Detetar desvio de dados (visualização) em conjuntos de dados
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Saiba como monitorar o desvio de dados e definir alertas quando o desvio é alto.
Nota
O monitoramento de modelo do Azure Machine Learning (v2) fornece recursos aprimorados para desvio de dados, juntamente com funcionalidades adicionais para monitorar sinais e métricas. Para saber mais sobre os recursos de monitoramento de modelo no Azure Machine Learning (v2), consulte Monitoramento de modelo com o Azure Machine Learning.
Com os monitores de conjunto de dados do Azure Machine Learning (visualização), você pode:
- Analise o desvio em seus dados para entender como eles mudam ao longo do tempo.
- Monitore os dados do modelo quanto às diferenças entre os conjuntos de dados de treinamento e serviço. Comece coletando dados de modelo de modelos implantados.
- Monitore novos dados quanto a diferenças entre qualquer conjunto de dados de linha de base e de destino.
- Recursos de perfil nos dados para acompanhar como as propriedades estatísticas mudam ao longo do tempo.
- Configure alertas sobre desvio de dados para alertas antecipados de possíveis problemas.
- Crie uma nova versão do conjunto de dados quando determinar que os dados se desviaram demais.
Um conjunto de dados do Azure Machine Learning é usado para criar o monitor. O conjunto de dados deve incluir uma coluna de carimbo de data/hora.
Você pode exibir métricas de desvio de dados com o SDK do Python ou no estúdio de Aprendizado de Máquina do Azure. Outras métricas e informações estão disponíveis por meio do recurso Azure Application Insights associado ao espaço de trabalho do Azure Machine Learning .
Importante
A deteção de desvio de dados para conjuntos de dados está atualmente em visualização pública. A versão de visualização é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Pré-requisitos
Para criar e trabalhar com monitores de conjunto de dados, você precisa:
- Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente hoje mesmo a versão gratuita ou paga do Azure Machine Learning .
- Um espaço de trabalho do Azure Machine Learning.
- O SDK do Azure Machine Learning para Python instalado, que inclui o pacote azureml-datasets.
- Dados estruturados (tabulares) com um carimbo de data/hora especificado no caminho do arquivo, nome do arquivo ou coluna nos dados.
O que é desvio de dados?
A precisão do modelo degrada-se com o tempo, em grande parte devido à deriva de dados. Para modelos de aprendizado de máquina, desvio de dados é a alteração nos dados de entrada do modelo que leva à degradação do desempenho do modelo. O desvio de dados de monitoramento ajuda a detetar esses problemas de desempenho do modelo.
As causas do desvio de dados incluem:
- O processo a montante muda, como a substituição de um sensor que altera as unidades de medida de polegadas para centímetros.
- Problemas de qualidade de dados, como um sensor quebrado sempre lendo 0.
- Deriva natural nos dados, como a temperatura média mudando com as estações.
- Alteração na relação entre características ou mudança de covariável.
O Azure Machine Learning simplifica a deteção de desvios ao calcular uma única métrica, abstraindo a complexidade dos conjuntos de dados que estão a ser comparados. Esses conjuntos de dados podem ter centenas de recursos e dezenas de milhares de linhas. Uma vez que o desvio é detetado, você detalha quais recursos estão causando o desvio. Em seguida, você inspeciona métricas de nível de recurso para depurar e isolar a causa raiz do desvio.
Essa abordagem de cima para baixo facilita o monitoramento de dados em vez das técnicas tradicionais baseadas em regras. Técnicas baseadas em regras, como intervalo de dados permitido ou valores exclusivos permitidos, podem ser demoradas e propensas a erros.
No Aprendizado de Máquina do Azure, você usa monitores de conjunto de dados para detetar e alertar sobre desvio de dados.
Monitores de conjunto de dados
Com um monitor de conjunto de dados, você pode:
- Detete e alerte para desvio de dados em novos dados em um conjunto de dados.
- Analise dados históricos para deriva.
- Crie um perfil de novos dados ao longo do tempo.
O algoritmo de desvio de dados fornece uma medida geral da mudança nos dados e indica quais características são responsáveis por uma investigação mais aprofundada. Os monitores de conjunto de dados produzem muitas outras métricas criando o perfil de novos dados no timeseries conjunto de dados.
Os alertas personalizados podem ser configurados em todas as métricas geradas pelo monitor por meio do Azure Application Insights. Os monitores de conjunto de dados podem ser usados para detetar rapidamente problemas de dados e reduzir o tempo para depurar o problema, identificando causas prováveis.
Conceitualmente, há três cenários principais para configurar monitores de conjunto de dados no Aprendizado de Máquina do Azure.
| Cenário | Description |
|---|---|
| Monitore os dados de serviço de um modelo em busca de desvio dos dados de treinamento | Os resultados desse cenário podem ser interpretados como o monitoramento de um proxy para a precisão do modelo, uma vez que a precisão do modelo se degrada quando os dados de serviço se desviam dos dados de treinamento. |
| Monitore um conjunto de dados de séries temporais quanto a desvios de um período de tempo anterior. | Esse cenário é mais geral e pode ser usado para monitorar conjuntos de dados envolvidos a montante ou a jusante da construção de modelos. O conjunto de dados de destino deve ter uma coluna de carimbo de data/hora. O conjunto de dados de linha de base pode ser qualquer conjunto de dados tabular que tenha recursos em comum com o conjunto de dados de destino. |
| Execute análises em dados passados. | Esse cenário pode ser usado para entender dados históricos e informar decisões em configurações para monitores de conjunto de dados. |
Os monitores de conjunto de dados dependem dos seguintes serviços do Azure.
| Serviço do Azure | Description |
|---|---|
| Conjunto de dados | O Drift usa conjuntos de dados do Machine Learning para recuperar dados de treinamento e comparar dados para treinamento de modelo. A geração de perfil de dados é usada para gerar algumas das métricas relatadas, como min, max, valores distintos, contagem de valores distintos. |
| Pipeline e computação do Azure Machine Learning | O trabalho de cálculo de desvio é hospedado em um pipeline do Azure Machine Learning. O trabalho é acionado sob demanda ou por agendamento para ser executado em uma computação configurada no momento da criação do monitor de deriva. |
| Application Insights | O Drift emite métricas para o Application Insights pertencentes ao espaço de trabalho de aprendizado de máquina. |
| Armazenamento de blobs do Azure | O Drift emite métricas no formato json para o armazenamento de blobs do Azure. |
Conjuntos de dados de base e de destino
Você monitora os conjuntos de dados do Aprendizado de Máquina do Azure em busca de desvio de dados. Ao criar um monitor de conjunto de dados, você faz referência a:
- Conjunto de dados de linha de base - geralmente o conjunto de dados de treinamento para um modelo.
- O conjunto de dados de destino - geralmente dados de entrada de modelo - é comparado ao longo do tempo com seu conjunto de dados de linha de base. Essa comparação significa que seu conjunto de dados de destino deve ter uma coluna de carimbo de data/hora especificada.
O monitor compara os conjuntos de dados de linha de base e de destino.
Criar conjunto de dados de destino
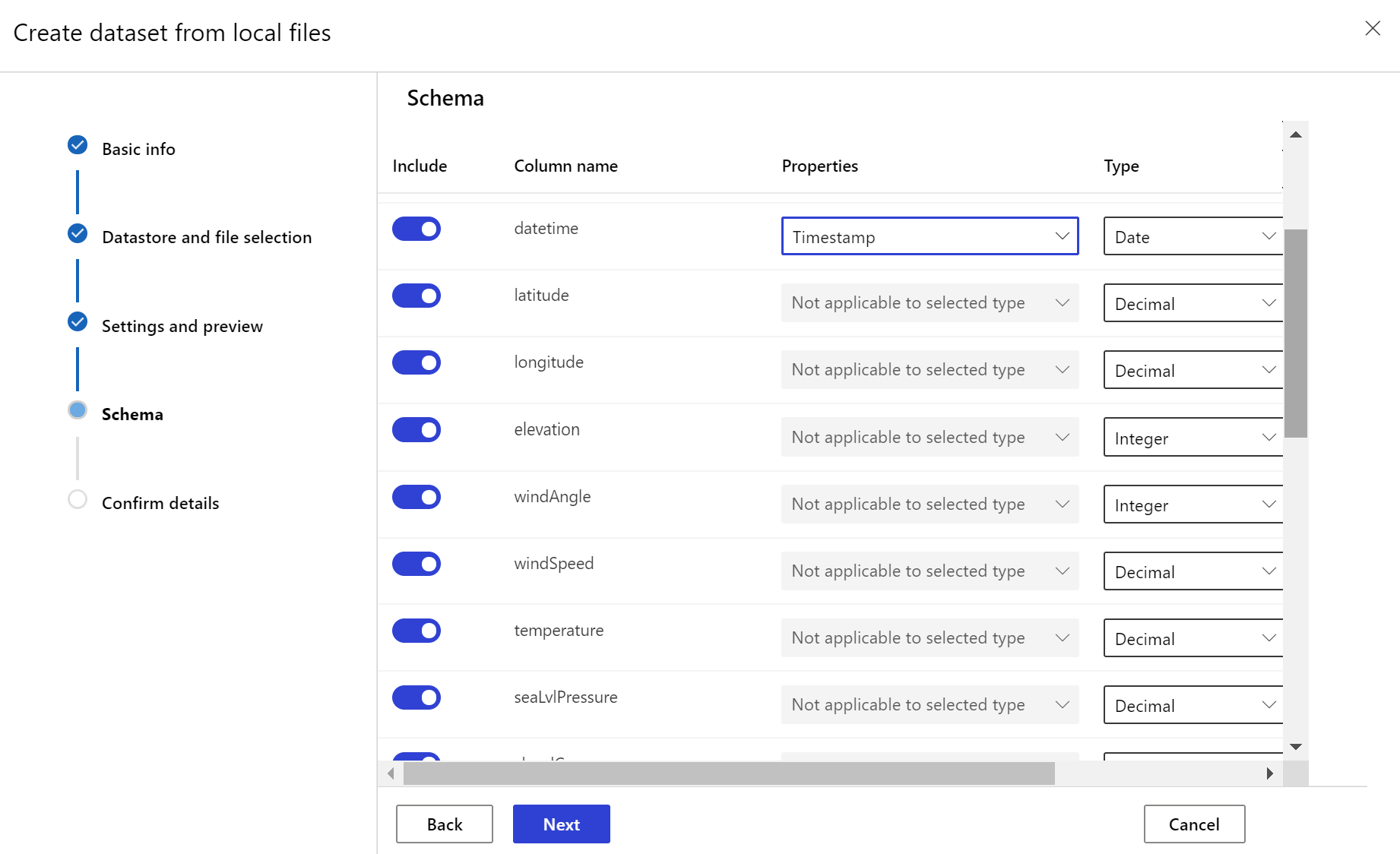
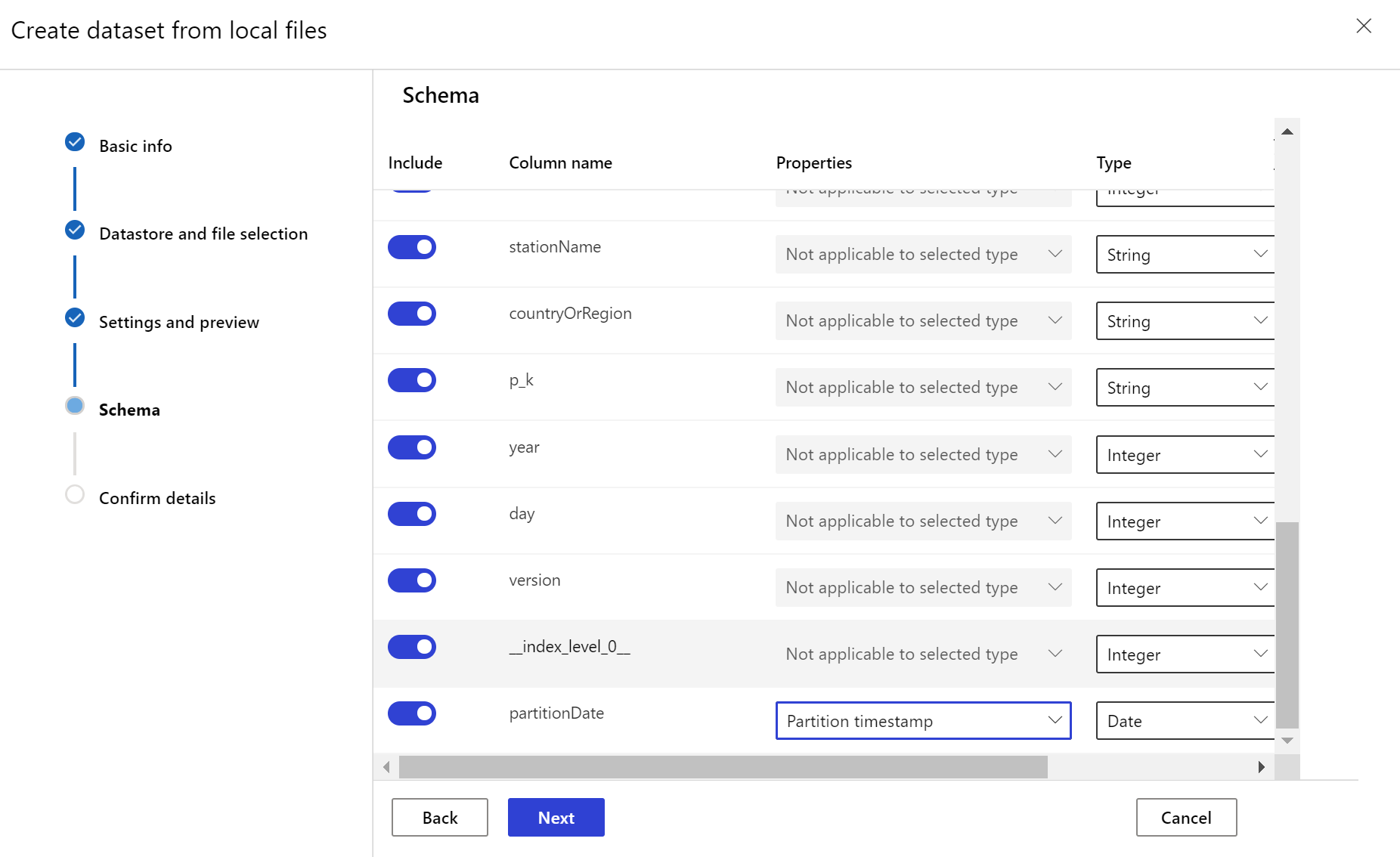
O conjunto de dados de destino precisa da timeseries característica definida nele, especificando a coluna de carimbo de data/hora de uma coluna nos dados ou de uma coluna virtual derivada do padrão de caminho dos arquivos. Crie o conjunto de dados com um carimbo de data/hora por meio do SDK do Python ou do estúdio do Azure Machine Learning. Uma coluna que representa um "carimbo de data/hora" deve ser especificada para adicionar timeseries uma característica ao conjunto de dados. Se seus dados forem particionados na estrutura de pastas com informações de tempo, como '{yyyy/MM/dd}', crie uma coluna virtual através da configuração de padrão de caminho e defina-a como o "carimbo de data/hora da partição" para habilitar a funcionalidade da API de série temporal.
APLICA-SE A: Python SDK azureml v1
O Dataset método class with_timestamp_columns() define a coluna de carimbo de data/hora para o conjunto de dados.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Gorjeta
Para obter um exemplo completo de como usar a timeseries característica de conjuntos de dados, consulte o bloco de anotações de exemplo ou a documentação do SDK de conjuntos de dados.

Criar monitor de conjunto de dados
Crie um monitor de conjunto de dados para detetar e alertar sobre desvio de dados em um novo conjunto de dados. Use o SDK do Python ou o estúdio do Azure Machine Learning.
Conforme descrito mais adiante, um monitor de conjunto de dados é executado em intervalos de frequência definidos (diários, semanais e mensais). Ele analisa novos dados disponíveis no conjunto de dados de destino desde sua última execução. Em alguns casos, esta análise dos dados mais recentes pode não ser suficiente:
- Os novos dados da fonte upstream foram atrasados devido a um pipeline de dados quebrado, e esses novos dados não estavam disponíveis quando o monitor do conjunto de dados foi executado.
- Um conjunto de dados de série temporal tinha apenas dados históricos e você deseja analisar padrões de desvio no conjunto de dados ao longo do tempo. Por exemplo: compare o tráfego que flui para um site, tanto no inverno quanto no verão, para identificar padrões sazonais.
- Você é novo no Dataset Monitors. Você deseja avaliar como o recurso funciona com seus dados existentes antes de configurá-lo para monitorar dias futuros. Nesses cenários, você pode enviar uma execução sob demanda, com um intervalo de datas de conjunto de dados de destino específico, para comparar com o conjunto de dados de linha de base.
A função de preenchimento executa um trabalho de preenchimento, para um intervalo de datas de início e fim especificado. Um trabalho de preenchimento preenche os pontos de dados ausentes esperados em um conjunto de dados, como uma maneira de garantir a precisão e integridade dos dados.
APLICA-SE A: Python SDK azureml v1
Consulte a documentação de referência do SDK do Python sobre desvio de dados para obter detalhes completos.
O exemplo a seguir mostra como criar um monitor de conjunto de dados usando o Python SDK
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Gorjeta
Para obter um exemplo completo de configuração de um timeseries conjunto de dados e detetor de desvio de dados, consulte nosso bloco de anotações de exemplo.
Compreender os resultados do desvio de dados
Esta seção mostra os resultados do monitoramento de um conjunto de dados, encontrados na página Monitores de Conjunto de Dados de Conjuntos / de Dados no estúdio do Azure. Você pode atualizar as configurações e analisar os dados existentes para um período de tempo específico nesta página.
Comece com os insights de alto nível sobre a magnitude do desvio de dados e um destaque de recursos a serem investigados mais a fundo.
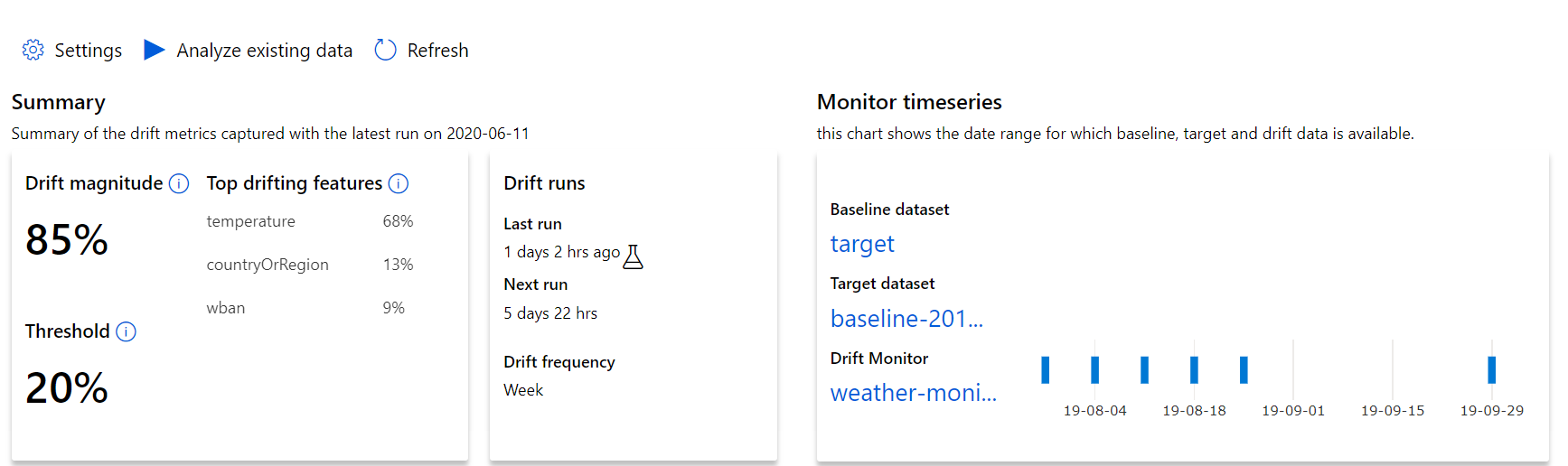
| Métrico | Description |
|---|---|
| Magnitude do desvio de dados | Uma percentagem de desvio entre o conjunto de dados de base e de destino ao longo do tempo. Essa porcentagem varia de 0 a 100, 0 indica conjuntos de dados idênticos e 100 indica que o modelo de desvio de dados do Azure Machine Learning pode diferenciar completamente os dois conjuntos de dados. O ruído na porcentagem exata medida é esperado devido às técnicas de aprendizado de máquina que estão sendo usadas para gerar essa magnitude. |
| Principais características de deriva | Mostra os recursos do conjunto de dados que mais se desviaram e, portanto, estão contribuindo mais para a métrica Magnitude de Deriva. Devido à mudança de covariável, a distribuição subjacente de um recurso não precisa necessariamente mudar para ter uma importância relativamente alta do recurso. |
| Threshold | A magnitude do desvio de dados além do limite definido aciona alertas. Configure o valor limite nas configurações do monitor. |
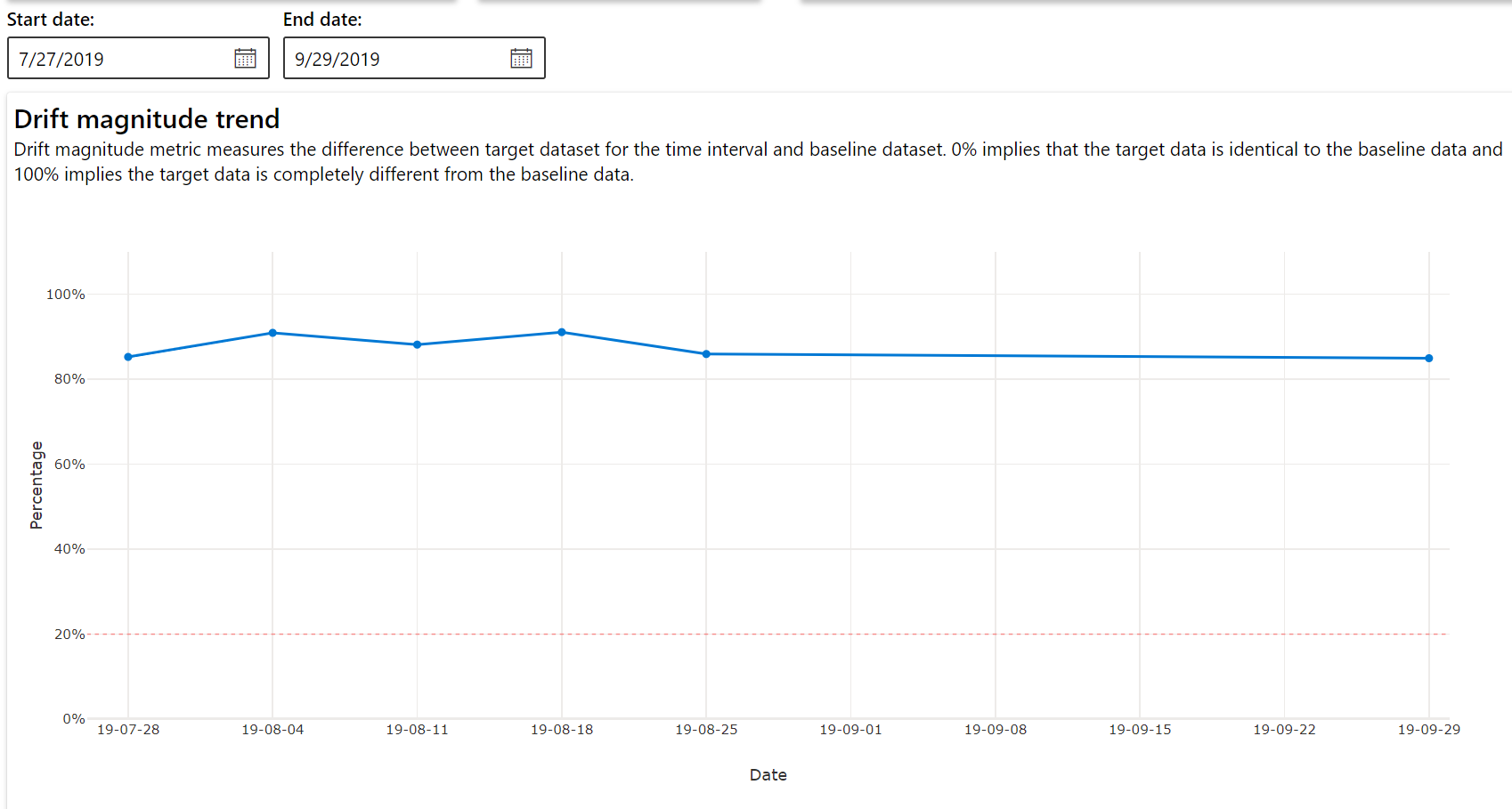
Tendência de magnitude de deriva
Veja como o conjunto de dados difere do conjunto de dados de destino no período de tempo especificado. Quanto mais próximo de 100%, mais os dois conjuntos de dados diferem.
Magnitude do desvio por características
Esta seção contém informações em nível de recurso sobre a alteração na distribuição do recurso selecionado e outras estatísticas ao longo do tempo.
O conjunto de dados de destino também é perfilado ao longo do tempo. A distância estatística entre a distribuição da linha de base de cada recurso é comparada com a do conjunto de dados de destino ao longo do tempo. Conceitualmente, isso se assemelha à magnitude do desvio de dados. No entanto, esta distância estatística é para uma característica individual e não para todas as características. Min, max e média também estão disponíveis.
No estúdio do Azure Machine Learning, selecione uma barra no gráfico para ver os detalhes no nível do recurso dessa data. Por padrão, você vê a distribuição do conjunto de dados da linha de base e a distribuição do trabalho mais recente do mesmo recurso.
Essas métricas também podem ser recuperadas no SDK do Python por meio do get_metrics() método em um DataDriftDetector objeto.
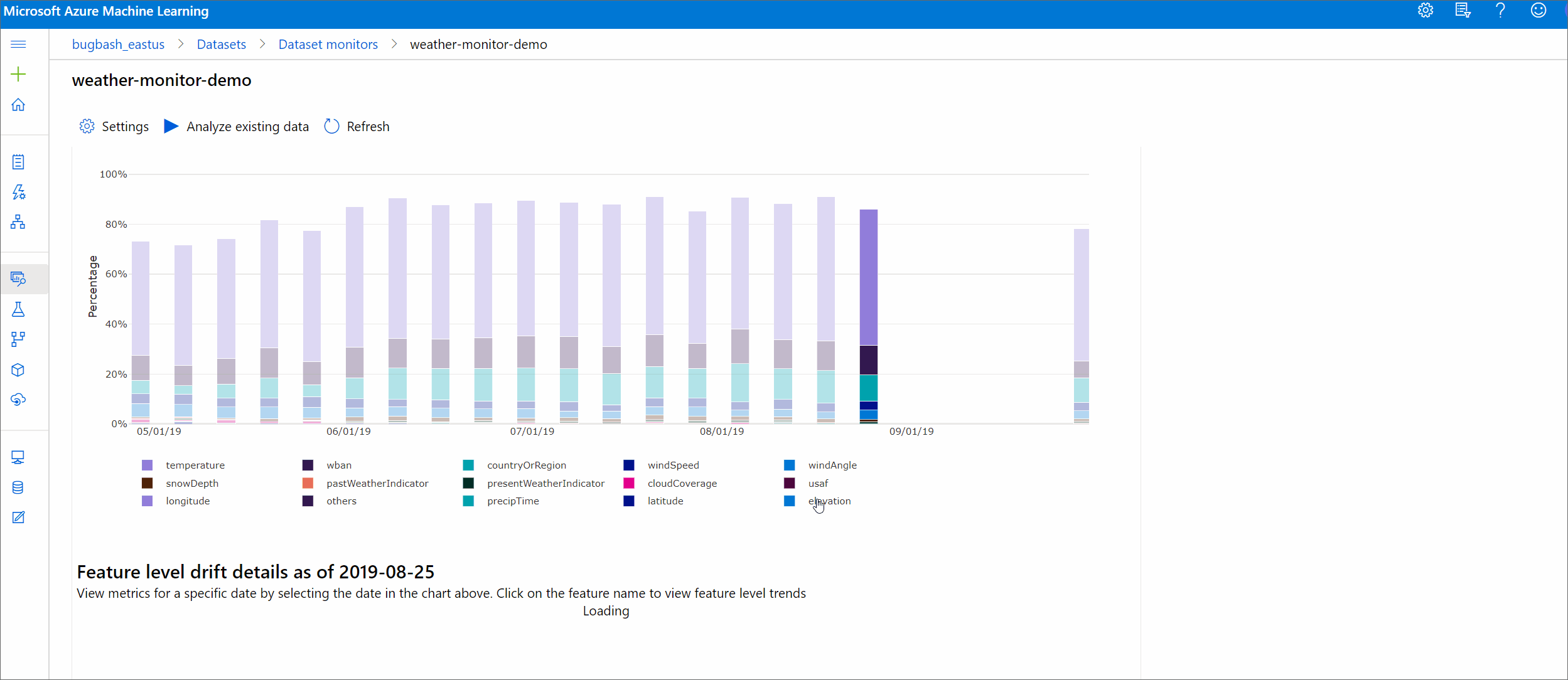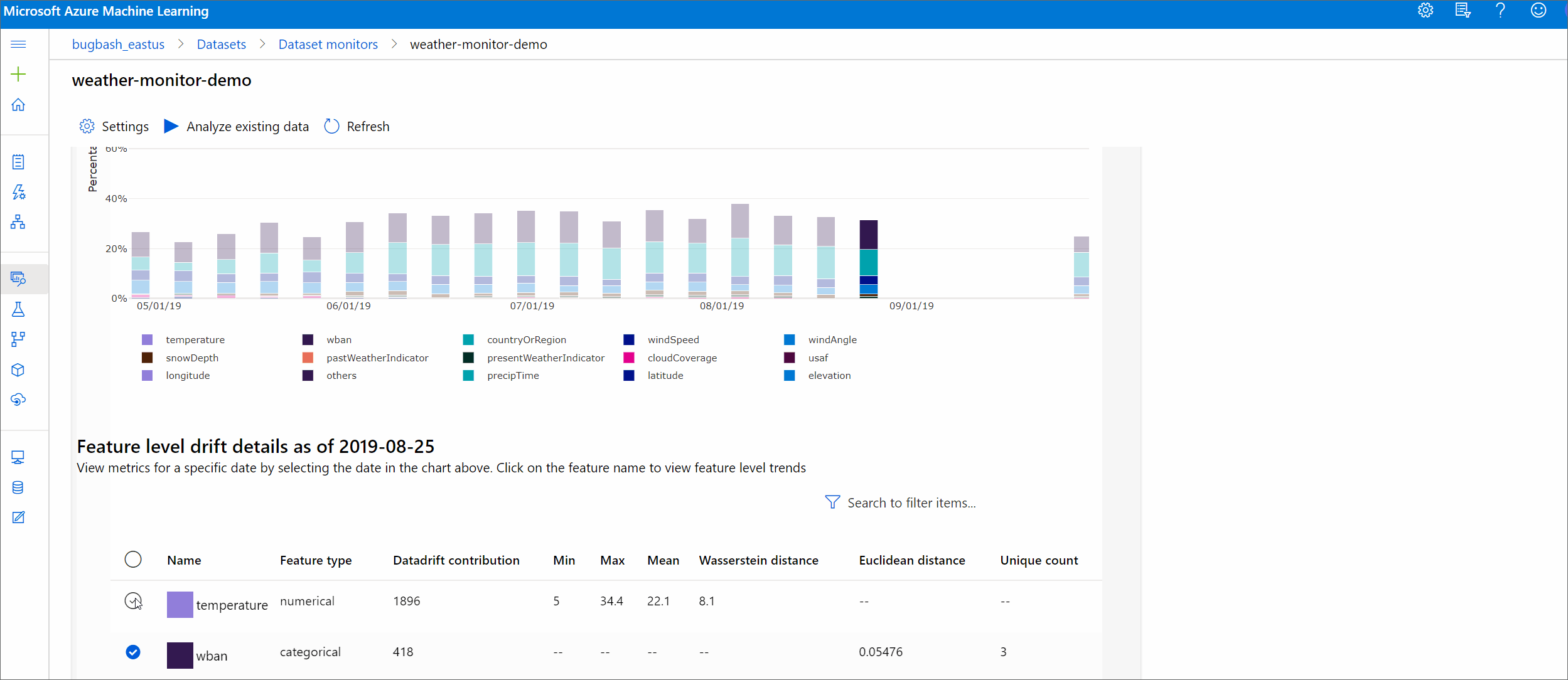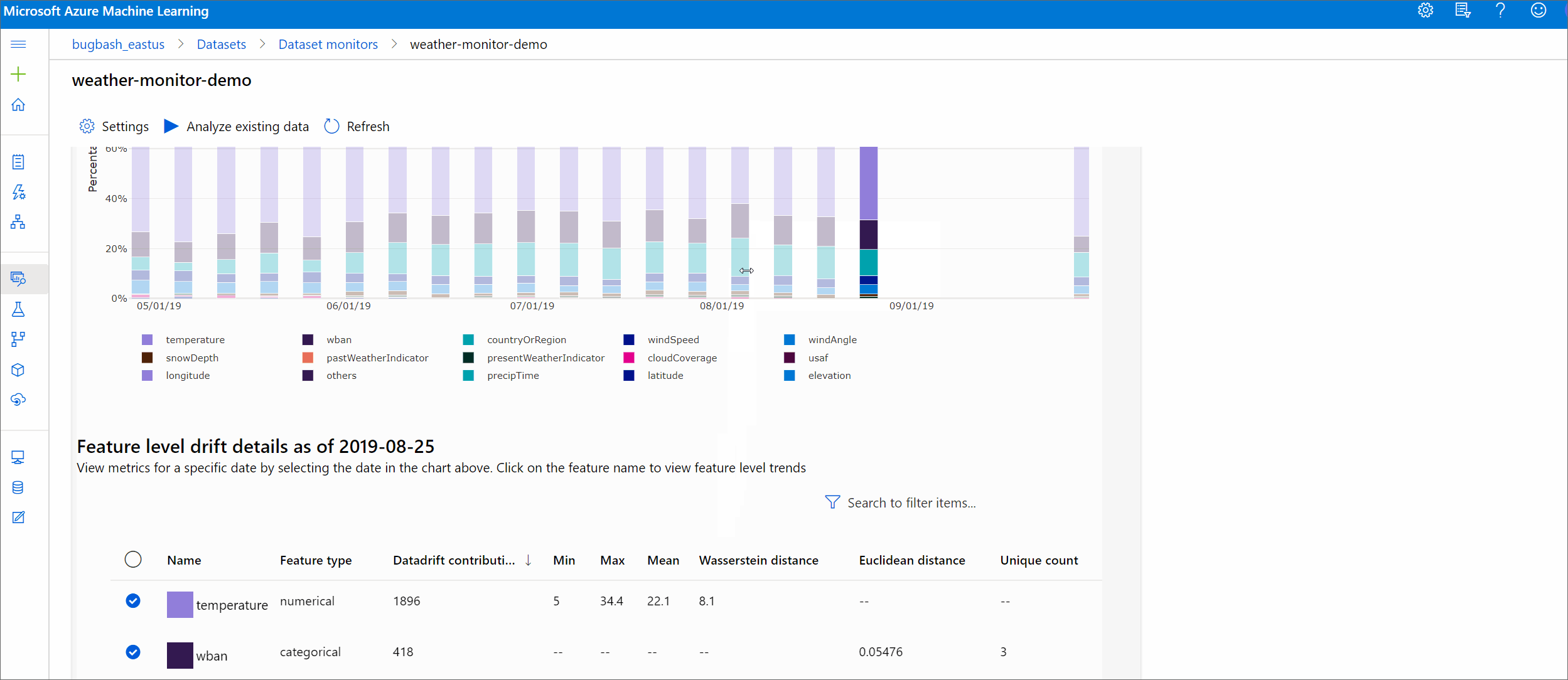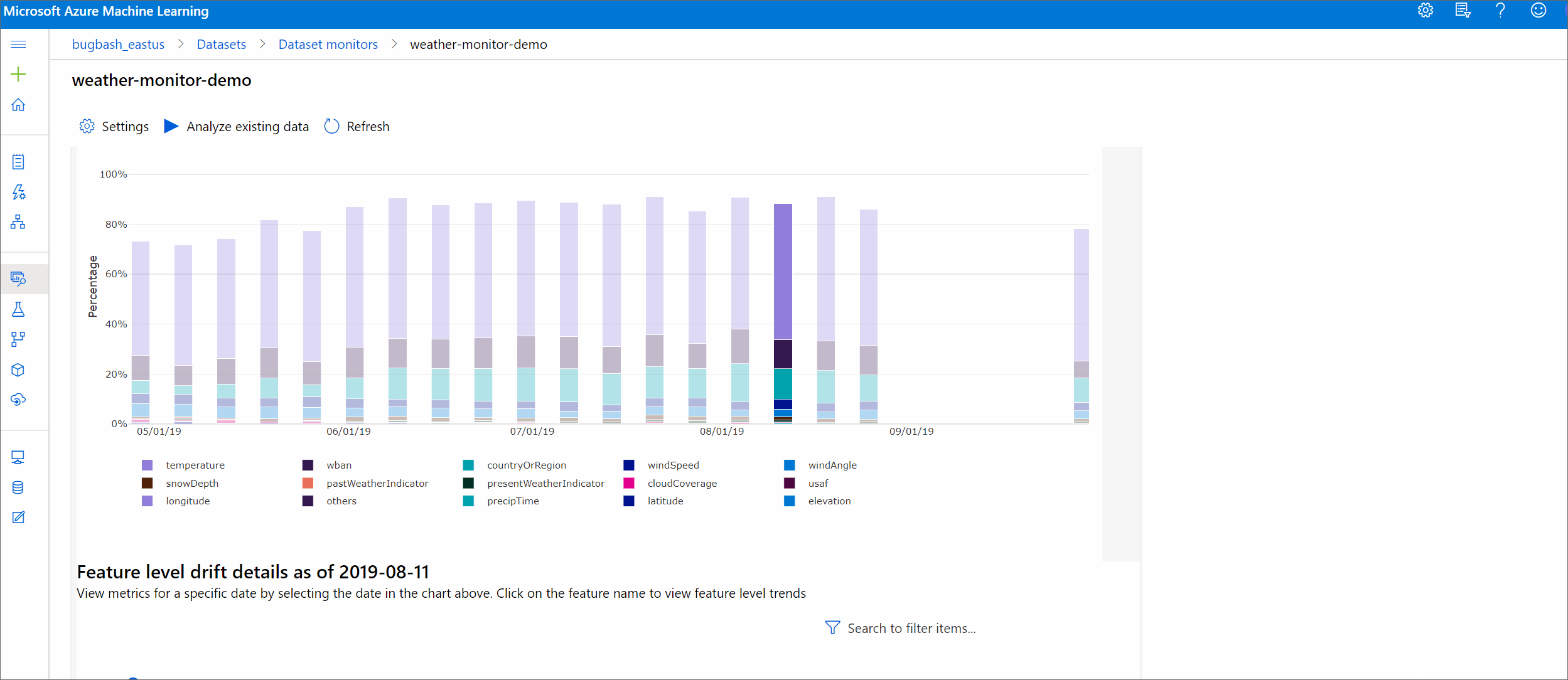
Detalhes da caraterística
Finalmente, role para baixo para ver os detalhes de cada recurso individual. Use os menus suspensos acima do gráfico para selecionar o recurso e, adicionalmente, selecione a métrica que deseja visualizar.
As métricas no gráfico dependem do tipo de recurso.
Características numéricas
Métrico Description Distância Wasserstein Quantidade mínima de trabalho para transformar a distribuição de linha de base na distribuição de destino. Valor médio Valor médio do recurso. Valor mínimo Valor mínimo do recurso. Valor máximo Valor máximo do recurso. Características categóricas
Métrico Description Distância euclidiana Computado para colunas categóricas. A distância euclidiana é calculada em dois vetores, gerados a partir da distribuição empírica da mesma coluna categórica a partir de dois conjuntos de dados. 0 indica que não há diferença nas distribuições empíricas. Quanto mais se desvia de 0, mais esta coluna se desvia. As tendências podem ser observadas a partir de um gráfico de séries temporais desta métrica e podem ser úteis para descobrir uma característica de deriva. Valores únicos Número de valores únicos (cardinalidade) do recurso.
Neste gráfico, selecione uma única data para comparar a distribuição do recurso entre o destino e esta data para o recurso exibido. Para características numéricas, isso mostra duas distribuições de probabilidade. Se o recurso for numérico, um gráfico de barras será mostrado.
Métricas, alertas e eventos
As métricas podem ser consultadas no recurso do Azure Application Insights associado ao seu espaço de trabalho de aprendizado de máquina. Você tem acesso a todos os recursos do Application Insights, incluindo a configuração de regras de alerta personalizadas e grupos de ação para acionar uma ação, como um Email/SMS/Push/Voice ou uma Função do Azure. Consulte a documentação completa do Application Insights para obter detalhes.
Para começar, navegue até o portal do Azure e selecione a página Visão geral do seu espaço de trabalho. O recurso associado do Application Insights está na extrema direita:

Selecione Logs (Analytics) em Monitoramento no painel esquerdo:
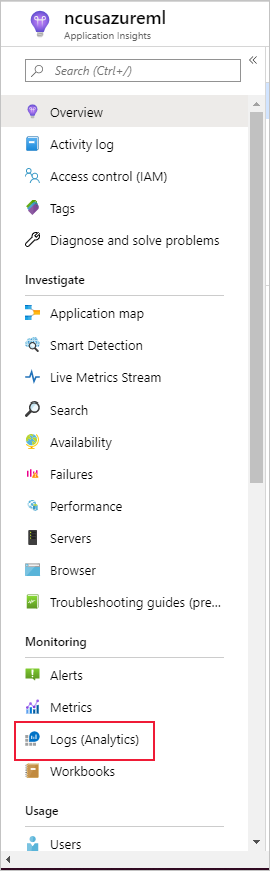
As métricas do monitor do conjunto de dados são armazenadas como customMetrics. Você pode escrever e executar uma consulta depois de configurar um monitor de conjunto de dados para exibi-los:

Depois de identificar métricas para configurar regras de alerta, crie uma nova regra de alerta:
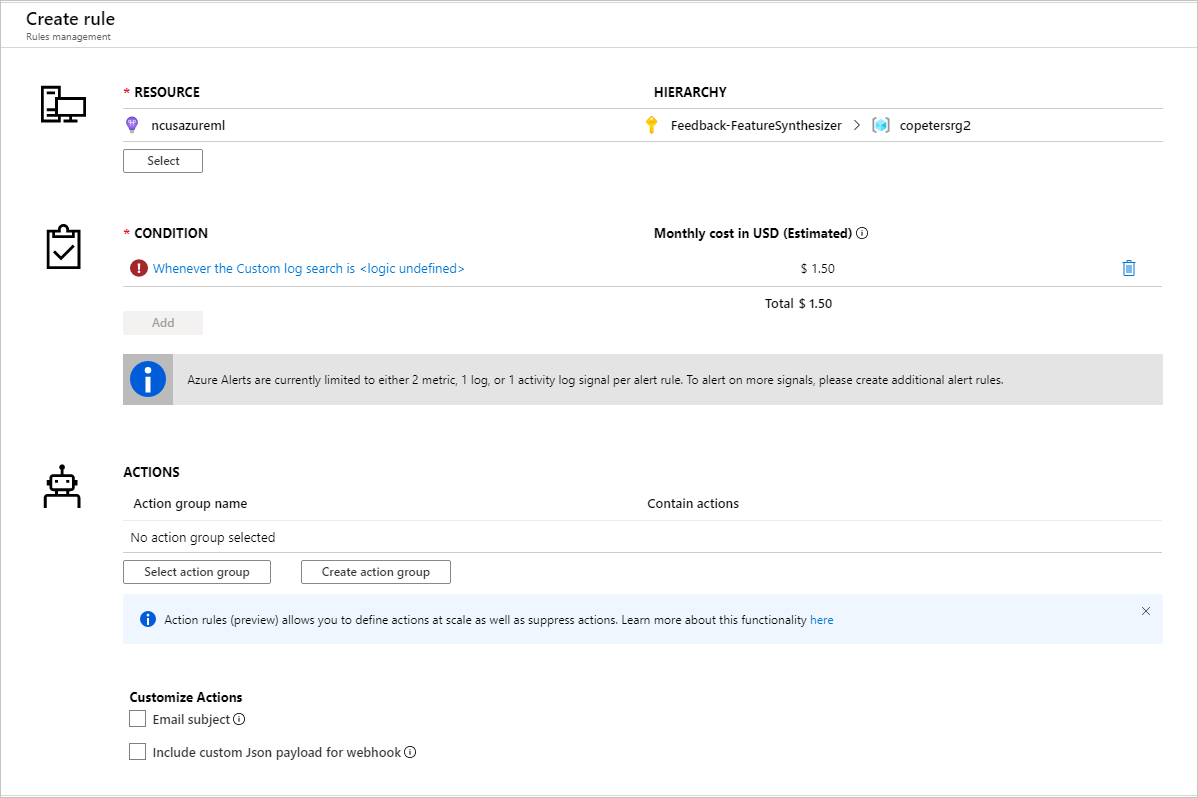
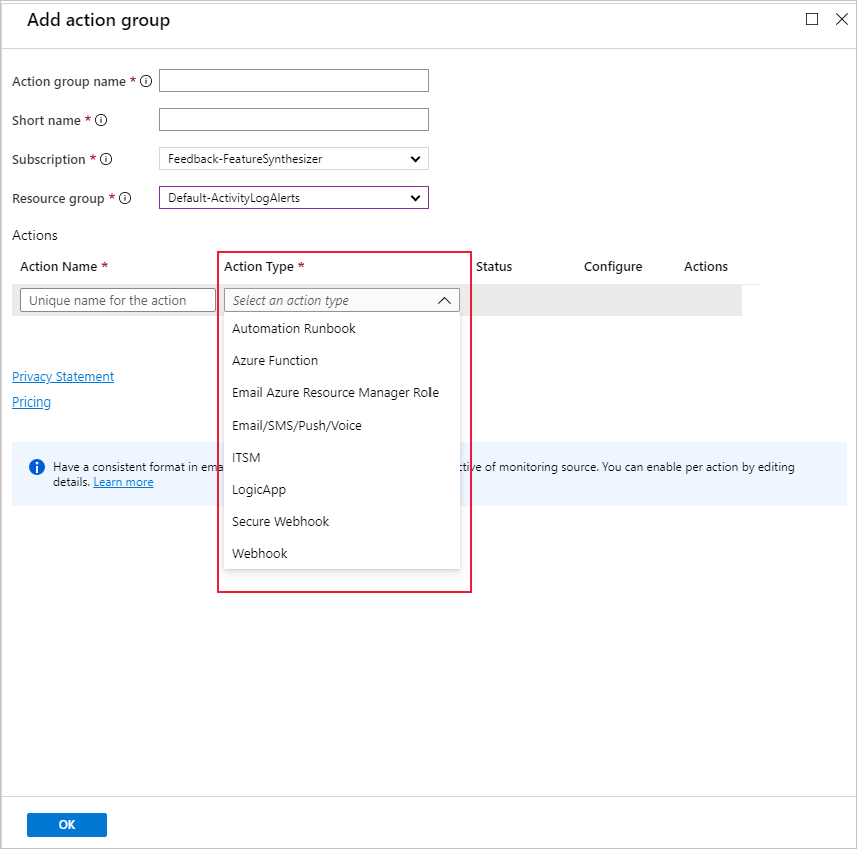
Você pode usar um grupo de ações existente ou criar um novo para definir a ação a ser executada quando as condições definidas forem atendidas:
Resolução de Problemas
Limitações e problemas conhecidos para monitores de desvio de dados:
O intervalo de tempo ao analisar dados históricos é limitado a 31 intervalos da configuração de frequência do monitor.
Limitação de 200 recursos, a menos que uma lista de recursos não seja especificada (todos os recursos usados).
O tamanho da computação deve ser grande o suficiente para lidar com os dados.
Certifique-se de que seu conjunto de dados tenha dados dentro das datas de início e término de um determinado trabalho de monitor.
Os monitores de conjunto de dados só funcionam em conjuntos de dados que contêm 50 linhas ou mais.
As colunas ou recursos no conjunto de dados são classificadas como categóricas ou numéricas com base nas condições da tabela a seguir. Se o recurso não atender a essas condições - por exemplo, uma coluna de cadeia de caracteres do tipo com >100 valores exclusivos - o recurso será descartado do nosso algoritmo de desvio de dados, mas ainda será perfilado.
Tipo de recurso Tipo de dados Condição Limitações Categórico string O número de valores exclusivos no recurso é menor que 100 e menos de 5% do número de linhas. Null é tratado como sua própria categoria. Numérico int, flutuar Os valores no recurso são de um tipo de dados numéricos e não atendem à condição para um recurso categórico. Recurso descartado se >15% dos valores forem nulos. Quando você tiver criado um monitor de desvio de dados, mas não conseguir ver os dados na página Monitores de Conjunto de Dados no estúdio do Azure Machine Learning, tente o seguinte.
- Verifique se você selecionou o intervalo de datas correto na parte superior da página.
- Na guia Monitores de Conjunto de Dados, selecione o link do experimento para verificar o status do trabalho. Este link está na extrema direita da tabela.
- Se o trabalho for concluído com êxito, verifique os logs do driver para ver quantas métricas foram geradas ou se há alguma mensagem de aviso. Encontre os logs do driver na guia Saída + logs depois de selecionar um experimento.
Se a função SDK
backfill()não gerar a saída esperada, pode ser devido a um problema de autenticação. Quando você criar o cálculo para passar para essa função, não useRun.get_context().experiment.workspace.compute_targets. Em vez disso, use ServicePrincipalAuthentication como o seguinte para criar a computação que você passa para essabackfill()função:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")A partir do Model Data Collector, pode levar até 10 minutos para que os dados cheguem à sua conta de armazenamento de blobs. No entanto, geralmente leva menos tempo. Em um script ou Bloco de Anotações, aguarde 10 minutos para garantir que as células abaixo sejam executadas com êxito.
import time time.sleep(600)
Próximos passos
- Vá para o estúdio do Azure Machine Learning ou para o bloco de anotações Python para configurar um monitor de conjunto de dados.
- Veja como configurar o desvio de dados em modelos implantados no Serviço Kubernetes do Azure.
- Configure monitores de desvio do conjunto de dados com a Grade de Eventos do Azure.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários