Use o pacote de interpretabilidade Python para explicar modelos de ML e previsões (visualização)
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste guia de instruções, você aprenderá a usar o pacote de interpretabilidade do SDK Python do Azure Machine Learning para executar as seguintes tarefas:
Explique localmente todo o comportamento do modelo ou previsões individuais na sua máquina pessoal.
Habilite técnicas de interpretabilidade para recursos projetados.
Explique o comportamento de todo o modelo e previsões individuais no Azure.
Carregue explicações para o Histórico de Execução do Azure Machine Learning.
Use um painel de visualização para interagir com as explicações do modelo, tanto em um Jupyter Notebook quanto no estúdio do Azure Machine Learning.
Implante um explicador de pontuação ao lado do seu modelo para observar as explicações durante a inferência.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Para obter mais informações sobre as técnicas de interpretabilidade suportadas e modelos de aprendizagem automática, consulte Interpretabilidade do modelo no Azure Machine Learning e exemplos de blocos de notas.
Para obter orientação sobre como habilitar a interpretabilidade para modelos treinados com aprendizado de máquina automatizado, consulte Interpretabilidade: explicações de modelo para modelos de aprendizado de máquina automatizados (visualização).
Gere valor de importância de recursos em sua máquina pessoal
O exemplo a seguir mostra como usar o pacote de interpretabilidade em sua máquina pessoal sem entrar em contato com os serviços do Azure.
Instale o pacote
azureml-interpret.pip install azureml-interpretTreine um modelo de amostra em um Caderno Jupyter local.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Ligue para o explicador localmente.
- Para inicializar um objeto explicador, passe seu modelo e alguns dados de treinamento para o construtor do explicador.
- Para tornar suas explicações e visualizações mais informativas, você pode optar por passar nomes de recursos e nomes de classe de saída se estiver fazendo a classificação.
Os blocos de código a seguir mostram como instanciar um objeto explicativo com
TabularExplainer,MimicExplainerePFIExplainerlocalmente.TabularExplainerchama um dos três explicadores SHAP abaixo (TreeExplainer,DeepExplainer, ouKernelExplainer).TabularExplainerseleciona automaticamente o mais apropriado para o seu caso de uso, mas você pode chamar cada um dos três explicadores subjacentes diretamente.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)ou
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)ou
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Explicar todo o comportamento do modelo (explicação global)
Consulte o exemplo a seguir para ajudá-lo a obter os valores de importância do recurso agregado (global).
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Explicar uma previsão individual (explicação local)
Obtenha os valores de importância de recursos individuais de diferentes pontos de dados chamando explicações para uma instância individual ou um grupo de instâncias.
Nota
PFIExplainer não suporta explicações locais.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Transformações de recursos brutos
Você pode optar por obter explicações em termos de recursos brutos e não transformados, em vez de recursos projetados. Para essa opção, você passa seu pipeline de transformação de recursos para o explicador em train_explain.py. Caso contrário, o explicador fornece explicações em termos de recursos projetados.
O formato das transformações suportadas é o mesmo descrito em sklearn-pandas. Em geral, todas as transformações são suportadas, desde que operem em uma única coluna para que fique claro que são um-para-muitos.
Obtenha uma explicação para as características brutas usando uma sklearn.compose.ColumnTransformer ou com uma lista de tuplas de transformador ajustadas. O exemplo a seguir usa sklearn.compose.ColumnTransformero .
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Caso você queira executar o exemplo com a lista de tuplas de transformador ajustadas, use o seguinte código:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Gere valores de importância de recursos por meio de execuções remotas
O exemplo a seguir mostra como você pode usar a classe para habilitar a interpretabilidade do ExplanationClient modelo para execuções remotas. É conceitualmente semelhante ao processo local, exceto você:
- Use o
ExplanationClientna execução remota para carregar o contexto de interpretabilidade. - Faça o download do contexto mais tarde em um ambiente local.
Instale o pacote
azureml-interpret.pip install azureml-interpretCrie um script de treinamento em um Jupyter Notebook local. Por exemplo,
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Configure uma computação do Azure Machine Learning como seu destino de computação e envie sua execução de treinamento. Consulte Criar e gerenciar clusters de computação do Azure Machine Learning para obter instruções. Você também pode achar os blocos de anotações de exemplo úteis.
Faça o download da explicação no seu Caderno Jupyter local.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualizações
Depois de baixar as explicações em seu Jupyter Notebook local, você pode usar as visualizações no painel de explicações para entender e interpretar seu modelo. Para carregar o widget do painel de explicações no seu Jupyter Notebook, use o seguinte código:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
As visualizações suportam explicações sobre recursos projetados e brutos. As explicações brutas são baseadas nos recursos do conjunto de dados original e as explicações de engenharia são baseadas nos recursos do conjunto de dados com engenharia de recursos aplicada.
Ao tentar interpretar um modelo em relação ao conjunto de dados original, é recomendável usar explicações brutas, pois cada importância do recurso corresponderá a uma coluna do conjunto de dados original. Um cenário em que explicações projetadas podem ser úteis é ao examinar o impacto de categorias individuais a partir de uma característica categórica. Se uma codificação a quente for aplicada a um recurso categórico, as explicações de engenharia resultantes incluirão um valor de importância diferente por categoria, um por recurso de engenharia a quente. Essa codificação pode ser útil ao restringir qual parte do conjunto de dados é mais informativa para o modelo.
Nota
As explicações brutas e de engenharia são calculadas sequencialmente. Primeiro, uma explicação de engenharia é criada com base no modelo e no pipeline de featurização. Em seguida, a explicação bruta é criada com base nessa explicação de engenharia, agregando a importância de recursos de engenharia que vieram do mesmo recurso bruto.
Criar, editar e exibir coortes de conjuntos de dados
A faixa de opções superior mostra as estatísticas gerais do seu modelo e dados. Você pode dividir e dividir seus dados em coortes ou subgrupos de conjuntos de dados para investigar ou comparar o desempenho e as explicações do seu modelo nesses subgrupos definidos. Ao comparar as estatísticas e explicações do conjunto de dados entre esses subgrupos, você pode ter uma noção de por que possíveis erros estão acontecendo em um grupo versus outro.

Compreender todo o comportamento do modelo (explicação global)
As três primeiras guias do painel de explicação fornecem uma análise geral do modelo treinado, juntamente com suas previsões e explicações.
Desempenho do modelo
Avalie o desempenho do seu modelo explorando a distribuição dos seus valores de previsão e os valores das métricas de desempenho do seu modelo. Você pode investigar ainda mais seu modelo observando uma análise comparativa de seu desempenho em diferentes coortes ou subgrupos do seu conjunto de dados. Selecione filtros ao longo do valor y e do valor x para cortar em diferentes dimensões. Visualize métricas como precisão, precisão, recordação, taxa de falsos positivos (FPR) e taxa de falsos negativos (FNR).

Explorador de conjuntos de dados
Explore as estatísticas do conjunto de dados selecionando diferentes filtros ao longo dos eixos X, Y e de cores para dividir os dados em diferentes dimensões. Crie coortes de conjuntos de dados acima para analisar estatísticas de conjuntos de dados com filtros como resultados previstos, recursos de conjuntos de dados e grupos de erros. Use o ícone de engrenagem no canto superior direito do gráfico para alterar os tipos de gráfico.

Importância agregada do recurso
Explore os principais recursos importantes que afetam as previsões gerais do modelo (também conhecidas como explicação global). Use o controle deslizante para mostrar valores decrescentes de importância do recurso. Selecione até três coortes para ver seus valores de importância de recurso lado a lado. Selecione qualquer uma das barras de recursos no gráfico para ver como os valores do recurso selecionado impactam a previsão do modelo no gráfico de dependência abaixo.

Compreender previsões individuais (explicação local)
A quarta guia da guia de explicação permite detalhar um ponto de dados individual e suas importâncias de recursos individuais. Você pode carregar o gráfico de importância de recurso individual para qualquer ponto de dados clicando em qualquer um dos pontos de dados individuais no gráfico de dispersão principal ou selecionando um ponto de dados específico no assistente do painel à direita.
| Desenho | Description |
|---|---|
| Importância da característica individual | Mostra os recursos mais importantes para uma previsão individual. Ajuda a ilustrar o comportamento local do modelo subjacente em um ponto de dados específico. |
| Análise hipotética | Permite alterações nos valores de feição do ponto de dados real selecionado e observa as alterações resultantes no valor de previsão gerando um ponto de dados hipotético com os novos valores de recurso. |
| Expectativa Condicional Individual (ICE) | Permite alterações no valor do recurso de um valor mínimo para um valor máximo. Ajuda a ilustrar como a previsão do ponto de dados muda quando um recurso é alterado. |

Nota
Estas são explicações baseadas em muitas aproximações e não são a "causa" das previsões. Sem robustez matemática estrita de inferência causal, não aconselhamos os usuários a tomar decisões da vida real com base nas perturbações de recursos da ferramenta What-If. Esta ferramenta é principalmente para entender seu modelo e depuração.
Visualização no estúdio do Azure Machine Learning
Se você concluir as etapas de interpretabilidade remota (carregando explicações geradas para o Histórico de Execução do Aprendizado de Máquina do Azure), poderá exibir as visualizações no painel de explicações no estúdio do Azure Machine Learning. Este painel é uma versão mais simples do widget do painel que é gerado no seu Jupyter Notebook. A geração de pontos de dados hipotéticos e os gráficos ICE estão desativados, pois não há computação ativa no estúdio de Aprendizado de Máquina do Azure que possa executar seus cálculos em tempo real.
Se o conjunto de dados, as explicações globais e locais estiverem disponíveis, os dados preencherão todas as guias. No entanto, se apenas uma explicação global estiver disponível, a guia Importância do recurso individual será desativada.
Siga um destes caminhos para acessar o painel de explicações no estúdio do Azure Machine Learning:
Painel Experiências (Pré-visualização)
- Selecione Experiências no painel esquerdo para ver uma lista de experiências que executou no Azure Machine Learning.
- Selecione um experimento específico para exibir todas as execuções desse experimento.
- Selecione uma execução e, em seguida, a guia Explicações para o painel de visualização de explicação.
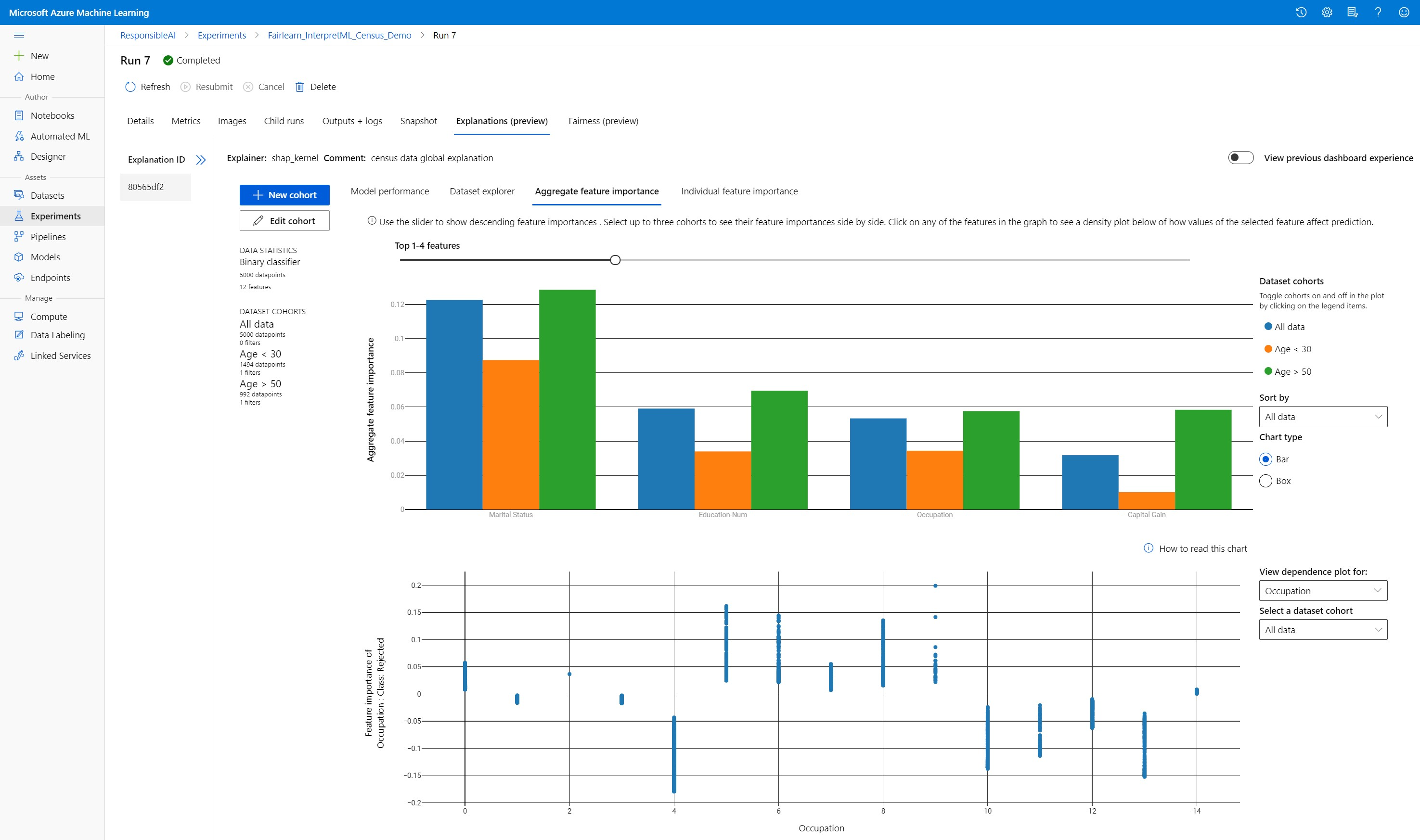
Painel Modelos
- Se você registrou seu modelo original seguindo as etapas em Implantar modelos com o Azure Machine Learning, poderá selecionar Modelos no painel esquerdo para exibi-lo.
- Selecione um modelo e, em seguida, a guia Explicações para exibir o painel de explicações.

Interpretabilidade no momento da inferência
Você pode implantar o explicador junto com o modelo original e usá-lo no momento da inferência para fornecer os valores de importância do recurso individual (explicação local) para qualquer novo ponto de dados. Também oferecemos explicadores de pontuação mais leves para melhorar o desempenho da interpretabilidade no momento da inferência, que atualmente é suportado apenas no SDK do Azure Machine Learning. O processo de implantação de um explicador de pontuação mais leve é semelhante à implantação de um modelo e inclui as seguintes etapas:
Crie um objeto de explicação. Por exemplo, você pode usar
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Crie um explicador de pontuação com o objeto de explicação.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Configure e registre uma imagem que use o modelo explicativo de pontuação.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Como etapa opcional, você pode recuperar o explicador de pontuação da nuvem e testar as explicações.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Implante a imagem em um destino de computação, seguindo estas etapas:
Se necessário, registre seu modelo de previsão original seguindo as etapas em Implantar modelos com o Azure Machine Learning.
Crie um arquivo de pontuação.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Defina a configuração da implementação.
Esta configuração depende dos requisitos do seu modelo. O exemplo a seguir define uma configuração que usa um núcleo de CPU e um GB de memória.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Crie um arquivo com dependências de ambiente.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Crie um dockerfile personalizado com o g++ instalado.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Implante a imagem criada.
Este processo demora aproximadamente cinco minutos.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Teste a implantação.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Limpe.
Para excluir um serviço Web implantado, use
service.delete().
Resolução de Problemas
Dados esparsos não suportados: O painel de explicação do modelo quebra/diminui substancialmente com um grande número de recursos, portanto, atualmente não suportamos o formato de dados esparso. Além disso, problemas gerais de memória surgirão com grandes conjuntos de dados e grande número de recursos.
Matriz de recursos de explicações suportadas
| Guia de explicação suportada | Características brutas (densas) | Recursos brutos (esparsos) | Características de engenharia (densas) | Recursos projetados (esparsos) |
|---|---|---|---|---|
| Desempenho do modelo | Suportado (não previsão) | Suportado (não previsão) | Suportado | Suportado |
| Explorador de conjuntos de dados | Suportado (não previsão) | Não suportado. Como dados esparsos não são carregados e a interface do usuário tem problemas para renderizar dados esparsos. | Suportado | Não suportado. Como dados esparsos não são carregados e a interface do usuário tem problemas para renderizar dados esparsos. |
| Importância agregada do recurso | Suportado | Suportado | Suportado | Suportado |
| Importância da característica individual | Suportado (não previsão) | Não suportado. Como dados esparsos não são carregados e a interface do usuário tem problemas para renderizar dados esparsos. | Suportado | Não suportado. Como dados esparsos não são carregados e a interface do usuário tem problemas para renderizar dados esparsos. |
Modelos de previsão não suportados com explicações de modelo: A interpretabilidade, a melhor explicação do modelo, não está disponível para experimentos de previsão do AutoML que recomendam os seguintes algoritmos como o melhor modelo: TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Seasonal Average e Seasonal Naive. Os modelos de regressão de previsão AutoML suportam explicações. No entanto, no painel de explicação, a guia "Importância do recurso individual" não é suportada para previsão devido à complexidade em seus pipelines de dados.
Explicação local para o índice de dados: o painel de explicação não suporta a relação de valores de importância local a um identificador de linha do conjunto de dados de validação original se esse conjunto de dados for maior que 5000 pontos de dados à medida que o painel reduz aleatoriamente a resolução dos dados. No entanto, o painel mostra valores brutos de recursos do conjunto de dados para cada ponto de dados passado para o painel na guia Importância do recurso individual. Os usuários podem mapear as importâncias locais de volta ao conjunto de dados original por meio da correspondência dos valores brutos do recurso do conjunto de dados. Se o tamanho do conjunto de dados de validação for inferior a 5000 exemplos, o
indexrecurso no estúdio do Azure Machine Learning corresponderá ao índice no conjunto de dados de validação.Os gráficos What-if/ICE não são suportados no estúdio: os gráficos What-If e Individual Conditional Expectation (ICE) não são suportados no estúdio do Azure Machine Learning no separador Explicações, uma vez que a explicação carregada precisa de um cálculo ativo para recalcular previsões e probabilidades de funcionalidades perturbadas. Atualmente, é suportado em notebooks Jupyter quando executado como um widget usando o SDK.
Próximos passos
Técnicas para interpretabilidade de modelo no Azure Machine Learning
Confira os blocos de anotações de exemplo de interpretabilidade do Azure Machine Learning