O que é o aprendizado de máquina automatizado (AutoML)?
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
O aprendizado de máquina automatizado, também conhecido como ML automatizado ou AutoML, é o processo de automatizar as tarefas iterativas e demoradas do desenvolvimento de modelos de aprendizado de máquina. Ele permite que cientistas de dados, analistas e desenvolvedores criem modelos de ML com alta escala, eficiência e produtividade, ao mesmo tempo em que sustentam a qualidade do modelo. O ML automatizado no Azure Machine Learning baseia-se num avanço da divisão Microsoft Research.
- Para clientes experientes em código, instale o SDK Python do Azure Machine Learning. Introdução ao Tutorial: Treinar um modelo de deteção de objetos (visualização) com AutoML e Python.
Como funciona o AutoML?
Durante o treinamento, o Aprendizado de Máquina do Azure cria muitos pipelines em paralelo que tentam algoritmos e parâmetros diferentes para você. O serviço itera através de algoritmos de ML emparelhados com seleções de recursos, onde cada iteração produz um modelo com uma pontuação de treinamento. Quanto melhor a pontuação para a métrica para a qual você deseja otimizar, melhor o modelo é considerado para "ajustar" seus dados. Ele para quando atinge os critérios de saída definidos no experimento.
Usando o Azure Machine Learning, você pode projetar e executar seus experimentos de treinamento automatizados de ML com estas etapas:
Identificar o problema de ML a ser resolvido: classificação, previsão, regressão, visão computacional ou PNL.
Escolha se você deseja uma experiência code-first ou uma experiência web no-code studio: os usuários que preferem uma experiência code-first podem usar o SDK do Azure Machine Learning v2 ou o Azure Machine Learning CLIv2. Introdução ao Tutorial: Treinar um modelo de deteção de objetos com AutoML e Python. Os usuários que preferem uma experiência limitada ou sem código podem usar a interface Web no estúdio de Aprendizado de Máquina do Azure em https://ml.azure.com. Introdução ao Tutorial: Criar um modelo de classificação com ML automatizado no Azure Machine Learning.
Especifique a origem dos dados de treinamento rotulados: você pode trazer seus dados para o Azure Machine Learning de muitas maneiras diferentes.
Configure os parâmetros de aprendizado de máquina automatizados que determinam quantas iterações em diferentes modelos, configurações de hiperparâmetros, pré-processamento/featurização avançados e quais métricas observar ao determinar o melhor modelo.
Apresentar o trabalho de formação.
Analise os resultados.
O diagrama a seguir ilustra esse processo.
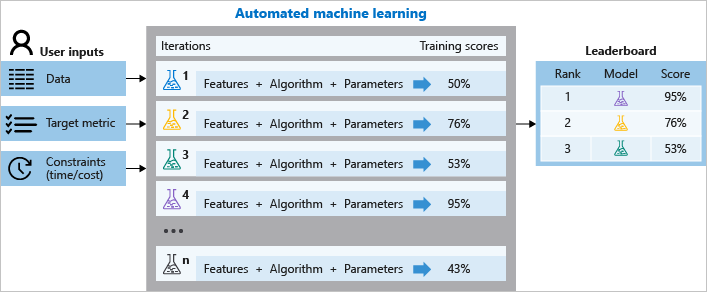
Você também pode inspecionar as informações de trabalho registradas, que contêm métricas coletadas durante o trabalho. O trabalho de treinamento produz um objeto serializado Python (.pkl arquivo) que contém o modelo e o pré-processamento de dados.
Embora a construção de modelos seja automatizada, você também pode aprender como os recursos são importantes ou relevantes para os modelos gerados.
Quando usar o AutoML: classificação, regressão, previsão, visão computacional, & NLP
Aplique ML automatizado quando quiser que o Aprendizado de Máquina do Azure treine e ajuste um modelo para você usando a métrica de destino especificada. O ML automatizado democratiza o processo de desenvolvimento do modelo de aprendizado de máquina e capacita seus usuários, independentemente de sua experiência em ciência de dados, a identificar um pipeline de aprendizado de máquina de ponta a ponta para qualquer problema.
