Configurar o AutoML para treinar um modelo de previsão de séries temporais com Python (SDKv1)
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste artigo, você aprenderá a configurar o treinamento AutoML para modelos de previsão de séries cronológicas com o ML automatizado do Azure Machine Learning no SDK Python do Azure Machine Learning.
Para tal, terá de:
- Preparar dados para modelagem de séries temporais.
- Configure parâmetros específicos de séries cronológicas em um
AutoMLConfigobjeto. - Execute previsões com dados de séries cronológicas.
Para obter uma experiência de baixo código, consulte o Tutorial: Prever a demanda com aprendizado de máquina automatizado para obter um exemplo de previsão de séries cronológicas usando ML automatizado no estúdio de Aprendizado de Máquina do Azure.
Ao contrário dos métodos clássicos de séries temporais, no ML automatizado, os valores de séries temporais passadas são "pivotados" para se tornarem dimensões adicionais para o regressor juntamente com outros preditores. Esta abordagem incorpora múltiplas variáveis contextuais e a sua relação entre si durante o treino. Uma vez que vários fatores podem influenciar uma previsão, este método alinha-se bem com cenários de previsão do mundo real. Por exemplo, ao prever vendas, as interações de tendências históricas, taxa de câmbio e preço impulsionam conjuntamente o resultado das vendas.
Pré-requisitos
Para este artigo você precisa,
Uma área de trabalho do Azure Machine Learning. Para criar o espaço de trabalho, consulte Criar recursos do espaço de trabalho.
Este artigo pressupõe alguma familiaridade com a configuração de um experimento automatizado de aprendizado de máquina. Siga o tutorial para ver os principais padrões de design de experimentos de aprendizado de máquina automatizados.
Importante
Os comandos Python neste artigo requerem a versão mais recente
azureml-train-automldo pacote.- Instale o pacote mais recente
azureml-train-automlem seu ambiente local. - Para obter detalhes sobre o pacote mais recente
azureml-train-automl, consulte as notas de versão.
- Instale o pacote mais recente
Dados de formação e validação
A diferença mais importante entre um tipo de tarefa de regressão de previsão e um tipo de tarefa de regressão no ML automatizado é incluir um recurso em seus dados de treinamento que representa uma série temporal válida. Uma série temporal regular tem uma frequência bem definida e consistente e tem um valor em cada ponto da amostra num período de tempo contínuo.
Importante
Ao treinar um modelo para previsão de valores futuros, certifique-se de que todos os recursos usados no treinamento possam ser usados ao executar previsões para o horizonte pretendido. Por exemplo, ao criar uma previsão de demanda, incluir um recurso para o preço atual das ações pode aumentar enormemente a precisão do treinamento. No entanto, se você pretende prever com um horizonte longo, talvez não seja capaz de prever com precisão os valores futuros de ações correspondentes a pontos de séries cronológicas futuras, e a precisão do modelo pode ser prejudicada.
Você pode especificar dados de treinamento separados e dados de validação diretamente no AutoMLConfig objeto. Saiba mais sobre o AutoMLConfig.
Para previsão de séries temporais, apenas a Validação Cruzada de Origem Rolante (ROCV) é usada para validação por padrão. A ROCV divide a série em dados de treinamento e validação usando um ponto de tempo de origem. Deslizar a origem no tempo gera as dobras de validação cruzada. Essa estratégia preserva a integridade dos dados da série temporal e elimina o risco de vazamento de dados.
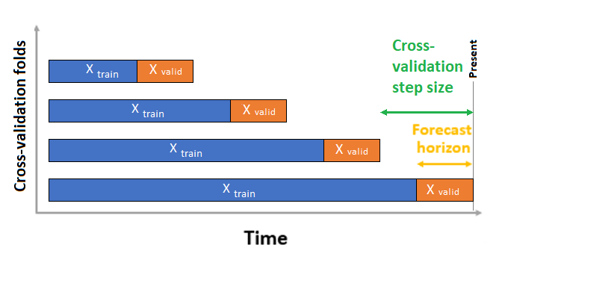
Passe seus dados de treinamento e validação como um conjunto de dados para o parâmetro training_data. Defina o número de dobras de validação cruzada com o parâmetro n_cross_validations e defina o número de períodos entre duas dobras de validação cruzada consecutivas com cv_step_size. Você também pode deixar um ou ambos os parâmetros vazios e o AutoML os define automaticamente.
APLICA-SE A: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Você também pode trazer seus próprios dados de validação, saber mais em Configurar divisões de dados e validação cruzada no AutoML.
Saiba mais sobre como o AutoML aplica a validação cruzada para evitar modelos de sobreajuste.
Configurar experiência
O AutoMLConfig objeto define as configurações e os dados necessários para uma tarefa automatizada de aprendizado de máquina. A configuração de um modelo de previsão é semelhante à configuração de um modelo de regressão padrão, mas determinados modelos, opções de configuração e etapas de featurização existem especificamente para dados de séries temporais.
Modelos suportados
O aprendizado de máquina automatizado experimenta automaticamente diferentes modelos e algoritmos como parte do processo de criação e ajuste do modelo. Como usuário, não há necessidade de especificar o algoritmo. Para experiências de previsão, tanto séries cronológicas nativas como modelos de aprendizagem profunda fazem parte do sistema de recomendação.
Gorjeta
Modelos de regressão tradicionais também são testados como parte do sistema de recomendação para experimentos de previsão. Consulte uma lista completa dos modelos suportados na documentação de referência do SDK.
Definições de configuração
Semelhante a um problema de regressão, você define parâmetros de treinamento padrão, como tipo de tarefa, número de iterações, dados de treinamento e número de validações cruzadas. As tarefas de previsão exigem os time_column_name parâmetros e forecast_horizon para configurar seu experimento. Se os dados incluírem várias séries temporais, como dados de vendas para vários armazenamentos ou dados de energia em diferentes estados, o ML automatizado detetará isso automaticamente e definirá o time_series_id_column_names parâmetro (visualização) para você. Você também pode incluir parâmetros adicionais para configurar melhor sua execução, consulte a seção de configurações opcionais para obter mais detalhes sobre o que pode ser incluído.
Importante
A identificação automática de séries cronológicas está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
| Nome do parâmetro | Description |
|---|---|
time_column_name |
Usado para especificar a coluna datetime nos dados de entrada usados para construir a série temporal e inferir sua frequência. |
forecast_horizon |
Define quantos períodos você gostaria de prever. O horizonte está em unidades da frequência da série temporal. As unidades são baseadas no intervalo de tempo dos seus dados de treinamento, por exemplo, mensalmente, semanalmente que o meteorologista deve prever. |
O seguinte código,
- Usa a
ForecastingParametersclasse para definir os parâmetros de previsão para seu treinamento de experimento - Define o
time_column_namecampo para oday_datetimeno conjunto de dados. - Define como
forecast_horizon50 para prever todo o conjunto de testes.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Em seguida, eles forecasting_parameters são passados para o objeto padrão AutoMLConfig junto com o tipo de tarefa, a métrica principal, os critérios de saída e os forecasting dados de treinamento.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
A quantidade de dados necessária para treinar com êxito um modelo de previsão com ML automatizado é influenciada pelos valores , n_cross_validationse target_lags ou target_rolling_window_size especificados quando você configura o forecast_horizon.AutoMLConfig
A fórmula a seguir calcula a quantidade de dados históricos que seriam necessários para construir características de séries temporais.
Dados históricos mínimos necessários: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Um Error exception é gerado para qualquer série no conjunto de dados que não atenda à quantidade necessária de dados históricos para as configurações relevantes especificadas.
Etapas de featurização
Em todos os experimentos automatizados de aprendizado de máquina, as técnicas de dimensionamento e normalização automáticas são aplicadas aos seus dados por padrão. Estas técnicas são tipos de featurização que ajudam certos algoritmos que são sensíveis a características em diferentes escalas. Saiba mais sobre as etapas de featurização padrão em Featurization in AutoML
No entanto, as seguintes etapas são executadas apenas para forecasting tipos de tarefas:
- Detete a frequência da amostra de séries cronológicas (por exemplo, horária, diária, semanal) e crie novos registros para pontos de tempo ausentes para tornar a série contínua.
- Imputar valores ausentes nas colunas de destino (via preenchimento para frente) e feição (usando valores de coluna mediana)
- Crie recursos com base em identificadores de séries temporais para habilitar efeitos fixos em diferentes séries
- Crie recursos baseados no tempo para ajudar a aprender padrões sazonais
- Codificar variáveis categóricas para quantidades numéricas
- Detete as séries temporais não estacionárias e diferencie-as automaticamente para mitigar o impacto das raízes da unidade.
Para exibir a lista completa de possíveis recursos de engenharia gerados a partir de dados de séries temporais, consulte TimeIndexFeaturizer Class.
Nota
Etapas automatizadas de featurização de aprendizado de máquina (normalização de recursos, manipulação de dados ausentes, conversão de texto em numérico, etc.) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de featurização aplicadas durante o treinamento são aplicadas aos seus dados de entrada automaticamente.
Personalizar featurização
Você também tem a opção de personalizar suas configurações de featurização para garantir que os dados e recursos usados para treinar seu modelo de ML resultem em previsões relevantes.
As personalizações suportadas para forecasting tarefas incluem:
| Personalização | Definição |
|---|---|
| Atualização da finalidade da coluna | Substitua o tipo de recurso detetado automaticamente para a coluna especificada. |
| Atualização dos parâmetros do transformador | Atualize os parâmetros para o transformador especificado. Atualmente suporta Imputer (fill_value e mediana). |
| Soltar colunas | Especifica as colunas a serem soltas de serem featurizadas. |
Para personalizar featurizações com o SDK, especifique "featurization": FeaturizationConfig em seu AutoMLConfig objeto. Saiba mais sobre featurizações personalizadas.
Nota
A funcionalidade de soltar colunas foi preterida a partir da versão 1.19 do SDK. Solte colunas do conjunto de dados como parte da limpeza de dados, antes de consumi-las em seu experimento automatizado de ML.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Se você estiver usando o estúdio de Aprendizado de Máquina do Azure para seu experimento, veja como personalizar a featurização no estúdio.
Configurações opcionais
Mais configurações opcionais estão disponíveis para tarefas de previsão, como habilitar o aprendizado profundo e especificar uma agregação de janela contínua de destino. Uma lista completa de mais parâmetros está disponível na documentação de referência do SDK ForecastingParameters.
Frequência & agregação de dados de destino
Use o parâmetro freqüência, freq, para ajudar a evitar falhas causadas por dados irregulares. Dados irregulares incluem dados que não seguem uma cadência definida, como dados horários ou diários.
Para dados altamente irregulares ou para necessidades comerciais variáveis, os usuários podem, opcionalmente, freqdefinir a frequência de previsão desejada e especificar a target_aggregation_function para agregar a coluna de destino da série temporal. Usar essas duas configurações em seu AutoMLConfig objeto pode ajudar a economizar algum tempo na preparação de dados.
As operações de agregação suportadas para valores de coluna de destino incluem:
| Function | Description |
|---|---|
sum |
Soma dos valores-alvo |
mean |
Média ou média dos valores-alvo |
min |
Valor mínimo de um alvo |
max |
Valor máximo de um alvo |
Habilite o aprendizado profundo
Nota
O suporte DNN para previsão no Automated Machine Learning está em pré-visualização e não é suportado para execuções locais ou iniciadas no Databricks.
Você também pode aplicar deep learning com redes neurais profundas, DNNs, para melhorar as pontuações do seu modelo. A aprendizagem profunda do ML automatizado permite prever dados de séries temporais univariadas e multivariadas.
Os modelos de aprendizagem profunda têm três capacidades intrínsecas:
- Eles podem aprender com mapeamentos arbitrários de entradas para saídas
- Eles suportam várias entradas e saídas
- Eles podem extrair automaticamente padrões em dados de entrada que se estendem por sequências longas.
Para habilitar o aprendizado profundo, defina o enable_dnn=True AutoMLConfig no objeto.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Aviso
Quando você habilita a DNN para experimentos criados com o SDK, as melhores explicações de modelo são desabilitadas.
Para habilitar a DNN para um experimento AutoML criado no estúdio do Azure Machine Learning, consulte as configurações de tipo de tarefa no tutorial da interface do usuário do estúdio.
Agregação da janela rolante de destino
Muitas vezes, a melhor informação para um meteorologista é o valor recente do alvo. As agregações de janela contínua de destino permitem adicionar uma agregação contínua de valores de dados como recursos. Gerar e usar esses recursos como dados contextuais extras ajuda na precisão do modelo de trem.
Por exemplo, digamos que você queira prever a demanda de energia. Você pode querer adicionar um recurso de janela rolante de três dias para levar em conta as mudanças térmicas de espaços aquecidos. Neste exemplo, crie essa janela definindo target_rolling_window_size= 3 no AutoMLConfig construtor.
A tabela mostra a engenharia de recursos resultante que ocorre quando a agregação de janelas é aplicada. As colunas para mínimo, máximo e soma são geradas em uma janela deslizante de três com base nas configurações definidas. Cada linha tem um novo recurso calculado, no caso do carimbo de data/hora para 8 de setembro de 2017 4h00, os valores máximo, mínimo e soma são calculados usando os valores de demanda para 8 de setembro de 2017, das 1h00 às 3h00. Esta janela de três deslocamentos ao longo para preencher os dados para as linhas restantes.

Veja um exemplo de código Python aplicando o recurso de agregação de janela rolante de destino.
Manuseamento em séries curtas
O ML automatizado considera uma série temporal uma série curta se não houver pontos de dados suficientes para conduzir as fases de treinamento e validação do desenvolvimento do modelo. O número de pontos de dados varia para cada experimento e depende do max_horizon, do número de divisões de validação cruzada e do comprimento do lookback do modelo, que é o máximo de histórico necessário para construir os recursos de séries temporais.
O ML automatizado oferece manipulação de séries curtas por padrão com o short_series_handling_configuration parâmetro no ForecastingParameters objeto.
Para permitir o tratamento de séries curtas, o freq parâmetro também deve ser definido. Para definir uma frequência horária, vamos definir freq='H'. Exiba as opções de cadeia de frequência visitando a seção de objetos DataOffset da página de séries temporais pandas. Para alterar o comportamento padrão, short_series_handling_configuration = 'auto'atualize o short_series_handling_configuration parâmetro em seu ForecastingParameter objeto.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
A tabela a seguir resume as configurações disponíveis para short_series_handling_configo .
| Definição | Descrição |
|---|---|
auto |
O valor padrão para manipulação de séries curtas. - Se todas as séries forem curtas, preencha os dados. - Se nem todas as séries são curtas, abandone as séries curtas. |
pad |
Se short_series_handling_config = pad, então o ML automatizado adiciona valores aleatórios a cada série curta encontrada. A seguir estão listados os tipos de coluna e com o que eles são acolchoados: - Colunas de objetos com NaNs - Colunas numéricas com 0 - Colunas booleanas/lógicas com Falso - A coluna alvo é acolchoada com valores aleatórios com média de zero e desvio padrão de 1. |
drop |
Se short_series_handling_config = drop, então o ML automatizado descarta a série curta, e ele não será usado para treinamento ou previsão. As previsões para estas séries regressam às de NaN. |
None |
Nenhuma série é acolchoada ou descartada |
Aviso
O preenchimento pode afetar a precisão do modelo resultante, uma vez que estamos introduzindo dados artificiais apenas para obter treinamento passado sem falhas. Se muitas das séries são curtas, então você também pode ver algum impacto nos resultados de explicabilidade
Deteção e manuseamento de séries cronológicas não estacionárias
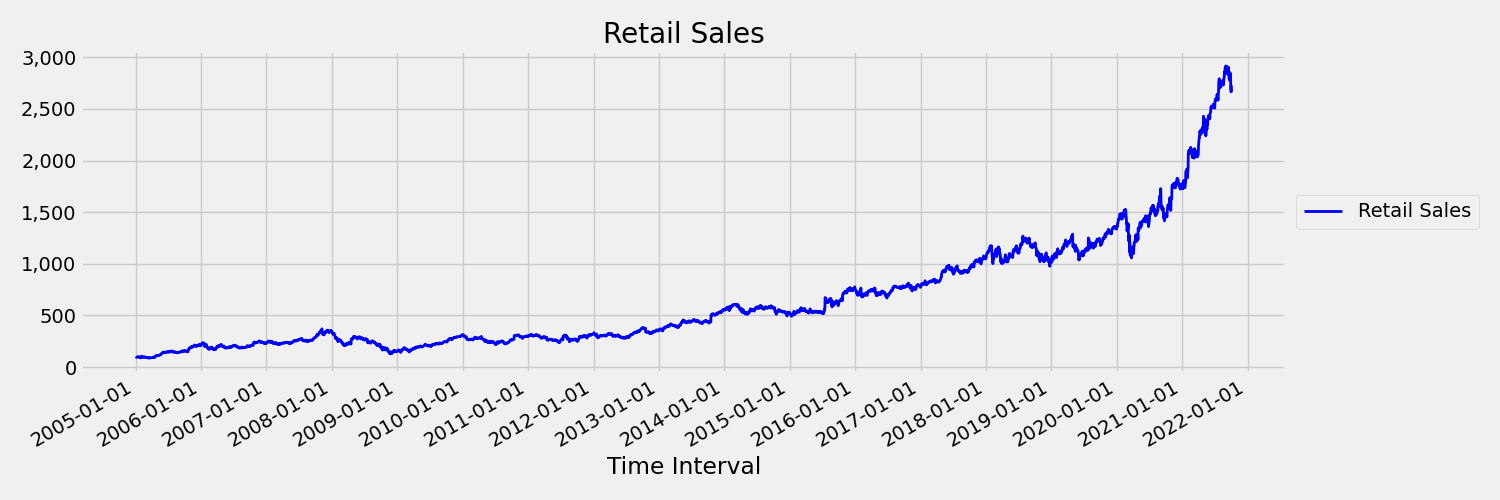
Uma série temporal cujos momentos (média e variância) mudam ao longo do tempo é chamada de não-estacionária. Por exemplo, séries temporais que exibem tendências estocásticas não são estacionárias por natureza. Para visualizar isso, a imagem abaixo traça uma série que geralmente tende a subir. Agora, calcule e compare os valores médios (médios) da primeira e da segunda metade da série. São os mesmos? Aqui, a média da série na primeira metade da trama é menor do que na segunda metade. O fato de que a média da série depende do intervalo de tempo que se está olhando, é um exemplo dos momentos que variam no tempo. Aqui, a média de uma série é o primeiro momento.
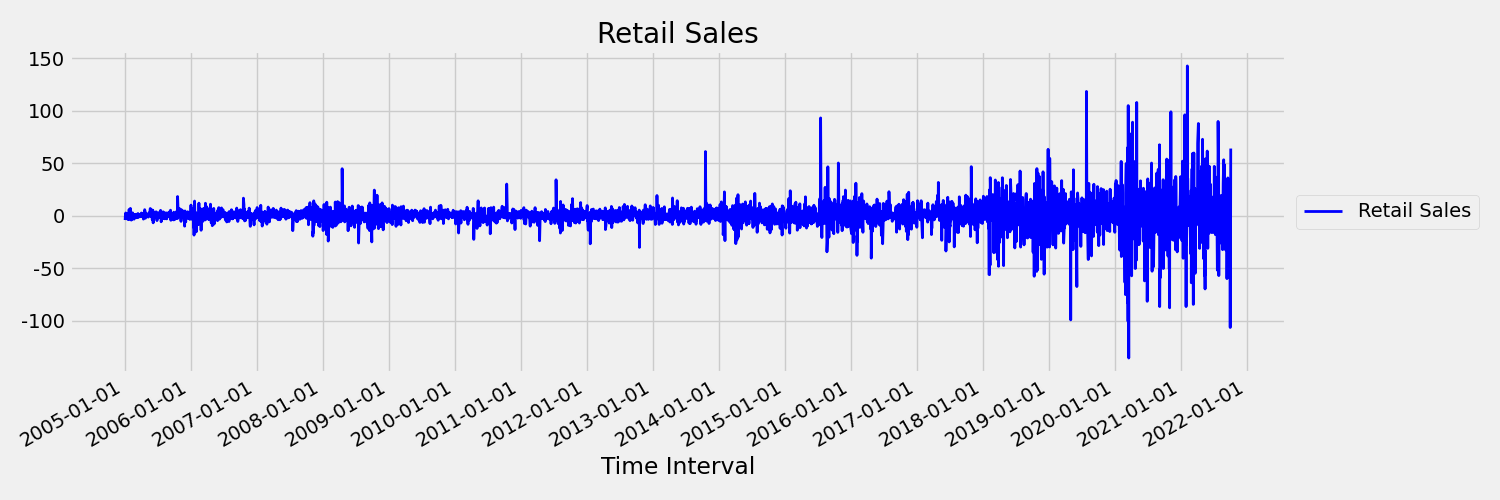
Em seguida, vamos examinar a imagem, que plota a série original em primeiras diferenças, $x_t = y_t - y_{t-1}$ onde $x_t$ é a mudança nas vendas no varejo e $y_t$ e $y_{t-1}$ representam a série original e seu primeiro lag, respectivamente. A média da série é aproximadamente constante, independentemente do período de tempo que se está olhando. Este é um exemplo de uma série temporal estacionária de primeira ordem. A razão pela qual adicionamos o termo de primeira ordem é porque o primeiro momento (média) não muda com o intervalo de tempo, o mesmo não pode ser dito sobre a variância, que é um segundo momento.
Os modelos de aprendizado de máquina AutoML não podem lidar inerentemente com tendências estocásticas ou outros problemas bem conhecidos associados a séries temporais não estacionárias. Como resultado, sua precisão de previsão fora da amostra é "fraca" se tais tendências estiverem presentes.
O AutoML analisa automaticamente o conjunto de dados de séries temporais para verificar se está parado ou não. Quando séries temporais não estacionárias são detetadas, o AutoML aplica uma transformação diferencial automaticamente para atenuar o efeito de séries temporais não estacionárias.
Executar a experimentação
Quando você tiver seu AutoMLConfig objeto pronto, poderá enviar o experimento. Depois que o modelo terminar, recupere a melhor iteração de execução.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Previsão com o melhor modelo
Use a melhor iteração de modelo para prever valores para dados que não foram usados para treinar o modelo.
Avaliando a precisão do modelo com uma previsão contínua
Antes de colocar um modelo em produção, você deve avaliar sua precisão em um conjunto de testes realizado a partir dos dados de treinamento. Um procedimento de práticas recomendadas é a chamada avaliação contínua, que rola o meteorologista treinado para frente no tempo ao longo do conjunto de testes, calculando métricas de erro em média em várias janelas de previsão para obter estimativas estatisticamente robustas para algum conjunto de métricas escolhidas. Idealmente, o conjunto de testes para a avaliação é longo em relação ao horizonte de previsão do modelo. Caso contrário, as estimativas de erro de previsão podem ser estatisticamente ruidosas e, por conseguinte, menos fiáveis.
Por exemplo, suponha que você treine um modelo em vendas diárias para prever a demanda até duas semanas (14 dias) no futuro. Se houver dados históricos suficientes disponíveis, você pode reservar os meses finais até mesmo um ano dos dados para o conjunto de testes. A avaliação contínua começa por gerar uma previsão de 14 dias de antecedência para as duas primeiras semanas do conjunto de testes. Em seguida, o meteorologista é adiantado por algum número de dias no conjunto de testes e você gera outra previsão de 14 dias de antecedência a partir da nova posição. O processo continua até chegar ao final do conjunto de testes.
Para fazer uma avaliação contínua, você chama o rolling_forecast método do fitted_modele, em seguida, calcula as métricas desejadas no resultado. Por exemplo, suponha que você tenha recursos de conjunto de teste em um DataFrame pandas chamado test_features_df e os valores reais do conjunto de teste do destino em uma matriz numpy chamada test_target. Uma avaliação contínua usando o erro quadrático médio é mostrada no exemplo de código a seguir:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
Nesta amostra, o tamanho da etapa para a previsão contínua é definido como um, o que significa que o meteorologista é avançado um período, ou um dia em nosso exemplo de previsão de demanda, em cada iteração. O número total de previsões retornadas rolling_forecast , portanto, depende da duração do conjunto de teste e do tamanho dessa etapa. Para obter mais detalhes e exemplos, consulte a documentação rolling_forecast() e o bloco de anotações Previsão de dados de treinamento.
Previsão para o futuro
A função forecast_quantiles() permite especificações de quando as previsões devem começar, ao contrário do predict() método, que normalmente é usado para tarefas de classificação e regressão. O método forecast_quantiles() por padrão gera uma previsão pontual ou uma previsão média/mediana, que não tem um cone de incerteza ao seu redor. Saiba mais no caderno de dados Previsão longe do treinamento.
No exemplo a seguir, você primeiro substitui todos os valores por y_pred NaN. A origem da previsão está no final dos dados de treinamento neste caso. No entanto, se você substituísse apenas a segunda metade de y_pred com NaN, a função deixaria os valores numéricos na primeira metade inalterados, mas preveja os NaN valores na segunda metade. A função retorna os valores previstos e os recursos alinhados.
Você também pode usar o forecast_destination forecast_quantiles() parâmetro na função para prever valores até uma data especificada.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Muitas vezes, os clientes querem entender as previsões em um quantil específico da distribuição. Por exemplo, quando a previsão é usada para controlar o estoque, como itens de supermercado ou máquinas virtuais para um serviço de nuvem. Nesses casos, o ponto de controle geralmente é algo como "queremos que o item esteja em estoque e não acabe 99% do tempo". A seguir demonstra como especificar quais quantis você gostaria de ver para suas previsões, como percentil 50 ou 95. Se você não especificar um quantil, como no exemplo de código acima mencionado, apenas as previsões do percentil 50 serão geradas.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Você pode calcular métricas do modelo como, erro quadrático médio raiz (RMSE) ou erro percentual absoluto médio (MAPE) para ajudá-lo a estimar o desempenho dos modelos. Consulte a seção Avaliar do bloco de anotações de demanda de compartilhamento de bicicletas para obter um exemplo.
Depois que a precisão geral do modelo tiver sido determinada, a próxima etapa mais realista é usar o modelo para prever valores futuros desconhecidos.
Forneça um conjunto de dados no mesmo formato do conjunto test_dataset de teste, mas com datas/hora futuras, e o conjunto de previsão resultante é os valores previstos para cada etapa da série temporal. Suponha que os últimos registros de séries temporais no conjunto de dados foram para 31/12/2018. Para prever a demanda para o dia seguinte (ou quantos períodos você precisar prever, <= forecast_horizon), crie um único registro de série temporal para cada loja para 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Repita as etapas necessárias para carregar esses dados futuros em um dataframe e, em seguida, execute best_run.forecast_quantiles(test_dataset) para prever valores futuros.
Nota
Não há suporte para previsões na amostra para previsão com ML automatizado quando target_lags e/ou target_rolling_window_size estão habilitadas.
Previsão à escala
Há cenários em que um único modelo de aprendizado de máquina é insuficiente e vários modelos de aprendizado de máquina são necessários. Por exemplo, prever as vendas de cada loja individual para uma marca ou adaptar uma experiência a utilizadores individuais. A criação de um modelo para cada instância pode levar a melhores resultados em muitos problemas de aprendizado de máquina.
O agrupamento é um conceito na previsão de séries temporais que permite combinar séries temporais para treinar um modelo individual por grupo. Essa abordagem pode ser particularmente útil se você tiver séries temporais que exijam suavização, preenchimento ou entidades no grupo que podem se beneficiar do histórico ou tendências de outras entidades. Muitos modelos e previsões hierárquicas de séries temporais são soluções alimentadas por aprendizado de máquina automatizado para esses cenários de previsão em larga escala.
Muitos modelos
A solução de muitos modelos do Azure Machine Learning com aprendizado de máquina automatizado permite que os usuários treinem e gerenciem milhões de modelos em paralelo. Muitos modelos O acelerador de solução usa pipelines do Azure Machine Learning para treinar o modelo. Especificamente, um objeto Pipeline e ParalleRunStep são usados e exigem parâmetros de configuração específicos definidos por meio do ParallelRunConfig.
O diagrama a seguir mostra o fluxo de trabalho para a solução de muitos modelos.

O código a seguir demonstra os principais parâmetros que os usuários precisam para configurar seus muitos modelos executados. Consulte o notebook Muitos modelos - ML automatizado para obter um exemplo de previsão de muitos modelos
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Previsão hierárquica de séries cronológicas
Na maioria das aplicações, os clientes têm a necessidade de entender suas previsões em um nível macro e micro do negócio. Os forcasts podem prever vendas de produtos em diferentes localizações geográficas ou entender a demanda esperada de força de trabalho para diferentes organizações em uma empresa. A capacidade de treinar um modelo de aprendizado de máquina para prever de forma inteligente os dados da hierarquia é essencial.
Uma série temporal hierárquica é uma estrutura na qual cada uma das séries únicas é organizada em uma hierarquia com base em dimensões como, geografia ou tipo de produto. O exemplo a seguir mostra dados com atributos exclusivos que formam uma hierarquia. Nossa hierarquia é definida por: o tipo de produto, como fones de ouvido ou tablets, a categoria de produto, que divide os tipos de produto em acessórios e dispositivos, e a região em que os produtos são vendidos.

Para visualizar ainda mais isso, os níveis de folha da hierarquia contêm todas as séries temporais com combinações exclusivas de valores de atributos. Cada nível superior na hierarquia considera uma dimensão a menos para definir a série temporal e agrega cada conjunto de nós filho do nível inferior em um nó pai.

A solução de séries cronológicas hierárquicas é construída sobre a Solução de Muitos Modelos e partilha uma configuração semelhante.
O código a seguir demonstra os parâmetros-chave para configurar suas execuções hierárquicas de previsão de séries temporais. Consulte o Bloco de anotações cronológicas hierárquicas - Notebook de ML automatizado, para obter um exemplo de ponta a ponta.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Blocos de notas de exemplo
Veja os blocos de notas de previsão de exemplo para obter exemplos de código detalhados de configuração de previsão avançada, incluindo:
- Deteção e caracterização de feriados
- Validação entre origens de implementação
- Atrasos configuráveis
- Funcionalidades agregadas de janelas de implementação
Próximos passos
- Saiba mais sobre Como implantar um modelo AutoML em um ponto de extremidade online.
- Saiba mais sobre Interpretabilidade: explicações de modelo em aprendizado de máquina automatizado (visualização).
- Saiba mais sobre como o AutoML cria modelos de previsão.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários