Como selecionar algoritmos para o Azure Machine Learning
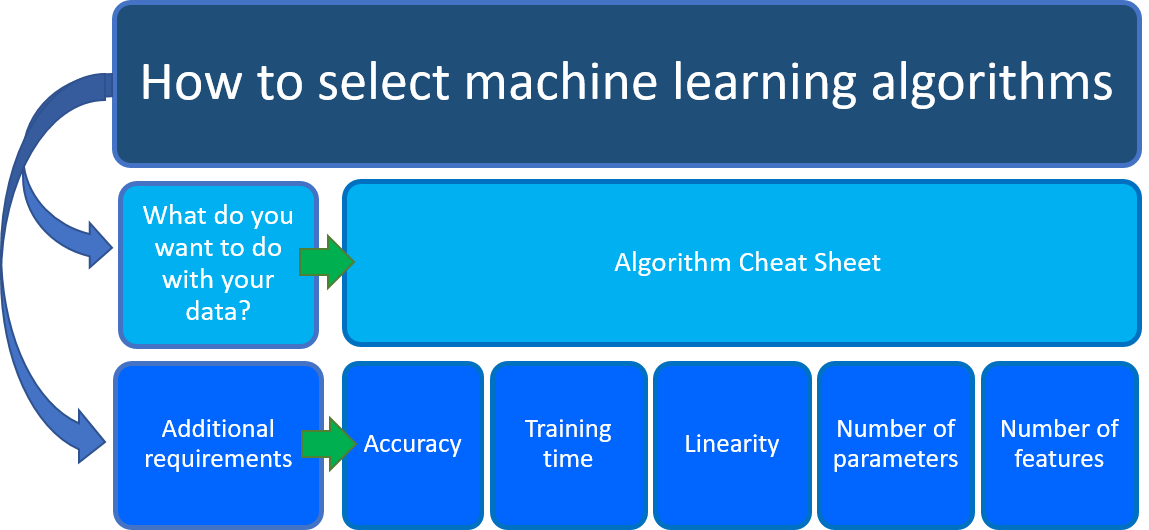
Se você está se perguntando qual algoritmo de aprendizado de máquina usar, a resposta depende principalmente de dois aspetos do seu cenário de ciência de dados:
O que pretende fazer com os seus dados? Especificamente, qual é a pergunta de negócios que você deseja responder aprendendo com seus dados passados?
Quais são os requisitos do seu cenário de ciência de dados? Quais são os recursos, a precisão, o tempo de treinamento, a linearidade e os parâmetros suportados pela sua solução?
Nota
O designer do Azure Machine Learning dá suporte a dois tipos de componentes: componentes pré-criados clássicos (v1) e componentes personalizados (v2). Estes dois tipos de componentes NÃO são compatíveis.
Os componentes pré-construídos clássicos destinam-se principalmente ao processamento de dados e a tarefas tradicionais de aprendizagem automática, como regressão e classificação. Este tipo de componente continua a ser suportado, mas não terá novos componentes adicionados.
Os componentes personalizados permitem que você envolva seu próprio código como um componente. Eles oferecem suporte ao compartilhamento de componentes entre espaços de trabalho e à criação contínua nas interfaces Studio, CLI v2 e SDK v2.
Para novos projetos, recomendamos que você use componentes personalizados, que são compatíveis com o AzureML V2 e continuarão recebendo novas atualizações.
Este artigo se aplica a componentes pré-criados clássicos e não é compatível com CLI v2 e SDK v2.
Azure Machine Learning Algorithm Cheat Sheet
O Azure Machine Learning Algorithm Cheat Sheet ajuda-o com a primeira consideração: O que pretende fazer com os seus dados? No cheat sheet, procure a tarefa que você deseja fazer e, em seguida, encontre um algoritmo de designer do Azure Machine Learning para a solução de análise preditiva.
Nota
Você pode baixar o Machine Learning Algorithm Cheat Sheet.
O designer fornece um portfólio abrangente de algoritmos, como Floresta de Decisão Multiclasse, Sistemas de Recomendação, Regressão de Rede Neural, Rede Neural Multiclasse e Clustering K-Means. Cada algoritmo é projetado para abordar um tipo diferente de problema de aprendizado de máquina. Consulte o algoritmo e a referência de componentes para obter uma lista completa, juntamente com a documentação sobre como cada algoritmo funciona e como ajustar parâmetros para otimizar o algoritmo.
Junto com essa orientação, tenha outros requisitos em mente ao escolher um algoritmo de aprendizado de máquina. Seguem-se fatores adicionais a considerar, tais como a precisão, o tempo de treino, a linearidade, o número de parâmetros e o número de funcionalidades.
Comparação de algoritmos de aprendizagem automática
Alguns algoritmos fazem suposições particulares sobre a estrutura dos dados ou os resultados desejados. Se você puder encontrar um que atenda às suas necessidades, ele pode lhe dar resultados mais úteis, previsões mais precisas ou tempos de treinamento mais rápidos.
A tabela a seguir resume algumas das características mais importantes dos algoritmos das famílias de classificação, regressão e agrupamento:
| Algoritmo | Exatidão | Tempo de treino | Linearidade | Parâmetros | Notas |
|---|---|---|---|---|---|
| Família de classificação | |||||
| Regressão logística de duas classes | Bom | Rápido | Sim | 4 | |
| Floresta de decisão de duas classes | Excelente | Moderado | Não | 5 | Mostra tempos de pontuação mais lentos. Sugerimos não trabalhar com One-vs-All Multiclass, devido aos tempos de pontuação mais lentos causados pelo bloqueio de thread no acúmulo de previsões de árvore |
| Árvore de decisão impulsionada de duas classes | Excelente | Moderado | Não | 6 | Grande espaço ocupado pela memória |
| Rede neural de duas classes | Bom | Moderado | Não | 8 | |
| Perceptron médio de duas classes | Bom | Moderado | Sim | 4 | |
| Máquina vetorial de suporte de duas classes | Bom | Rápido | Sim | 5 | Bom para grandes conjuntos de recursos |
| Regressão logística multiclasse | Bom | Rápido | Sim | 4 | |
| Floresta de decisão multiclasse | Excelente | Moderado | Não | 5 | Mostra tempos de pontuação mais lentos |
| Árvore de decisão impulsionada por várias classes | Excelente | Moderado | Não | 6 | Tende a melhorar a precisão com algum pequeno risco de menos cobertura |
| Rede neural multiclasse | Bom | Moderado | Não | 8 | |
| Multiclasse um-vs-todos | - | - | - | - | Consulte as propriedades do método de duas classes selecionado |
| Família de regressão | |||||
| Regressão linear | Bom | Rápido | Sim | 4 | |
| Regressão florestal de decisão | Excelente | Moderado | Não | 5 | |
| Regressão da árvore de decisão impulsionada | Excelente | Moderado | Não | 6 | Grande espaço ocupado pela memória |
| Regressão de redes neurais | Bom | Moderado | Não | 8 | |
| Família de agrupamento | |||||
| Agrupamento de K-means | Excelente | Moderado | Sim | 8 | Um algoritmo de agrupamento |
Requisitos do cenário de ciência de dados
Depois de saber o que deseja fazer com seus dados, você precisa determinar outros requisitos para seu cenário de ciência de dados.
Faça escolhas e, possivelmente, soluções de compromisso para os seguintes requisitos:
- Precisão
- Tempo de preparação
- Linearidade
- Número de parâmetros
- Número de funcionalidades
Precisão
A precisão no aprendizado de máquina mede a eficácia de um modelo como a proporção de resultados verdadeiros para o total de casos. No designer, o componente Avaliar modelo calcula um conjunto de métricas de avaliação padrão do setor. Você pode usar esse componente para medir a precisão de um modelo treinado.
Nem sempre é necessário obter a resposta mais precisa possível. Às vezes, uma aproximação é adequada, dependendo do que você quer usá-lo para. Se esse for o caso, você poderá reduzir drasticamente seu tempo de processamento aderindo a métodos mais aproximados. Os métodos aproximados também tendem naturalmente a evitar o sobreajuste.
Há três maneiras de usar o componente Avaliar modelo:
- Gere pontuações sobre seus dados de treinamento para avaliar o modelo.
- Gere pontuações no modelo, mas compare essas pontuações com pontuações em um conjunto de testes reservado.
- Compare as pontuações de dois modelos diferentes, mas relacionados, usando o mesmo conjunto de dados.
Para obter uma lista completa de métricas e abordagens que você pode usar para avaliar a precisão dos modelos de aprendizado de máquina, consulte Avaliar componente do modelo.
Tempo de preparação
Na aprendizagem supervisionada, o treinamento significa usar dados históricos para construir um modelo de aprendizado de máquina que minimize os erros. O número de minutos ou horas necessárias para treinar um modelo varia muito entre os algoritmos. O tempo de treino está muitas vezes intimamente ligado à precisão; um normalmente acompanha o outro.
Além disso, alguns algoritmos são mais sensíveis ao número de pontos de dados do que outros. Você pode escolher um algoritmo específico porque tem uma limitação de tempo, especialmente quando o conjunto de dados é grande.
No designer, criar e usar um modelo de aprendizado de máquina normalmente é um processo de três etapas:
Configure um modelo, escolhendo um tipo específico de algoritmo e, em seguida, definindo seus parâmetros ou hiperparâmetros.
Forneça um conjunto de dados rotulado e com dados compatíveis com o algoritmo. Conecte os dados e o modelo ao componente Train Model.
Após a conclusão do treinamento, use o modelo treinado com um dos componentes de pontuação para fazer previsões sobre novos dados.
Linearidade
A linearidade na estatística e no aprendizado de máquina significa que há uma relação linear entre uma variável e uma constante em seu conjunto de dados. Por exemplo, os algoritmos de classificação linear assumem que as classes podem ser separadas por uma linha reta (ou seu análogo de dimensão superior).
Muitos algoritmos de aprendizado de máquina fazem uso da linearidade. No designer do Azure Machine Learning, eles incluem:
Os algoritmos de regressão linear assumem que as tendências dos dados seguem uma linha reta. Essa suposição não é ruim para alguns problemas, mas para outros reduz a precisão. Apesar de suas desvantagens, os algoritmos lineares são populares como uma primeira estratégia. Eles tendem a ser algorítmicos simples e rápidos de treinar.
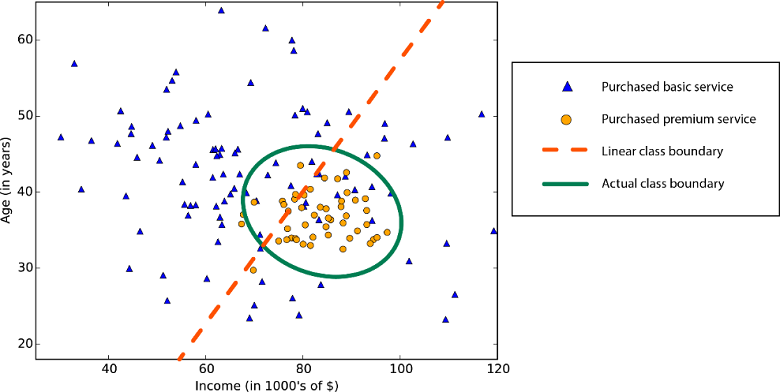
Limite de classe não linear: confiar em um algoritmo de classificação linear resultaria em baixa precisão.
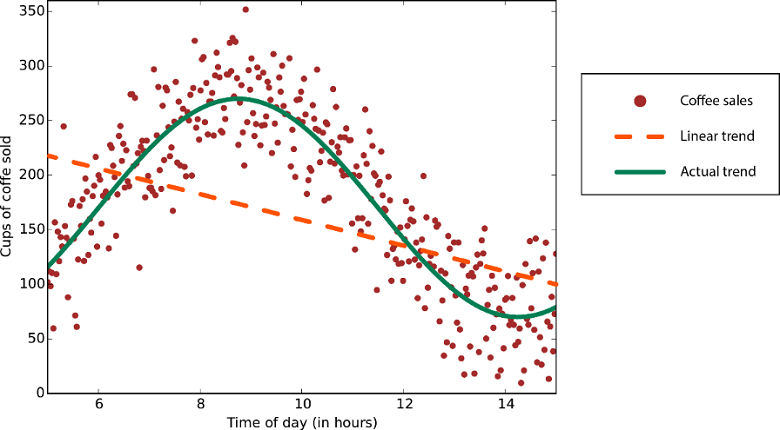
Dados com uma tendência não linear: Usar um método de regressão linear geraria erros muito maiores do que o necessário.
Número de parâmetros
Os parâmetros são os botões que um cientista de dados consegue girar ao configurar um algoritmo. São números que afetam o comportamento do algoritmo, como tolerância a erros ou número de iterações, ou opções entre variantes de como o algoritmo se comporta. O tempo de treinamento e a precisão do algoritmo às vezes podem ser sensíveis para obter apenas as configurações certas. Normalmente, algoritmos com um grande número de parâmetros requerem mais tentativa e erro para encontrar uma boa combinação.
Como alternativa, há o componente Tune Model Hyperparameters no designer. O objetivo deste componente é determinar os hiperparâmetros ideais para um modelo de aprendizado de máquina. O componente cria e testa vários modelos usando diferentes combinações de configurações. Ele compara métricas em todos os modelos para obter as combinações de configurações.
Embora essa seja uma ótima maneira de garantir que você abranja o espaço de parâmetros, o tempo necessário para treinar um modelo aumenta exponencialmente com o número de parâmetros. A vantagem é que ter muitos parâmetros normalmente indica que um algoritmo tem maior flexibilidade. Muitas vezes, pode alcançar uma precisão muito boa, desde que você possa encontrar a combinação certa de configurações de parâmetros.
Número de funcionalidades
No aprendizado de máquina, um recurso é uma variável quantificável do fenômeno que você está tentando analisar. Para certos tipos de dados, o número de recursos pode ser muito grande em comparação com o número de pontos de dados. Este é frequentemente o caso da genética ou dos dados textuais.
Um grande número de recursos pode atrapalhar alguns algoritmos de aprendizagem, tornando o tempo de treinamento inviável longo. As máquinas vetoriais de suporte são adequadas para cenários com um elevado número de funcionalidades. Por esta razão, eles têm sido usados em muitas aplicações, desde a recuperação de informações até a classificação de texto e imagem. Máquinas vetoriais de suporte podem ser usadas para tarefas de classificação e regressão.
A seleção de recursos refere-se ao processo de aplicação de testes estatísticos às entradas, dada uma saída especificada. O objetivo é determinar quais colunas são mais preditivas da saída. O componente Seleção de recursos baseada em filtro no designer fornece vários algoritmos de seleção de recursos para escolher. O componente inclui métodos de correlação como correlação de Pearson e valores qui-quadrado.
Você também pode usar o componente Importância do recurso de permutação para calcular um conjunto de pontuações de importância do recurso para seu conjunto de dados. Em seguida, você pode usar essas pontuações para ajudá-lo a determinar os melhores recursos a serem usados em um modelo.