Profissionais e desenvolvedores de ML em todos os setores podem usar ML automatizado para:
- Implemente soluções de ML sem amplo conhecimento de programação
- Poupe tempo e recursos
- Aplicar as melhores práticas de ciência de dados
- Proporcionar uma resolução ágil de problemas
Classificação
A classificação é um tipo de aprendizagem supervisionada em que os modelos aprendem a usar dados de treinamento e aplicar esses aprendizados a novos dados. O Azure Machine Learning oferece caracterizações especificamente para estas tarefas, tais como "featurizers" de texto de rede neural profunda para classificação. Para obter mais informações sobre opções de featurização, consulte Featurização de dados. Você também pode encontrar a lista de algoritmos suportados pelo AutoML em Algoritmos suportados.
O principal objetivo dos modelos de classificação é prever em quais categorias os novos dados se enquadram com base nos aprendizados de seus dados de treinamento. Alguns exemplos comuns de classificação incluem deteção de fraude, reconhecimento de caligrafia e deteção de objetos.
Veja um exemplo de classificação e aprendizado de máquina automatizado neste caderno Python: Marketing Bancário.
Regressão
À semelhança da classificação, as tarefas de regressão são também uma tarefa comum de aprendizagem supervisionada. O Azure Machine Learning oferece featurização específica para problemas de regressão. Saiba mais sobre as opções de featurização. Você também pode encontrar a lista de algoritmos suportados pelo AutoML em Algoritmos suportados.
Diferente da classificação em que os valores de saída previstos são categóricos, os modelos de regressão predizem valores numéricos de saída com base em preditores independentes. Na regressão, o objetivo é ajudar a estabelecer a relação entre essas variáveis de preditor independente ao calcular como uma variável afeta as outras. Por exemplo, o modelo pode prever o preço do automóvel com base em recursos como quilometragem do gás e classificação de segurança.
Veja um exemplo de regressão e aprendizado de máquina automatizado para previsões nestes notebooks Python: Desempenho de hardware.
Previsão da série temporal
A criação de previsões faz parte de qualquer negócio, seja receita, inventário, vendas ou procura de clientes. Pode utilizar ML automatizado para combinar técnicas e abordagens, e obter uma previsão recomendada de série temporal de alta qualidade. Você pode encontrar a lista de algoritmos suportados pelo AutoML em Algoritmos suportados.
Um experimento automatizado de séries temporais é tratado como um problema de regressão multivariada. Os valores de séries temporais passadas são "pivotados" para se tornarem mais dimensões para o regressor juntamente com outros preditores. Esta abordagem, ao contrário dos métodos clássicos de séries temporais, tem a vantagem de incorporar naturalmente múltiplas variáveis contextuais e a sua relação entre si durante o treino. O ML automatizado aprende um modelo único, mas muitas vezes ramificado internamente, para todos os itens no conjunto de dados e horizontes de previsão. Mais dados estão assim disponíveis para estimar os parâmetros do modelo e torna-se possível generalizar para séries invisíveis.
A configuração avançada de previsão inclui:
- Deteção e caracterização de feriados
- Alunos de séries cronológicas e DNN (Auto-ARIMA, Prophet, ForecastTCN)
- Muitos modelos suportam através de agrupamento
- Validação cruzada de origem rolante
- Atrasos configuráveis
- Funcionalidades agregadas de janelas de implementação
Veja um exemplo de previsão e aprendizado de máquina automatizado neste notebook Python: Demanda de energia.
Imagem digitalizada
O suporte para tarefas de visão computacional permite gerar facilmente modelos treinados em dados de imagem para cenários como classificação de imagens e deteção de objetos.
Com essa capacidade, você pode:
- Integre-se perfeitamente com o recurso de rotulagem de dados do Azure Machine Learning.
- Use dados rotulados para gerar modelos de imagem.
- Otimize o desempenho do modelo especificando o algoritmo do modelo e ajustando os hiperparâmetros.
- Transfira ou implemente o modelo resultante como um serviço Web no Azure Machine Learning.
- Operacionalize em escala, aproveitando os recursos de MLOps e ML Pipelines do Azure Machine Learning.
A criação de modelos AutoML para tarefas de visão é suportada por meio do SDK Python do Azure Machine Learning. Os trabalhos, modelos e saídas de experimentação resultantes podem ser acessados na interface do usuário do estúdio de Aprendizado de Máquina do Azure.
Saiba como configurar o treinamento AutoML para modelos de visão computacional.
 Imagem de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Imagem de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
O ML Automatizado para imagens suporta as seguintes tarefas de imagens digitalizadas:
| Tarefa | Descrição |
|---|---|
| Classificação de imagens multiclasse | Tarefas em que uma imagem é classificada com apenas um rótulo de um conjunto de classes - por exemplo, cada imagem é classificada como uma imagem de um "gato" ou um "cão" ou um "pato". |
| Classificação de imagens de várias etiquetas | Tarefas em que uma imagem pode ter uma ou mais etiquetas de um conjunto de etiquetas - por exemplo, uma imagem pode ser rotulada com "gato" e "cão". |
| Deteção de objetos | Tarefas para identificar objetos em uma imagem e localizar cada objeto com uma caixa delimitadora, por exemplo, localizar todos os cães e gatos em uma imagem e desenhar uma caixa delimitadora em torno de cada um. |
| Segmentação de instâncias | Tarefas para identificar objetos numa imagem ao nível dos pixels, ao desenhar um polígono à volta de cada objeto na imagem. |
Processamento de linguagem natural: PNL
O suporte para tarefas de processamento de linguagem natural (NLP) em ML automatizado permite gerar facilmente modelos treinados em dados de texto para cenários de classificação de texto e reconhecimento de entidade nomeada. A criação de modelos de PNL treinados em ML automatizados é suportada por meio do SDK Python do Azure Machine Learning. Os trabalhos, modelos e saídas de experimentação resultantes podem ser acessados na interface do usuário do estúdio de Aprendizado de Máquina do Azure.
O recurso de PNL suporta:
- Treinamento completo de PNL em redes neurais profundas com os mais recentes modelos BERT pré-treinados
- Integração perfeita com a rotulagem de dados do Azure Machine Learning
- Usar dados rotulados para gerar modelos de PNL
- Suporte multilingue com 104 idiomas
- Formação distribuída com o Horovod
Saiba como configurar o treinamento AutoML para modelos de PNL.
Dados de treinamento, validação e teste
Com o ML automatizado, você fornece os dados de treinamento para treinar modelos de ML e pode especificar que tipo de validação de modelo executar. O ML automatizado executa a validação do modelo como parte do treinamento. Ou seja, o ML automatizado usa dados de validação para ajustar os hiperparâmetros do modelo com base no algoritmo aplicado para encontrar a combinação que melhor se ajusta aos dados de treinamento. No entanto, os mesmos dados de validação são usados para cada iteração de ajuste, o que introduz viés de avaliação do modelo, uma vez que o modelo continua a melhorar e se ajustar aos dados de validação.
Para ajudar a confirmar que esse viés não é aplicado ao modelo final recomendado, o ML automatizado suporta o uso de dados de teste para avaliar o modelo final que o ML automatizado recomenda no final do experimento. Quando você fornece dados de teste como parte da configuração do experimento AutoML, esse modelo recomendado é testado por padrão no final do experimento (visualização).
Importante
Testar seus modelos com um conjunto de dados de teste para avaliar os modelos gerados é um recurso de visualização. Esse recurso é um recurso de visualização experimental e pode ser alterado a qualquer momento.
Saiba como configurar experimentos de AutoML para usar dados de teste (visualização) com o SDK ou com o estúdio do Azure Machine Learning.
Desenvolvimento de funcionalidades
A engenharia de recursos é o processo de usar o conhecimento de domínio dos dados para criar recursos que ajudam os algoritmos de ML a aprender melhor. No Azure Machine Learning, as técnicas de dimensionamento e normalização são aplicadas para facilitar a engenharia de recursos. Coletivamente, essas técnicas e engenharia de recursos são chamadas de featurização.
Para experimentos automatizados de aprendizado de máquina, a featurização é aplicada automaticamente, mas também pode ser personalizada com base em seus dados. Saiba mais sobre o que a featurização está incluída (SDK v1) e como o AutoML ajuda a evitar dados sobreajustados e desequilibrados em seus modelos.
Nota
Etapas automatizadas de featurização de aprendizado de máquina (por exemplo, normalização de recursos, manipulação de dados ausentes e conversão de texto em numérico) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de featurização aplicadas durante o treinamento são aplicadas aos seus dados de entrada automaticamente.
Personalizar featurização
Técnicas adicionais de engenharia de recursos, como codificação e transformações, também estão disponíveis.
Habilite essa configuração com:
Estúdio do Azure Machine Learning: habilite a featurização automática na seção Exibir configuração adicional com estas etapas.
Python SDK: Especifique featurization em seu objeto AutoML Job . Saiba mais sobre como habilitar a featurização.
Modelos Ensemble
O aprendizado de máquina automatizado suporta modelos de conjunto, que são habilitados por padrão. O Ensemble Learning melhora os resultados do aprendizado de máquina e o desempenho preditivo combinando vários modelos em vez de usar modelos únicos. As iterações de conjunto aparecem como as iterações finais do seu trabalho. O aprendizado de máquina automatizado usa métodos de votação e conjunto de empilhamento para combinar modelos:
- Votação: prevê com base na média ponderada das probabilidades de classe previstas (para tarefas de classificação) ou metas de regressão previstas (para tarefas de regressão).
- Empilhamento: Combina modelos heterogêneos e treina um metamodelo com base na saída dos modelos individuais. Os metamodelos padrão atuais são LogisticRegression para tarefas de classificação e ElasticNet para tarefas de regressão/previsão.
O algoritmo de seleção do conjunto Caruana com inicialização do conjunto classificado é usado para decidir quais modelos usar dentro do conjunto. Em um nível alto, este algoritmo inicializa o conjunto com até cinco modelos com as melhores pontuações individuais, e verifica se esses modelos estão dentro do limiar de 5% da melhor pontuação para evitar um conjunto inicial ruim. Em seguida, para cada iteração de conjunto, um novo modelo é adicionado ao conjunto existente e a pontuação resultante é calculada. Se um novo modelo melhorou a pontuação do conjunto existente, o conjunto é atualizado para incluir o novo modelo.
Consulte o pacote AutoML para alterar as configurações padrão do conjunto no aprendizado de máquina automatizado.
AutoML & ONNX
Com o Azure Machine Learning, você pode usar ML automatizado para criar um modelo Python e convertê-lo para o formato ONNX. Uma vez que os modelos estão no formato ONNX, eles podem ser executados em várias plataformas e dispositivos. Saiba mais sobre como acelerar modelos de ML com ONNX.
Veja como converter para o formato ONNX neste exemplo de bloco de anotações Jupyter. Saiba quais algoritmos são suportados no ONNX.
O tempo de execução ONNX também suporta C#, para que você possa usar o modelo criado automaticamente em seus aplicativos C# sem qualquer necessidade de recodificação ou qualquer uma das latências de rede que os pontos de extremidade REST introduzem. Saiba mais sobre como usar um modelo ONNX AutoML em um aplicativo .NET com ML.NET e inferir modelos ONNX com a API C# de tempo de execução ONNX.
Próximos passos
Há vários recursos para você começar a trabalhar com o AutoML.
Tutoriais / instruções
Os tutoriais são exemplos introdutórios completos de cenários de AutoML.
Para uma primeira experiência de código, siga Tutorial: Treinar um modelo de deteção de objeto com AutoML e Python
Para obter uma experiência de baixo ou nenhum código, consulte Tutorial: Treinar um modelo de classificação com AutoML sem código no estúdio de Aprendizado de Máquina do Azure.
Os artigos de instruções fornecem mais detalhes sobre a funcionalidade que o ML automatizado oferece. Por exemplo,
Definir as configurações para experimentos de treinamento automático
- Sem código no estúdio do Azure Machine Learning.
- Com o Python SDK.
Aprenda a treinar modelos de visão computacional com Python.
Saiba como visualizar o código gerado a partir de seus modelos de ML automatizados (SDK v1).
Amostras de cadernos Jupyter
Analise os exemplos de código e casos de utilização detalhados no Repositório do bloco de notas do GitHub para amostras de machine learning automatizado.
Referência SDK Python
Aprofunde sua experiência em padrões de design SDK e especificações de classe com a documentação de referência de classe AutoML Job.
Nota
Os recursos de aprendizado de máquina automatizado também estão disponíveis em outras soluções da Microsoft, como ML.NET, HDInsight, Power BI e SQL Server.