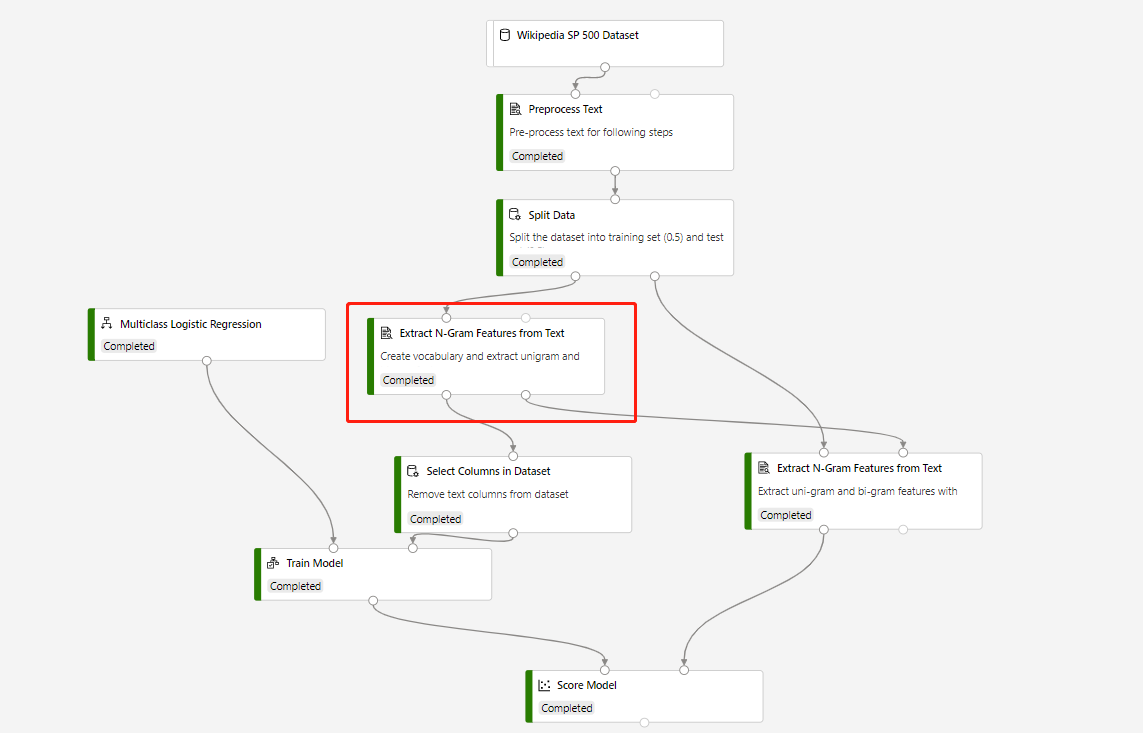
O modo vocabulário do componente Extração de N-Gramas de Texto em círculo é Criar e o modo vocabulário do componente que se liga ao componente Score Model é ReadOnly.
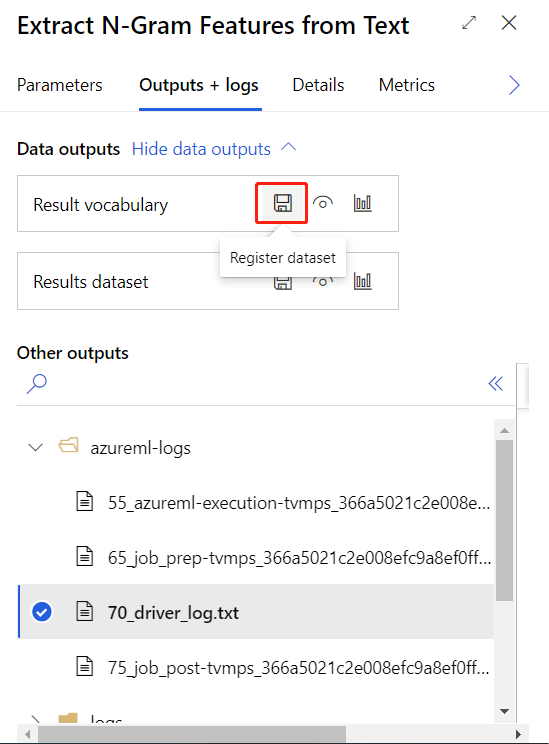
Depois de submeter o pipeline de preparação acima com êxito, pode registar a saída do componente em círculo como conjunto de dados.
Em seguida, pode criar um pipeline de inferência em tempo real. Depois de criar o pipeline de inferência, tem de ajustar manualmente o pipeline de inferência da seguinte forma:
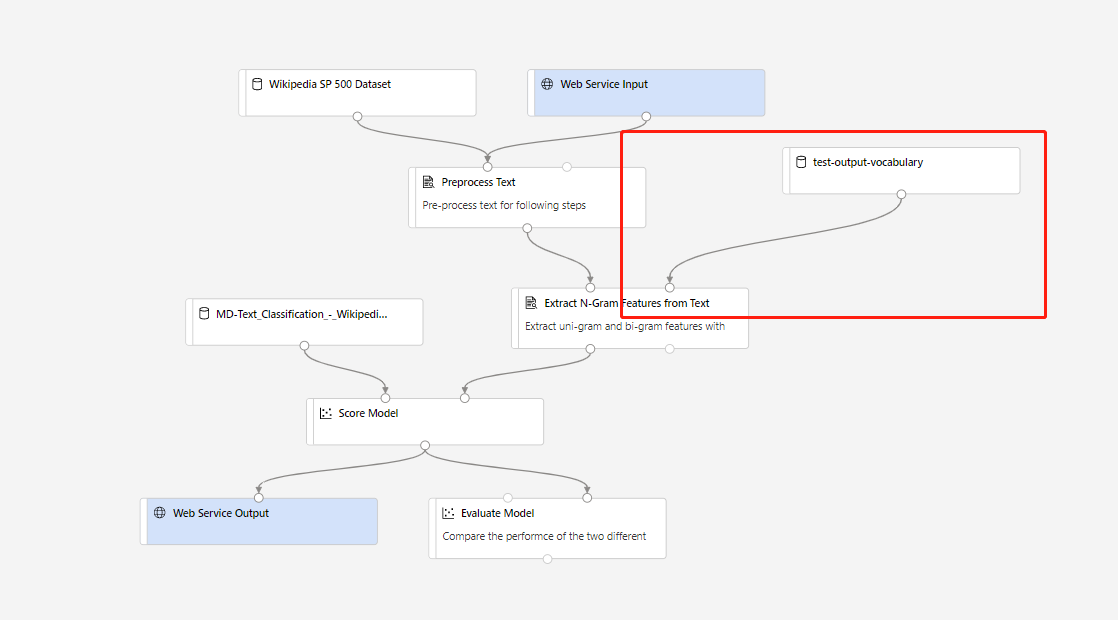
Em seguida, submeta o pipeline de inferência e implemente um ponto final em tempo real.
Resultados
O componente Extrair Funcionalidades de N-Grama do Texto cria dois tipos de saída:
Conjunto de dados de resultados: este resultado é um resumo do texto analisado combinado com os n-gramas que foram extraídos. As colunas que não selecionou na opção Coluna de texto são transmitidas para a saída. Para cada coluna de texto que analisar, o componente gera estas colunas:
- Matriz de ocorrências de n-gramas: o componente gera uma coluna para cada n-grama encontrada no corpus total e adiciona uma pontuação em cada coluna para indicar o peso do n-grama para essa linha.
Vocabulário do resultado: o vocabulário contém o dicionário real de n-gramas, juntamente com as pontuações de frequência do termo que são geradas como parte da análise. Pode guardar o conjunto de dados para reutilização com um conjunto diferente de entradas ou para uma atualização posterior. Também pode reutilizar o vocabulário para modelação e classificação.
Vocabulário do resultado
O vocabulário contém o dicionário n-grama com as pontuações de frequência de termo que são geradas como parte da análise. As classificações DF e IDF são geradas independentemente de outras opções.
- ID: um identificador gerado para cada n-grama exclusivo.
- NGram: O n-gram. Os espaços ou outros separadores de palavras são substituídos pelo caráter de sublinhado.
- DF: A pontuação de frequência do termo para o n-grama no corpus original.
- IDF: a pontuação inversa da frequência do documento para o n-gram no corpus original.
Pode atualizar manualmente este conjunto de dados, mas pode introduzir erros. Por exemplo:
- É gerado um erro se o componente encontrar linhas duplicadas com a mesma chave no vocabulário de entrada. Certifique-se de que nenhuma das duas linhas no vocabulário tem a mesma palavra.
- O esquema de entrada dos conjuntos de dados de vocabulário tem de corresponder exatamente, incluindo nomes de colunas e tipos de coluna.
- A coluna ID e a coluna DF têm de ser do tipo de número inteiro.
- A coluna IDF tem de ser do tipo flutuante.
Nota
Não ligue a saída de dados ao componente Train Model diretamente. Deve remover colunas de texto livre antes de serem inseridas no Modelo de Preparação. Caso contrário, as colunas de texto livre serão tratadas como funcionalidades categóricas.
Passos seguintes
Veja o conjunto de componentes disponíveis para o Azure Machine Learning.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários