Usar parâmetros de pipeline para treinar novamente modelos no designer
Neste artigo de instruções, você aprenderá a usar o designer do Azure Machine Learning para treinar novamente um modelo de aprendizado de máquina usando parâmetros de pipeline. Você usará pipelines publicados para automatizar seu fluxo de trabalho e definir parâmetros para treinar seu modelo em novos dados. Os parâmetros de pipeline permitem reutilizar pipelines existentes para trabalhos diferentes.
Neste artigo, vai aprender a:
- Treine um modelo de aprendizado de máquina.
- Crie um parâmetro de pipeline.
- Publique seu pipeline de treinamento.
- Retreine seu modelo com novos parâmetros.
Pré-requisitos
- Uma área de trabalho do Azure Machine Learning
- Conclua a parte 1 desta série de instruções, Transformar dados no designer
Importante
Se você não vir elementos gráficos mencionados neste documento, como botões no estúdio ou designer, talvez não tenha o nível correto de permissões para o espaço de trabalho. Entre em contato com o administrador da assinatura do Azure para verificar se você recebeu o nível correto de acesso. Para obter mais informações, veja Gerir utilizadores e funções.
Este artigo também pressupõe que você tenha algum conhecimento de construção de pipelines no designer. Para uma introdução guiada, conclua o tutorial.
Pipeline de amostra
O pipeline usado neste artigo é uma versão alterada de um pipeline de amostra Previsão de renda na página inicial do designer. O pipeline usa o componente Importar dados em vez do conjunto de dados de exemplo para mostrar como treinar modelos usando seus próprios dados.

Criar um parâmetro de pipeline
Os parâmetros de pipeline são usados para construir pipelines versáteis que podem ser reenviados posteriormente com valores de parâmetros variáveis. Alguns cenários comuns são a atualização de conjuntos de dados ou alguns hiperparâmetros para reciclagem. Crie parâmetros de pipeline para definir dinamicamente variáveis em tempo de execução.
Os parâmetros do pipeline podem ser adicionados à fonte de dados ou aos parâmetros do componente em um pipeline. Quando o pipeline é reenviado, os valores desses parâmetros podem ser especificados.
Neste exemplo, você alterará o caminho de dados de treinamento de um valor fixo para um parâmetro, para que possa treinar novamente seu modelo em dados diferentes. Você também pode adicionar outros parâmetros de componente como parâmetros de pipeline de acordo com seu caso de uso.
Selecione o componente Importar dados .
Nota
Este exemplo usa o componente Import Data para acessar dados em um armazenamento de dados registrado. No entanto, você pode seguir etapas semelhantes se usar padrões alternativos de acesso a dados.
No painel de detalhes do componente, à direita da tela, selecione sua fonte de dados.
Insira o caminho para seus dados. Você também pode selecionar Procurar caminho para navegar na árvore de arquivos.
Passe o mouse sobre o campo Caminho e selecione as reticências acima do campo Caminho que aparecem.
Selecione Adicionar ao parâmetro de pipeline.
Forneça um nome de parâmetro e um valor padrão.
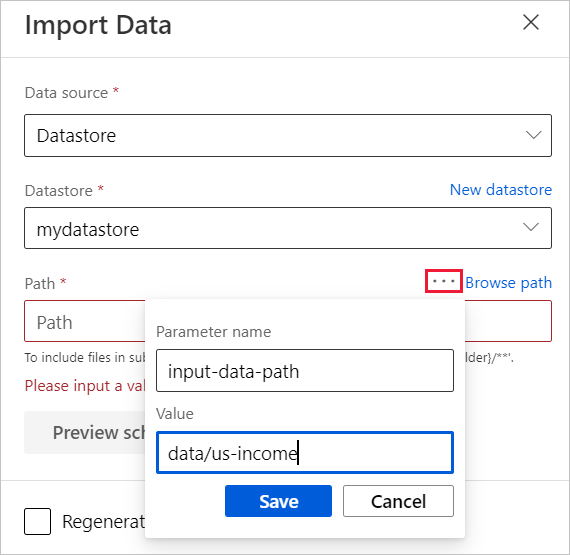
Selecione Guardar.
Nota
Você também pode desanexar um parâmetro de componente do parâmetro de pipeline no painel de detalhes do componente, semelhante à adição de parâmetros de pipeline.
Você pode inspecionar e editar os parâmetros do pipeline selecionando o ícone de engrenagem Configurações ao lado do título do rascunho do pipeline.
- Depois de desanexar, você pode excluir o parâmetro pipeline no painel Configurações .
- Você também pode adicionar um parâmetro de pipeline no painel Configurações e, em seguida, aplicá-lo em algum parâmetro de componente.
Envie o trabalho de pipeline.
Publicar um pipeline de treinamento
Publique um pipeline em um ponto de extremidade de pipeline para reutilizar facilmente seus pipelines no futuro. Um ponto de extremidade de pipeline cria um ponto de extremidade REST para invocar pipeline no futuro. Neste exemplo, o ponto de extremidade do pipeline permite reutilizar o pipeline para treinar novamente um modelo em dados diferentes.
Selecione Publicar acima da tela do designer.
Selecione ou crie um ponto de extremidade de pipeline.
Nota
Pode publicar vários pipelines num único ponto final. Cada pipeline num determinado ponto final recebe um número de versão, que pode especificar quando chamar o ponto final do pipeline.
Selecione Publicar.
Retreine o seu modelo
Agora que você tem um pipeline de treinamento publicado, pode usá-lo para treinar novamente seu modelo em novos dados. Você pode enviar trabalhos de um ponto de extremidade de pipeline a partir do espaço de trabalho do estúdio ou programaticamente.
Enviar trabalhos usando o portal do estúdio
Use as seguintes etapas para enviar um trabalho de ponto de extremidade de pipeline parametrizado a partir do portal do estúdio:
- Vá para a página Pontos de extremidade no espaço de trabalho do estúdio.
- Selecione a guia Pontos de extremidade de pipeline. Em seguida, selecione o ponto de extremidade do pipeline.
- Selecione a guia Pipelines publicados . Em seguida, selecione a versão do pipeline que você deseja executar.
- Selecione Submeter.
- Na caixa de diálogo de configuração, você pode especificar os valores dos parâmetros para o trabalho. Neste exemplo, atualize o caminho de dados para treinar seu modelo usando um conjunto de dados diferente dos EUA.

Enviar trabalhos usando código
Você pode encontrar o ponto de extremidade REST de um pipeline publicado no painel de visão geral. Ao chamar o ponto de extremidade, você pode treinar novamente o pipeline publicado.
Para fazer uma chamada REST, você precisa de um cabeçalho de autenticação do tipo portador OAuth 2.0. Para obter informações sobre como configurar a autenticação em seu espaço de trabalho e fazer uma chamada REST parametrizada, consulte Usar REST para gerenciar recursos.
Próximos passos
Neste artigo, você aprendeu como criar um ponto de extremidade de pipeline de treinamento parametrizado usando o designer.
Para obter um passo a passo completo de como você pode implantar um modelo para fazer previsões, consulte o tutorial do designer para treinar e implantar um modelo de regressão.
Para saber como publicar e enviar um trabalho para o ponto de extremidade de pipeline usando o SDK v1, consulte Publicar pipelines.