Exibir código de treinamento para um modelo de ML automatizado
Neste artigo, você aprenderá a exibir o código de treinamento gerado a partir de qualquer modelo treinado em aprendizado de máquina automatizado.
A geração de código para modelos treinados em ML automatizados permite que você veja os seguintes detalhes que o ML automatizado usa para treinar e criar o modelo para uma execução específica.
- Pré-processamento de dados
- Seleção de algoritmos
- Caracterização
- Hiperparâmetros
Você pode selecionar qualquer modelo treinado em ML automatizado, recomendado ou executado filho, e visualizar o código de treinamento Python gerado que criou esse modelo específico.
Com o código de treinamento do modelo gerado, você pode,
- Saiba qual o processo de featurização e hiperparâmetros que o algoritmo do modelo usa.
- Modelos treinados para rastrear/versão/auditoria . Armazene o código versionado para controlar qual código de treinamento específico é usado com o modelo a ser implantado na produção.
- Personalize o código de treinamento alterando hiperparâmetros ou aplicando suas habilidades/experiência em ML e algoritmos e treine novamente um novo modelo com seu código personalizado.
O diagrama a seguir ilustra que você pode gerar o código para experimentos automatizados de ML com todos os tipos de tarefas. Primeiro, selecione um modelo. O modelo selecionado será realçado e, em seguida, o Aprendizado de Máquina do Azure copia os arquivos de código usados para criar o modelo e os exibe na pasta compartilhada dos blocos de anotações. A partir daqui, você pode visualizar e personalizar o código conforme necessário.
Pré-requisitos
Uma área de trabalho do Azure Machine Learning. Para criar o espaço de trabalho, consulte Criar recursos do espaço de trabalho.
Este artigo pressupõe alguma familiaridade com a configuração de um experimento automatizado de aprendizado de máquina. Siga o tutorial ou instruções para ver os principais padrões de design de experimento de aprendizado de máquina automatizado.
A geração automatizada de código de ML só está disponível para experiências executadas em destinos de computação remotos do Azure Machine Learning. A geração de código não é suportada para execuções locais.
Todas as execuções automatizadas de ML acionadas por meio do estúdio Azure Machine Learning, SDKv2 ou CLIv2 terão a geração de código habilitada.
Obter código gerado e artefatos de modelo
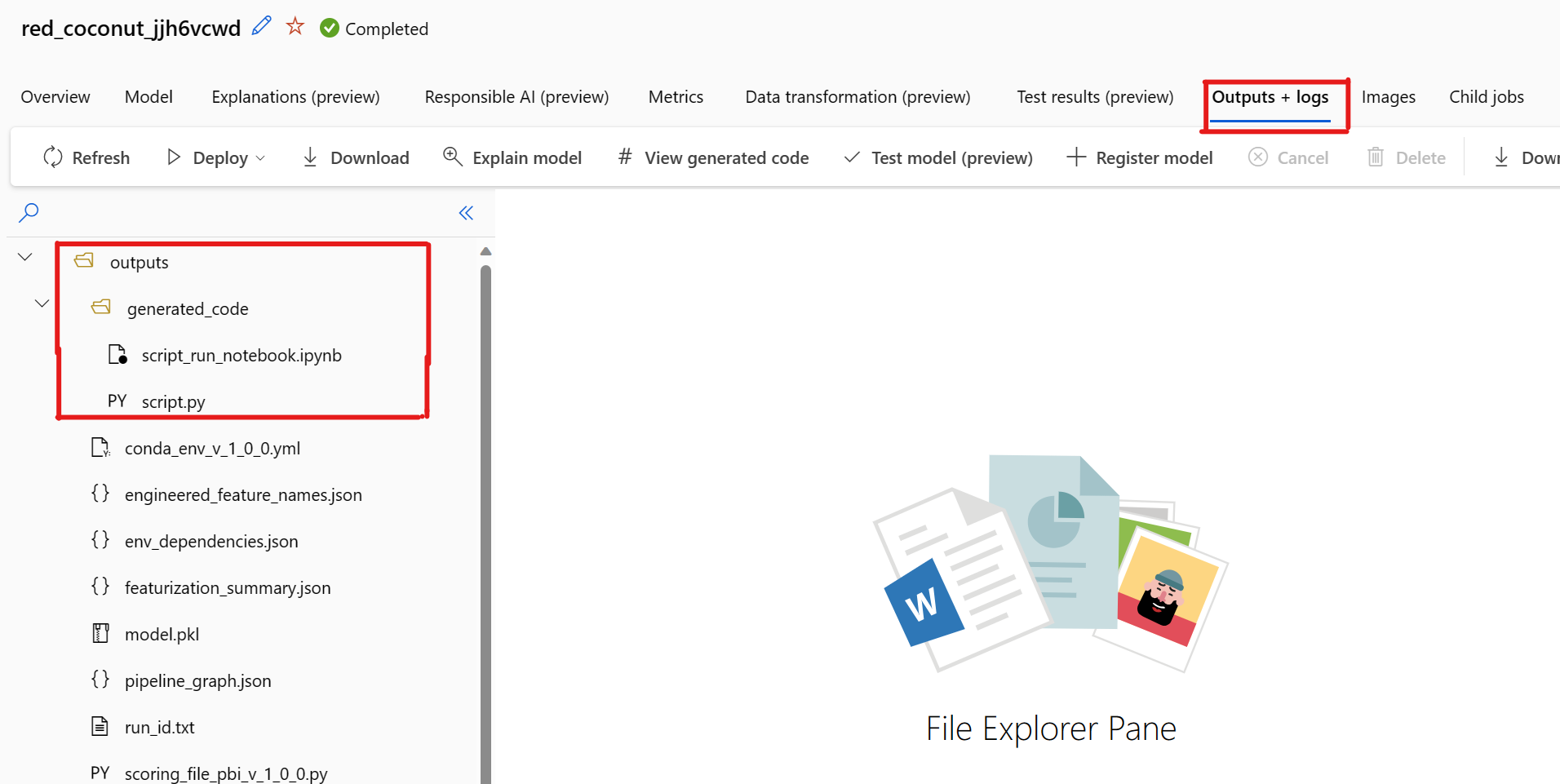
Por padrão, cada modelo treinado em ML automatizado gera seu código de treinamento após a conclusão do treinamento. O ML automatizado salva esse código no experimento outputs/generated_code para esse modelo específico. Você pode exibi-los na interface do usuário do estúdio do Azure Machine Learning na guia Saídas + logs do modelo selecionado.
script.py Este é o código de treinamento do modelo que você provavelmente deseja analisar com as etapas de featurização, algoritmo específico usado e hiperparâmetros.
Bloco de Anotações script_run_notebook.ipynb com código clichê para executar o código de treinamento (script.py) do modelo na computação do Azure Machine Learning por meio do SDK do Azure Machine Learning v2.
Após a conclusão da execução de treinamento automatizado de ML, você pode acessar os e os script.pyscript_run_notebook.ipynb arquivos por meio da interface do usuário do estúdio de Aprendizado de Máquina do Azure.
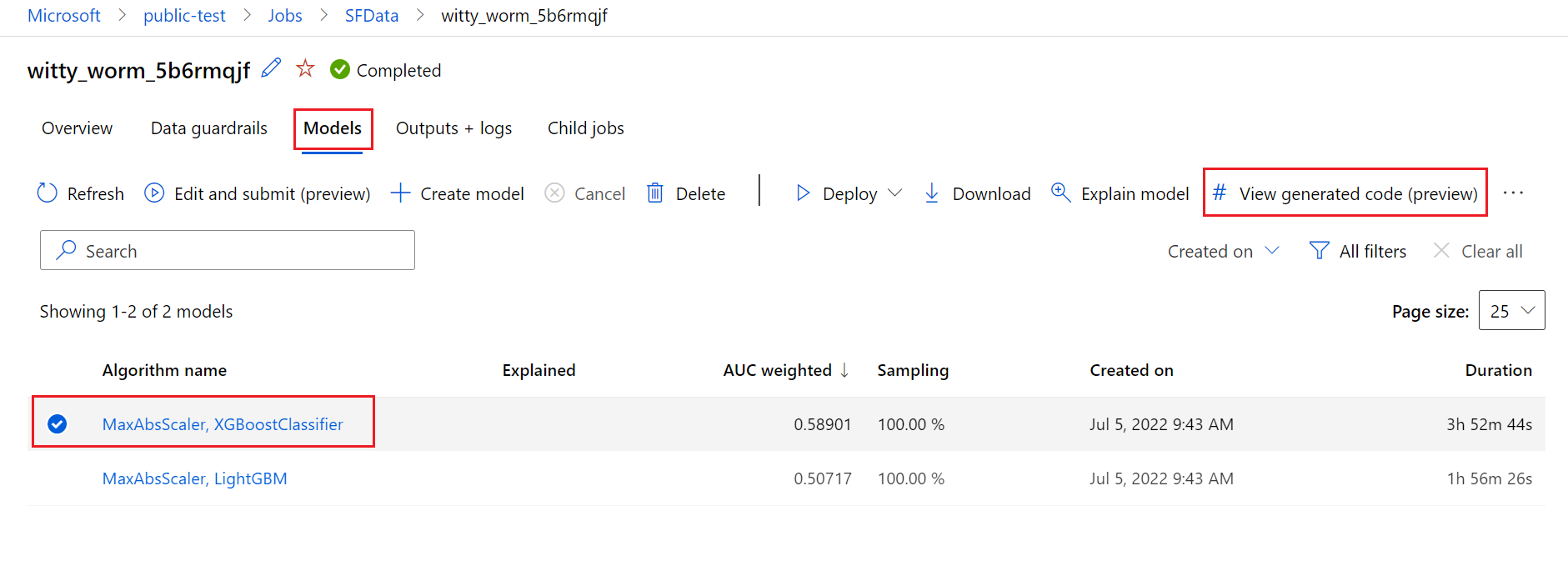
Para fazer isso, navegue até a guia Modelos da página da execução pai do experimento de ML automatizado. Depois de selecionar um dos modelos treinados, você pode selecionar o botão Exibir código gerado. Este botão redireciona-o para a extensão do portal Blocos de Notas , onde pode visualizar, editar e executar o código gerado para esse modelo selecionado em particular.
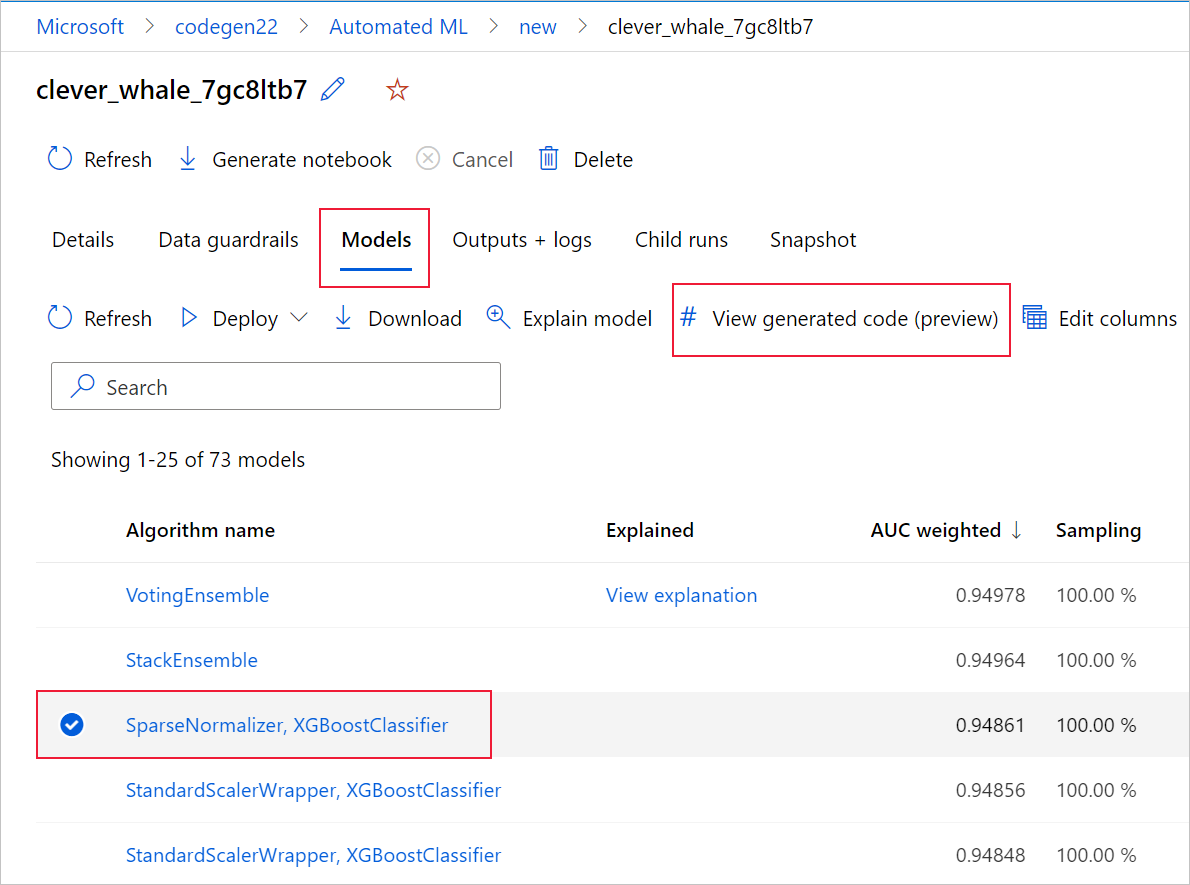
Você também pode acessar o código gerado do modelo na parte superior da página da execução filho depois de navegar para a página da execução filho de um modelo específico.
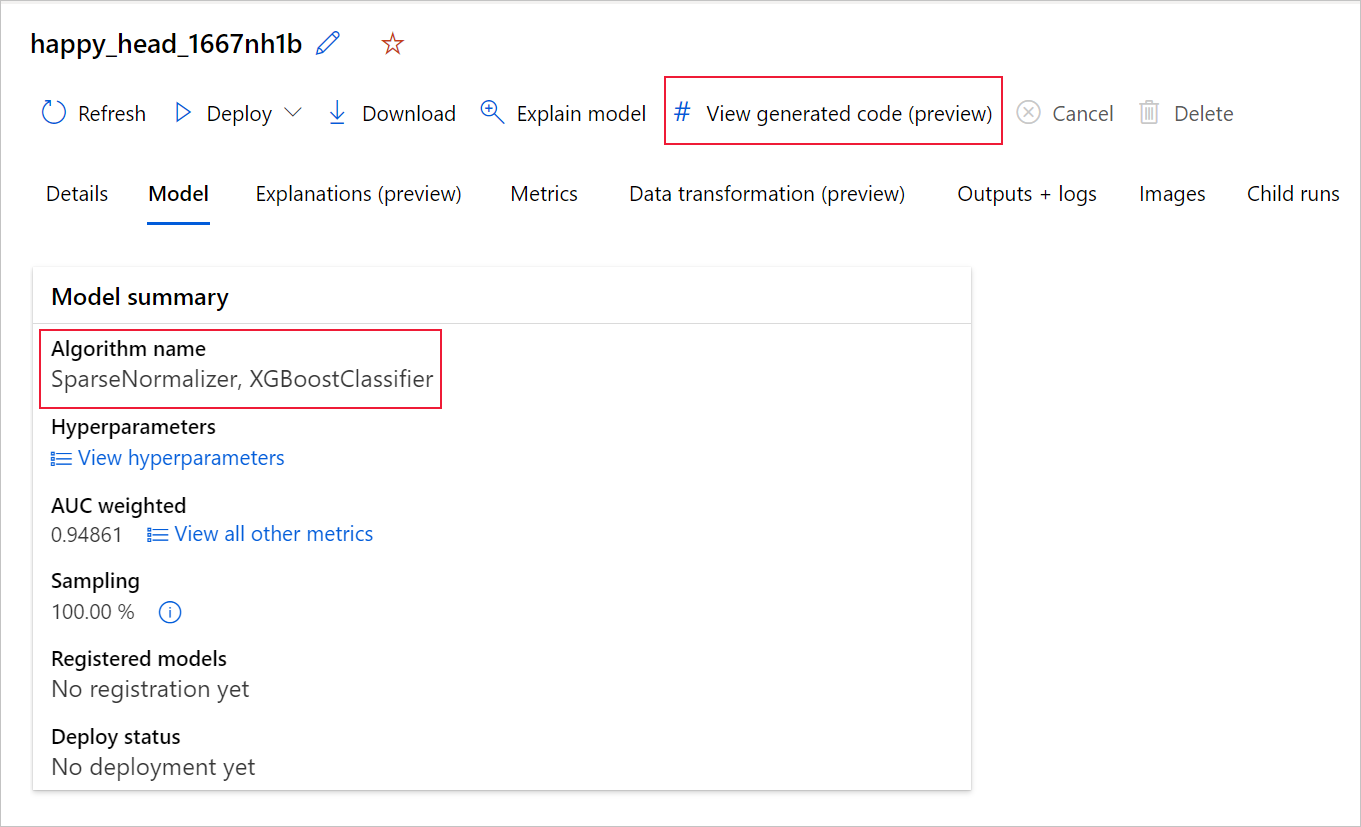
Se você estiver usando o Python SDKv2, você também pode baixar o "script.py" e o "script_run_notebook.ipynb" recuperando a melhor execução via MLFlow & baixando os artefatos resultantes.
Limitações
Há um problema conhecido ao selecionar Exibir código gerado. Esta ação não consegue redirecionar para o portal Notebooks quando o armazenamento está atrás de uma VNet. Como solução alternativa, o usuário pode baixar manualmente os arquivos script.py e script_run_notebook.ipynbnavegando até a guia Saídas + Logs na pasta generated_code saídas>. Esses arquivos podem ser carregados manualmente para a pasta de blocos de anotações para executá-los ou editá-los. Siga este link para saber mais sobre VNets no Azure Machine Learning.
script.py
O script.py arquivo contém a lógica central necessária para treinar um modelo com os hiperparâmetros usados anteriormente. Embora destinado a ser executado no contexto de uma execução de script do Azure Machine Learning, com algumas modificações, o código de treinamento do modelo também pode ser executado de forma autônoma em seu próprio ambiente local.
O script pode ser dividido em várias das seguintes partes: carregamento de dados, preparação de dados, featurização de dados, especificação de pré-processador/algoritmo e treinamento.
Carregamento de dados
A função get_training_dataset() carrega o conjunto de dados usado anteriormente. Ele pressupõe que o script seja executado em um script do Aprendizado de Máquina do Azure executado no mesmo espaço de trabalho do experimento original.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Ao executar como parte de uma execução de script, Run.get_context().experiment.workspace recupera o espaço de trabalho correto. No entanto, se esse script for executado dentro de um espaço de trabalho diferente ou executado localmente, você precisará modificá-lo para especificar explicitamente o espaço de trabalho apropriado.
Depois que o espaço de trabalho for recuperado, o conjunto de dados original será recuperado por sua ID. Outro conjunto de dados com exatamente a mesma estrutura também pode ser especificado por ID ou nome com o get_by_id() ou get_by_name(), respectivamente. Você pode encontrar o ID mais adiante no script, em uma seção semelhante ao código a seguir.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
Você também pode optar por substituir toda essa função pelo seu próprio mecanismo de carregamento de dados; as únicas restrições são que o valor de retorno deve ser um dataframe Pandas e que os dados devem ter a mesma forma que no experimento original.
Código de preparação de dados
A função prepare_data() limpa os dados, divide as colunas de peso do recurso e da amostra e prepara os dados para uso no treinamento.
Esta função pode variar dependendo do tipo de conjunto de dados e do tipo de tarefa do experimento: classificação, regressão, previsão de séries temporais, imagens ou tarefas de PNL.
O exemplo a seguir mostra que, em geral, o dataframe da etapa de carregamento de dados é passado. A coluna do rótulo e os pesos da amostra, se originalmente especificados, são extraídos e as linhas que contêm NaN são descartadas dos dados de entrada.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Se você quiser fazer mais alguma preparação de dados, isso pode ser feito nesta etapa, adicionando seu código de preparação de dados personalizado.
Código de featurização de dados
A função generate_data_transformation_config() especifica a etapa de featurização no pipeline final scikit-learn. Os featurizers do experimento original são reproduzidos aqui, juntamente com seus parâmetros.
Por exemplo, a possível transformação de dados que pode acontecer nesta função pode ser baseada em imputadores como, e , SimpleImputer() ou transformadores como StringCastTransformer() e LabelEncoderTransformer()CatImputer().
A seguir está um transformador do tipo StringCastTransformer() que pode ser usado para transformar um conjunto de colunas. Neste caso, o conjunto indicado por column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Se você tiver muitas colunas que precisam ter a mesma featurização/transformação aplicada (por exemplo, 50 colunas em vários grupos de colunas), essas colunas serão manipuladas agrupando com base no tipo.
No exemplo a seguir, observe que cada grupo tem um mapeador exclusivo aplicado. Este mapeador é então aplicado a cada uma das colunas desse grupo.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Essa abordagem permite que você tenha um código mais simplificado, não tendo um bloco de código do transformador para cada coluna, o que pode ser especialmente complicado mesmo quando você tem dezenas ou centenas de colunas em seu conjunto de dados.
Com tarefas de classificação e regressão, [FeatureUnion] é usado para featurizers.
Para modelos de previsão de séries temporais, vários featurizers com reconhecimento de séries temporais são coletados em um pipeline scikit-learn e, em seguida, envolvidos no TimeSeriesTransformer.
Qualquer funcionalidade fornecida pelo usuário para modelos de previsão de séries temporais acontece antes das fornecidas pelo ML automatizado.
Código de especificação do pré-processador
A função generate_preprocessor_config(), se presente, especifica uma etapa de pré-processamento a ser feita após a featurização no pipeline final scikit-learn.
Normalmente, essa etapa de pré-processamento consiste apenas na padronização/normalização de dados realizada com sklearn.preprocessingo .
O ML automatizado especifica apenas uma etapa de pré-processamento para modelos de classificação e regressão não conjuntos.
Aqui está um exemplo de um código de pré-processador gerado:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Código de especificação de algoritmos e hiperparâmetros
O algoritmo e o código de especificação de hiperparâmetros é provavelmente o que muitos profissionais de ML estão mais interessados.
A generate_algorithm_config() função especifica o algoritmo real e os hiperparâmetros para treinar o modelo como o último estágio do pipeline final de scikit-learn.
O exemplo a seguir usa um algoritmo XGBoostClassifier com hiperparâmetros específicos.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
O código gerado na maioria dos casos usa pacotes e classes de software de código aberto (OSS). Há casos em que classes de wrapper intermediárias são usadas para simplificar códigos mais complexos. Por exemplo, o classificador XGBoost e outras bibliotecas comumente usadas como LightGBM ou algoritmos Scikit-Learn podem ser aplicados.
Como um profissional de ML, você pode personalizar o código de configuração desse algoritmo ajustando seus hiperparâmetros conforme necessário com base em suas habilidades e experiência para esse algoritmo e seu problema específico de ML.
Para modelos de conjunto, (se necessário) e generate_algorithm_config_N() são definidos para cada aluno no modelo de conjunto, generate_preprocessor_config_N() onde N representa a colocação de cada aluno na lista do modelo de conjunto. Para modelos de conjunto de pilha, o meta learner generate_algorithm_config_meta() é definido.
Código de treinamento de ponta a ponta
A geração de código emite build_model_pipeline() e para definir o pipeline scikit-learn e train_model() para chamá-lo fit() , respectivamente.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
O pipeline scikit-learn inclui a etapa de featurização, um pré-processador (se usado) e o algoritmo ou modelo.
Para modelos de previsão de séries temporais, o pipeline scikit-learn é envolvido em um ForecastingPipelineWrapper, que tem alguma lógica adicional necessária para lidar adequadamente com dados de séries temporais, dependendo do algoritmo aplicado.
Para todos os tipos de tarefas, usamos PipelineWithYTransformer nos casos em que a coluna de rótulo precisa ser codificada.
Depois de ter o pipeline scikit-Learn, tudo o que resta chamar é o método para treinar o fit() modelo:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
O valor de retorno de é o modelo ajustado/treinado nos dados de train_model() entrada.
O código principal que executa todas as funções anteriores é o seguinte:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Depois de ter o modelo treinado, você pode usá-lo para fazer previsões com o método predict(). Se o experimento for para um modelo de série temporal, use o método forecast() para previsões.
y_pred = model.predict(X)
Finalmente, o modelo é serializado e salvo como um .pkl arquivo chamado "model.pkl":
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
O script_run_notebook.ipynb bloco de anotações serve como uma maneira fácil de executar script.py em uma computação do Azure Machine Learning.
Este bloco de anotações é semelhante aos blocos de anotações de exemplo de ML automatizados existentes, no entanto, há algumas diferenças importantes, conforme explicado nas seções a seguir.
Environment
Normalmente, o ambiente de treinamento para uma execução automatizada de ML é definido automaticamente pelo SDK. No entanto, ao executar um script personalizado como o código gerado, o ML automatizado não está mais conduzindo o processo, portanto, o ambiente deve ser especificado para que o trabalho de comando seja bem-sucedido.
A geração de código reutiliza o ambiente que foi usado no experimento de ML automatizado original, se possível. Isso garante que a execução do script de treinamento não falhe devido à falta de dependências e tenha um benefício secundário de não precisar de uma reconstrução de imagem do Docker, o que economiza tempo e recursos de computação.
Se você fizer alterações script.py que exijam dependências adicionais, ou se quiser usar seu próprio ambiente, precisará atualizar o ambiente de script_run_notebook.ipynb acordo.
Submeter a experimentação
Como o código gerado não é mais controlado por ML automatizado, em vez de criar e enviar um trabalho AutoML, você precisa criar um Command Job e fornecer o código gerado (script.py) para ele.
O exemplo a seguir contém os parâmetros e dependências regulares necessários para executar um trabalho de comando, como computação, ambiente, etc.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
Próximos passos
- Saiba mais sobre como e onde implantar um modelo.
- Veja como habilitar recursos de interpretabilidade especificamente em experimentos automatizados de ML.