Partilhe modelos, componentes e ambientes entre espaços de trabalho com registos
O registo do Azure Machine Learning permite-lhe colaborar entre espaços de trabalho dentro da sua organização. Usando registros, você pode compartilhar modelos, componentes e ambientes.
Há dois cenários em que você gostaria de usar o mesmo conjunto de modelos, componentes e ambientes em vários espaços de trabalho:
- MLOps entre espaços de trabalho: você está treinando um modelo em um
devespaço de trabalho e precisa implantá-lo emtestespaçosprodde trabalho. Nesse caso, você deseja ter uma linhagem de ponta a ponta entre os pontos de extremidade nos quais o modelo é implantado outestprodespaços de trabalho e o trabalho de treinamento, métricas, código, dados e ambiente que foi usado para treinar o modelo nodevespaço de trabalho. - Compartilhe e reutilize modelos e pipelines em diferentes equipes: compartilhar e reutilizar melhora a colaboração e a produtividade. Nesse cenário, talvez você queira publicar um modelo treinado e os componentes e ambientes associados usados para treiná-lo para um catálogo central. A partir daí, colegas de outras equipes podem pesquisar e reutilizar os recursos que você compartilhou em seus próprios experimentos.
Neste artigo, vai aprender a:
- Crie um ambiente e um componente no Registro.
- Use o componente do Registro para enviar um trabalho de treinamento modelo em um espaço de trabalho.
- Registre o modelo treinado no registro.
- Implante o modelo do Registro em um ponto de extremidade online no espaço de trabalho e, em seguida, envie uma solicitação de inferência.
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
- Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Um registro do Azure Machine Learning para compartilhar modelos, componentes e ambientes. Para criar um registo, consulte Saiba como criar um registo.
Uma área de trabalho do Azure Machine Learning. Se você não tiver um, use as etapas no artigo Guia de início rápido: criar recursos do espaço de trabalho para criar um.
Importante
A região do Azure (local) onde você cria seu espaço de trabalho deve estar na lista de regiões com suporte para o registro do Azure Machine Learning
A CLI do Azure e a
mlextensão ou o SDK do Python do Azure Machine Learning v2:Para instalar a CLI e a extensão do Azure, consulte Instalar, configurar e usar a CLI (v2).
Importante
Os exemplos de CLI neste artigo pressupõem que você esteja usando o shell Bash (ou compatível). Por exemplo, de um sistema Linux ou Subsistema Windows para Linux.
Os exemplos também pressupõem que você tenha configurado padrões para a CLI do Azure para que não seja necessário especificar os parâmetros para sua assinatura, espaço de trabalho, grupo de recursos ou local. Para definir as configurações padrão, use os seguintes comandos. Substitua os seguintes parâmetros pelos valores para sua configuração:
- Substitua
<subscription>pelo seu ID da subscrição do Azure. - Substitua
<workspace>pelo nome do espaço de trabalho do Azure Machine Learning. - Substitua
<resource-group>pelo grupo de recursos do Azure que contém seu espaço de trabalho. - Substitua
<location>pela região do Azure que contém seu espaço de trabalho.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Você pode ver quais são seus padrões atuais usando o
az configure -lcomando.- Substitua
Repositório de exemplos de clonagem
Os exemplos de código neste artigo são baseados no nyc_taxi_data_regression exemplo no repositório de exemplos. Para usar esses arquivos em seu ambiente de desenvolvimento, use os seguintes comandos para clonar o repositório e alterar diretórios para o exemplo:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
Para o exemplo da CLI, altere os diretórios para cli/jobs/pipelines-with-components/nyc_taxi_data_regression no clone local do repositório de exemplos.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Criar conexão SDK
Gorjeta
Esta etapa só é necessária ao usar o Python SDK.
Crie uma conexão de cliente com o espaço de trabalho e o Registro do Azure Machine Learning:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Criar ambiente no registo
Os ambientes definem o contêiner docker e as dependências Python necessárias para executar trabalhos de treinamento ou implantar modelos. Para obter mais informações sobre ambientes, consulte os seguintes artigos:
Gorjeta
O mesmo comando az ml environment create CLI pode ser usado para criar ambientes em um espaço de trabalho ou registro. Executar o comando com --workspace-name comando cria o ambiente em um espaço de trabalho, enquanto executar o comando com --registry-name cria o ambiente no registro.
Criaremos um ambiente que usa a imagem docker python:3.8 e instala os pacotes Python necessários para executar um trabalho de treinamento usando a estrutura do SciKit Learn. Se você clonou o repositório de exemplos e está na pasta cli/jobs/pipelines-with-components/nyc_taxi_data_regression, você deve ser capaz de ver o arquivo env_train.yml de definição de ambiente que faz referência ao arquivo env_train/Dockerfiledocker . O env_train.yml é mostrado abaixo para sua referência:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Crie o ambiente usando o az ml environment create seguinte
az ml environment create --file env_train.yml --registry-name <registry-name>
Se você receber um erro informando que um ambiente com esse nome e versão já existe no Registro, poderá editar o version campo ou env_train.yml especificar uma versão diferente na CLI que substitua o valor da versão em env_train.yml.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Gorjeta
version=$(date +%s) funciona apenas em Linux. Substitua $version por um número aleatório se isso não funcionar.
Anote o name e version do ambiente a partir da saída do az ml environment create comando e use-os com az ml environment show comandos da seguinte forma. Você precisará do name e version na próxima seção quando criar um componente no Registro.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Gorjeta
Se você usou um nome ou versão de ambiente diferente, substitua os --name parâmetros e --version de acordo.
Você também pode usar az ml environment list --registry-name <registry-name> para listar todos os ambientes no registro.
Você pode navegar em todos os ambientes no estúdio do Azure Machine Learning. Certifique-se de navegar até a interface do usuário global e procure a entrada Registros .

Criar um componente no Registro
Os componentes são blocos de construção reutilizáveis de pipelines de Aprendizado de Máquina no Aprendizado de Máquina do Azure. Você pode empacotar o código, comando, ambiente, interface de entrada e interface de saída de uma etapa de pipeline individual em um componente. Em seguida, você pode reutilizar o componente em vários pipelines sem ter que se preocupar com a portabilidade de dependências e código cada vez que escrever um pipeline diferente.
Criar um componente em um espaço de trabalho permite que você use o componente em qualquer trabalho de pipeline dentro desse espaço de trabalho. Criar um componente em um registro permite que você use o componente em qualquer pipeline em qualquer espaço de trabalho dentro da sua organização. Criar componentes em um registro é uma ótima maneira de criar utilitários modulares reutilizáveis ou tarefas de treinamento compartilhadas que podem ser usadas para experimentação por diferentes equipes dentro da sua organização.
Para obter mais informações sobre componentes, consulte os seguintes artigos:
Como usar componentes em pipelines (SDK)
Importante
O Registro suporta apenas ter ativos nomeados (dados/modelo/componente/ambiente). Se você fizer referência a um ativo em um registro, precisará criá-lo primeiro no registro. Especialmente para o caso do componente de pipeline, se você quiser componente de referência ou ambiente no componente de pipeline, você precisa primeiro criar o componente ou ambiente no registro.
Certifique-se de que está na pasta cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Você encontrará o arquivo train.yml de definição de componente que empacota um script train_src/train.py de treinamento do Scikit Learn e o ambiente AzureML-sklearn-0.24-ubuntu18.04-py37-cpucom curadoria. Usaremos o ambiente Scikit Learn criado em uma etapa anterior em vez do ambiente com curadoria. Você pode editar environment o campo para train.yml se referir ao seu ambiente Scikit Learn. O arquivo de train.yml definição de componente resultante será semelhante ao exemplo a seguir:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Se você usou um nome ou versão diferente, a representação mais genérica terá esta aparência: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, portanto, certifique-se de substituir o <registry-name>, <sklearn-environment-name> e <sklearn-environment-version> de acordo. Em seguida, execute o az ml component create comando para criar o componente da seguinte maneira.
az ml component create --file train.yml --registry-name <registry-name>
Gorjeta
O mesmo comando az ml component create CLI pode ser usado para criar componentes em um espaço de trabalho ou registro. Executar o comando com --workspace-name comando cria o componente em um espaço de trabalho, enquanto executar o comando com --registry-name cria o componente no registro.
Se preferir não editar o train.yml, você pode substituir o nome do ambiente na CLI da seguinte maneira:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Gorjeta
Se você receber um erro informando que o nome do componente já existe no Registro, poderá editar a versão ou train.yml substituir a versão na CLI por uma versão aleatória.
Anote o name e version do componente a partir da saída do az ml component create comando e use-os com az ml component show comandos da seguinte maneira. Você precisará do name e version na próxima seção quando criar enviar um trabalho de treinamento no espaço de trabalho.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
Você também pode usar az ml component list --registry-name <registry-name> para listar todos os componentes no registro.
Você pode procurar todos os componentes no estúdio do Azure Machine Learning. Certifique-se de navegar até a interface do usuário global e procure a entrada Registros .

Executar um trabalho de pipeline em um espaço de trabalho usando o componente do Registro
Ao executar um trabalho de pipeline que usa um componente de um registro, os recursos de computação e os dados de treinamento são locais para o espaço de trabalho. Para obter mais informações sobre como executar trabalhos, consulte os seguintes artigos:
- Trabalhos em execução (CLI)
- Executando trabalhos (SDK)
- Trabalhos de pipeline com componentes (CLI)
- Trabalhos de pipeline com componentes (SDK)
Executaremos um trabalho de pipeline com o componente de treinamento Scikit Learn criado na seção anterior para treinar um modelo. Verifique se você está na pasta cli/jobs/pipelines-with-components/nyc_taxi_data_regression. O conjunto de dados de treinamento está localizado na data_transformed pasta. Edite a component seção abaixo da train_job seção do single-job-pipeline.yml arquivo para fazer referência ao componente de treinamento criado na seção anterior. O resultado single-job-pipeline.yml é mostrado abaixo.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
O aspeto principal é que esse pipeline será executado em um espaço de trabalho usando um componente que não está no espaço de trabalho específico. O componente está em um registro que pode ser usado com qualquer espaço de trabalho em sua organização. Você pode executar esse trabalho de treinamento em qualquer espaço de trabalho ao qual tenha acesso sem ter que se preocupar em disponibilizar o código e o ambiente de treinamento nesse espaço de trabalho.
Aviso
- Antes de executar o trabalho de pipeline, confirme se o espaço de trabalho no qual você executará o trabalho está em uma região do Azure que é suportada pelo registro no qual você criou o componente.
- Confirme se o espaço de trabalho tem um cluster de computação com o nome
cpu-clusterou edite ocomputecampo abaixojobs.train_job.computecom o nome do seu cálculo.
Execute o trabalho de pipeline com o az ml job create comando.
az ml job create --file single-job-pipeline.yml
Gorjeta
Se você não configurou o espaço de trabalho padrão e o grupo de recursos conforme explicado na seção de pré-requisitos, será necessário especificar os --workspace-name parâmetros e --resource-group para que funcione az ml job create .
Como alternativa, você pode pular a edição single-job-pipeline.yml e substituir o nome do componente usado pela train_job CLI.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Como o componente usado no trabalho de treinamento é compartilhado por meio de um registro, você pode enviar o trabalho para qualquer espaço de trabalho ao qual tenha acesso em sua organização, mesmo em assinaturas diferentes. Por exemplo, se você tiver dev-workspace, test-workspace e prod-workspace, executar o trabalho de treinamento nesses três espaços de trabalho é tão fácil quanto executar três az ml job create comandos.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
No estúdio do Azure Machine Learning, selecione o link do ponto de extremidade na saída do trabalho para exibir o trabalho. Aqui você pode analisar métricas de treinamento, verificar se o trabalho está usando o componente e o ambiente do registro e revisar o modelo treinado. Anote o name do trabalho na saída ou localize as mesmas informações na visão geral do trabalho no estúdio do Azure Machine Learning. Você precisará dessas informações para baixar o modelo treinado na próxima seção sobre a criação de modelos no registro.

Criar um modelo no registo
Você aprenderá como criar modelos em um registro nesta seção. Analise gerenciar modelos para saber mais sobre o gerenciamento de modelos no Azure Machine Learning. Veremos duas maneiras diferentes de criar um modelo em um registro. O primeiro é de arquivos locais. Em segundo lugar, é copiar um modelo registrado no espaço de trabalho para um registro.
Em ambas as opções, você criará um modelo com o formato MLflow, que o ajudará a implantar esse modelo para inferência sem escrever nenhum código de inferência.
Criar um modelo no registo a partir de ficheiros locais
Baixe o modelo, que está disponível como saída do train_job substituindo <job-name> pelo nome do trabalho da seção anterior. O modelo, juntamente com os arquivos de metadados MLflow, ./artifacts/model/deve estar disponível no .
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Gorjeta
Se você não configurou o espaço de trabalho padrão e o grupo de recursos conforme explicado na seção de pré-requisitos, será necessário especificar os --workspace-name parâmetros e --resource-group para que funcione az ml model create .
Aviso
A saída de az ml job list é passada para sed. Isso funciona apenas em shells Linux. Se você estiver no Windows, execute az ml job list --parent-job-name <job-name> --query [0].name e remova todas as aspas que você vê no nome do trabalho do trem.
Se você não conseguir baixar o modelo, poderá encontrar um exemplo de modelo MLflow treinado pelo trabalho de treinamento na seção anterior da cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ pasta.
Crie o modelo no registo:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Gorjeta
- Use um número aleatório para o parâmetro se você receber um erro que o nome do modelo e a
versionversão existem. - O mesmo comando
az ml model createCLI pode ser usado para criar modelos em um espaço de trabalho ou registro. Executar o comando com--workspace-nameo comando cria o modelo em um espaço de trabalho, enquanto executar o comando com--registry-namecria o modelo no registro.
Partilhar um modelo da área de trabalho para o registo
Neste fluxo de trabalho, você primeiro criará o modelo no espaço de trabalho e, em seguida, o compartilhará no Registro. Esse fluxo de trabalho é útil quando você deseja testar o modelo no espaço de trabalho antes de compartilhá-lo. Por exemplo, implante-o em pontos de extremidade, experimente a inferência com alguns dados de teste e, em seguida, copie o modelo para um registro se tudo parecer bom. Esse fluxo de trabalho também pode ser útil quando você está desenvolvendo uma série de modelos usando diferentes técnicas, estruturas ou parâmetros e deseja promover apenas um deles para o registro como um candidato de produção.
Certifique-se de ter o nome do trabalho de pipeline da seção anterior e substitua-o no comando para buscar o nome do trabalho de treinamento abaixo. Em seguida, você registrará o modelo da saída do trabalho de treinamento no espaço de trabalho. Observe como o --path parâmetro se refere à saída de saída train_job com a azureml://jobs/$train_job_name/outputs/artifacts/paths/model sintaxe.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Gorjeta
- Use um número aleatório para o
versionparâmetro se você receber um erro de que o nome do modelo e a versão existem." - Se você não configurou o espaço de trabalho padrão e o grupo de recursos conforme explicado na seção de pré-requisitos, será necessário especificar os
--workspace-nameparâmetros e--resource-grouppara que funcioneaz ml model create.
Anote o nome e a versão do modelo. Você pode validar se o modelo está registrado no espaço de trabalho navegando-o na interface do usuário do Studio ou usando az ml model show --name nyc-taxi-model --version $model_version o comando.
Em seguida, você compartilhará o modelo do espaço de trabalho para o registro.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Gorjeta
- Certifique-se de usar o nome e a versão do modelo corretos se você o alterou no
az ml model createcomando. - O comando acima tem dois parâmetros opcionais: "--share-with-name" e "--share-with-version". Se estes não forem fornecidos, o novo modelo terá o mesmo nome e versão do modelo que está a ser partilhado.
Anote o
nameeversiondo modelo a partir da saída doaz ml model createcomando e use-os comaz ml model showcomandos da seguinte maneira. Você precisará donameeversionna próxima seção quando implantar o modelo em um ponto de extremidade online para inferência.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
Você também pode usar az ml model list --registry-name <registry-name> para listar todos os modelos no Registro ou procurar todos os componentes na interface do usuário do estúdio do Azure Machine Learning. Certifique-se de navegar até a interface do usuário global e procure o hub Registros.
A captura de tela a seguir mostra um modelo em um registro no estúdio do Azure Machine Learning. Se você criou um modelo a partir da saída do trabalho e, em seguida, copiou o modelo do espaço de trabalho para o registro, verá que o modelo tem um link para o trabalho que treinou o modelo. Você pode usar esse link para navegar até o trabalho de treinamento para revisar o código, o ambiente e os dados usados para treinar o modelo.
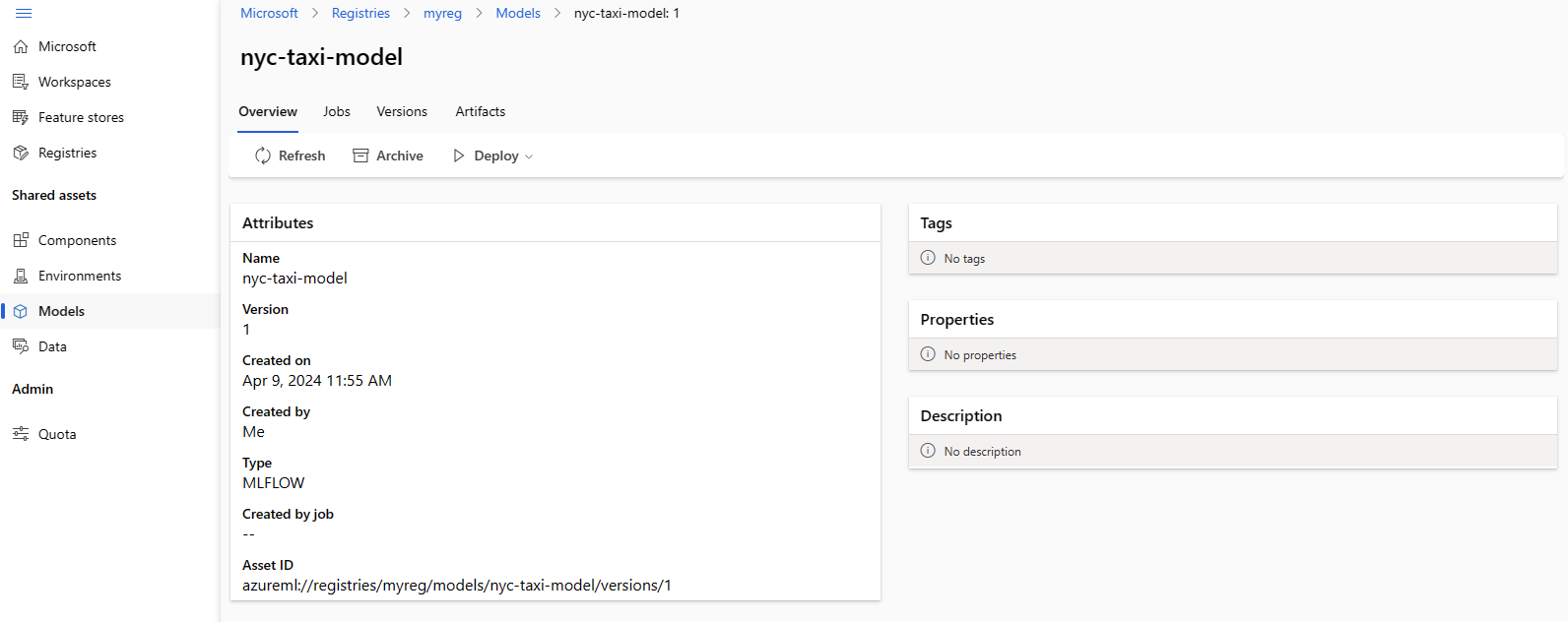
Implantar modelo do registro para o ponto de extremidade online no espaço de trabalho
Na última seção, você implantará um modelo do registro em um ponto de extremidade online em um espaço de trabalho. Você pode optar por implantar qualquer espaço de trabalho ao qual tenha acesso em sua organização, desde que o local do espaço de trabalho seja um dos locais suportados pelo Registro. Esse recurso é útil se você treinou um modelo em um dev espaço de trabalho e agora precisa implantar o modelo no test espaço prod de trabalho, preservando as informações de linhagem em torno do código, ambiente e dados usados para treinar o modelo.
Os pontos de extremidade online permitem implantar modelos e enviar solicitações de inferência por meio das APIs REST. Para obter mais informações, consulte Como implantar e pontuar um modelo de aprendizado de máquina usando um ponto de extremidade online.
Crie um ponto de extremidade online.
az ml online-endpoint create --name reg-ep-1234
Atualize a model: linha deploy.yml disponível na pasta para consultar o cli/jobs/pipelines-with-components/nyc_taxi_data_regression nome do modelo e a versão da etapa anterior. Crie uma implantação online para o ponto de extremidade online. O deploy.yml é mostrado abaixo para referência.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Crie a implantação online. A conclusão da implementação demora vários minutos.
az ml online-deployment create --file deploy.yml --all-traffic
Buscar o URI de pontuação e enviar uma solicitação de pontuação de amostra. Os dados de exemplo para a solicitação de pontuação estão disponíveis na scoring-data.json cli/jobs/pipelines-with-components/nyc_taxi_data_regression pasta.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Gorjeta
curlcomando funciona apenas no Linux.- Se você não configurou o espaço de trabalho padrão e o grupo de recursos conforme explicado na seção de pré-requisitos, será necessário especificar os
--workspace-nameparâmetros e--resource-grouppara que osaz ml online-endpointcomandos eaz ml online-deploymentfuncionem.
Clean up resources (Limpar recursos)
Se você não vai usar a implantação, deve excluí-la para reduzir custos. O exemplo a seguir exclui o ponto de extremidade e todas as implantações subjacentes:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait