Resolver problemas nos pipelines de aprendizagem automática
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste artigo, você aprenderá a solucionar problemas quando receber erros ao executar um pipeline de aprendizado de máquina no SDK do Azure Machine Learning e no designer do Azure Machine Learning.
Sugestões de resolução de problemas
A tabela seguinte apresenta problemas comuns durante o desenvolvimento de pipelines, com soluções possíveis.
| Problema | Solução possível |
|---|---|
Não é possível transmitir dados para o diretório PipelineData |
Verifique se criou um diretório no script correspondente ao local onde o pipeline aguarda os dados de saída do passo. Na maioria dos casos, um argumento de entrada define o diretório de saída e, em seguida, você cria o diretório explicitamente. Utilize os.makedirs(args.output_dir, exist_ok=True) para criar o diretório de saída. Veja o tutorial para obter um exemplo de script de classificação que mostra este padrão de design. |
| Erros de dependência | Se você vir erros de dependência em seu pipeline remoto que não ocorreram durante o teste local, confirme se as dependências e versões do ambiente remoto correspondem às do seu ambiente de teste. (Ver Criação, armazenamento em cache e reutilização de ambientes |
| Erros ambíguos com destinos de computação | Tente eliminar e recriar os destinos de computação. A recriação de destinos de computação é rápida e pode resolver alguns problemas transitórios. |
| O pipeline não está a reutilizar os passos | A reutilização de passos está ativada por predefinição, mas garanta que não a desativou num passo do pipeline. Se a reutilização estiver desativada, o allow_reuse parâmetro na etapa será definido como False. |
| O pipeline está a voltar a ser executado desnecessariamente | Para garantir que os passos só voltam a ser executados quando os dados ou scripts subjacentes forem alterados, desassocie os diretórios de código de origem de cada passo. Se utilizar o mesmo diretório de origem para vários passos, poderão ocorrer repetições desnecessárias. Use o source_directory parâmetro em um objeto de etapa de pipeline para apontar para o diretório isolado para essa etapa e verifique se você não está usando o mesmo source_directory caminho para várias etapas. |
| Passo a abrandar ao longo das épocas da preparação ou outro comportamento em ciclo | Tente mudar as escritas de ficheiros, incluindo o registo, de as_mount() para as_upload(). O modo de montagem utiliza um sistema de ficheiros virtualizado remoto e carrega todo o ficheiro sempre que este é anexado. |
| O destino de computação demora muito tempo a ser iniciado | As imagens do Docker para destinos de computação são carregadas do Azure Container Registry (ACR). Por padrão, o Aprendizado de Máquina do Azure cria uma ACR que usa a camada de serviço básica . Mudar o ACR da área de trabalho para o escalão standard ou premium pode reduzir o tempo de criação e carregamento de imagens. Para obter mais informações, veja Escalões de serviço do Azure Container Registry (ACR). |
Erros de autenticação
Se você executar uma operação de gerenciamento em um destino de computação a partir de um trabalho remoto, receberá um dos seguintes erros:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Por exemplo, você recebe um erro se tentar criar ou anexar um destino de computação de um pipeline de ML enviado para execução remota.
Solução de problemas ParallelRunStep
O script para um ParallelRunStep deve conter duas funções:
init(): Use esta função para qualquer preparação dispendiosa ou comum para inferência posterior. Por exemplo, use-o para carregar o modelo em um objeto global. Esta função é chamada apenas uma vez no início do processo.run(mini_batch): A função é executada para cadamini_batchinstância.mini_batch:ParallelRunStepinvoca o método run e passa uma lista ou pandasDataFramecomo um argumento para o método. Cada entrada no mini_batch é um caminho de arquivo se a entrada for umFileDatasetou um pandasDataFramese a entrada for umTabularDataset.response: run() método deve retornar um pandasDataFrameou uma matriz. Por append_row output_action, esses elementos retornados são anexados ao arquivo de saída comum. Por summary_only, o conteúdo dos elementos é ignorado. Para todas as ações de saída, cada elemento de saída retornado indica uma execução bem-sucedida do elemento de entrada no minilote de entrada. Certifique-se de que dados suficientes estão incluídos no resultado da execução para mapear a entrada para executar o resultado da saída. A saída de execução é escrita no arquivo de saída e não é garantido que esteja em ordem, você deve usar alguma chave na saída para mapeá-la para a entrada.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Se você tiver outro arquivo ou pasta no mesmo diretório do script de inferência, poderá fazer referência a ele localizando o diretório de trabalho atual.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parâmetros para ParallelRunConfig
ParallelRunConfig é a configuração principal, por ParallelRunStep exemplo, dentro do pipeline do Azure Machine Learning. Você o usa para encapsular seu script e configurar os parâmetros necessários, incluindo todas as seguintes entradas:
entry_script: Um script de usuário como um caminho de arquivo local que é executado em paralelo em vários nós. Sesource_directoryestiver presente, use um caminho relativo. Caso contrário, use qualquer caminho acessível na máquina.mini_batch_size: O tamanho do minilote passado para uma únicarun()chamada. (opcional; o valor padrão é10arquivos paraFileDatasete1MBparaTabularDataset.)- Para
FileDataset, é o número de arquivos com um valor mínimo de1. Você pode combinar vários arquivos em um minilote. - Para
TabularDataset, é o tamanho dos dados. Os valores de exemplo são1024,1024KB,10MBe1GB. O valor recomendado é1MB. O minilote de nunca cruzará os limites doTabularDatasetarquivo. Por exemplo, se você tiver .csv arquivos com vários tamanhos, o menor arquivo é de 100 KB e o maior é de 10 MB. Se você definirmini_batch_size = 1MBo , os arquivos com tamanho menor que 1 MB serão tratados como um minilote. Os ficheiros com um tamanho superior a 1 MB são divididos em vários mini-lotes.
- Para
error_threshold: O número de falhasTabularDatasetde registro e falhas de arquivo paraFileDatasetisso deve ser ignorado durante o processamento. Se a contagem de erros para toda a entrada ultrapassar esse valor, o trabalho será abortado. O limite de erro é para toda a entrada e não para o minilote individual enviado para orun()método. O intervalo é[-1, int.max]. A-1peça indica ignorar todas as falhas durante o processamento.output_action: Um dos seguintes valores indica como a saída é organizada:summary_only: O script de usuário armazena a saída.ParallelRunStepusa a saída apenas para o cálculo do limite de erro.append_row: Para todas as entradas, apenas um arquivo é criado na pasta de saída para acrescentar todas as saídas separadas por linha.
append_row_file_name: Para personalizar o nome do arquivo de saída para append_row output_action (opcional; o valor padrão éparallel_run_step.txt).source_directory: Caminhos para pastas que contêm todos os arquivos a serem executados no destino de computação (opcional).compute_target: SomenteAmlComputeé suportado.node_count: O número de nós de computação a serem usados para executar o script do usuário.process_count_per_node: O número de processos por nó. A prática recomendada é definir o número de GPU ou CPU que um nó tem (opcional; o valor padrão é1).environment: A definição do ambiente Python. Você pode configurá-lo para usar um ambiente Python existente ou para configurar um ambiente temporário. A definição também é responsável por definir as dependências de aplicativo necessárias (opcional).logging_level: Log verbosidade. Os valores no aumento da verbosidade são:WARNING,INFO, eDEBUG. (opcional; o valor padrão éINFO)run_invocation_timeout: Orun()tempo limite de invocação do método em segundos. (opcional; o valor padrão é60)run_max_try: Contagem máxima de tentativas pararun()um minilote. Arun()falhará se uma exceção for lançada ou nada for retornado quandorun_invocation_timeoutfor atingido (opcional; o valor padrão será3).
Você pode especificar mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout, e run_max_try como PipelineParameter, para que, ao reenviar uma execução de pipeline, possa ajustar os valores dos parâmetros. Neste exemplo, você usa PipelineParameter para mini_batch_size e Process_count_per_node altera esses valores quando reenvia uma execução mais tarde.
Parâmetros para criar o ParallelRunStep
Crie o ParallelRunStep usando o script, a configuração do ambiente e os parâmetros. Especifique o destino de computação que você já anexou ao seu espaço de trabalho como o destino de execução para seu script de inferência. Use ParallelRunStep para criar a etapa de pipeline de inferência em lote, que usa todos os seguintes parâmetros:
name: O nome da etapa, com as seguintes restrições de nomenclatura: exclusivo, 3-32 caracteres e regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: UmParallelRunConfigobjeto, conforme definido anteriormente.inputs: Um ou mais conjuntos de dados do Azure Machine Learning de tipo único a serem particionados para processamento paralelo.side_inputs: Um ou mais dados de referência ou conjuntos de dados usados como entradas laterais sem a necessidade de serem particionados.output: UmOutputFileDatasetConfigobjeto que corresponde ao diretório de saída.arguments: Uma lista de argumentos passados para o script de usuário. Use unknown_args para recuperá-los em seu script de entrada (opcional).allow_reuse: Se a etapa deve reutilizar resultados anteriores quando executada com as mesmas configurações/entradas. Se esse parâmetro forFalse, uma nova execução será gerada para esta etapa durante a execução do pipeline. (opcional; o valor padrão éTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Técnicas de depuração
Existem três técnicas principias para depurar pipelines:
- Depurar os passos de pipeline individuais no computador local
- Utilizar o registo e o Application Insights para isolar e diagnosticar a origem do problema
- Anexar um depurador remoto a um pipeline em execução no Azure
Depurar scripts localmente
Uma das falhas mais comuns em um pipeline é que o script de domínio não é executado como pretendido ou contém erros de tempo de execução no contexto de computação remota que são difíceis de depurar.
Os oleodutos em si não podem ser executados localmente. Mas executar os scripts isoladamente em sua máquina local permite que você depure mais rápido porque você não precisa esperar pelo processo de compilação de computação e ambiente. Algum trabalho de desenvolvimento é necessário para fazer isso:
- Se os dados estiverem em um armazenamento de dados na nuvem, você precisará baixar os dados e disponibilizá-los para o script. Usar uma pequena amostra de seus dados é uma boa maneira de reduzir o tempo de execução e obter rapidamente feedback sobre o comportamento do script
- Se você estiver tentando simular uma etapa de pipeline intermediária, talvez seja necessário criar manualmente os tipos de objeto que o script específico está esperando da etapa anterior
- Você precisa definir seu próprio ambiente e replicar as dependências definidas em seu ambiente de computação remota
Depois de ter uma configuração de script para ser executada em seu ambiente local, é mais fácil fazer tarefas de depuração como:
- Anexando uma configuração de depuração personalizada
- Pausando a execução e inspecionando o estado do objeto
- Detetando erros lógicos ou de tipo que não serão expostos até o tempo de execução
Gorjeta
Depois de verificar se o script está sendo executado conforme o esperado, uma boa próxima etapa é executar o script em um pipeline de uma única etapa antes de tentar executá-lo em um pipeline com várias etapas.
Configurar, gravar e revisar logs de pipeline
Testar scripts localmente é uma ótima maneira de depurar os principais fragmentos de código e a lógica complexa antes de começar a criar um pipeline. Em algum momento, você precisa depurar scripts durante a própria execução do pipeline, especialmente ao diagnosticar o comportamento que ocorre durante a interação entre as etapas do pipeline. Recomendamos o uso liberal de instruções em seus scripts de etapa para que você possa ver o estado do print() objeto e os valores esperados durante a execução remota, semelhante a como você depuraria o código JavaScript.
Opções e comportamento de registro em log
A tabela a seguir fornece informações para diferentes opções de depuração para pipelines. Não é uma lista exaustiva, pois existem outras opções além apenas das do Azure Machine Learning, Python e OpenCensus mostradas aqui.
| Biblioteca | Tipo | Exemplo | Destino | Recursos |
|---|---|---|---|---|
| Azure Machine Learning SDK | Metric | run.log(name, val) |
IU do Portal do Azure Machine Learning | Como monitorizar as experimentações azureml.core.Run class |
| Registo/impressão Python | Registo | print(val)logging.info(message) |
Registos do controlador, estruturador do Azure Machine Learning | Como monitorizar as experimentações Registo Python |
| OpenCensus Python | Registo | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights – rastreios | Depurar pipelines no Application Insights OpenCensus Azure Monitor Exporters (Exportadores do Azure Monitor do OpenCensus) Guia detalhado do registo Python |
Exemplo de opções de registo
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Estruturador do Azure Machine Learning
Para pipelines criados no designer, você pode encontrar o arquivo 70_driver_log na página de criação ou na página de detalhes da execução do pipeline.
Habilite o registro em log para pontos de extremidade em tempo real
Para solucionar problemas e depurar pontos de extremidade em tempo real no designer, você deve habilitar o log do Application Insight usando o SDK. O registro em log permite solucionar e depurar problemas de implantação e uso do modelo. Para obter mais informações, consulte Registro em log para modelos implantados.
Obter logs da página de criação
Quando você envia uma execução de pipeline e permanece na página de criação, você pode encontrar os arquivos de log gerados para cada componente à medida que cada componente termina de ser executado.
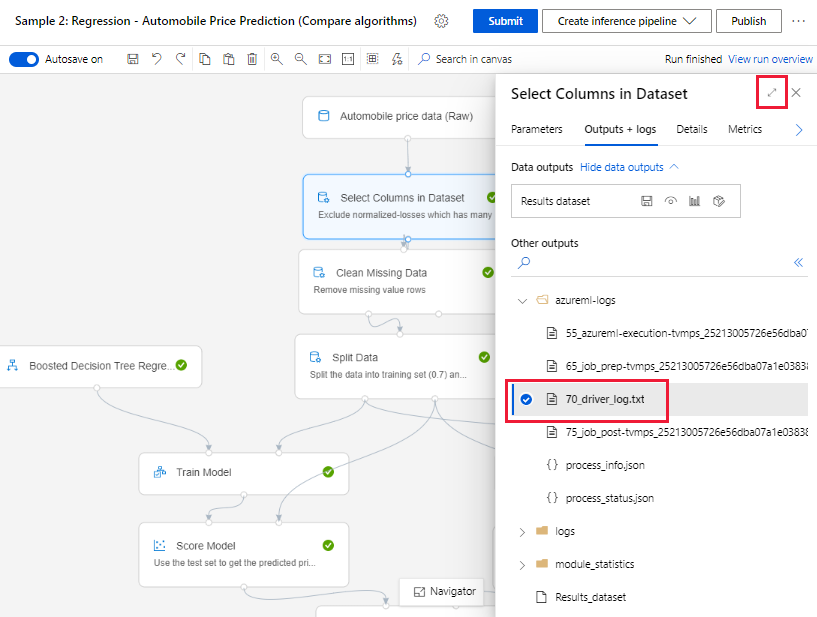
Selecione um componente que tenha terminado de ser executado na tela de criação.
No painel direito do componente, vá para a guia Saídas + logs .
Expanda o painel direito e selecione o 70_driver_log.txt para exibir o arquivo no navegador. Você também pode baixar logs localmente.
Obter logs de execuções de pipeline
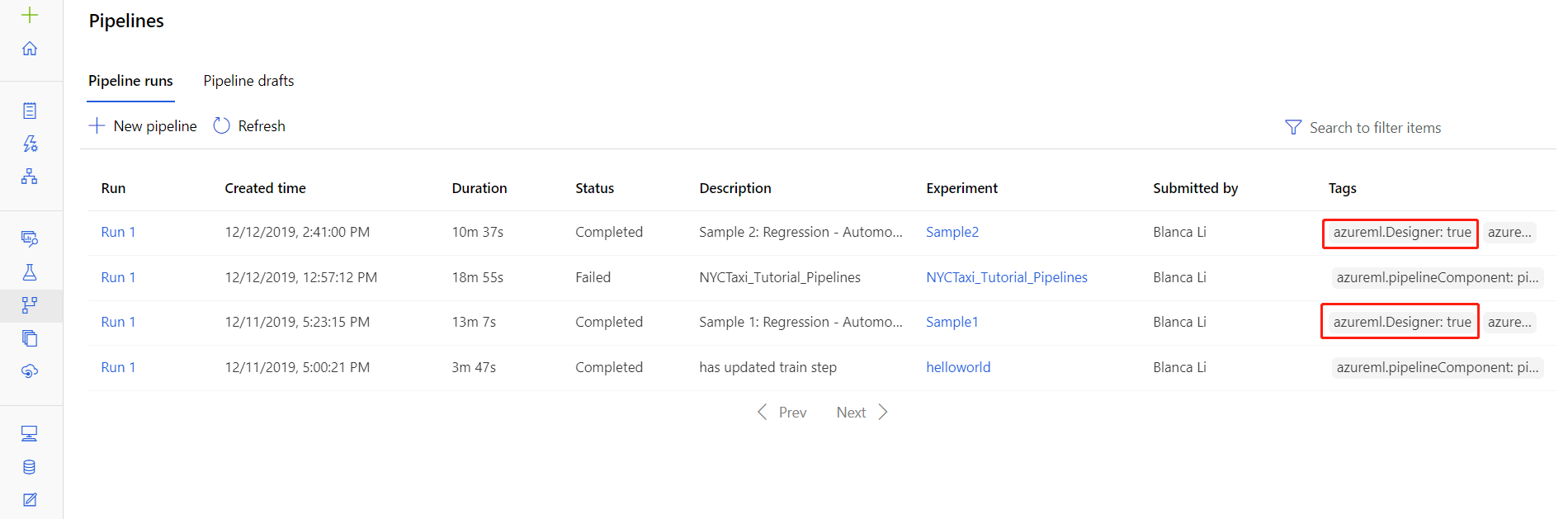
Você também pode encontrar os arquivos de log para execuções específicas na página de detalhes da execução do pipeline, que pode ser encontrada na seção Pipelines ou Experimentos do estúdio.
Selecione uma execução de pipeline criada no designer.
Selecione um componente no painel de visualização.
No painel direito do componente, vá para a guia Saídas + logs .
Expanda o painel direito para exibir o arquivo std_log.txt no navegador ou selecione o arquivo para baixar os logs localmente.
Importante
Para atualizar um pipeline a partir da página de detalhes da execução do pipeline, você deve clonar o pipeline executado para um novo rascunho do pipeline. Uma execução de pipeline é um instantâneo do pipeline. É semelhante a um arquivo de log e não pode ser alterado.
Application Insights
Para obter mais informações sobre como usar a biblioteca OpenCensus Python dessa maneira, consulte este guia: Depurar e solucionar problemas de pipelines de aprendizado de máquina no Application Insights
Depuração interativa com o Visual Studio Code
Em determinados casos, poderá ter de depurar interativamente o código do Python utilizado no pipeline do ML. Ao utilizar o Visual Studio Code (VS Code) e debugpy, pode anexar ao código tal como é executado no ambiente de preparação. Para obter mais informações, veja a depuração interativa no guia do VS Code.
HyperdriveStep e AutoMLStep falham com isolamento de rede
Depois de usar HyperdriveStep e AutoMLStep, quando você tenta registrar o modelo, você pode receber um erro.
Você está usando o SDK do Azure Machine Learning v1.
Seu espaço de trabalho do Azure Machine Learning está configurado para isolamento de rede (VNet).
Seu pipeline tenta registrar o modelo gerado pela etapa anterior. Por exemplo, no exemplo a seguir, o
inputsparâmetro é o saved_model de um HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Solução
Importante
Esse comportamento não ocorre ao usar o SDK do Azure Machine Learning v2.
Para contornar esse erro, use a classe Run para obter o modelo criado a partir do HyperdriveStep ou AutoMLStep. A seguir está um script de exemplo que obtém o modelo de saída de um HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
O arquivo pode então ser usado a partir de um PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Próximos passos
Para obter um tutorial completo usando
ParallelRunStepo , consulte Tutorial: Criar um pipeline do Azure Machine Learning para pontuação em lote.Para obter um exemplo completo mostrando o aprendizado de máquina automatizado em pipelines de ML, consulte Usar ML automatizado em um pipeline do Azure Machine Learning em Python.
Consulte a referência do SDK para obter ajuda com o pacote azureml-pipelines-core e o pacote azureml-pipelines-steps .
Consulte a lista de exceções e códigos de erro do designer.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários