Como implantar modelos Cohere Embed com o estúdio Azure Machine Learning
A Cohere oferece dois modelos Embed no estúdio Azure Machine Learning. Esses modelos estão disponíveis como APIs sem servidor com faturamento pré-pago baseado em token.
- Cohere Embed v3 - Português
- Cohere Embed v3 - Multilingue
Você pode navegar pela família de modelos Cohere no catálogo de modelos filtrando a coleção Cohere.
Modelos
Neste artigo, você aprenderá a usar o estúdio do Azure Machine Learning para implantar os modelos Cohere como uma API sem servidor com cobrança paga conforme o uso.
Cohere Embed v3 - Português
Cohere Embed English é o principal modelo de representação de texto do mercado usado para pesquisa semântica, geração aumentada de recuperação (RAG), classificação e clustering. Embed English tem o melhor desempenho no benchmark MTEB HuggingFace e tem um bom desempenho em vários setores, como Finanças, Jurídico e Corpora de Uso Geral.
- Embed English tem 1.024 dimensões.
- A janela de contexto do modelo é de 512 tokens.
Cohere Embed v3 - Multilingue
Cohere Embed Multilingual é o principal modelo de representação de texto do mercado usado para pesquisa semântica, geração aumentada de recuperação (RAG), classificação e clustering. Incorporar Multilingue suporta 100+ idiomas e pode ser usado para pesquisar dentro de um idioma (por exemplo, pesquisa com uma consulta francesa em documentos franceses) e entre idiomas (por exemplo, pesquisa com uma consulta em inglês em documentos chineses). Incorporar multilíngue tem desempenho SOTA em benchmarks multilíngues como Miracl.
- O Embed Multilingual tem 1.024 dimensões.
- A janela de contexto do modelo é de 512 tokens.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Implantar como uma API sem servidor
Certos modelos no catálogo de modelos podem ser implantados como uma API sem servidor com faturamento pré-pago, fornecendo uma maneira de consumi-los como uma API sem hospedá-los em sua assinatura, mantendo a segurança corporativa e a conformidade de que as organizações precisam. Essa opção de implantação não exige cota da sua assinatura.
Os modelos Cohere mencionados anteriormente podem ser implantados como um serviço com pagamento conforme o uso e são oferecidos pela Cohere por meio do Microsoft Azure Marketplace. A Cohere pode alterar ou atualizar os termos de uso e preços deste modelo.
Pré-requisitos
Uma subscrição do Azure com um método de pagamento válido. As subscrições gratuitas ou de avaliação do Azure não funcionarão. Se você não tiver uma assinatura do Azure, crie uma conta paga do Azure para começar.
Uma área de trabalho do Azure Machine Learning. Se você não tiver esses recursos, use as etapas no artigo Guia de início rápido: criar recursos do espaço de trabalho para criá-los. A oferta de implantação de modelo de API sem servidor para Cohere Embed só está disponível com espaços de trabalho criados nestas regiões:
- E.U.A. Leste
- E.U.A. Leste 2
- E.U.A. Centro-Norte
- E.U.A. Centro-Sul
- E.U.A. Oeste
- EUA Oeste 3
- Suécia Central
Para obter uma lista das regiões disponíveis para cada um dos modelos que suportam implementações de ponto final de API sem servidor, consulte Disponibilidade regional para modelos em pontos finais de API sem servidor.
Os controles de acesso baseados em função do Azure (Azure RBAC) são usados para conceder acesso às operações. Para executar as etapas neste artigo, sua conta de usuário deve receber a função de Desenvolvedor do Azure AI no Grupo de Recursos.
Para obter mais informações sobre permissões, consulte Gerir o acesso a um espaço de trabalho do Azure Machine Learning.
Criar uma nova implantação
Para criar uma implantação:
Vá para o estúdio do Azure Machine Learning.
Selecione o espaço de trabalho no qual você deseja implantar seus modelos. Para usar a oferta de implantação do modelo pré-pago, seu espaço de trabalho deve pertencer à região EastUS2 ou Sweden Central.
Escolha o modelo que deseja implantar no catálogo de modelos.
Como alternativa, você pode iniciar a implantação acessando seu espaço de trabalho e selecionando Pontos>de extremidade>sem servidor Criar.
Na página de visão geral do modelo no catálogo de modelos, selecione Implantar.

No assistente de implantação, selecione o link para Termos do Azure Marketplace para saber mais sobre os termos de uso.
Você também pode selecionar a guia Detalhes da oferta do Marketplace para saber mais sobre os preços do modelo selecionado.
Se esta for a primeira vez que você implanta o modelo no espaço de trabalho, você precisa inscrever seu espaço de trabalho para a oferta específica do modelo. Esta etapa requer que sua conta tenha as permissões da função Desenvolvedor do Azure AI no Grupo de Recursos, conforme listado nos pré-requisitos. Cada espaço de trabalho tem a sua própria subscrição para a oferta específica do Azure Marketplace, que lhe permite controlar e monitorizar os gastos. Selecione Inscrever-se e Implantar. Atualmente, você pode ter apenas uma implantação para cada modelo em um espaço de trabalho.
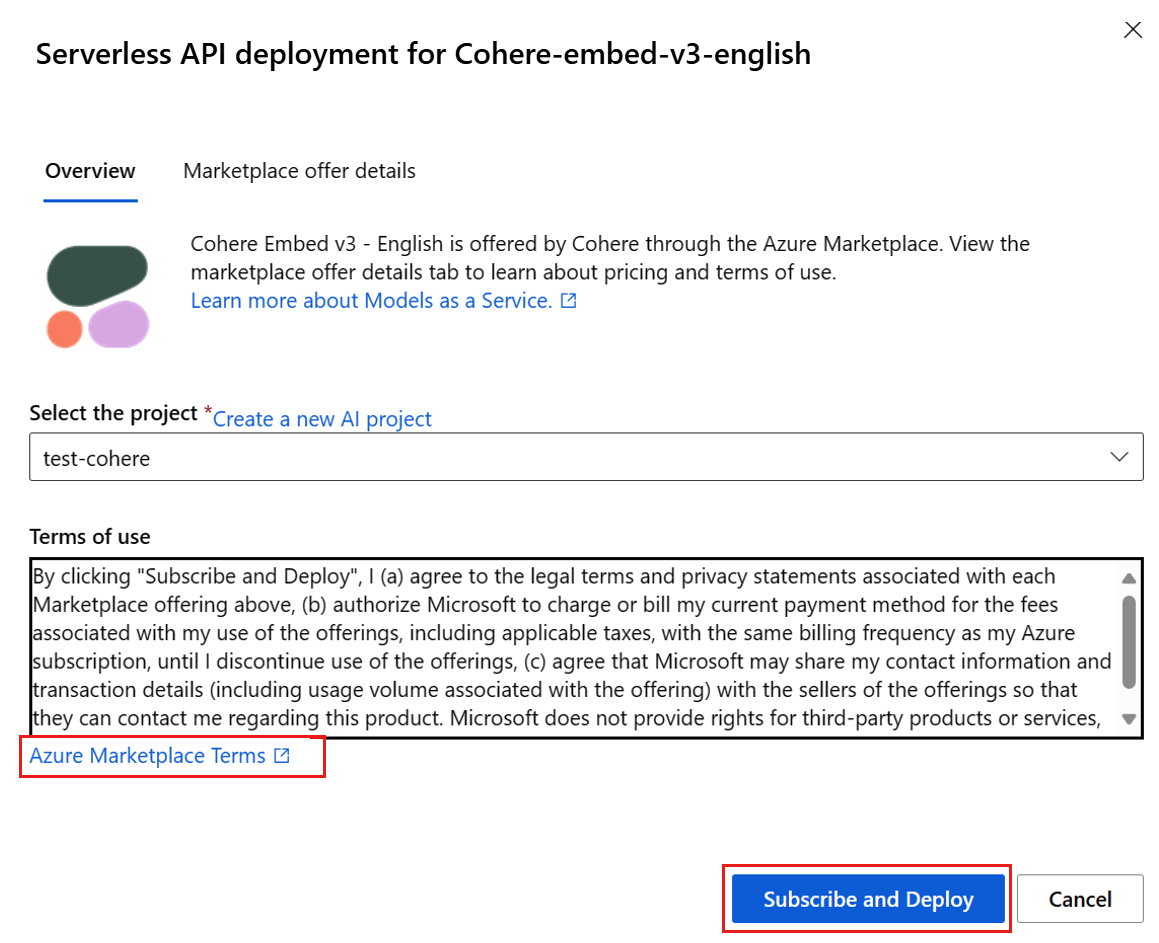
Depois de inscrever o espaço de trabalho para a oferta específica do Azure Marketplace, as implantações subsequentes da mesma oferta no mesmo espaço de trabalho não exigem assinatura novamente. Se esse cenário se aplicar a você, há uma opção Continuar a implantar para selecionar.

Dê um nome à implantação. Esse nome se torna parte da URL da API de implantação. Essa URL deve ser exclusiva em cada região do Azure.
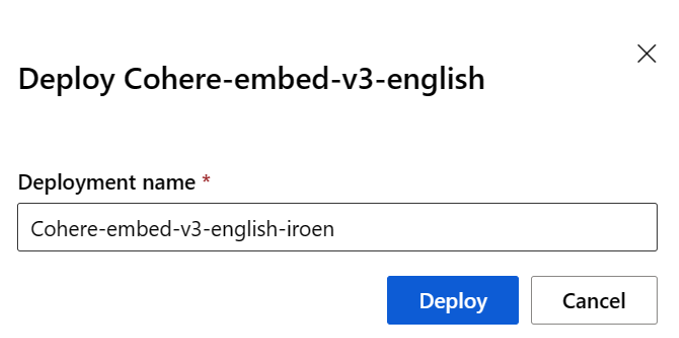
Selecione Implementar. Aguarde até que a implantação seja concluída e você seja redirecionado para a página de pontos de extremidade sem servidor.
Selecione o ponto de extremidade para abrir a página Detalhes.
Selecione a guia Teste para começar a interagir com o modelo.
Você sempre pode encontrar os detalhes, a URL e as chaves de acesso do ponto de extremidade navegando até Pontos de extremidade sem servidor de pontos de extremidade de espaço de trabalho>>.
Anote o URL de destino e a chave secreta. Para obter mais informações sobre como usar as APIs, consulte a seção [reference] (#embed-api-reference-for-cohere-embed-models-deployed-as-a-serverless-api).




Para saber mais sobre a cobrança de modelos implantados com pagamento conforme o uso, consulte Considerações sobre custo e cota para modelos Cohere implantados como um serviço.
Consuma os modelos implantados como uma API sem servidor
Os modelos Cohere mencionados anteriormente podem ser consumidos usando a API de chat.
No espaço de trabalho, selecione Pontos de extremidade> sem servidor.
Localize e selecione a implantação que você criou.
Copie a URL de destino e os valores do token de chave .
Cohere expõe duas rotas para inferência com os modelos Embed v3 - English e Embed v3 - Multilingual .
v1/embeddingsadere ao esquema da API de Mensagens Generativas da IA do Azure ev1/embeddá suporte ao esquema de API nativo do Cohere.Para obter mais informações sobre como usar as APIs, consulte a seção de referência .
Incorporar referência de API para modelos Cohere Embed implantados como uma API sem servidor
Cohere Embed v3 - English e Embed v3 - Multilingual aceitam aAPI de Inferência de Modelos do Azure AI na rota /embeddings (para texto) e /images/embeddings (para imagens) e a API Cohere Embed v3 nativa em /embed.
API de Inferência de Modelos do Azure AI
O esquema da API de Inferência de Modelos do Azure AI está disponível nos artigos seguintes:
Uma especificação OpenAPI pode ser obtida do próprio ponto final.
Cohere Incorporar v3
O seguinte contém detalhes sobre Cohere Embed v3 API.
Pedir
POST /v1/embed HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Esquema de solicitação v1/embed
Cohere Embed v3 - English e Embed v3 - Multilingual aceitam os seguintes parâmetros para uma v1/embed chamada de API:
| Chave | Type | Predefinido | Description |
|---|---|---|---|
texts |
array of strings |
Obrigatório | Uma matriz de cadeias de caracteres para o modelo incorporar. O número máximo de mensagens de texto por chamada é de 96. Recomendamos reduzir o comprimento de cada texto para menos de 512 tokens para uma qualidade ideal. |
input_type |
enum string |
Necessário | Precede tokens especiais para diferenciar cada tipo um do outro. Você não deve misturar tipos diferentes, exceto ao misturar tipos para pesquisa e recuperação. Neste caso, incorpore o seu corpus com o tipo e incorpore as consultas com o search_document tipo de tipo search_query . search_document – Em casos de uso de pesquisa, use search_document quando codificar documentos para incorporações que você armazena em um banco de dados vetorial. search_query – Use search_query ao consultar seu banco de dados vetorial para encontrar documentos relevantes. classification – Use a classificação ao usar incorporações como uma entrada para um classificador de texto. clustering – Use clustering para agrupar as incorporações. |
truncate |
enum string |
NONE |
NONE – Retorna um erro quando a entrada excede o comprimento máximo do token de entrada. START – Descarta o início da entrada. END – Descarta o final da entrada. |
embedding_types |
array of strings |
float |
Especifica os tipos de incorporações que você deseja recuperar. Pode ser um ou mais dos seguintes tipos. float, int8, uint8, binary, ubinary |
Esquema de resposta v1/embed
Cohere Embed v3 - English e Embed v3 - Multilingual incluem os seguintes campos na resposta:
| Chave | Tipo | Description |
|---|---|---|
response_type |
enum |
O tipo de resposta. Retorna embeddings_floats quando embedding_types não é especificado ou retorna embeddings_by_type quando embeddings_types é especificado. |
id |
integer |
Um identificador para a resposta. |
embeddings |
array ou array of objects |
Uma matriz de incorporações, onde cada incorporação é uma matriz de flutuadores com 1.024 elementos. O comprimento da matriz de incorporações é o mesmo que o comprimento da matriz de textos originais. |
texts |
array of strings |
As entradas de texto para as quais as incorporações foram retornadas. |
meta |
string |
Dados de uso da API, incluindo a versão atual e tokens faturáveis. |
Para obter mais informações, veja https://docs.cohere.com/reference/embed.
Exemplos v1/embed
Embeddings_floats resposta
Pedido:
{
"input_type": "clustering",
"truncate": "START",
"texts":["hi", "hello"]
}
Resposta:
{
"id": "da7a104c-e504-4349-bcd4-4d69dfa02077",
"texts": [
"hi",
"hello"
],
"embeddings": [
[
...
],
[
...
]
],
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 2
}
},
"response_type": "embeddings_floats"
}
Embeddings_by_types resposta
Pedido:
{
"input_type": "clustering",
"embedding_types": ["int8", "binary"],
"truncate": "START",
"texts":["hi", "hello"]
}
Resposta:
{
"id": "b604881a-a5e1-4283-8c0d-acbd715bf144",
"texts": [
"hi",
"hello"
],
"embeddings": {
"binary": [
[
...
],
[
...
]
],
"int8": [
[
...
],
[
...
]
]
},
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 2
}
},
"response_type": "embeddings_by_type"
}
Exemplos adicionais de inferência
| Pacote | Bloco de notas de exemplo |
|---|---|
| CLI usando solicitações da Web CURL e Python | cohere-embed.ipynb |
| OpenAI SDK (experimental) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Cohere SDK | cohere-sdk.ipynb |
| LiteLLM SDK | litellm.ipynb |
Geração aumentada de recuperação (RAG) e amostras de uso de ferramentas
| Descrição | Pacote | Bloco de notas de exemplo |
|---|---|---|
| Crie um índice vetorial local do Facebook AI Similarity Search (FAISS), usando incorporações Cohere - Langchain | langchain, langchain_cohere |
cohere_faiss_langchain_embed.ipynb |
| Use o comando Cohere R/R+ para responder a perguntas de dados no índice vetorial FAISS local - Langchain | langchain, langchain_cohere |
command_faiss_langchain.ipynb |
| Use o comando Cohere R/R+ para responder a perguntas de dados no índice vetorial de pesquisa de IA - Langchain | langchain, langchain_cohere |
cohere-aisearch-langchain-rag.ipynb |
| Use o Cohere Command R/R+ para responder a perguntas de dados no índice de vetores de pesquisa de IA - Cohere SDK | cohere, azure_search_documents |
cohere-aisearch-rag.ipynb |
| Chamada de ferramenta/função Command R+, usando LangChain | cohere, langchain, langchain_cohere |
command_tools-langchain.ipynb |
Custo e quotas
Considerações sobre custo e cota para modelos implantados como serviço
Os modelos Cohere implementados como serviço são oferecidos pela Cohere através do Azure Marketplace e estão integrados no estúdio do Azure Machine Learning para uso. Pode obter os preços do Azure Marketplace quando implementar os modelos.
Sempre que uma área de trabalho subscreve uma determinada oferta de modelo do Azure Marketplace, é criado um novo recurso para controlar os custos associados ao seu consumo. O mesmo recurso é usado para monitorizar os custos associados à inferência; no entanto, estão disponíveis vários medidores para monitorizar cada cenário de forma independente.
Para obter mais informações sobre como controlar os custos, consulte Monitorizar custos dos modelos oferecidos através do Azure Marketplace.
A quota é gerida por implementação. Cada implementação tem um limite de taxa de 200 000 tokens por minuto e 1000 pedidos de API por minuto. No entanto, atualmente, limitamos uma implementação por modelo por área de trabalho. Contacte o Suporte do Microsoft Azure se os limites de taxa atuais não forem suficientes para os seus cenários.
Filtragem de conteúdos
Os modelos implantados como um serviço com pagamento conforme o uso são protegidos pela segurança de conteúdo da IA do Azure. Com a segurança de conteúdo de IA do Azure habilitada, tanto o prompt quanto a conclusão passam por um conjunto de modelos de classificação destinados a detetar e prevenir a saída de conteúdo nocivo. O sistema de filtragem de conteúdo deteta e age em categorias específicas de conteúdo potencialmente nocivo em prompts de entrada e finalizações de saída. Saiba mais sobre a Segurança de Conteúdo do Azure AI.
Conteúdos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários