Gere insights de IA responsável na interface do usuário do estúdio
Neste artigo, você cria um painel de IA responsável e um scorecard (visualização) com uma experiência sem código na interface do usuário do estúdio de Aprendizado de Máquina do Azure.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Para acessar o assistente de geração de painel e gerar um painel de IA responsável, faça o seguinte:
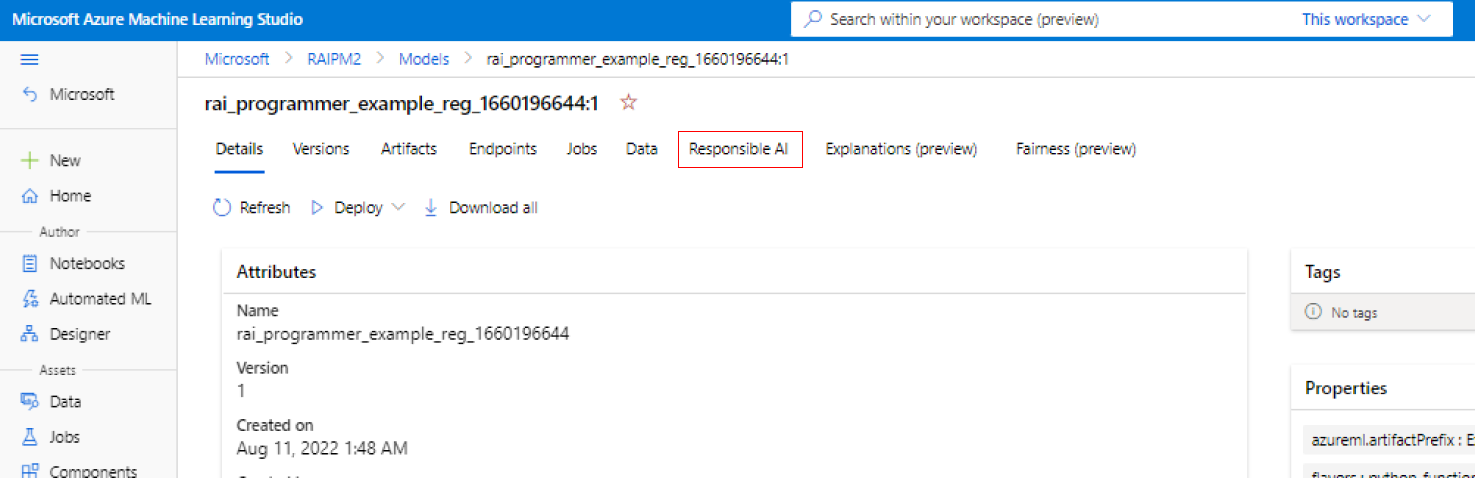
Registre seu modelo no Azure Machine Learning para que você possa acessar a experiência sem código.
No painel esquerdo do estúdio do Azure Machine Learning, selecione a guia Modelos .
Selecione o modelo registrado para o qual você deseja criar insights de IA responsável e, em seguida, selecione a guia Detalhes .
Selecione Criar painel de IA responsável (visualização).

Para saber mais sobre os tipos de modelo suportados e as limitações no painel de IA responsável, consulte Cenários e limitações suportados.
O assistente fornece uma interface para inserir todos os parâmetros necessários para criar seu painel de IA responsável sem ter que tocar no código. A experiência ocorre inteiramente na interface do usuário do estúdio de Aprendizado de Máquina do Azure. O estúdio apresenta um fluxo guiado e um texto instrutivo para ajudar a contextualizar a variedade de escolhas sobre quais componentes de IA responsável você gostaria de preencher seu painel.
O assistente está dividido em cinco seções:
- Conjuntos de dados de treinamento
- Conjunto de dados de teste
- Tarefa de modelagem
- Componentes do dashboard
- Parâmetros dos componentes
- Configuração do experimento
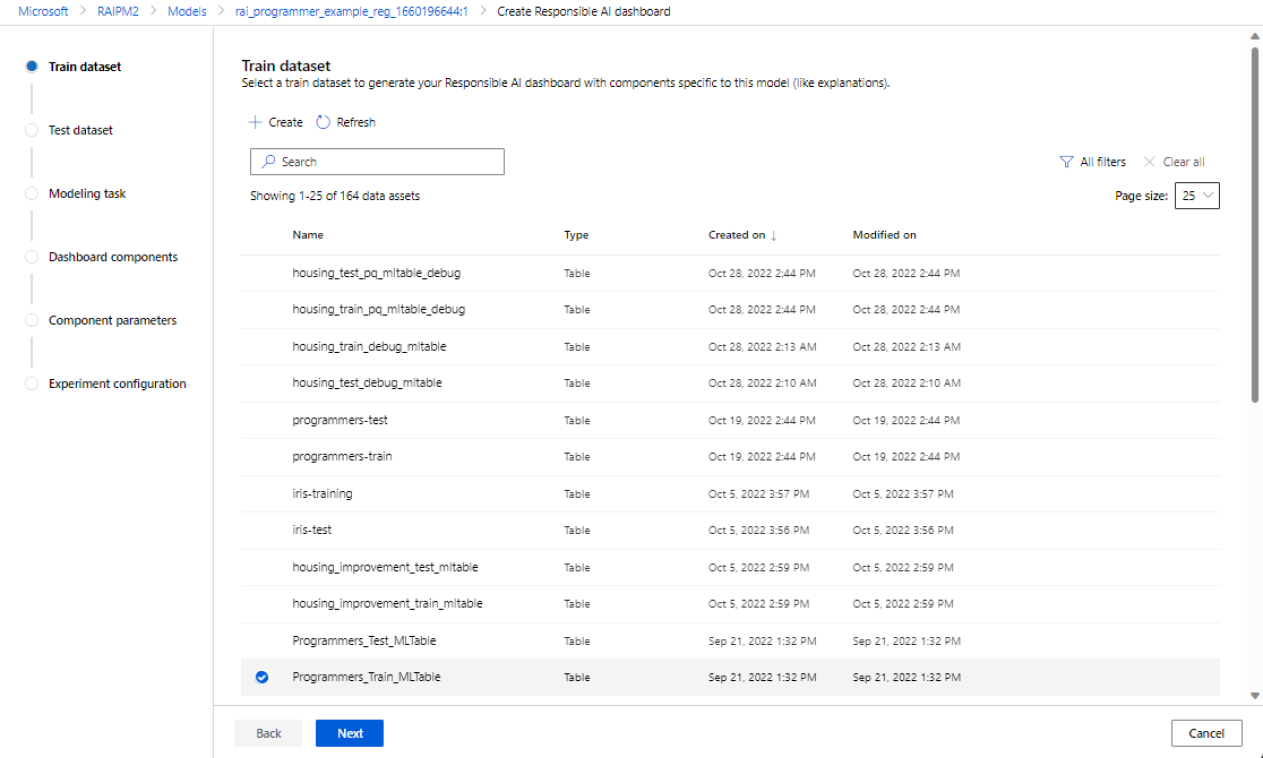
Selecione seus conjuntos de dados
Nas duas primeiras seções, você seleciona os conjuntos de dados de treinamento e teste que usou quando treinou seu modelo para gerar insights de depuração de modelo. Para componentes como a análise causal, que não requer um modelo, você usa o conjunto de dados de trem para treinar o modelo causal para gerar os insights causais.
Nota
Somente formatos de conjunto de dados tabulares na Tabela ML são suportados.
Selecione um conjunto de dados para treinamento: na lista de conjuntos de dados registrados no espaço de trabalho do Azure Machine Learning, selecione o conjunto de dados que você deseja usar para gerar insights de IA responsável para componentes, como explicações de modelo e análise de erros.
Selecione um conjunto de dados para teste: na lista de conjuntos de dados registrados, selecione o conjunto de dados que você deseja usar para preencher suas visualizações do painel de IA responsável.
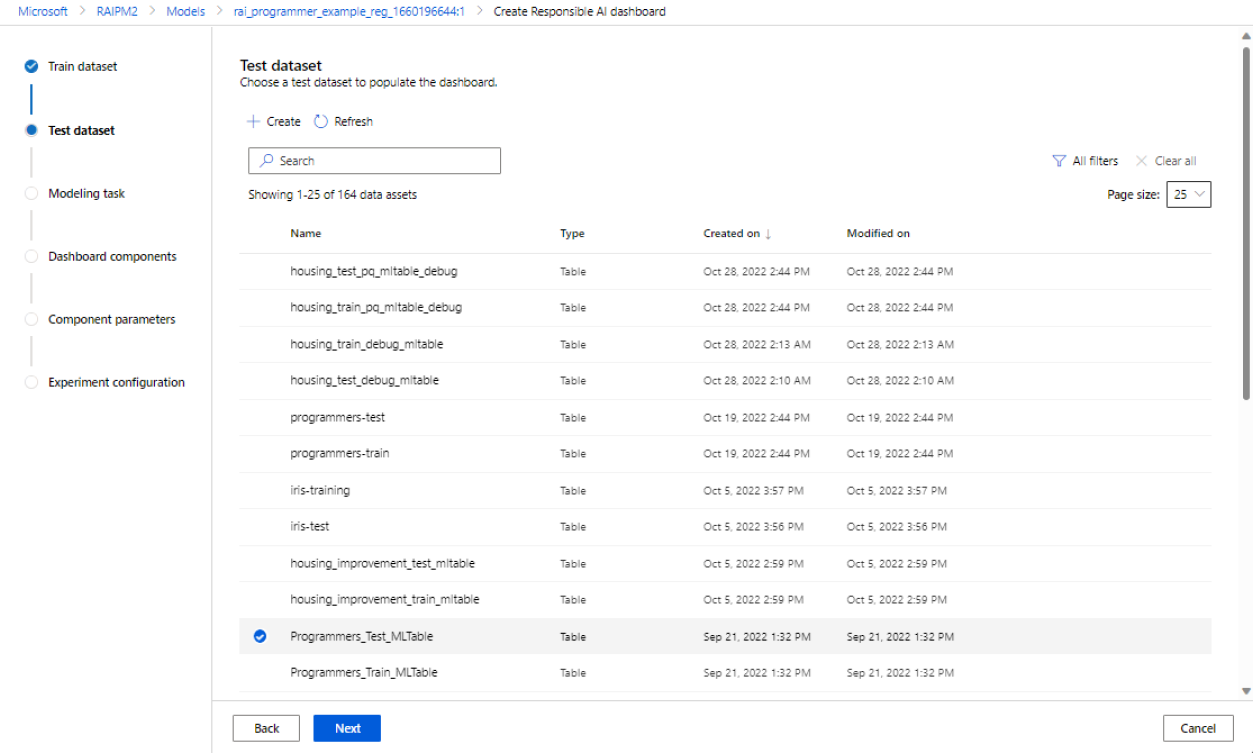
Se o conjunto de dados de trem ou teste que você deseja usar não estiver listado, selecione Criar para carregá-lo.


Selecione sua tarefa de modelagem
Depois de escolher seus conjuntos de dados, selecione o tipo de tarefa de modelagem, conforme mostrado na imagem a seguir:

Selecione os componentes do painel
O painel de IA Responsável oferece dois perfis para conjuntos recomendados de ferramentas que você pode gerar:
Depuração de modelo: compreenda e depure coortes de dados errôneos em seu modelo de aprendizado de máquina usando análise de erro, exemplos hipotéticos contrafactuais e explicabilidade do modelo.
Intervenções da vida real: compreenda e depure coortes de dados errôneos em seu modelo de aprendizado de máquina usando análise causal.
Nota
A classificação multiclasse não suporta o perfil de análise de intervenções da vida real.

- Selecione o perfil que deseja usar.
- Selecione Seguinte.
Configurar parâmetros para componentes do painel
Depois de selecionar um perfil, o painel de configuração Parâmetros do componente para depuração de modelo para os componentes correspondentes é exibido.

Parâmetros de componente para depuração de modelo:
Recurso de destino (obrigatório): especifique o recurso que seu modelo foi treinado para prever.
Recursos categóricos: indique quais recursos são categóricos para renderizá-los corretamente como valores categóricos na interface do usuário do painel. Este campo é pré-carregado para você com base nos metadados do conjunto de dados.
Gerar árvore de erros e mapa de calor: ative e desative para gerar um componente de análise de erros para seu painel de IA responsável.
Recursos para mapa de calor de erro: selecione até dois recursos para os quais você deseja pré-gerar um mapa de calor de erro.
Configuração avançada: especifique parâmetros adicionais, como Profundidade máxima da árvore de erro, Número de folhas na árvore de erro e Número mínimo de amostras em cada nó da folha.
Gere exemplos hipotéticos contrafactuais: ative e desative para gerar um componente hipotético contrafactual para seu painel de IA responsável.
Número de cenários em ausência de intervenção (obrigatório): especifique o número de exemplos contrafactuais que pretende gerar por ponto de dados. Um mínimo de 10 deve ser gerado para permitir uma visualização de gráfico de barras dos recursos que foram mais perturbados, em média, para alcançar a previsão desejada.
Intervalo de previsões de valor (obrigatório): especifique para cenários de regressão o intervalo no qual você deseja que os exemplos contrafactuais tenham valores de previsão. Para cenários de classificação binária, o intervalo será automaticamente definido para gerar contrafactuais para a classe oposta de cada ponto de dados. Para cenários de várias classificações, use a lista suspensa para especificar qual classe você deseja que cada ponto de dados seja previsto.
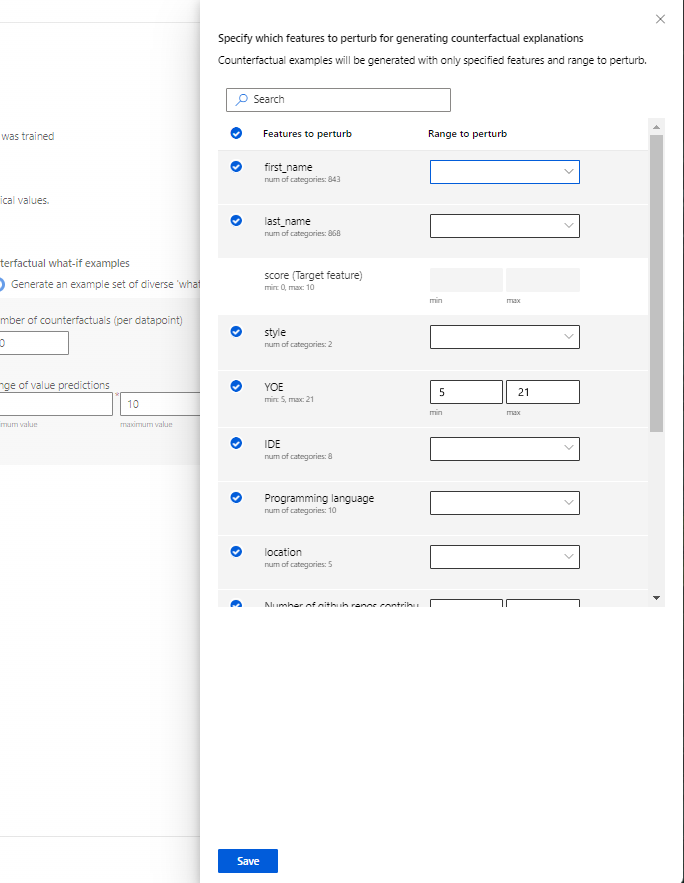
Especifique quais recursos perturbar: Por padrão, todos os recursos serão perturbados. No entanto, se desejar que apenas recursos específicos sejam perturbados, selecione Especificar quais recursos perturbar para gerar explicações contrafactuais para exibir um painel com uma lista de recursos a serem selecionados.
Ao selecionar Especificar quais recursos perturbar, você pode especificar o intervalo no qual deseja permitir perturbações. Por exemplo: para o recurso YOE (Anos de experiência), especifique que os cenários em ausência de dados devem ter valores de recurso que variam de apenas 10 a 21, em vez dos valores padrão de 5 a 21.
Gerar explicações: ative e desative para gerar um componente de explicação de modelo para seu painel de IA responsável. Nenhuma configuração é necessária, porque uma caixa opaca padrão imita o explicador será usada para gerar importâncias de recursos.

Como alternativa, se você selecionar o perfil de intervenções da vida real, verá a tela a seguir gerar uma análise causal. Isso irá ajudá-lo a entender os efeitos causais dos recursos que você deseja "tratar" em um determinado resultado que deseja otimizar.

Os parâmetros dos componentes para intervenções da vida real utilizam a análise causal. Efetue o seguinte procedimento:
- Característica alvo (obrigatório): Escolha o resultado para o qual deseja que os efeitos causais sejam calculados.
- Recursos de tratamento (obrigatório): escolha um ou mais recursos que você está interessado em alterar ("tratar") para otimizar o resultado desejado.
- Recursos categóricos: indique quais recursos são categóricos para renderizá-los corretamente como valores categóricos na interface do usuário do painel. Este campo é pré-carregado para você com base nos metadados do conjunto de dados.
- Configurações avançadas: especifique parâmetros adicionais para sua análise causal, como características heterogêneas (ou seja, recursos adicionais para entender a segmentação causal em sua análise, além de suas características de tratamento) e qual modelo causal você deseja usar.
Configure seu experimento
Por fim, configure seu experimento para iniciar um trabalho para gerar seu painel de IA responsável.

No painel de configuração Trabalho de treinamento ou Experimento, faça o seguinte:
- Nome: dê ao seu painel um nome exclusivo para que você possa diferenciá-lo quando estiver visualizando a lista de painéis de um determinado modelo.
- Nome do experimento: selecione um experimento existente para executar o trabalho ou crie um novo experimento.
- Experiência existente: na lista suspensa, selecione uma experiência existente.
- Selecionar tipo de computação: especifique qual tipo de computação você deseja usar para executar seu trabalho.
- Selecionar computação: na lista suspensa, selecione a computação que deseja usar. Se não houver recursos de computação existentes, selecione o sinal de adição (+), crie um novo recurso de computação e atualize a lista.
- Descrição: adicione uma descrição mais longa do seu painel de IA responsável.
- Tags: Adicione quaisquer tags a este painel de IA responsável.
Depois de concluir a configuração do experimento, selecione Criar para começar a gerar seu painel de IA responsável. Você será redirecionado para a página do experimento para acompanhar o progresso do seu trabalho com um link para o painel de IA responsável resultante da página do trabalho quando ele for concluído.
Para saber como exibir e usar seu painel de IA Responsável, consulte Usar o painel de IA Responsável no estúdio de Aprendizado de Máquina do Azure.
Como gerar scorecard de IA Responsável (visualização)
Depois de criar um painel, você pode usar uma interface do usuário sem código no estúdio do Azure Machine Learning para personalizar e gerar um scorecard de IA responsável. Isso permite que você compartilhe informações importantes para a implantação responsável do seu modelo, como equidade e importância de recursos, com partes interessadas técnicas e não técnicas. Semelhante à criação de um painel, você pode usar as seguintes etapas para acessar o assistente de geração de scorecard:
- Navegue até a guia Modelos na barra de navegação esquerda no estúdio do Azure Machine Learning.
- Selecione o modelo registrado para o qual você gostaria de criar um scorecard e selecione a guia IA responsável.
- No painel superior, selecione Criar insights de IA responsável (visualização) e, em seguida , Gerar novo scorecard PDF.
O assistente permitirá que você personalize seu scorecard PDF sem ter que tocar no código. A experiência ocorre inteiramente no estúdio do Azure Machine Learning para ajudar a contextualizar a variedade de opções da interface do usuário com um fluxo guiado e texto instrucional para ajudá-lo a escolher os componentes com os quais deseja preencher seu scorecard. O assistente é dividido em sete etapas, com uma oitava etapa (avaliação de equidade) que só aparecerá para modelos com características categóricas:
- Resumo do scorecard PDF
- Desempenho do modelo
- Seleção de ferramentas
- Análise de dados (anteriormente chamada de explorador de dados)
- Análise causal
- Capacidade de interpretação
- Configuração do experimento
- Avaliação da equidade (apenas se existirem características categóricas)
Configurando seu scorecard
Primeiro, insira um título descritivo para o seu scorecard. Você também pode inserir uma descrição opcional sobre a funcionalidade do modelo, os dados em que ele foi treinado e avaliado, o tipo de arquitetura e muito mais.

A seção Desempenho do modelo permite que você incorpore ao seu scorecard métricas de avaliação de modelo padrão do setor, ao mesmo tempo em que permite definir os valores-alvo desejados para as métricas selecionadas. Selecione as métricas de desempenho desejadas (até três) e os valores-alvo usando os menus suspensos.

A etapa de seleção de ferramentas permite que você escolha quais componentes subsequentes você gostaria de incluir em seu scorecard. Marque Incluir no scorecard para incluir todos os componentes ou marque/desmarque cada componente individualmente. Selecione o ícone de informações ("i" em um círculo) ao lado dos componentes para saber mais sobre eles.

A seção Análise de dados (anteriormente chamada de explorador de dados) permite a análise de coorte. Aqui, você pode identificar problemas de sobre-representação e sub-representação, explorar como os dados são agrupados no conjunto de dados e como as previsões de modelo afetam coortes de dados específicas. Use caixas de seleção na lista suspensa para selecionar seus recursos de interesse abaixo para identificar o desempenho do seu modelo em suas coortes subjacentes.

A seção Avaliação de equidade pode ajudar a avaliar quais grupos de pessoas podem ser afetados negativamente pelas previsões de um modelo de aprendizado de máquina. Há dois campos nesta seção.
Recursos sensíveis: identifique o(s) atributo(s) sensível(s) de escolha (por exemplo, idade, sexo) priorizando até 20 subgrupos que você gostaria de explorar e comparar.
Métrica de equidade: selecione uma métrica de equidade apropriada para sua configuração (por exemplo, diferença na precisão, taxa de erro) e identifique o(s) valor(es) desejado(s) de destino na(s) métrica(s) de equidade selecionada(s). Sua métrica de equidade selecionada (emparelhada com sua seleção de diferença ou proporção por meio da alternância) capturará a diferença ou proporção entre os valores extremos entre os subgrupos. (max - min ou max/min).

Nota
Atualmente, a avaliação da equidade só está disponível para atributos sensíveis categóricos, como o género.
A seção Análise causal responde a perguntas do mundo real sobre como as mudanças de tratamentos afetariam um resultado no mundo real. Se o componente causal for ativado no painel de IA responsável para o qual você está gerando um scorecard, não será necessária mais configuração.

A seção Interpretabilidade gera descrições compreensíveis por humanos para previsões feitas pelo seu modelo de aprendizado de máquina. Usando explicações de modelo, você pode entender o raciocínio por trás das decisões tomadas pelo seu modelo. Selecione um número (K) abaixo para ver os principais recursos K importantes que afetam suas previsões gerais do modelo. O valor padrão para K é 10.

Por fim, configure seu experimento para iniciar um trabalho para gerar seu scorecard. Essas configurações são as mesmas do seu painel de IA responsável.
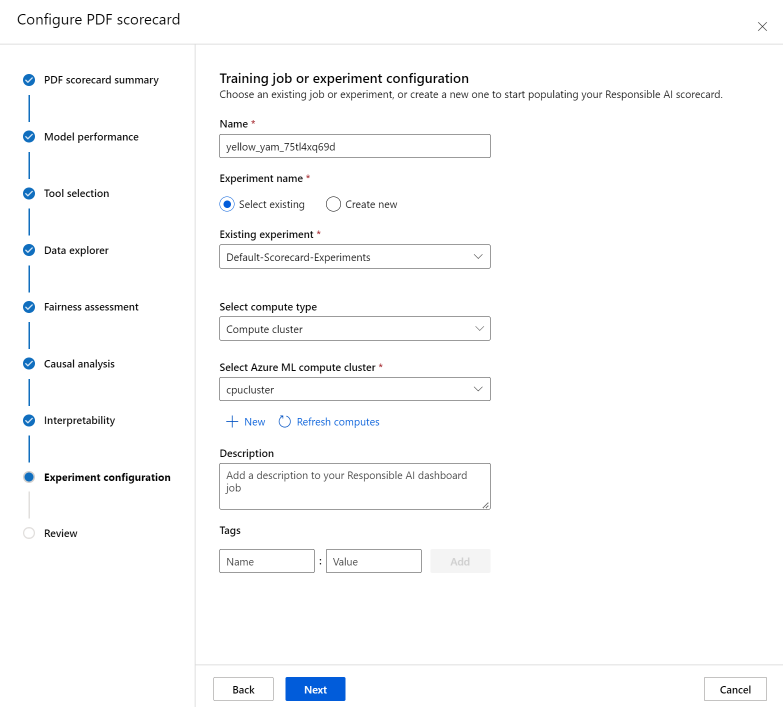
Por fim, reveja as suas configurações e selecione Criar para iniciar o seu trabalho!
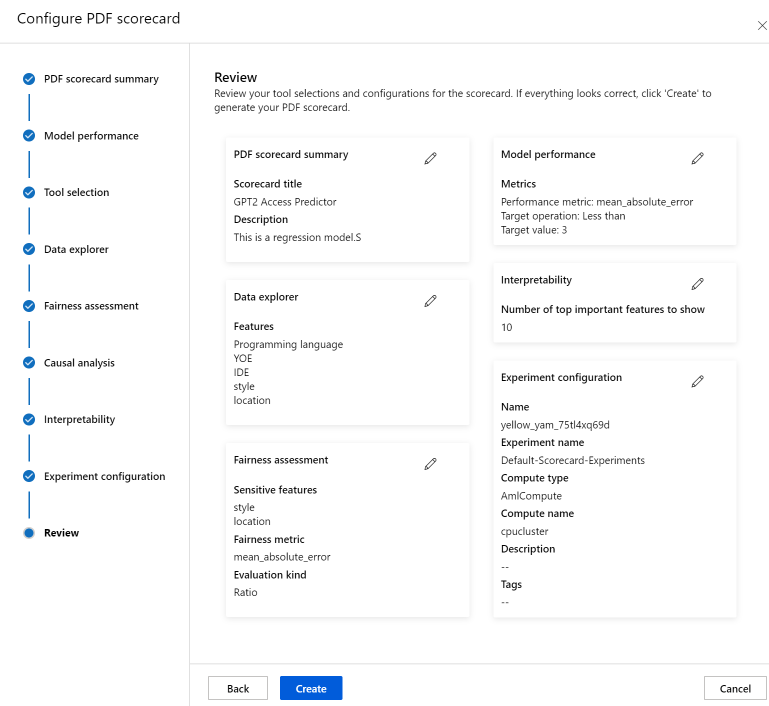
Você será redirecionado para a página do experimento para acompanhar o progresso do seu trabalho depois de iniciá-lo. Para saber como visualizar e usar seu scorecard de IA responsável, consulte Usar scorecard de IA responsável (visualização).









Próximos passos
- Depois de gerar seu painel de IA responsável, veja como acessá-lo e usá-lo no estúdio do Azure Machine Learning.
- Saiba mais sobre os conceitos e técnicas por trás do painel de IA responsável.
- Saiba mais sobre como recolher dados de forma responsável.
- Saiba mais sobre como usar o painel e o scorecard da IA Responsável para depurar dados e modelos e informar uma melhor tomada de decisão nesta postagem do blog da comunidade de tecnologia.
- Saiba mais sobre como o painel e o scorecard da IA Responsável foram usados pelo Serviço Nacional de Saúde do Reino Unido (NHS) em uma história de cliente da vida real.
- Explore os recursos do painel de IA Responsável por meio desta demonstração interativa da web do AI Lab.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários