Como implantar modelos Mistral com o estúdio Azure Machine Learning
Neste artigo, você aprenderá a usar o estúdio do Azure Machine Learning para implantar a família de modelos Mistral como APIs sem servidor com cobrança baseada em token pré-pago.
O Mistral AI oferece duas categorias de modelos no estúdio do Azure Machine Learning. Estes modelos estão disponíveis no catálogo de modelos.
- Modelos premium: Mistral Large e Mistral Small. Esses modelos podem ser implantados como APIs sem servidor com faturamento baseado em token pré-pago.
- Modelos abertos: Mixtral-8x7B-Instruct-v01, Mixtral-8x7B-v01, Mistral-7B-Instruct-v01 e Mistral-7B-v01. Esses modelos podem ser implantados em cálculos gerenciados em sua própria assinatura do Azure.
Você pode navegar pela família de modelos Mistral no catálogo de modelos filtrando a coleção Mistral.
Família de modelos Mistral
O Mistral Large é o modelo de linguagem grande (LLM) mais avançado da Mistral AI. Pode ser usado em qualquer tarefa baseada na linguagem, graças às suas capacidades de raciocínio e conhecimento de última geração.
Além disso, Mistral Large é:
- Especializada em RAG. Informações cruciais não são perdidas no meio de longas janelas de contexto (até 32 K tokens).
- Forte na codificação. Geração, revisão e comentários de código. Suporta todas as principais linguagens de codificação.
- Multilingue por design. Melhor desempenho em francês, alemão, espanhol e italiano - além do inglês. Dezenas de outros idiomas são suportados.
- Compatível com IA responsável. Guarda-corpos eficientes no modelo e camada de segurança extra com a
safe_modeopção.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Implantar a família de modelos Mistral como uma API sem servidor
Certos modelos no catálogo de modelos podem ser implantados como uma API sem servidor com faturamento pré-pago. Esse tipo de implantação fornece uma maneira de consumir modelos como uma API sem hospedá-los em sua assinatura, mantendo a segurança e a conformidade corporativas de que as organizações precisam. Essa opção de implantação não exige cota da sua assinatura.
O Mistral Large e o Mistral Small podem ser implantados como uma API sem servidor com cobrança paga conforme o uso e são oferecidos pela Mistral AI por meio do Microsoft Azure Marketplace. A Mistral AI pode alterar ou atualizar os termos de uso e preços desses modelos.
Pré-requisitos
Uma subscrição do Azure com um método de pagamento válido. As subscrições gratuitas ou de avaliação do Azure não funcionarão. Se você não tiver uma assinatura do Azure, crie uma conta paga do Azure para começar.
Uma área de trabalho do Azure Machine Learning. Se você não tiver um espaço de trabalho, use as etapas no artigo Guia de início rápido: criar recursos do espaço de trabalho para criar um. A oferta de implantação de modelo de API sem servidor para modelos qualificados na família Mistral só está disponível em espaços de trabalho criados nestas regiões:
- E.U.A. Leste
- E.U.A. Leste 2
- E.U.A. Centro-Norte
- E.U.A. Centro-Sul
- E.U.A. Oeste
- EUA Oeste 3
- Suécia Central
Para obter uma lista de regiões disponíveis para cada um dos modelos que suportam implantações de ponto de extremidade de API sem servidor, consulte Disponibilidade de região para modelos em pontos de extremidade de API sem servidor
Os controlos de acesso baseado em funções (RBAC do Azure) são utilizados para conceder acesso às operações no Azure Machine Learning. Para executar as etapas neste artigo, sua conta de usuário deve receber a função de Desenvolvedor do Azure AI no grupo de recursos. Para obter mais informações sobre permissões, consulte Gerir o acesso a um espaço de trabalho do Azure Machine Learning.
Criar uma nova implantação
As etapas a seguir demonstram a implantação do Mistral Large, mas você pode usar as mesmas etapas para implantar o Mistral Small substituindo o nome do modelo.
Para criar uma implantação:
Vá para o estúdio do Azure Machine Learning.
Selecione o espaço de trabalho no qual você deseja implantar seu modelo. Para usar a oferta de implantação de modelo de API sem servidor, seu espaço de trabalho deve pertencer a uma das regiões listadas nos pré-requisitos.
Escolha o modelo que deseja implantar, por exemplo, Mistral-large, no catálogo de modelos.
Como alternativa, você pode iniciar a implantação acessando seu espaço de trabalho e selecionando Pontos>de extremidade>sem servidor Criar.
Na página de visão geral do modelo no catálogo de modelos, selecione Implantar para abrir uma janela de implantação de API sem servidor para o modelo.
Marque a caixa de seleção para confirmar a política de compra da Microsoft.
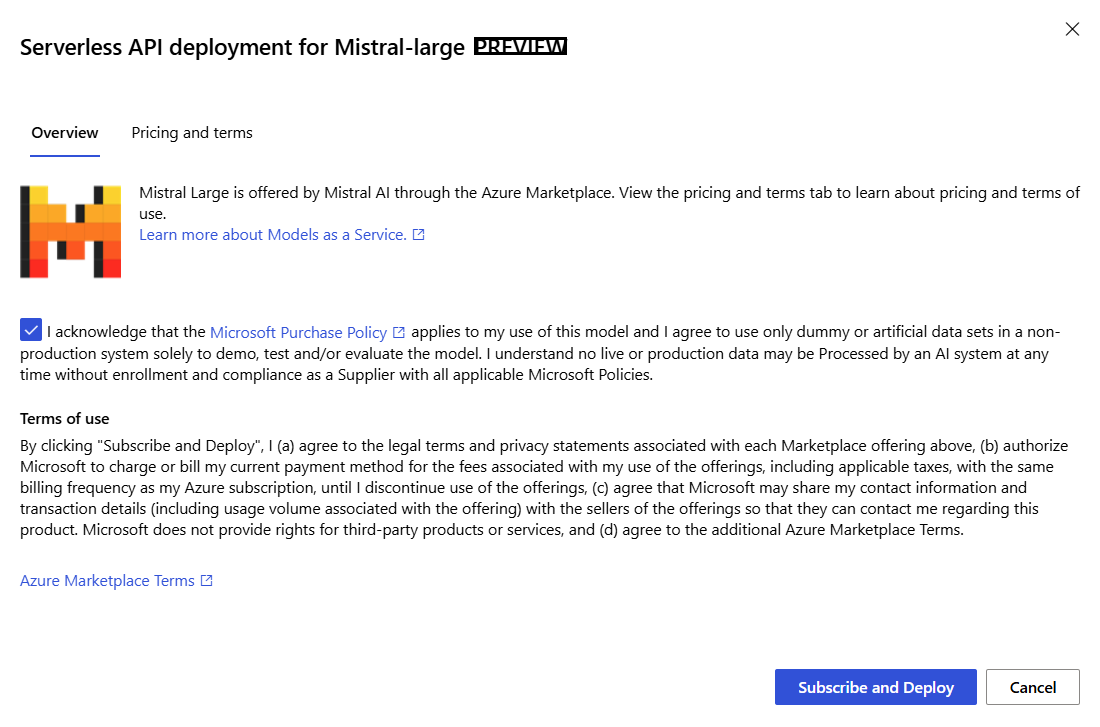
No assistente de implantação, selecione o link para Termos do Azure Marketplace para saber mais sobre os termos de uso.
Você também pode selecionar a guia Preços e termos para saber mais sobre os preços do modelo selecionado.
Se esta for a primeira vez que você implanta o modelo no espaço de trabalho, você precisa inscrever seu espaço de trabalho para a oferta específica (por exemplo, Mistral-large). Esta etapa requer que sua conta tenha as permissões da função Desenvolvedor do Azure AI no Grupo de Recursos, conforme listado nos pré-requisitos. Cada espaço de trabalho tem a sua própria subscrição para a oferta específica do Azure Marketplace, que lhe permite controlar e monitorizar os gastos. Selecione Inscrever-se e Implantar. Atualmente, você pode ter apenas uma implantação para cada modelo em um espaço de trabalho.
Depois de inscrever o espaço de trabalho para a oferta específica do Azure Marketplace, as implantações subsequentes da mesma oferta no mesmo espaço de trabalho não exigem assinatura novamente. Se esse cenário se aplicar a você, você verá uma opção Continuar a implantar para selecionar.
Dê um nome à implantação. Esse nome se torna parte da URL da API de implantação. Essa URL deve ser exclusiva em cada região do Azure.
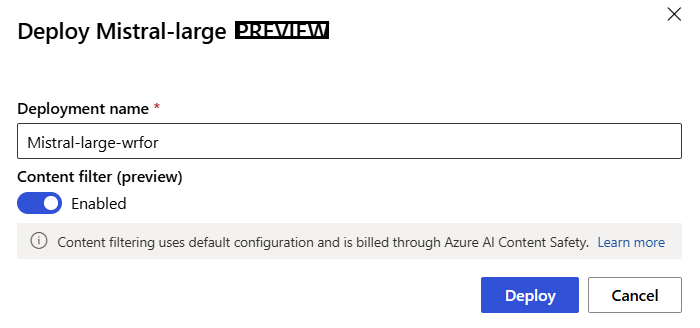
Selecione Implementar. Aguarde até que a implantação seja concluída e você seja redirecionado para a página de pontos de extremidade sem servidor.
Selecione o ponto de extremidade para abrir a página Detalhes.
Selecione a guia Teste para começar a interagir com o modelo.
Você sempre pode encontrar os detalhes, a URL e as chaves de acesso do ponto de extremidade navegando até Pontos de extremidade sem servidor de pontos de extremidade de espaço de trabalho>>.



Para saber mais sobre o faturamento de modelos Mistral implantados como uma API sem servidor com faturamento baseado em token pré-pago, consulte Considerações de custo e cota para a família de modelos Mistral implantados como um serviço.
Consuma a família de modelos Mistral como um serviço
Você pode consumir o Mistral Large usando a API de chat.
- No espaço de trabalho, selecione Pontos de extremidade> sem servidor.
- Localize e selecione a implantação que você criou.
- Copie a URL de destino e os valores do token de chave .
- Faça uma solicitação de API usando a API de Inferência de Modelo de IA do Azure na rota
/chat/completionse a API de Chat Mistral nativa no/v1/chat/completions.
Para obter mais informações sobre como usar as APIs, consulte a seção de referência .
Referência para a família de modelos Mistral implantados como um serviço
Os modelos Mistral aceitam a API de Inferência de Modelo do Azure AI na rota /chat/completions e a API Mistral Chat nativa em /v1/chat/completions.
API de Inferência de Modelos do Azure AI
O esquema da API de Inferência de Modelo do Azure AI está disponível no artigo Referência à conclusão de chats e é possível obter uma especificação da OpenAPI a partir do próprio ponto final.
API de bate-papo Mistral
Use o método POST para enviar a solicitação para a /v1/chat/completions rota:
Pedir
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Esquema de solicitação
Payload é uma cadeia de caracteres formatada JSON que contém os seguintes parâmetros:
| Chave | Type | Predefinido | Description |
|---|---|---|---|
messages |
string |
Sem predefinição. Este valor deve ser especificado. | A mensagem ou o histórico de mensagens a serem usadas para solicitar o modelo. |
stream |
boolean |
False |
O streaming permite que os tokens gerados sejam enviados como eventos enviados apenas pelo servidor de dados sempre que estiverem disponíveis. |
max_tokens |
integer |
8192 |
O número máximo de tokens a serem gerados na conclusão. A contagem de tokens do prompt plus max_tokens não pode exceder o comprimento de contexto do modelo. |
top_p |
float |
1 |
Uma alternativa à amostragem com temperatura, chamada amostragem de núcleo, onde o modelo considera os resultados dos tokens com top_p massa de probabilidade. Assim, 0,1 significa que apenas os tokens que compõem a massa de probabilidade superior de 10% são considerados. Geralmente recomendamos alterar top_p ou temperature, mas não ambos. |
temperature |
float |
1 |
A temperatura de amostragem a utilizar, entre 0 e 2. Valores mais altos significam que o modelo mostra de forma mais ampla a distribuição de tokens. Zero significa amostragem gananciosa. Recomendamos alterar este parâmetro ou top_p, mas não ambos. |
ignore_eos |
boolean |
False |
Se o token EOS deve ser ignorado e continuar gerando tokens depois que o token EOS for gerado. |
safe_prompt |
boolean |
False |
Se deve injetar um aviso de segurança antes de todas as conversas. |
O messages objeto tem os seguintes campos:
| Chave | Type | valor |
|---|---|---|
content |
string |
O conteúdo da mensagem. O conteúdo é necessário para todas as mensagens. |
role |
string |
O papel do autor da mensagem. Um de system, userou assistant. |
Exemplo de solicitação
Corpo
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."
},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Esquema de resposta
A carga útil de resposta é um dicionário com os seguintes campos.
| Chave | Tipo | Description |
|---|---|---|
id |
string |
Um identificador exclusivo para a conclusão. |
choices |
array |
A lista de opções de conclusão que o modelo gerou para as mensagens de entrada. |
created |
integer |
O carimbo de data/hora Unix (em segundos) de quando a conclusão foi criada. |
model |
string |
O model_id usado para conclusão. |
object |
string |
O tipo de objeto, que é sempre chat.completion. |
usage |
object |
Estatísticas de utilização do pedido de conclusão. |
Gorjeta
No modo de streaming, para cada parte da resposta, finish_reason é sempre null, exceto a última que é encerrada por uma carga [DONE]útil. Em cada choices objeto, a chave para messages é alterada por delta.
O choices objeto é um dicionário com os seguintes campos.
| Chave | Tipo | Description |
|---|---|---|
index |
integer |
Índice de escolha. Quando best_of> 1, o índice nessa matriz pode não estar em ordem e pode não estar 0 em n-1. |
messages ou delta |
string |
Resultado da conclusão do bate-papo no messages objeto. Quando o modo de streaming é usado, delta a chave é usada. |
finish_reason |
string |
A razão pela qual o modelo parou de gerar tokens: - stop: o modelo atingiu um ponto de paragem natural ou uma sequência de paragem fornecida. - length: se o número máximo de tokens tiver sido atingido. - content_filter: Quando a RAI modera e a CMP força a moderação - content_filter_error: um erro durante a moderação e não foi capaz de tomar uma decisão sobre a resposta - null: Resposta da API ainda em andamento ou incompleta. |
logprobs |
object |
As probabilidades de log dos tokens gerados no texto de saída. |
O usage objeto é um dicionário com os seguintes campos.
| Chave | Type | valor |
|---|---|---|
prompt_tokens |
integer |
Número de tokens no prompt. |
completion_tokens |
integer |
Número de tokens gerados na conclusão. |
total_tokens |
integer |
Total de tokens. |
O logprobs objeto é um dicionário com os seguintes campos:
| Chave | Type | valor |
|---|---|---|
text_offsets |
array de integers |
A posição ou índice de cada token na saída de conclusão. |
token_logprobs |
array de float |
Selecionado logprobs do dicionário na top_logprobs matriz. |
tokens |
array de string |
Tokens selecionados. |
top_logprobs |
array de dictionary |
Matriz de dicionário. Em cada dicionário, a chave é o token e o valor é o prob. |
Exemplo de resposta
O JSON a seguir é um exemplo de resposta:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
Mais exemplos de inferência
| Tipo de amostra | Bloco de notas de exemplo |
|---|---|
| CLI usando solicitações da Web CURL e Python | webrequests.ipynb |
| OpenAI SDK (experimental) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Mistral AI | mistralai.ipynb |
| LiteLLM | litellm.ipynb |
Custo e quotas
Considerações de custo e cota para a família de modelos Mistral implantados como um serviço
Os modelos Mistral implantados como um serviço são oferecidos pela Mistral AI por meio do Azure Marketplace e integrados ao estúdio Azure Machine Learning para uso. Pode obter os preços do Azure Marketplace quando implementar os modelos.
Sempre que uma área de trabalho subscreve uma determinada oferta de modelo do Azure Marketplace, é criado um novo recurso para controlar os custos associados ao seu consumo. O mesmo recurso é usado para monitorizar os custos associados à inferência; no entanto, estão disponíveis vários medidores para monitorizar cada cenário de forma independente.
Para obter mais informações sobre como controlar os custos, consulte Monitorizar custos dos modelos oferecidos através do Azure Marketplace.
A quota é gerida por implementação. Cada implementação tem um limite de taxa de 200 000 tokens por minuto e 1000 pedidos de API por minuto. No entanto, atualmente, limitamos uma implementação por modelo por área de trabalho. Contacte o Suporte do Microsoft Azure se os limites de taxa atuais não forem suficientes para os seus cenários.
Filtragem de conteúdos
Os modelos implantados como um serviço com pagamento conforme o uso são protegidos pela segurança de conteúdo da IA do Azure. Com a segurança de conteúdo de IA do Azure habilitada, tanto o prompt quanto a conclusão passam por um conjunto de modelos de classificação destinados a detetar e prevenir a saída de conteúdo nocivo. O sistema de filtragem de conteúdo deteta e age em categorias específicas de conteúdo potencialmente nocivo em prompts de entrada e finalizações de saída. Saiba mais sobre a Segurança de Conteúdo do Azure AI.
Conteúdos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários