Aprendizagem profunda vs. machine Learning no Azure Machine Learning
Este artigo explica deep learning vs. machine learning e como eles se encaixam na categoria mais ampla de inteligência artificial. Saiba mais sobre as soluções de aprendizagem profunda que pode desenvolver no Azure Machine Learning, tais como deteção de fraude, reconhecimento facial e de voz, análise de sentimento e previsão de séries cronológicas.
Para obter orientação sobre como escolher algoritmos para suas soluções, consulte o Machine Learning Algorithm Cheat Sheet.
Os Modelos de Base no Azure Machine Learning são modelos de aprendizagem profunda pré-treinados que podem ser ajustados para casos de uso específicos. Saiba mais sobre os Modelos de Base (pré-visualização) no Azure Machine Learning e como utilizar os Modelos de Base no Azure Machine Learning (pré-visualização).
Deep learning, machine learning e IA
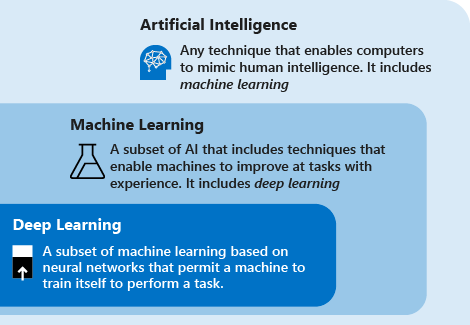
Considere as seguintes definições para entender o aprendizado profundo vs. aprendizado de máquina vs. IA:
O deep learning é um subconjunto do aprendizado de máquina baseado em redes neurais artificiais. O processo de aprendizagem é profundo porque a estrutura das redes neurais artificiais consiste em múltiplas camadas de entrada, saída e ocultas. Cada camada contém unidades que transformam os dados de entrada em informações que a próxima camada pode utilizar para uma determinada tarefa preditiva. Graças a esta estrutura, uma máquina pode aprender através do seu próprio processamento de dados.
O aprendizado de máquina é um subconjunto da inteligência artificial que usa técnicas (como deep learning) que permitem que as máquinas usem a experiência para melhorar as tarefas. O processo de aprendizagem baseia-se nas seguintes etapas:
- Alimente dados em um algoritmo. (Nesta etapa, você pode fornecer informações adicionais ao modelo, por exemplo, executando a extração de recursos.)
- Use esses dados para treinar um modelo.
- Teste e implante o modelo.
- Consuma o modelo implantado para executar uma tarefa preditiva automatizada. (Em outras palavras, chame e use o modelo implantado para receber as previsões retornadas pelo modelo.)
A inteligência artificial (IA) é uma técnica que permite aos computadores imitar a inteligência humana. Inclui aprendizagem automática.
A IA generativa é um subconjunto da inteligência artificial que usa técnicas (como deep learning) para gerar novos conteúdos. Por exemplo, você pode usar IA generativa para criar imagens, texto ou áudio. Esses modelos aproveitam o conhecimento pré-treinado maciço para gerar esse conteúdo.
Usando técnicas de aprendizado de máquina e aprendizado profundo, você pode construir sistemas de computador e aplicativos que executam tarefas que são comumente associadas à inteligência humana. Essas tarefas incluem reconhecimento de imagem, reconhecimento de fala e tradução de idiomas.
Técnicas de deep learning vs. machine learning
Agora que você tem uma visão geral do aprendizado de máquina versus aprendizado profundo, vamos comparar as duas técnicas. No aprendizado de máquina, o algoritmo precisa ser informado sobre como fazer uma previsão precisa consumindo mais informações (por exemplo, realizando a extração de recursos). Na aprendizagem profunda, o algoritmo pode aprender a fazer uma previsão precisa através do seu próprio processamento de dados, graças à estrutura da rede neural artificial.
A tabela a seguir compara as duas técnicas com mais detalhes:
| Toda a aprendizagem automática | Apenas aprendizagem profunda | |
|---|---|---|
| Número de pontos de dados | Pode usar pequenas quantidades de dados para fazer previsões. | Precisa usar grandes quantidades de dados de treinamento para fazer previsões. |
| Dependências de hardware | Pode trabalhar em máquinas low-end. Ele não precisa de uma grande quantidade de poder computacional. | Depende de máquinas topo de gama. Inerentemente faz um grande número de operações de multiplicação matricial. Uma GPU pode otimizar essas operações de forma eficiente. |
| Processo de featurização | Requer que os recursos sejam identificados e criados com precisão pelos usuários. | Aprende recursos de alto nível a partir de dados e cria novos recursos por si só. |
| Abordagem de aprendizagem | Divide o processo de aprendizagem em etapas menores. Em seguida, combina os resultados de cada etapa em uma saída. | Move-se através do processo de aprendizagem, resolvendo o problema em uma base de ponta a ponta. |
| Prazo de execução | Leva relativamente pouco tempo para treinar, variando de alguns segundos a algumas horas. | Geralmente leva muito tempo para treinar porque um algoritmo de aprendizagem profunda envolve muitas camadas. |
| Saída | A saída é geralmente um valor numérico, como uma pontuação ou uma classificação. | A saída pode ter vários formatos, como um texto, uma partitura ou um som. |
O que é a transferência de aprendizagem?
O treinamento de modelos de aprendizagem profunda geralmente requer grandes quantidades de dados de treinamento, recursos de computação high-end (GPU, TPU) e um tempo de treinamento mais longo. Em cenários em que você não tem nenhum deles disponível, você pode atalho o processo de treinamento usando uma técnica conhecida como aprendizagem por transferência.
A aprendizagem por transferência é uma técnica que aplica o conhecimento adquirido na resolução de um problema a um problema diferente, mas relacionado.
Devido à estrutura das redes neurais, o primeiro conjunto de camadas geralmente contém recursos de nível inferior, enquanto o conjunto final de camadas contém recursos de nível superior que estão mais próximos do domínio em questão. Ao redirecionar as camadas finais para uso em um novo domínio ou problema, você pode reduzir significativamente a quantidade de tempo, dados e recursos de computação necessários para treinar o novo modelo. Por exemplo, se você já tem um modelo que reconhece carros, você pode reaproveitar esse modelo usando o aprendizado de transferência para também reconhecer caminhões, motocicletas e outros tipos de veículos.
Saiba como aplicar o aprendizado de transferência para classificação de imagens usando uma estrutura de código aberto no Azure Machine Learning: Treine um modelo PyTorch de aprendizado profundo usando o aprendizado de transferência.
Casos de uso de aprendizagem profunda
Devido à estrutura da rede neural artificial, o deep learning se destaca na identificação de padrões em dados não estruturados, como imagens, som, vídeo e texto. Por esse motivo, o deep learning está transformando rapidamente muitos setores, incluindo saúde, energia, finanças e transporte. Estas indústrias estão agora a repensar os processos empresariais tradicionais.
Algumas das aplicações mais comuns para aprendizagem profunda são descritas nos parágrafos seguintes. No Azure Machine Learning, você pode usar um modelo criado a partir de uma estrutura de código aberto ou criar o modelo usando as ferramentas fornecidas.
Reconhecimento de entidade nomeada
O reconhecimento de entidade nomeada é um método de aprendizagem profunda que usa um pedaço de texto como entrada e o transforma em uma classe pré-especificada. Esta nova informação pode ser um código postal, uma data, um ID do produto. As informações podem ser armazenadas em um esquema estruturado para criar uma lista de endereços ou servir como referência para um mecanismo de validação de identidade.
Deteção de objetos
A aprendizagem profunda tem sido aplicada em muitos casos de uso de deteção de objetos. A deteção de objetos é usada para identificar objetos em uma imagem (como carros ou pessoas) e fornecer localização específica para cada objeto com uma caixa delimitadora.
A deteção de objetos já é usada em indústrias como jogos, varejo, turismo e carros autônomos.
Geração de legendas de imagem
Assim como o reconhecimento de imagem, na legendagem de imagem, para uma determinada imagem, o sistema deve gerar uma legenda que descreva o conteúdo da imagem. Quando você pode detetar e rotular objetos em fotografias, a próxima etapa é transformar esses rótulos em frases descritivas.
Normalmente, os aplicativos de legendagem de imagem usam redes neurais convolucionais para identificar objetos em uma imagem e, em seguida, usam uma rede neural recorrente para transformar os rótulos em frases consistentes.
Tradução automática
A tradução automática utiliza palavras ou frases de uma língua e traduz-as automaticamente para outra língua. A tradução automática já existe há muito tempo, mas a aprendizagem profunda alcança resultados impressionantes em duas áreas específicas: tradução automática de texto (e tradução de fala para texto) e tradução automática de imagens.
Com a transformação de dados apropriada, uma rede neural pode entender texto, áudio e sinais visuais. A tradução automática pode ser usada para identificar trechos de som em arquivos de áudio maiores e transcrever a palavra falada ou imagem como texto.
Análise de texto
A análise de texto baseada em métodos de aprendizagem profunda envolve a análise de grandes quantidades de dados de texto (por exemplo, documentos médicos ou recibos de despesas), o reconhecimento de padrões e a criação de informações organizadas e concisas a partir deles.
As empresas usam o aprendizado profundo para realizar análises de texto para detetar insider trading e conformidade com regulamentações governamentais. Outro exemplo comum é a fraude de seguro: a análise de texto tem sido frequentemente usada para analisar grandes quantidades de documentos para reconhecer as chances de uma reclamação de seguro ser fraude.
Redes neurais artificiais
As redes neurais artificiais são formadas por camadas de nós conectados. Os modelos de aprendizagem profunda usam redes neurais que têm um grande número de camadas.
As seções a seguir exploram as topologias de redes neurais artificiais mais populares.
Rede neural Feedforward
A rede neural feedforward é o tipo mais simples de rede neural artificial. Em uma rede feedforward, as informações se movem em apenas uma direção da camada de entrada para a camada de saída. As redes neurais Feedforward transformam uma entrada colocando-a através de uma série de camadas ocultas. Cada camada é composta por um conjunto de neurônios, e cada camada está totalmente conectada a todos os neurônios na camada anterior. A última camada totalmente conectada (a camada de saída) representa as previsões geradas.
Rede neural recorrente (recurrent neural network, RNN)
As redes neurais recorrentes são uma rede neural artificial amplamente utilizada. Essas redes salvam a saída de uma camada e a retroalimentam para a camada de entrada para ajudar a prever o resultado da camada. As redes neurais recorrentes têm grandes capacidades de aprendizagem. Eles são amplamente utilizados para tarefas complexas, como previsão de séries temporais, aprendizagem de manuscrito e reconhecimento de linguagem.
Rede neural convolucional (convolutional neural network, CNN)
Uma rede neural convolucional é uma rede neural artificial particularmente eficaz, e apresenta uma arquitetura única. As camadas são organizadas em três dimensões: largura, altura e profundidade. Os neurónios de uma camada ligam-se não a todos os neurónios da camada seguinte, mas apenas a uma pequena região dos neurónios da camada. O resultado final é reduzido a um único vetor de escores de probabilidade, organizados ao longo da dimensão profundidade.
Redes neurais convolucionais têm sido usadas em áreas como reconhecimento de vídeo, reconhecimento de imagem e sistemas de recomendação.
Rede generativa antagónica (generative adversarial network, GAN)
As redes generativas adversárias são modelos generativos treinados para criar conteúdo realista, como imagens. É composto por duas redes conhecidas como gerador e discriminador. Ambas as redes são treinadas simultaneamente. Durante o treinamento, o gerador usa ruído aleatório para criar novos dados sintéticos que se assemelham a dados reais. O discriminador toma a saída do gerador como entrada e usa dados reais para determinar se o conteúdo gerado é real ou sintético. Cada rede concorre entre si. O gerador está tentando gerar conteúdo sintético que é indistinguível do conteúdo real e o discriminador está tentando classificar corretamente as entradas como reais ou sintéticas. A saída é então usada para atualizar os pesos de ambas as redes para ajudá-los a alcançar melhor seus respetivos objetivos.
Redes generativas adversariais são usadas para resolver problemas como tradução de imagem para imagem e progressão de idade.
Transformadores
Os transformadores são uma arquitetura de modelo adequada para resolver problemas que contêm sequências, como texto ou dados de séries temporais. Consistem em camadas de codificador e descodificador. O codificador pega uma entrada e a mapeia para uma representação numérica contendo informações como contexto. O decodificador usa informações do codificador para produzir uma saída, como texto traduzido. O que torna os transformadores diferentes de outras arquiteturas contendo codificadores e decodificadores são as subcamadas de atenção. Atenção é a ideia de focar em partes específicas de uma entrada com base na importância de seu contexto em relação a outras entradas em uma sequência. Por exemplo, ao resumir uma notícia, nem todas as frases são relevantes para descrever a ideia principal. Ao focar em palavras-chave ao longo do artigo, o resumo pode ser feito em uma única frase, o título.
Os transformadores têm sido usados para resolver problemas de processamento de linguagem natural, como tradução, geração de texto, resposta a perguntas e resumo de texto.
Algumas implementações bem conhecidas de transformadores são:
- Representações de codificadores bidirecionais de transformadores (BERT)
- Transformador pré-treinado generativo 2 (GPT-2)
- Transformador Generativo Pré-treinado 3 (GPT-3)
Próximos passos
Os artigos a seguir mostram mais opções para usar modelos de aprendizado profundo de código aberto no Azure Machine Learning: