Script de pontuação de depuração com o servidor HTTP de inferência do Azure Machine Learning
O servidor HTTP de inferência do Azure Machine Learning é um pacote Python que expõe sua função de pontuação como um ponto de extremidade HTTP e encapsula o código e as dependências do servidor Flask em um pacote singular. Ele está incluído nas imagens pré-criadas do Docker para inferência que são usadas ao implantar um modelo com o Azure Machine Learning. Usando apenas o pacote, você pode implantar o modelo localmente para produção e também pode validar facilmente seu script de pontuação (entrada) em um ambiente de desenvolvimento local. Se houver um problema com o script de pontuação, o servidor retornará um erro e o local onde o erro ocorreu.
O servidor também pode ser usado para criar portas de validação em um pipeline contínuo de integração e implantação. Por exemplo, você pode iniciar o servidor com o script candidato e executar o conjunto de testes no ponto de extremidade local.
Este artigo destina-se principalmente a usuários que desejam usar o servidor de inferência para depurar localmente, mas também ajudará você a entender como usar o servidor de inferência com pontos de extremidade online.
Depuração local de ponto de extremidade online
Depurar pontos de extremidade localmente antes de implantá-los na nuvem pode ajudá-lo a detetar erros em seu código e configuração anteriormente. Para depurar pontos de extremidade localmente, você pode usar:
- o servidor HTTP de inferência do Azure Machine Learning
- um ponto final local
Este artigo se concentra no servidor HTTP de inferência do Azure Machine Learning.
A tabela a seguir fornece uma visão geral dos cenários para ajudá-lo a escolher o que funciona melhor para você.
| Cenário | Servidor HTTP de inferência | Ponto final local |
|---|---|---|
| Atualize o ambiente Python local sem a reconstrução da imagem do Docker | Sim | No |
| Atualizar script de pontuação | Sim | Sim |
| Atualizar configurações de implantação (implantação, ambiente, código, modelo) | Não | Sim |
| Integrar o depurador de código VS | Sim | Sim |
Ao executar o servidor HTTP de inferência localmente, você pode se concentrar em depurar seu script de pontuação sem ser afetado pelas configurações do contêiner de implantação.
Pré-requisitos
- Requer: Python >=3.8
- Anaconda
Gorjeta
O servidor HTTP de inferência do Azure Machine Learning é executado em sistemas operacionais baseados em Windows e Linux.
Instalação
Nota
Para evitar conflitos de pacote, instale o servidor em um ambiente virtual.
Para instalar o azureml-inference-server-http package, execute o seguinte comando no cmd/terminal:
python -m pip install azureml-inference-server-http
Depurar seu script de pontuação localmente
Para depurar seu script de pontuação localmente, você pode testar como o servidor se comporta com um script de pontuação fictício, usar o VS Code para depurar com o pacote azureml-inference-server-http ou testar o servidor com um script de pontuação real, arquivo de modelo e arquivo de ambiente de nosso repositório de exemplos.
Teste o comportamento do servidor com um script de pontuação fictício
Crie um diretório para armazenar seus arquivos:
mkdir server_quickstart cd server_quickstartPara evitar conflitos de pacotes, crie um ambiente virtual e ative-o:
python -m venv myenv source myenv/bin/activateGorjeta
Após o teste, execute
deactivatepara desativar o ambiente virtual Python.Instale o
azureml-inference-server-httppacote a partir do feed pypi :python -m pip install azureml-inference-server-httpCrie seu script de entrada (
score.py). O exemplo a seguir cria um script de entrada básico:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyInicie o servidor (azmlinfsrv) e defina
score.pycomo o script de entrada:azmlinfsrv --entry_script score.pyNota
O servidor está hospedado em 0.0.0.0, o que significa que ele ouvirá todos os endereços IP da máquina de hospedagem.
Envie uma solicitação de pontuação para o servidor usando
curl:curl -p 127.0.0.1:5001/scoreO servidor deve responder assim.
{"message": "Hello, World!"}
Após o teste, você pode pressionar Ctrl + C para encerrar o servidor.
Agora você pode modificar o script de pontuação (score.py) e testar suas alterações executando o servidor novamente (azmlinfsrv --entry_script score.py).
Como integrar com o Visual Studio Code
Há duas maneiras de usar o Visual Studio Code (VS Code) e Python Extension para depurar com o pacote azureml-inference-server-http (modos Iniciar e Anexar).
Modo de inicialização: configure o
launch.jsonno VS Code e inicie o servidor HTTP de inferência do Azure Machine Learning dentro do VS Code.Inicie o VS Code e abra a pasta que contém o script (
score.py).Adicione a seguinte configuração para
launch.jsonesse espaço de trabalho no VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Inicie a sessão de depuração no VS Code. Selecione "Executar" -> "Iniciar Depuração" (ou
F5).
Modo de anexação: inicie o servidor HTTP de inferência do Azure Machine Learning em uma linha de comando e use o VS Code + Python Extension para anexar ao processo.
Nota
Se você estiver usando o ambiente Linux, primeiro instale o
gdbpacote executandosudo apt-get install -y gdbo .Adicione a seguinte configuração para
launch.jsonesse espaço de trabalho no VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Inicie o servidor de inferência usando a CLI (
azmlinfsrv --entry_script score.py).Inicie a sessão de depuração no VS Code.
- No VS Code, selecione "Executar" -> "Iniciar Depuração" (ou
F5). - Insira o ID do
azmlinfsrvprocesso (não ogunicorn) usando os logs (do servidor de inferência) exibidos na CLI.
Nota
Se o seletor de processos não for exibido, insira manualmente o ID do
processIdlaunch.jsonprocesso no campo do .- No VS Code, selecione "Executar" -> "Iniciar Depuração" (ou
De ambas as maneiras, você pode definir o ponto de interrupção e depurar passo a passo.
Exemplo de ponta a ponta
Nesta seção, executaremos o servidor localmente com arquivos de exemplo (script de pontuação, arquivo de modelo e ambiente) em nosso repositório de exemplo. Os arquivos de exemplo também são usados em nosso artigo para Implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online
Clone o repositório de exemplo.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Crie e ative um ambiente virtual com conda. Neste exemplo, o
azureml-inference-server-httppacote é instalado automaticamente porque está incluído como uma biblioteca dependente doazureml-defaultspacote da seguinte formaconda.yml.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envReveja o seu guião de pontuação.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Execute o servidor de inferência especificando o script de pontuação e o arquivo de modelo. O diretório modelo especificado (
model_dirparâmetro) será definido comoAZUREML_MODEL_DIRvariável e recuperado no script de pontuação. Nesse caso, especificamos o diretório atual (./), uma vez que o subdiretório é especificado no script de pontuação comomodel/sklearn_regression_model.pkl.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./O exemplo de log de inicialização será mostrado se o servidor for iniciado e o script de pontuação invocado com êxito. Caso contrário, haverá mensagens de erro no log.
Teste o script de pontuação com um exemplo de dados. Abra outro terminal e mova para o mesmo diretório de trabalho para executar o comando. Use o
curlcomando para enviar uma solicitação de exemplo para o servidor e receber um resultado de pontuação.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonO resultado da pontuação será devolvido se não houver nenhum problema no seu script de pontuação. Se você encontrar algo errado, você pode tentar atualizar o script de pontuação e iniciar o servidor novamente para testar o script atualizado.
Rotas do servidor
O servidor está escutando na porta 5001 (como padrão) nessas rotas.
| Nome | Rota |
|---|---|
| Sonda de vivacidade | 127.0.0.1:5001/ |
| Resultado | 127.0.0.1:5001/pontuação |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
Parâmetros do servidor
A tabela a seguir contém os parâmetros aceitos pelo servidor:
| Parâmetro | Necessário | Predefinição | Description |
|---|---|---|---|
| entry_script | True | N/A | O caminho relativo ou absoluto para o script de pontuação. |
| model_dir | False | N/A | O caminho relativo ou absoluto para o diretório que contém o modelo usado para inferência. |
| porta | False | 5001 | A porta de serviço do servidor. |
| worker_count | False | 1 | O número de threads de trabalho que processarão solicitações simultâneas. |
| appinsights_instrumentation_key | False | N/A | A chave de instrumentação para os insights do aplicativo onde os logs serão publicados. |
| access_control_allow_origins | False | N/A | Habilite o CORS para as origens especificadas. Separe várias origens com ",". Exemplo: "microsoft.com, bing.com" |
Fluxo de solicitações
As etapas a seguir explicam como o servidor HTTP de inferência do Aprendizado de Máquina do Azure (azmlinfsrv) lida com solicitações de entrada:
- Um wrapper de CLI Python fica ao redor da pilha de rede do servidor e é usado para iniciar o servidor.
- Um cliente envia uma solicitação para o servidor.
- Quando uma solicitação é recebida, ela passa pelo servidor WSGI e, em seguida, é despachada para um dos trabalhadores.
- As solicitações são então tratadas por um aplicativo Flask , que carrega o script de entrada e quaisquer dependências.
- Finalmente, a solicitação é enviada para o seu script de entrada. Em seguida, o script de entrada faz uma chamada de inferência para o modelo carregado e retorna uma resposta.
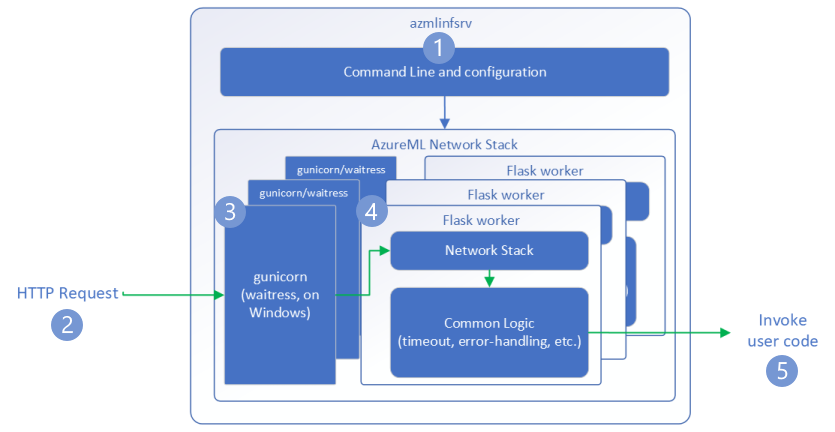
Noções básicas sobre logs
Aqui descrevemos os logs do servidor HTTP de inferência do Azure Machine Learning. Você pode obter o log quando executar o azureml-inference-server-http localmente ou obter logs de contêiner se estiver usando pontos de extremidade online.
Nota
O formato de registo foi alterado desde a versão 0.8.0. Se você encontrar seu login em estilo diferente, atualize o azureml-inference-server-http pacote para a versão mais recente.
Gorjeta
Se você estiver usando pontos de extremidade online, o log do servidor de inferência começará com Azure Machine Learning Inferencing HTTP server <version>.
Logs de inicialização
Quando o servidor é iniciado, as configurações do servidor são exibidas primeiro pelos logs da seguinte maneira:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
Por exemplo, quando você inicia o servidor, siga o exemplo de ponta a ponta:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Formato de registo
Os logs do servidor de inferência são gerados no seguinte formato, exceto para os scripts do iniciador, pois eles não fazem parte do pacote python:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Aqui <pid> está o ID do processo e é o primeiro caractere <level> do nível de log – E para ERROR, I para INFO, etc.
Existem seis níveis de registro em log em Python, com números associados à gravidade:
| Nível de registo | Valor numérico |
|---|---|
| CRÍTICO | 50 |
| ERRO | 40 |
| AVISO | 30 |
| INFORMAÇÃO | 20 |
| DEPURAR | 10 |
| NOTSET | 0 |
Guia de resolução de problemas
Nesta seção, forneceremos dicas básicas de solução de problemas para o servidor HTTP de inferência do Azure Machine Learning. Se você quiser solucionar problemas de pontos de extremidade online, consulte também Solução de problemas de implantação de pontos de extremidade online
Passos básicos
As etapas básicas para solução de problemas são:
- Reúna informações de versão para seu ambiente Python.
- Verifique se a versão do pacote python azureml-inference-server-http especificada no arquivo de ambiente corresponde à versão do servidor HTTP de Inferência do AzureML exibida no log de inicialização. Às vezes, o resolvedor de dependência do pip leva a versões inesperadas dos pacotes instalados.
- Se você especificar Flask (e ou suas dependências) em seu ambiente, remova-os. As dependências incluem
Flask,Jinja2,itsdangerous,Werkzeug,MarkupSafeeclick. O Flask está listado como uma dependência no pacote do servidor e é melhor deixar o nosso servidor instalá-lo. Desta forma, quando o servidor suporta novas versões do Flask, você as obterá automaticamente.
Versão do servidor
O pacote do azureml-inference-server-http servidor é publicado no PyPI. Você pode encontrar nosso changelog e todas as versões anteriores em nossa página PyPI. Atualize para a versão mais recente se estiver a utilizar uma versão anterior.
- 0.4.x: A versão incluída nas imagens de treinamento ≤
20220601e noazureml-defaults>=1.34,<=1.43.0.4.13é a última versão estável. Se você usar o servidor antes da versão0.4.11, poderá ver problemas de dependência do Flask, como não é possível importar o nomeMarkupdojinja2. Recomenda-se que atualize para0.4.13ou0.8.x(a versão mais recente), se possível. - 0.6.x: A versão pré-instalada na inferência de imagens ≤ 20220516. A última versão estável é
0.6.1. - 0.7.x: A primeira versão que suporta o Flask 2. A última versão estável é
0.7.7. - 0.8.x: O formato de log foi alterado e o suporte ao Python 3.6 caiu.
Dependências do pacote
Os pacotes mais relevantes para o servidor azureml-inference-server-http são os seguintes pacotes:
- frasco
- opencensus-ext-azure
- Esquema de inferência
Se você especificou azureml-defaults em seu ambiente Python, o azureml-inference-server-http pacote é dependente e será instalado automaticamente.
Gorjeta
Se você estiver usando o Python SDK v1 e não especificar azureml-defaults explicitamente em seu ambiente Python, o SDK poderá adicionar o pacote para você. No entanto, ele irá bloqueá-lo para a versão em que o SDK está. Por exemplo, se a versão do SDK for 1.38.0, ela será adicionada azureml-defaults==1.38.0 aos requisitos de pip do ambiente.
Perguntas mais frequentes
1. Encontrei o seguinte erro durante a inicialização do servidor:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
Você tem o Flask 2 instalado em seu ambiente python, mas está executando uma versão que azureml-inference-server-http não suporta o Flask 2. Suporte para Flask 2 é adicionado em azureml-inference-server-http>=0.7.0, que também está em azureml-defaults>=1.44.
Se você não estiver usando este pacote em uma imagem do docker do AzureML, use a versão mais recente do
azureml-inference-server-httpouazureml-defaults.Se estiver a utilizar este pacote com uma imagem docker do AzureML, certifique-se de que está a utilizar uma imagem incorporada ou posterior a julho de 2022. A versão da imagem está disponível nos logs do contêiner. Você deve ser capaz de encontrar um log semelhante ao seguinte:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |A data de construção da imagem aparece após "Materialization Build", que no exemplo acima é
20220708, ou 8 de julho de 2022. Esta imagem é compatível com o Flask 2. Se você não vir um banner como este no log do contêiner, sua imagem está desatualizada e deve ser atualizada. Se você estiver usando uma imagem CUDA e não conseguir encontrar uma imagem mais recente, verifique se sua imagem foi preterida no AzureML-Containers. Se for, você deve ser capaz de encontrar substitutos.Se estiver a utilizar o servidor com um ponto de extremidade online, também pode encontrar os registos em "Registos de implementação" na página do ponto de extremidade online no estúdio do Azure Machine Learning. Se você implantar com o SDK v1 e não especificar explicitamente uma imagem em sua configuração de implantação, o padrão será usar uma versão que corresponda ao conjunto de ferramentas do
openmpi4.1.0-ubuntu20.04SDK local, que pode não ser a versão mais recente da imagem. Por exemplo, oopenmpi4.1.0-ubuntu20.04:20220616SDK 1.43 usará como padrão o , que é incompatível. Certifique-se de usar o SDK mais recente para sua implantação.Se, por algum motivo, você não conseguir atualizar a imagem, poderá evitar temporariamente o problema fixando
azureml-defaults==1.43ouazureml-inference-server-http~=0.4.13, o que instalará o servidor da versão mais antiga comFlask 1.0.xo .
2. Encontrei um ImportError ou ModuleNotFoundError em módulos opencensus, jinja2, MarkupSafe, ou click durante a inicialização como a seguinte mensagem:
ImportError: cannot import name 'Markup' from 'jinja2'
As versões mais antigas (<= 0.4.10) do servidor não fixavam a dependência do Flask em versões compatíveis. Esse problema é corrigido na versão mais recente do servidor.
Próximos passos
- Para obter mais informações sobre como criar um script de entrada e implantar modelos, consulte Como implantar um modelo usando o Azure Machine Learning.
- Saiba mais sobre imagens do docker pré-construídas para inferência