Roteador de inferência do Azure Machine Learning e requisitos de conectividade
O roteador de inferência do Azure Machine Learning é um componente crítico para inferência em tempo real com cluster Kubernetes. Neste artigo, você pode aprender sobre:
- O que é o router de inferência do Azure Machine Learning
- Como funciona o dimensionamento automático
- Como configurar e atender ao desempenho da solicitação de inferência (# de solicitações por segundo e latência)
- Requisitos de conectividade para cluster de inferência AKS
O que é o router de inferência do Azure Machine Learning
O roteador de inferência do Azure Machine Learning é o componente front-end (azureml-fe) que é implantado no cluster AKS ou Arc Kubernetes no tempo de implantação da extensão do Azure Machine Learning. Tem as seguintes funções:
- Encaminha solicitações de inferência de entrada do balanceador de carga de cluster ou controlador de entrada para pods de modelo correspondentes.
- Balanceie a carga de todas as solicitações de inferência recebidas com roteamento coordenado inteligente.
- Gerencia o dimensionamento automático de pods de modelo.
- Capacidade tolerante a falhas e de failover, garantindo que as solicitações de inferência sejam sempre atendidas para aplicativos de negócios críticos.
As etapas a seguir mostram como as solicitações são processadas pelo front-end:
- O cliente envia a solicitação para o balanceador de carga.
- O balanceador de carga envia para um dos front-ends.
- O front-end localiza o roteador de serviço (a instância front-end que atua como coordenador) para o serviço.
- O roteador de serviço seleciona um back-end e o retorna para o front-end.
- O front-end encaminha a solicitação para o back-end.
- Depois que a solicitação for processada, o back-end enviará uma resposta ao componente front-end.
- O front-end propaga a resposta de volta para o cliente.
- O front-end informa ao roteador de serviço que o back-end terminou o processamento e está disponível para outras solicitações.
O diagrama a seguir ilustra esse fluxo:
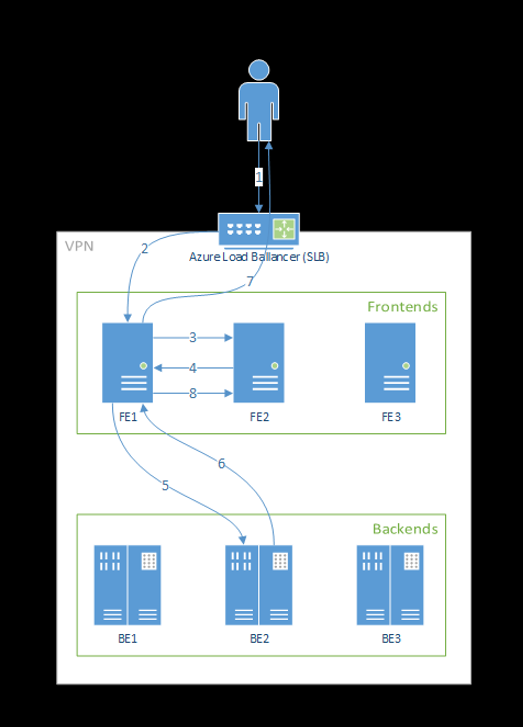
Como você pode ver no diagrama acima, por padrão, 3 azureml-fe instâncias são criadas durante a implantação da extensão do Azure Machine Learning, uma instância atua como função de coordenação e as outras instâncias atendem a solicitações de inferência de entrada. A instância coordenadora tem todas as informações sobre pods de modelo e toma decisões sobre qual pod de modelo atender à solicitação de entrada, enquanto as instâncias de serviço azureml-fe são responsáveis por rotear a solicitação para o pod de modelo selecionado e propagar a resposta de volta para o usuário original.
Dimensionamento automático
O roteador de inferência do Azure Machine Learning lida com o dimensionamento automático para todas as implantações de modelo no cluster do Kubernetes. Como todas as solicitações de inferência passam por ele, ele tem os dados necessários para dimensionar automaticamente o(s) modelo(s) implantado(s).
Importante
Não habilite o Kubernetes Horizontal Pod Autoscaler (HPA) para implantações de modelo. Isso faria com que os dois componentes de dimensionamento automático competissem entre si. O Azureml-fe foi projetado para dimensionar automaticamente modelos implantados pelo Azure Machine Learning, onde a HPA teria que adivinhar ou aproximar a utilização do modelo a partir de uma métrica genérica, como o uso da CPU ou uma configuração de métrica personalizada.
O Azureml-fe não dimensiona o número de nós em um cluster AKS, porque isso pode levar a aumentos de custo inesperados. Em vez disso, ele dimensiona o número de réplicas para o modelo dentro dos limites do cluster físico. Se precisar de dimensionar o número de nós no cluster, poderá dimensionar manualmente o cluster ou configurar o dimensionamento automático de clusters do AKS.
O dimensionamento automático pode ser controlado pela scale_settings propriedade na implantação YAML. O exemplo a seguir demonstra como habilitar o dimensionamento automático:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
A decisão de aumentar ou diminuir a escala baseia-se em utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Se esse número exceder target_utilization_percentageo , mais réplicas serão criadas. Se for menor, as réplicas serão reduzidas. Por padrão, a utilização de destino é de 70%.
As decisões para adicionar réplicas são rápidas e rápidas (cerca de 1 segundo). As decisões para remover réplicas são conservadoras (cerca de 1 minuto).
Por exemplo, se você deseja implantar um serviço modelo e deseja saber que muitas instâncias (pods/réplicas) devem ser configuradas para solicitações de destino por segundo (RPS) e tempo de resposta de destino. Você pode calcular as réplicas necessárias usando o seguinte código:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Desempenho do azureml-fe
O azureml-fe pode chegar a 5 K solicitações por segundo (QPS) com boa latência, tendo uma sobrecarga não superior a 3 ms em média e 15 ms no percentil 99%.
Nota
Se você tiver requisitos de RPS superiores a 10K, considere as seguintes opções:
- Aumente as solicitações/limites de recursos para
azureml-fepods: por padrão, ele tem 2 vCPU e 1.2G de limite de recursos de memória. - Aumente o número de instâncias do
azureml-fe. Por padrão, o Azure Machine Learning cria 3 ou 1azureml-feinstâncias por cluster.- Essa contagem de instâncias depende da sua configuração da
inferenceRouterHAtensão do Azure Machine Learning. - O aumento da contagem de instâncias não pode ser persistido, pois será substituído pelo valor configurado assim que a extensão for atualizada.
- Essa contagem de instâncias depende da sua configuração da
- Entre em contato com especialistas da Microsoft para obter ajuda.
Entender os requisitos de conectividade para o cluster de inferência do AKS
O cluster AKS é implantado com um dos dois modelos de rede a seguir:
- Rede Kubenet - Os recursos de rede são normalmente criados e configurados à medida que o cluster AKS é implantado.
- Rede CNI (Container Networking Interface) do Azure - O cluster AKS está conectado a um recurso e configurações de rede virtual existentes.
Para rede Kubenet, a rede é criada e configurada corretamente para o serviço Azure Machine Learning. Para a rede CNI, você precisa entender os requisitos de conectividade e garantir a resolução DNS e a conectividade de saída para inferência AKS. Por exemplo, você pode precisar de etapas adicionais se estiver usando um firewall para bloquear o tráfego de rede.
O diagrama a seguir mostra os requisitos de conectividade para inferência AKS. As setas pretas representam a comunicação real e as setas azuis representam os nomes de domínio. Talvez seja necessário adicionar entradas para esses hosts ao firewall ou ao servidor DNS personalizado.
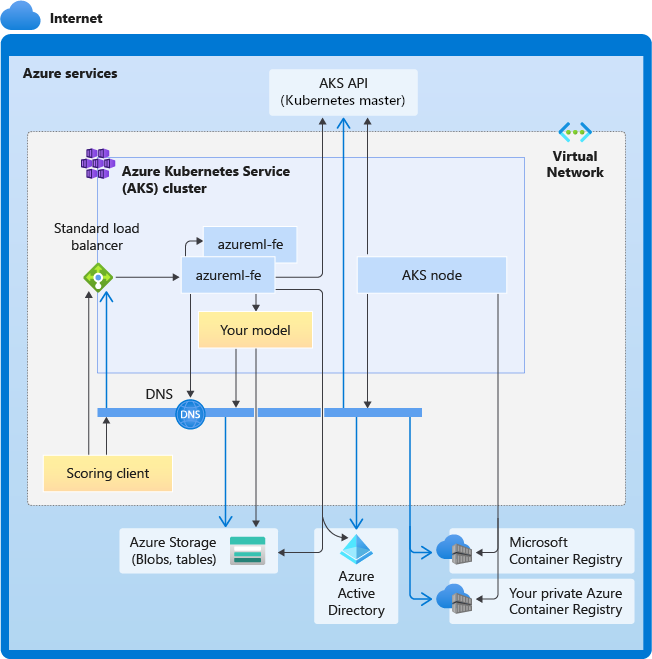
Para obter os requisitos gerais de conectividade do AKS, consulte Controlar o tráfego de saída para nós de cluster no Serviço Kubernetes do Azure.
Para acessar os serviços do Azure Machine Learning atrás de um firewall, consulte Configurar o tráfego de rede de entrada e saída.
Requisitos gerais de resolução de DNS
A resolução de DNS dentro de uma VNet existente está sob seu controle. Por exemplo, um firewall ou servidor DNS personalizado. Os seguintes hosts devem estar acessíveis:
| Nome do anfitrião | Utilizado por |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Servidor da API do AKS |
mcr.microsoft.com |
Registo de Contentor da Microsoft (MCR) |
<ACR name>.azurecr.io |
O Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Conta de Armazenamento do Azure (armazenamento de blobs) |
api.azureml.ms |
Autenticação do Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Ponto final do Kusto para carregar telemetria |
Requisitos de conectividade em ordem cronológica: da criação do cluster à implantação do modelo
Logo após a implantação do azureml-fe, ele tentará iniciar e isso exigirá:
- Resolver DNS para servidor de API AKS
- Consulte o servidor API do AKS para descobrir outras instâncias de si mesmo (é um serviço multi-pod)
- Conecte-se a outras instâncias de si mesmo
Uma vez iniciado o azureml-fe, ele requer a seguinte conectividade para funcionar corretamente:
- Conectar-se ao Armazenamento do Azure para baixar a configuração dinâmica
- Resolva o DNS para api.azureml.ms do servidor de autenticação Microsoft Entra e comunique-se com ele quando o serviço implantado usar a autenticação do Microsoft Entra.
- Consulte o servidor da API do AKS para descobrir modelos implantados
- Comunique-se com PODs de modelo implantados
No momento da implantação do modelo, para uma implantação de modelo bem-sucedida, o nó AKS deve ser capaz de:
- Resolver DNS para ACR do cliente
- Download de imagens do ACR do cliente
- Resolver DNS para BLOBs do Azure onde o modelo está armazenado
- Baixar modelos de BLOBs do Azure
Depois que o modelo for implantado e o serviço for iniciado, o azureml-fe o descobrirá automaticamente usando a API do AKS e estará pronto para rotear a solicitação para ele. Deve ser capaz de comunicar com modelos de PODs.
Nota
Se o modelo implantado exigir alguma conectividade (por exemplo, consultar banco de dados externo ou outro serviço REST, baixar um BLOB, etc.), a resolução DNS e a comunicação de saída para esses serviços devem ser habilitadas.