Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O painel de IA Responsável (RAI) reúne várias ferramentas RAI em uma única interface para ajudar a informar decisões baseadas em dados sobre seus modelos. Compreender modelos de processamento de linguagem natural (NLP) pode ser diferente de avaliar dados tabulares. A depuração e as visualizações do painel RAI agora suportam dados de texto.
O painel de texto de IA responsável é uma caixa de ferramentas personalizável e interoperável onde você pode selecionar componentes para executar a avaliação e depuração do modelo. Este artigo descreve como acessar e configurar os componentes e a funcionalidade do painel de texto RAI.
Importante
O painel de texto da IA responsável está atualmente em pré-visualização pública. Essa visualização é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas. Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Pré-requisitos
Uma assinatura do Azure com um espaço de trabalho do Azure Machine Learning.
Um modelo de aprendizado de máquina registrado que tem um painel de texto de IA responsável criado.
Você pode criar um painel de texto RAI usando:
- A interface do usuário do estúdio do Azure Machine Learning
- YAML e Python através de um trabalho de pipeline
- Um notebook Jupyter de amostra pré-configurado como Financial_News_Text_classifier.ipynb
Para abrir o painel de texto IA Responsável no estúdio de Aprendizado de Máquina, selecione seu modelo registrado na lista Modelos , selecione IA Responsável na parte superior da página do modelo e selecione o nome do painel de texto IA Responsável na lista.
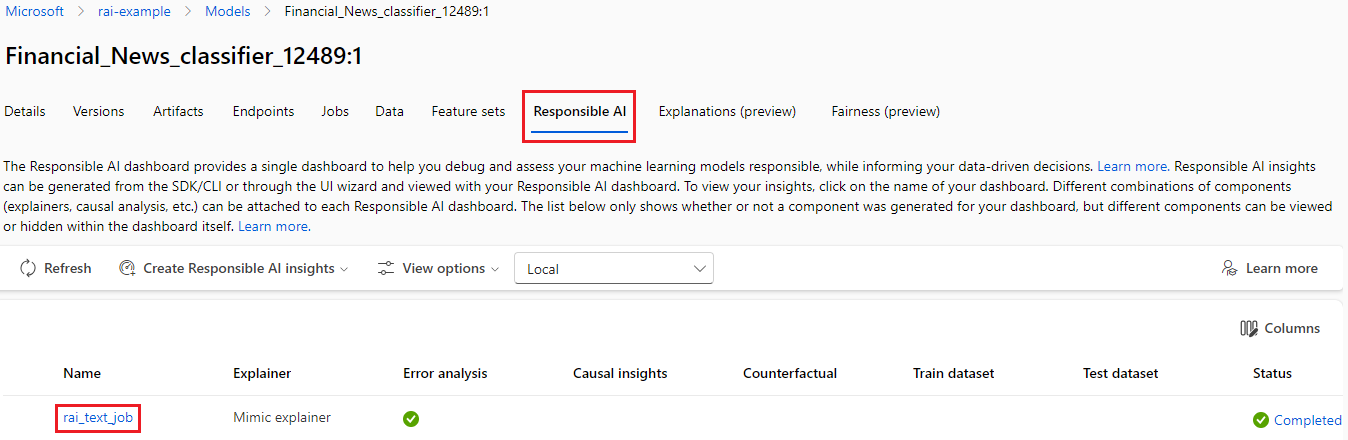
O painel de texto da IA responsável é aberto.
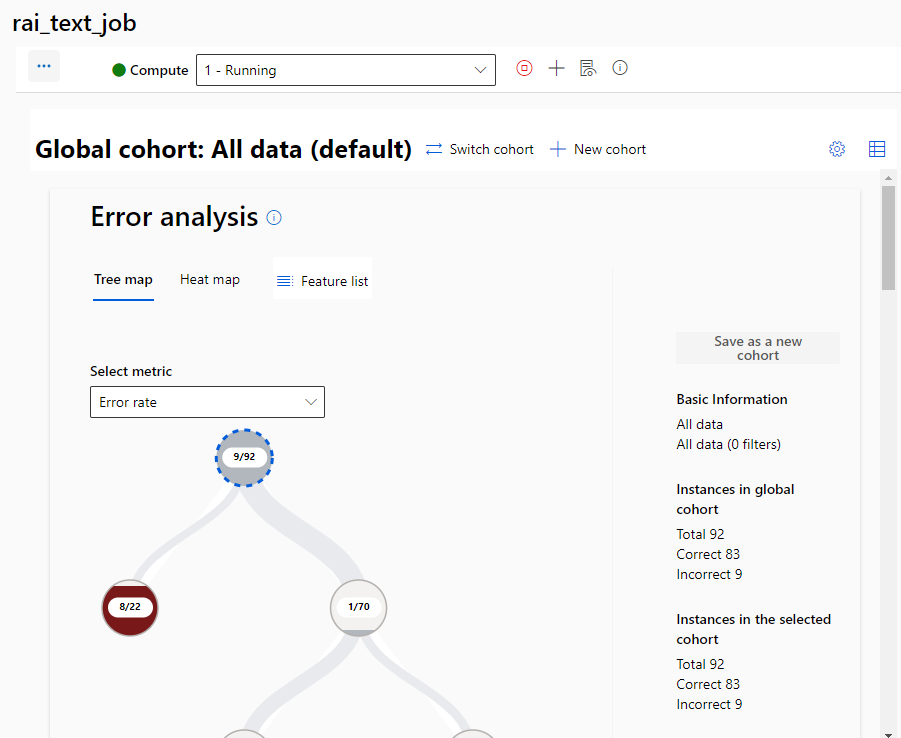


Coortes
No painel de texto RAI, você pode selecionar ou criar coortes de dados , que são subconjuntos de dados criados adicionando filtros manualmente ou salvando dados selecionados. Você pode visualizar, criar, editar, duplicar e excluir coortes.
A exibição de painel padrão mostra a coorte Global, que é todos os dados. Na parte superior do painel, selecione Alternar coorte para selecionar uma coorte diferente ou Nova coorte para criar uma nova coorte . Você também pode selecionar o ícone Configurações para abrir um painel lateral que lista os nomes e detalhes de todas as coortes e permite alternar ou criar novas coortes.

Selecionar Coorte de coorte na parte superior do painel ou na barra lateral Configurações de coorte abre um pop-up que permite selecionar e aplicar uma coorte diferente ao painel.

Selecionar Criar nova coorte na parte superior do painel ou na barra lateral Configurações de coorte abre uma barra lateral que permite criar uma nova coorte.

Para criar uma nova coorte:
Em Nome da coorte do conjunto de dados, insira um nome para a coorte.
Em Selecionar filtro, selecione um dos seguintes filtros de dados e configure os valores Incluídos.
- Filtros de índice pela posição do ponto de dados no conjunto de dados completo. Você pode selecionar uma Operação como Menos que e, em seguida, selecionar um Valor, ou pode selecionar a caixa de seleção Tratar como categórica e, em seguida, selecionar Valores incluídos.
- O conjunto de dados filtra pelo valor de um recurso específico no conjunto de dados. Em Selecionar filtro, selecione um recurso como positive_words. Em seguida, você pode selecionar uma Operação como Menos que e selecionar um Valor, ou pode selecionar a caixa de seleção Tratar como categórica e, em seguida, selecionar Valores incluídos.
- Filtros Y previstos pela previsão feita pelo modelo.
- True Y filtra pelo valor real do recurso de destino.
- O resultado da classificação filtra os problemas de classificação por tipo e precisão da classificação.
Depois de selecionar e configurar o filtro, selecione Adicionar filtro. Você pode adicionar vários filtros para definir a coorte.
Quando terminar de adicionar filtros, selecione Salvar ou Salvar e alterne para concluir a criação do grupo.
Componentes do painel de texto RAI
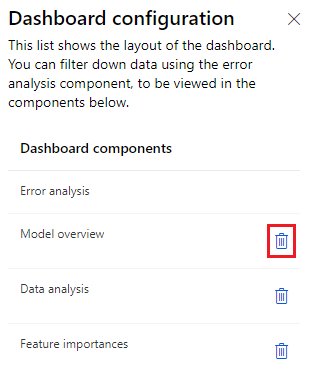
O painel de texto RAI padrão inclui análise de erros, visão geral do modelo, análise de dados e componentes de importância do recurso. Para visualizar e selecionar na lista de componentes, selecione o ícone de configuração do painel no canto superior direito.
Selecionar o ícone abre um painel lateral mostrando detalhes do layout do painel. Você pode selecionar o ícone de lata de lixo ao lado de um componente para remover o componente do painel.
As seções a seguir descrevem os componentes do painel de texto da IA responsável e suas funcionalidades.
Análise de erros
O componente Análise de erros ajuda a analisar padrões de falha em seu modelo. Você pode selecionar uma métrica na lista suspensa Selecionar métrica para saber mais sobre o desempenho dos nós de erro e sucesso. A métrica padrão é Taxa de erro. A seleção de métricas não afeta a forma como a árvore de erros é gerada.

O lado direito da tela Análise de erros mostra informações sobre o conjunto de dados, a coorte selecionada atual e os filtros aplicados.
- Informações básicas mostra o nome e os filtros aplicados para a coorte selecionada atual.
- As instâncias na coorte global exibem o número total de pontos e o número de pontos previstos correta e incorretamente em todo o conjunto de dados.
- As instâncias na coorte selecionada exibem o número total de pontos e o número de pontos previstos correta e incorretamente na coorte selecionada no momento.
- O caminho de previsão (filtros) lista os filtros aplicados ao conjunto de dados completo para criar a coorte selecionada no momento.
Se alterar uma vista aplicando filtros ou selecionando funcionalidades diferentes, pode guardar a vista como uma nova coorte selecionando Guardar como uma nova coorte.
Você pode visualizar o componente de análise de erros nas visualizações Mapa de árvore ou Mapa de calor selecionando uma guia na parte superior do componente.
Visualização do mapa em árvore
A visualização Mapa em árvore ilustra como a falha do modelo é distribuída entre diferentes coortes de recursos. Para dados de texto, a exibição em árvore é treinada em recursos tabulares extraídos de dados de texto e em quaisquer recursos de metadados adicionados que os usuários trouxerem.
A visualização em árvore usa as informações mútuas entre cada recurso e o erro para separar instâncias de erro de instâncias de sucesso hierarquicamente nos dados. Essa visualização simplifica o processo de descobrir e destacar padrões de falha comuns.

Na visualização em árvore, cada círculo ou nó representa uma coorte de conjunto de dados, potencialmente com filtros aplicados. Os números em cada nó mostram o número de erros em comparação com o número total de pontos de dados nesse nó.
Você pode passar o mouse sobre ou selecionar um nó para exibir a cobertura de erro ou a porcentagem de erros no conjunto de dados que estão nesse nó e a taxa de erro ou a porcentagem de falha dos pontos de dados no nó. Níveis mais altos de preenchimento de nó indicam maior cobertura de erros e cores de plano de fundo mais escuras indicam taxas de erro mais altas. Os nós selecionados têm um contorno pesado.
As linhas de preenchimento entre nós visualizam a distribuição de pontos de dados em coortes filhas com base em filtros, com o número de pontos de dados representado pela espessura da linha. Você pode passar o mouse sobre ou selecionar uma linha de preenchimento para exibir o recurso e a previsão que estão sendo aplicados.
Para encontrar padrões de falha importantes, procure nós com cores mais escuras indicando uma taxa de erro mais alta e linhas de preenchimento mais espessas indicando maior cobertura de erros.
Para editar a lista de recursos que a árvore usa para treinar o mapa da árvore, selecione Lista de recursos na parte superior da exibição.

No painel Lista de recursos, Recursos lista os nomes dos recursos no conjunto de dados. Você pode pesquisar para encontrar recursos específicos. Importâncias visualiza a importância relativa de cada recurso no conjunto de dados. Você pode marcar ou desmarcar as caixas de seleção ao lado de cada recurso para adicionar ou remover o recurso do mapa de árvore.
Você também pode definir as seguintes configurações:
- A profundidade máxima define a profundidade máxima da árvore.
- Número de folhas define o número de folhas na árvore.
- O número mínimo de amostras numa folha define o número mínimo de amostras necessário para criar uma folha.
Depois de fazer alterações no painel Lista de recursos , selecione Aplicar para aplicar as alterações ao modo de exibição atual.
Visualização do mapa de calor
Você pode usar a visualização Mapa de calor para se concentrar em filtros de recursos interseccionais específicos e calcular taxas de erro desagregadas. Comece comparando dois recursos de conjunto de dados com o cluster e filtre seus dados em duas dimensões. Você pode selecionar uma ou várias células de mapa de calor e criar novas coortes.

Na vista Mapa de calor :
- Células exibe o número de células selecionadas. Se nenhuma célula for selecionada, o modo de exibição mostrará os dados de todas as células.
- A cobertura de erros exibe a porcentagem de erros no conjunto de dados que estão nas células selecionadas.
- A taxa de erro exibe a porcentagem de falha dos pontos de dados nas células selecionadas.
Para configurar a vista:
- Em Selecionar métrica, selecione a métrica que deseja visualizar na lista suspensa.
- Em Linhas: Recurso 1 e Colunas: Recurso 2, selecione os recursos que deseja comparar nas listas suspensas.
- Opcionalmente, habilite o Quantile binning para distribuir valores uniformemente em vários intervalos de compartimentos.
- Defina o limite de vinculação para configurar o número de valores necessários antes da vinculação.
As células representam coortes do conjunto de dados, com filtros aplicados. Cada célula mostra a percentagem de erros do número total de pontos de dados na coorte.
As células selecionadas são delineadas e a escuridão da cor da célula representa a concentração de falhas. Passe o cursor sobre uma célula para exibir o número correto, o número incorreto, a cobertura de erros e a taxa de erro dessa célula.
Descrição geral do modelo
O componente Visão geral do modelo exibe estatísticas de modelo e conjunto de dados calculadas para coortes em todo o conjunto de dados.

Você pode escolher entre coortes de conjunto de dados ou coortes de recursos selecionando uma guia na parte superior do componente. Para qualquer visualização, selecione Métrica(s) na lista suspensa ou selecione Ajude-me a escolher métricas para abrir uma tela lateral que explica, recomenda e permite selecionar métricas para exibição.
Você também pode ativar Mostrar heatmaps para qualquer visualização.
Coortes de conjuntos de dados
As coortes do conjunto de dados exibem as métricas selecionadas na coorte global e todas as coortes definidas pelo usuário no painel.

Coortes de recursos
Coortes de recursos exibe as métricas selecionadas para coortes baseadas em recursos selecionados. Selecione o (s) recurso(s) para definir as coortes. Essa exibição também mostra métricas de equidade, como paridade de diferença e proporção .

Visualizações de métricas ou matriz de confusão
Na parte inferior do componente, você pode optar por visualizar visualizações de métricas ou uma matriz de confusão. O exemplo a seguir mostra uma matriz de confusão para o modo de exibição Coortes de recursos.

Análise de dados
O componente Análise de dados cria coortes de conjunto de dados para analisar estatísticas de conjuntos de dados ao longo de filtros, como resultados previstos, recursos de conjuntos de dados e grupos de erros. Você pode escolher entre o modo Tabela ou o modo Gráfico selecionando uma guia na parte superior do componente.
Vista de tabela
A vista de tabela mostra os valores verdadeiros e previstos e as características extraídas tabulares.

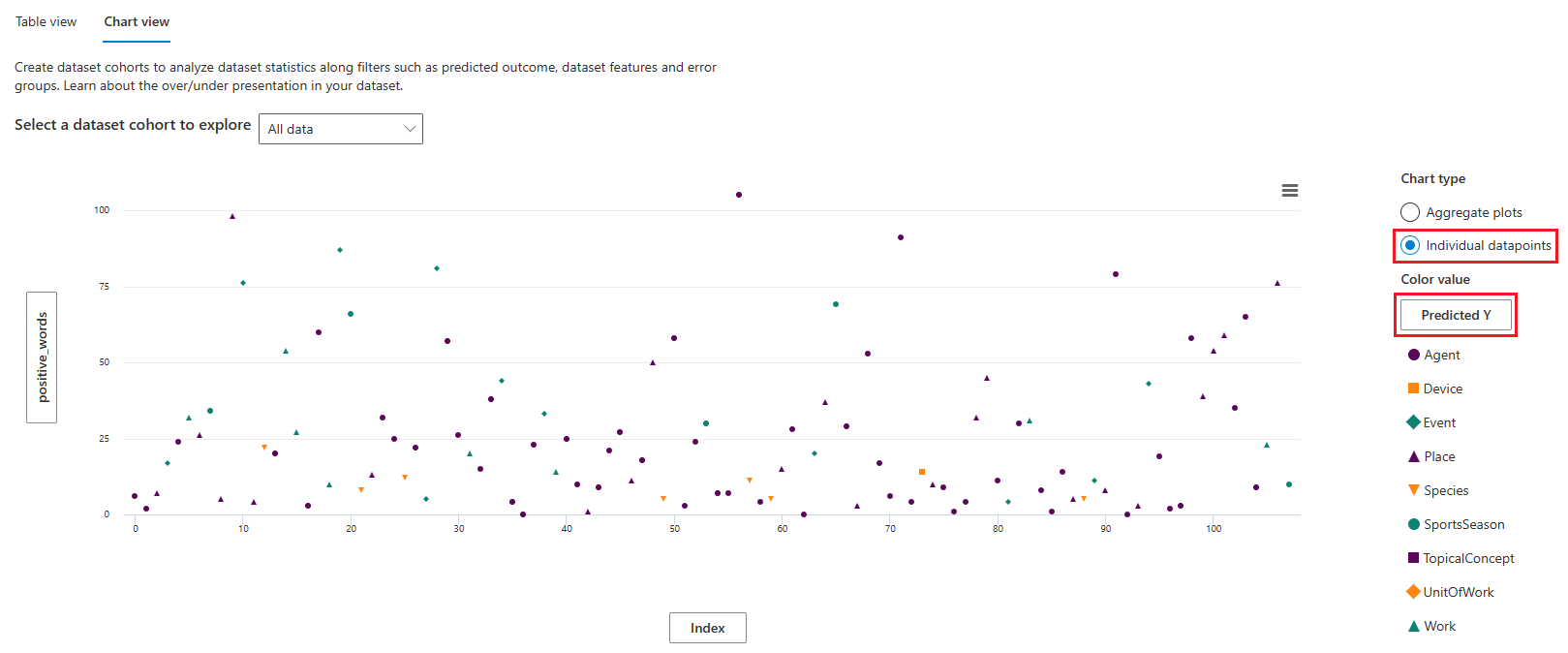
Vista de gráfico
A vista de gráfico permite-lhe escolher entre agregação personalizada e exploração de dados locais.

Na visualização de gráfico, os eixos X e Y mostram os valores que estão sendo plotados horizontal e verticalmente. Você pode selecionar qualquer rótulo para abrir um painel lateral para selecionar e configurar esse eixo.
No painel de configuração do eixo, dependendo do valor, você pode configurar opções como Aplicar binning aos dados, Habilitar dimensionamento logarítmico ou Tratar como categórico. Should dither adiciona ruído opcional aos dados para evitar pontos sobrepostos no gráfico de dispersão.
Em Tipo de gráfico, você pode selecionar se deseja agregar valores em todos os pontos de dados.
O gráfico agregado exibe dados em compartimentos ou categorias ao longo do eixo X.
Pontos de dados individuais exibem uma exibição desagregada dos dados.
Na visualização Pontos de dados individuais, você pode selecionar o tipo de legenda usado para agrupar pontos de dados. Selecionar o rótulo em Valor de cor abre o painel lateral de configuração do eixo.

Importância dos recursos
No componente Importância do recurso, você pode escolher entre Importância do recurso agregado ou Importância do recurso individual selecionando uma guia na parte superior do componente.
Importância agregada do recurso
Em Importância do recurso agregado, você pode explorar os recursos mais importantes que afetam as previsões gerais do modelo, também conhecidas como explicações globais. Use o controle deslizante para selecionar o número de recursos a serem exibidos lado a lado em importância decrescente. Passe o cursor sobre cada recurso para ver seu valor global absoluto.

Importância da característica individual
A seleção da guia Importâncias do recurso individual desloca as exibições para explicar como palavras específicas influenciam as previsões feitas em pontos de dados específicos. Selecione um ponto de dados na tabela para exibir os valores de importância do recurso local, ou explicações locais, no explicador de texto Shapley Additive explanations (SHAP).

No gráfico de explicação local, você pode configurar:
- Mostrar as palavras mais importantes para selecionar o número de palavras mais importantes a realçar no texto.
- Pesos de importância de classe para selecionar a classe ou uma exibição agregada das principais palavras mais importantes.

Conteúdos relacionados
- Saiba mais sobre os conceitos e técnicas por trás do painel de IA responsável.
- Veja exemplos de notebooks YAML e Python para gerar painéis de IA responsável com YAML ou Python.