Utilizar o estúdio do Azure Machine Learning numa rede virtual do Azure
Gorjeta
A Microsoft recomenda o uso de redes virtuais gerenciadas do Azure Machine Learning em vez das etapas neste artigo. Com uma rede virtual gerenciada, o Azure Machine Learning lida com o trabalho de isolamento de rede para seu espaço de trabalho e cálculos gerenciados. Você também pode adicionar pontos de extremidade privados para recursos necessários para o espaço de trabalho, como a Conta de Armazenamento do Azure. Para obter mais informações, consulte Isolamento de rede gerenciado pelo espaço de trabalho.
Este artigo explica como usar o estúdio do Azure Machine Learning em uma rede virtual. O estúdio inclui recursos como AutoML, o designer e rotulagem de dados.
Alguns dos recursos do estúdio são desativados por padrão em uma rede virtual. Para reativar esses recursos, você deve habilitar a identidade gerenciada para contas de armazenamento que pretende usar no estúdio.
As seguintes operações estão desativadas por predefinição numa rede virtual:
- Pré-visualizar dados no estúdio.
- Visualizar os dados no estruturador.
- Implementar um modelo no estruturador.
- Submeter uma experimentação de AutoML.
- Iniciar um projeto de etiquetagem.
O estúdio suporta a leitura de dados dos seguintes tipos de armazenamento de dados em uma rede virtual:
- Conta de Armazenamento do Azure (blob & file)
- Armazenamento do Azure Data Lake Ger1
- Armazenamento do Azure Data Lake Ger2
- Base de Dados SQL do Azure
Neste artigo, vai aprender a:
- Dê ao estúdio acesso aos dados armazenados dentro de uma rede virtual.
- Acesse o estúdio a partir de um recurso dentro de uma rede virtual.
- Entenda como o estúdio afeta a segurança do armazenamento.
Pré-requisitos
Leia a Visão geral da segurança de rede para entender cenários e arquitetura comuns de rede virtual.
Uma rede virtual pré-existente e uma sub-rede para usar.
Um espaço de trabalho existente do Azure Machine Learning com um ponto de extremidade privado.
Uma conta de armazenamento existente do Azure adicionou sua rede virtual.
Um espaço de trabalho existente do Azure Machine Learning com um ponto de extremidade privado.
Uma conta de armazenamento existente do Azure adicionou sua rede virtual.
- Para saber como criar um espaço de trabalho seguro, consulte Tutorial: Criar um espaço de trabalho seguro ou Tutorial: Criar um espaço de trabalho seguro usando um modelo.
Limitações
Conta de armazenamento do Azure
Quando a conta de armazenamento está na rede virtual, há requisitos de validação adicionais para usar o studio:
- Se a conta de armazenamento usar um ponto de extremidade de serviço, o ponto de extremidade privado do espaço de trabalho e o ponto de extremidade do serviço de armazenamento deverão estar na mesma sub-rede da rede virtual.
- Se a conta de armazenamento usar um ponto de extremidade privado, o ponto de extremidade privado do espaço de trabalho e o ponto de extremidade privado de armazenamento deverão estar na mesma rede virtual. Neste caso, podem estar em sub-redes diferentes.
Pipeline de amostra do designer
Há um problema conhecido em que os usuários não podem executar um pipeline de exemplo na página inicial do designer. Esse problema ocorre porque o conjunto de dados de exemplo usado no pipeline de exemplo é um conjunto de dados global do Azure. Ele não pode ser acessado de um ambiente de rede virtual.
Para resolver esse problema, use um espaço de trabalho público para executar o pipeline de exemplo. Ou substitua o conjunto de dados de exemplo por seu próprio conjunto de dados no espaço de trabalho dentro de uma rede virtual.
Datastore: Conta de Armazenamento do Azure
Use as seguintes etapas para habilitar o acesso aos dados armazenados no Blob do Azure e no armazenamento de arquivos:
Gorjeta
A primeira etapa não é necessária para a conta de armazenamento padrão do espaço de trabalho. Todas as outras etapas são necessárias para qualquer conta de armazenamento por trás da VNet e usadas pelo espaço de trabalho, incluindo a conta de armazenamento padrão.
Se a conta de armazenamento for o armazenamento padrão para seu espaço de trabalho, ignore esta etapa. Se não for o padrão, conceda à identidade gerenciada do espaço de trabalho a função Leitor de Dados de Blob de Armazenamento para a conta de armazenamento do Azure para que ela possa ler dados do armazenamento de blobs.
Para obter mais informações, consulte a função interna Leitor de Dados de Blob .
Conceda à sua identidade de usuário do Azure a função de leitor de Dados de Blob de Armazenamento para a conta de armazenamento do Azure. O estúdio usa sua identidade para acessar dados para armazenamento de blobs, mesmo que a identidade gerenciada pelo espaço de trabalho tenha a função de Leitor.
Para obter mais informações, consulte a função interna Leitor de Dados de Blob .
Conceda à identidade gerenciada do espaço de trabalho a função Leitor para pontos de extremidade privados de armazenamento. Se o serviço de armazenamento usar um ponto de extremidade privado, conceda ao Leitor de identidade gerenciado do espaço de trabalho acesso ao ponto de extremidade privado. A identidade gerenciada do espaço de trabalho no Microsoft Entra ID tem o mesmo nome do seu espaço de trabalho do Azure Machine Learning. Um ponto de extremidade privado é necessário para os tipos de armazenamento de blob e arquivo.
Gorjeta
Sua conta de armazenamento pode ter vários pontos de extremidade privados. Por exemplo, uma conta de armazenamento pode ter ponto de extremidade privado separado para blob, arquivo e dfs (Azure Data Lake Storage Gen2). Adicione a identidade gerenciada a todos esses pontos de extremidade.
Para obter mais informações, consulte a função interna Leitor .
Habilite a autenticação de identidade gerenciada para contas de armazenamento padrão. Cada espaço de trabalho do Azure Machine Learning tem duas contas de armazenamento padrão, uma conta de armazenamento de blob padrão e uma conta de armazenamento de arquivos padrão. Ambos são definidos quando você cria seu espaço de trabalho. Você também pode definir novos padrões na página de gerenciamento do Datastore.
A tabela a seguir descreve por que a autenticação de identidade gerenciada é usada para suas contas de armazenamento padrão do espaço de trabalho.
Conta de armazenamento Notas Armazenamento de blob padrão do espaço de trabalho Armazena ativos de modelo do designer. Habilite a autenticação de identidade gerenciada nessa conta de armazenamento para implantar modelos no designer. Se a autenticação de identidade gerenciada estiver desabilitada, a identidade do usuário será usada para acessar os dados armazenados no blob.
Você pode visualizar e executar um pipeline de designer se ele usar um armazenamento de dados não padrão que tenha sido configurado para usar identidade gerenciada. No entanto, se você tentar implantar um modelo treinado sem identidade gerenciada habilitada no armazenamento de dados padrão, a implantação falhará independentemente de quaisquer outros armazenamentos de dados em uso.Armazenamento de arquivos padrão do espaço de trabalho Armazena ativos de experimento AutoML. Habilite a autenticação de identidade gerenciada nessa conta de armazenamento para enviar experimentos AutoML. Configure datastores para usar autenticação de identidade gerenciada. Depois de adicionar uma conta de armazenamento do Azure à sua rede virtual com um ponto de extremidade de serviço ou ponto de extremidade privado, você deve configurar seu armazenamento de dados para usar a autenticação de identidade gerenciada. Isso permite que o estúdio acesse os dados em sua conta de armazenamento.
O Azure Machine Learning usa o armazenamento de dados para se conectar a contas de armazenamento. Ao criar um novo armazenamento de dados, use as seguintes etapas para configurar um armazenamento de dados para usar a autenticação de identidade gerenciada:
No estúdio, selecione Datastores.
Para criar um novo armazenamento de dados, selecione + Criar.
Nas configurações do armazenamento de dados, ative a opção Usar identidade gerenciada do espaço de trabalho para visualização de dados e criação de perfil no estúdio do Azure Machine Learning.
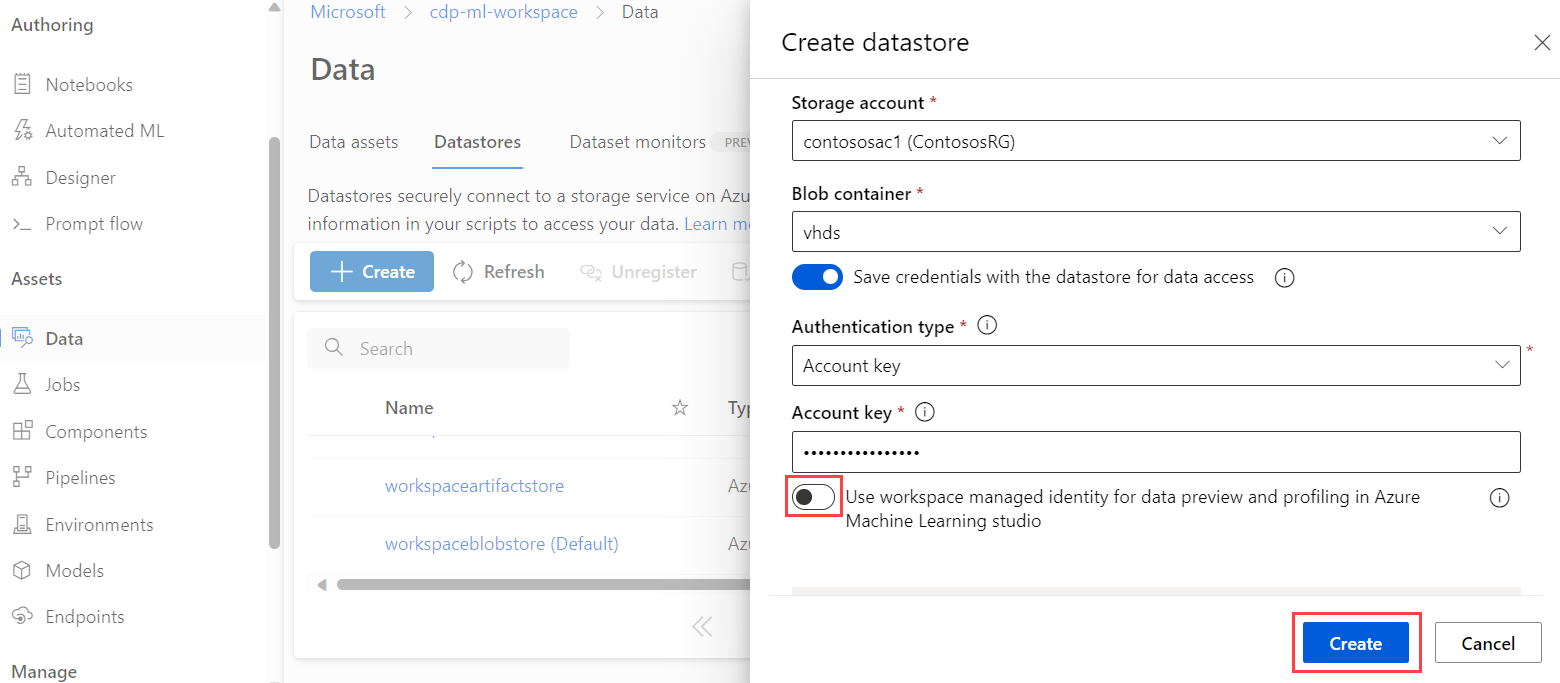
Nas configurações de rede para a Conta de Armazenamento do Azure, adicione o
Microsoft.MachineLearningService/workspacestipo de recurso e defina o nome da instância para o espaço de trabalho.
Essas etapas adicionam a identidade gerenciada do espaço de trabalho como um leitor ao novo serviço de armazenamento usando o RBAC (controle de acesso baseado em função) do Azure. O acesso do leitor permite que o espaço de trabalho visualize o recurso, mas não faça alterações.


Armazenamento de dados: Azure Data Lake Storage Gen1
Ao usar o Azure Data Lake Storage Gen1 como um armazenamento de dados, você só pode usar listas de controle de acesso no estilo POSIX. Você pode atribuir o acesso de identidade gerenciada do espaço de trabalho a recursos como qualquer outra entidade de segurança. Para obter mais informações, consulte Controle de acesso no Azure Data Lake Storage Gen1.
Armazenamento de dados: Azure Data Lake Storage Gen2
Ao usar o Azure Data Lake Storage Gen2 como um armazenamento de dados, você pode usar listas de controle de acesso (ACLs) no estilo RBAC do Azure e POSIX para controlar o acesso a dados dentro de uma rede virtual.
Para usar o RBAC do Azure, siga as etapas na seção Datastore: Conta de Armazenamento do Azure deste artigo. O Data Lake Storage Gen2 é baseado no Armazenamento do Azure, portanto, as mesmas etapas se aplicam ao usar o Azure RBAC.
Para usar ACLs, a identidade gerenciada do espaço de trabalho pode receber acesso como qualquer outra entidade de segurança. Para obter mais informações, consulte Listas de controle de acesso em arquivos e diretórios.
Armazenamento de dados: Banco de Dados SQL do Azure
Para acessar dados armazenados em um Banco de Dados SQL do Azure com uma identidade gerenciada, você deve criar um usuário contido no SQL que mapeie para a identidade gerenciada. Para obter mais informações sobre como criar um usuário a partir de um provedor externo, consulte Criar usuários contidos mapeados para identidades do Microsoft Entra.
Depois de criar um usuário SQL contido, conceda permissões a ele usando o comando GRANT T-SQL.
Saída de componentes intermediários
Ao usar a saída de componente intermediário do designer do Azure Machine Learning, você pode especificar o local de saída para qualquer componente no designer. Use essa saída para armazenar conjuntos de dados intermediários em local separado para fins de segurança, registro em log ou auditoria. Para especificar a saída, use as seguintes etapas:
- Selecione o componente cuja saída pretende especificar.
- No painel de configurações do componente, selecione Configurações de saída.
- Especifique o arquivo de dados que pretende utilizar para cada saída do componente.
Certifique-se de que tem acesso às contas de armazenamento intermédias na sua rede virtual. Caso contrário, o pipeline falhará.
Ative a autenticação de identidade gerida para contas de armazenamento intermédias para visualizar dados de saída.
Acesse o estúdio a partir de um recurso dentro da rede virtual
Se você acessar o estúdio a partir de um recurso dentro de uma rede virtual (por exemplo, uma instância de computação ou máquina virtual), deverá permitir o tráfego de saída da rede virtual para o estúdio.
Por exemplo, se você usar NSG (grupos de segurança de rede) para restringir o tráfego de saída, adicione uma regra a um destino de etiqueta de serviço de AzureFrontDoor.Frontend.
Definições de firewall
Alguns serviços de armazenamento, como a Conta de Armazenamento do Azure, têm configurações de firewall que se aplicam ao ponto de extremidade público dessa instância de serviço específica. Normalmente, esta definição permite-lhe permitir/não permitir o acesso a partir de endereços IP específicos a partir da Internet pública. Isso não é suportado ao usar o estúdio do Azure Machine Learning. Tem suporte ao usar o SDK ou CLI do Azure Machine Learning.
Gorjeta
O estúdio do Azure Machine Learning é suportado ao usar o serviço Firewall do Azure. Para obter mais informações, consulte Configurar o tráfego de rede de entrada e saída.
Conteúdos relacionados
Este artigo faz parte de uma série sobre como proteger um fluxo de trabalho do Azure Machine Learning. Veja os outros artigos desta série: