Aceder a dados numa tarefa
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Neste artigo você aprende:
- Como ler dados do armazenamento do Azure em um trabalho do Azure Machine Learning.
- Como gravar dados do seu trabalho do Azure Machine Learning no Armazenamento do Azure.
- A diferença entre os modos de montagem e download .
- Como usar a identidade do usuário e a identidade gerenciada para acessar dados.
- Monte as configurações disponíveis em um trabalho.
- Configurações de montagem ideais para cenários comuns.
- Como acessar ativos de dados V1.
Pré-requisitos
Uma subscrição do Azure. Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
Uma área de trabalho do Azure Machine Learning
Início Rápido
Antes de explorar as opções detalhadas disponíveis para você ao acessar dados, descrevemos primeiro os trechos de código relevantes para acesso aos dados.
Ler dados do armazenamento do Azure em um trabalho do Azure Machine Learning
Neste exemplo, você envia um trabalho do Azure Machine Learning que acessa dados de uma conta de armazenamento de blob pública . No entanto, você pode adaptar o trecho para acessar seus próprios dados em uma conta privada do Armazenamento do Azure. Atualize o caminho conforme descrito aqui. O Azure Machine Learning lida perfeitamente com a autenticação para armazenamento em nuvem, com a passagem do Microsoft Entra. Quando submete um emprego, pode escolher:
- Identidade do usuário: Passe pela sua identidade do Microsoft Entra para acessar os dados
- Identidade gerenciada: use a identidade gerenciada do destino de computação para acessar dados
- Nenhum: não especifique uma identidade para acessar os dados. Use Nenhum ao usar armazenamentos de dados baseados em credenciais (chave/token SAS) ou ao acessar dados públicos
Gorjeta
Se você usar chaves ou tokens SAS para autenticar, sugerimos que crie um armazenamento de dados do Azure Machine Learning, porque o tempo de execução se conectará automaticamente ao armazenamento sem exposição da chave/token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Gravar dados do seu trabalho do Azure Machine Learning no Armazenamento do Azure
Neste exemplo, você envia um trabalho do Azure Machine Learning que grava dados em seu armazenamento de dados padrão do Azure Machine Learning. Opcionalmente, você pode definir o name valor do seu ativo de dados para criar um ativo de dados na saída.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
O tempo de execução de dados do Azure Machine Learning
Quando você envia um trabalho, o tempo de execução de dados do Aprendizado de Máquina do Azure controla a carga de dados, desde o local de armazenamento até o destino de computação. O tempo de execução de dados do Azure Machine Learning é otimizado para velocidade e eficiência para tarefas de aprendizado de máquina. As principais vantagens incluem:
- Cargas de dados escritas na linguagem Rust, uma linguagem conhecida pela alta velocidade e alta eficiência de memória. Para downloads de dados simultâneos, o Rust evita problemas com o Python Global Interpreter Lock (GIL)
- Peso leve; Rust não tem dependências de outras tecnologias - por exemplo, JVM. Como resultado, o tempo de execução é instalado rapidamente e não drena recursos extras (CPU, memória) no destino de computação
- Carregamento de dados multiprocesso (paralelo)
- Pré-busca de dados como uma tarefa em segundo plano na(s) CPU(s), para permitir uma melhor utilização da(s) GPU(s) ao fazer deep-learning
- Tratamento de autenticação perfeito para armazenamento em nuvem
- Fornece opções para montar dados (fluxo) ou baixar todos os dados. Para obter mais informações, visite as seções Monte (streaming) e Download .
- Integração perfeita com fsspec - uma interface pythonic unificada para sistemas de arquivos locais, remotos e incorporados e armazenamento de bytes.
Gorjeta
Sugerimos que você aproveite o tempo de execução de dados do Azure Machine Learning, em vez de criar seu próprio recurso de montagem/download em seu código de treinamento (cliente). Observamos restrições de taxa de transferência de armazenamento quando o código do cliente usa Python para baixar dados do armazenamento, devido a problemas de Global Interpreter Lock (GIL).
Caminhos
Ao fornecer uma entrada/saída de dados para um trabalho, você deve especificar um path parâmetro que aponte para o local dos dados. Esta tabela mostra os diferentes locais de dados suportados pelo Azure Machine Learning e também mostra path exemplos de parâmetros:
| Location | Exemplos | Entrada | Saída |
|---|---|---|---|
| Um caminho no computador local | ./home/username/data/my_data |
Y | N |
| Um caminho em um servidor http(s) público(s) | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Um caminho no Armazenamento do Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, apenas para autenticação baseada em identidade. | N |
| Um caminho em um armazenamento de dados do Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| Um caminho para um Ativo de Dados | azureml:<my_data>:<version> |
Y | N, mas você pode usar name e version criar um ativo de dados a partir da saída |
Modos
Ao executar um trabalho com entradas/saídas de dados, você pode selecionar entre estas opções de modo :
ro_mount: Monte o local de armazenamento, como somente leitura no destino de computação do disco local (SSD).rw_mount: Monte o local de armazenamento, como leitura-gravação no destino de computação do disco local (SSD).download: Transfira os dados da localização de armazenamento para o destino de computação do disco local (SSD).upload: Carregue dados do destino de computação para o local de armazenamento.eval_mount/eval_download: Estes modos são exclusivos do MLTable. Em alguns cenários, um MLTable pode gerar arquivos que podem estar localizados em uma conta de armazenamento diferente da conta de armazenamento que hospeda o arquivo MLTable. Ou, um MLTable pode subdefinir ou embaralhar os dados localizados no recurso de armazenamento. Essa exibição do subconjunto/embaralhamento se tornará visível somente se o tempo de execução de dados do Aprendizado de Máquina do Azure realmente avaliar o arquivo MLTable. Por exemplo, este diagrama mostra como um MLTable usado comeval_mountoueval_downloadpode tirar imagens de dois contêineres de armazenamento diferentes e um arquivo de anotações localizado em uma conta de armazenamento diferente e, em seguida, montar/baixar para o sistema de arquivos do destino de computação remoto.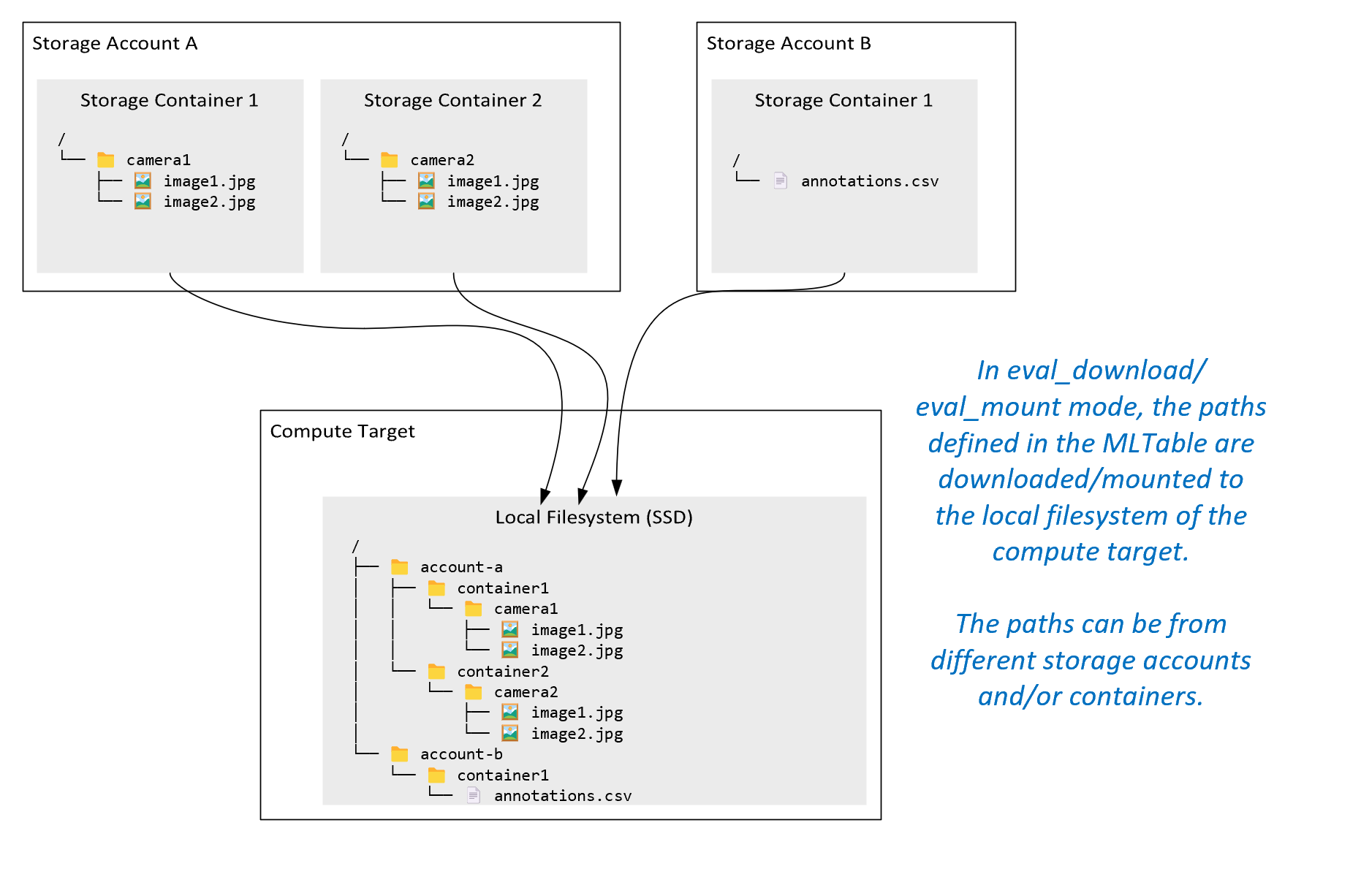
A
camera1pasta,camera2pasta eannotations.csvarquivo são então acessíveis no sistema de arquivos do destino de computação na estrutura de pastas:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Talvez você queira ler dados diretamente de um URI por meio de outras APIs, em vez de passar pelo tempo de execução de dados do Aprendizado de Máquina do Azure. Por exemplo, talvez você queira acessar dados em um bucket do s3 (com uma URL de estilo hospedado virtualmente ou de caminhohttps) usando o cliente boto s3. Você pode obter o URI da entrada como uma cadeia de caracteres com odirectmodo. Você vê o uso do modo direto no Spark Jobs, porque osspark.read_*()métodos sabem como processar os URIs. Para trabalhos que não sejam do Spark , é sua responsabilidade gerenciar as credenciais de acesso. Por exemplo, você deve usar explicitamente o MSI de computação ou o acesso do broker.

Esta tabela mostra os modos possíveis para diferentes combinações de tipo/modo/entrada/saída:
| Type | Entrada/Saída | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Entrada | ✓ | ✓ | ✓ | ||||
uri_file |
Entrada | ✓ | ✓ | ✓ | ||||
mltable |
Entrada | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Saída | ✓ | ✓ | |||||
uri_file |
Saída | ✓ | ✓ | |||||
mltable |
Saída | ✓ | ✓ | ✓ |
Download
No modo de download, todos os dados de entrada são copiados para o disco local (SSD) do destino de computação. O tempo de execução de dados do Azure Machine Learning inicia o script de treinamento do usuário, assim que todos os dados forem copiados. Quando o script de usuário é iniciado, ele lê dados do disco local, assim como qualquer outro arquivo. Quando o trabalho é concluído, os dados são removidos do disco do destino de computação.
| Vantagens | Desvantagens |
|---|---|
| Quando o treinamento começa, todos os dados estão disponíveis no disco local (SSD) do destino de computação, para o script de treinamento. Nenhuma interação de armazenamento/rede do Azure é necessária. | O conjunto de dados deve caber completamente em um disco de destino de computação. |
| Depois que o script do usuário é iniciado, não há dependências na confiabilidade do armazenamento/rede. | Todo o conjunto de dados é baixado (se o treinamento precisar selecionar aleatoriamente apenas uma pequena parte de um dado, grande parte do download será desperdiçada). |
| O tempo de execução de dados do Azure Machine Learning pode paralelizar o download (diferença significativa em muitos arquivos pequenos) e a taxa de transferência máxima de rede/armazenamento. | O trabalho aguarda até que todos os dados sejam baixados para o disco local do destino de computação. Para um trabalho de aprendizagem profunda enviado, as GPUs ficam ociosas até que os dados estejam prontos. |
| Nenhuma sobrecarga inevitável adicionada pela camada FUSE (ida e volta: chamada de espaço do usuário no script do usuário → kernel → daemon de fusível do espaço do usuário → resposta do kernel → resposta ao script do usuário no espaço do usuário) | As alterações de armazenamento não são refletidas nos dados após o download ser feito. |
Quando usar o download
- Os dados são pequenos o suficiente para caber no disco do destino de computação sem interferência com outros treinamentos
- O treinamento usa a maior parte ou todo o conjunto de dados
- O treinamento lê arquivos de um conjunto de dados mais de uma vez
- O treinamento deve saltar para posições aleatórias de um arquivo grande
- Não há problema em esperar até que todos os dados sejam baixados antes do início do treinamento
Configurações de download disponíveis
Você pode ajustar as configurações de download com estas variáveis de ambiente em seu trabalho:
| Nome da Variável de Ambiente | Type | Valor Predefinido | Description |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
U64 | NUMBER_OF_CPU_CORES * 4 |
Número de threads simultâneos que o download pode usar |
AZUREML_DATASET_HTTP_RETRY_COUNT |
U64 | 7 | Número de tentativas de repetição de armazenamento individual / http solicitação para recuperar de erros transitórios. |
Em seu trabalho, você pode alterar os padrões acima definindo as variáveis de ambiente - por exemplo:
Por uma questão de brevidade, mostramos apenas como definir as variáveis de ambiente no trabalho.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Baixar métricas de desempenho
O tamanho da VM do seu destino de computação tem um efeito no tempo de download dos seus dados. Especificamente:
- O número de núcleos. Quanto mais núcleos disponíveis, mais simultaneidade e, portanto, velocidade de download mais rápida.
- A largura de banda de rede esperada. Cada VM no Azure tem uma taxa de transferência máxima da placa de interface de rede (NIC).
Nota
Para VMs de GPU A100, o tempo de execução de dados do Aprendizado de Máquina do Azure pode saturar a NIC (Placa de Interface de Rede) ao baixar dados para o destino de computação (~24 Gbit/s): a taxa de transferência máxima teórica possível.
Esta tabela mostra o desempenho de download que o tempo de execução de dados do Azure Machine Learning pode manipular para um arquivo de 100 GB em uma Standard_D15_v2 VM (20 núcleos, taxa de transferência de rede de 25 Gbit/s):
| Estrutura de dados | Apenas download (segs) | Baixe e calcule MD5 (segs) | Taxa de transferência alcançada (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB Arquivos | 55.74 | 260.97 | 14,35 Gbit/s |
| Arquivos de 100 x 1 GB | 58.09 | 259.47 | 13,77 Gbit/s |
| 1 x 100 GB de arquivo | 96.13 | 300.61 | 8,32 Gbit/s |
Podemos ver que um arquivo maior, dividido em arquivos menores, pode melhorar o desempenho de download devido ao paralelismo. Recomendamos que você evite arquivos que se tornam muito pequenos (menos de 4 MB) porque o tempo necessário para envios de solicitações de armazenamento aumenta, em relação ao tempo gasto no download da carga útil. Para obter mais informações, leia Muitos problemas de arquivos pequenos.
Montagem (streaming)
No modo de montagem, o recurso de dados do Aprendizado de Máquina do Azure usa o recurso Linux FUSE (sistema de arquivos no espaço do usuário) para criar um sistema de arquivos emulado. Em vez de baixar todos os dados para o disco local (SSD) do destino de computação, o tempo de execução pode reagir às ações de script do usuário em tempo real. Por exemplo, "open file", "read 2-KB chunk from position X", "list directory content".
| Vantagens | Desvantagens |
|---|---|
| Os dados que excedem a capacidade do disco local de destino de computação podem ser usados (não limitados pelo hardware de computação) | Adicionada sobrecarga do módulo Linux FUSE. |
| Sem atraso no início do treinamento (ao contrário do modo de download). | Dependência do comportamento do código do usuário (se o código de treinamento que lê sequencialmente arquivos pequenos em uma única montagem de thread também solicitar dados do armazenamento, ele pode não maximizar a taxa de transferência de rede ou armazenamento). |
| Mais configurações disponíveis para ajustar para um cenário de uso. | Sem suporte a janelas. |
| Somente os dados necessários para o treinamento são lidos do armazenamento. |
Quando usar o Mount
- Os dados são grandes e não cabem no disco local de destino de computação.
- Cada nó de computação individual em um cluster não precisa ler todo o conjunto de dados (arquivo aleatório ou linhas na seleção de arquivos csv, etc.).
- Atrasos esperando que todos os dados sejam baixados antes do início do treinamento podem se tornar um problema (tempo ocioso da GPU).
Configurações de montagem disponíveis
Você pode ajustar as configurações de montagem com estas variáveis de ambiente em seu trabalho:
| Nome da variável Env | Type | Default value | Description |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
U64 | Não definido (o cache nunca expira) | Tempo, em milissegundos, necessário para manter os resultados da getattr chamada em cache e evitar solicitações subsequentes dessas informações do armazenamento novamente. |
DATASET_RESERVED_FREE_DISK_SPACE |
U64 | 150 MB | Destinado a uma configuração do sistema, para manter a computação íntegra. Não importa quais valores as outras configurações tenham, o tempo de execução de dados do Azure Machine Learning não usa os últimos RESERVED_FREE_DISK_SPACE bytes de espaço em disco. |
DATASET_MOUNT_CACHE_SIZE |
usize | Ilimitado | Controla quanto espaço em disco a montagem pode usar. Um valor positivo define o valor absoluto em bytes. O valor negativo define quanto espaço em disco deve ser deixado livre. Esta tabela fornece mais opções de cache de disco. Suporta KBe MB GB modificadores por conveniência. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | A montagem de volume inicia a remoção de cache quando o cache é preenchido até AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Deve estar entre 0 e 1. Defini-lo < 1 aciona a remoção de cache em segundo plano mais cedo. AVAILABLE_CACHE_SIZE não é uma variável de ambiente que você possa modificar ou visualizar diretamente. Neste contexto, refere-se ao "número de bytes que o sistema calcula como disponíveis para cache". Esse valor depende de fatores como o tamanho do disco, a quantidade de espaço em disco necessária para a integridade do sistema e as configurações definidas em variáveis de ambiente (como DATASET_RESERVED_FREE_DISK_SPACE e DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0.7 | A remoção de cache tenta liberar pelo menos (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) de um espaço de cache. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Tamanho do bloco de leitura de streaming. Quando o arquivo for grande o suficiente, solicite pelo menos DATASET_MOUNT_READ_BLOCK_SIZE os dados do armazenamento e armazene em cache, mesmo quando a operação de leitura solicitada pelo fusível for menor. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Número de blocos a serem pré-buscados (o bloco de leitura k aciona a pré-busca em segundo plano dos blocos k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Número de threads de pré-busca em segundo plano. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
booleano | false | Habilite o cache baseado em blocos. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Aplica-se apenas ao cache baseado em blocos. Tamanho do cache baseado em bloco de RAM pode usar. Um valor de 0 desativa completamente o cache de memória. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
booleano | verdadeiro | Aplica-se apenas ao cache baseado em blocos. Quando definido como true, o cache baseado em blocos usa o disco rígido local para armazenar blocos em cache. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Aplica-se apenas ao cache baseado em blocos. O cache baseado em blocos grava o bloco armazenado em cache em um disco local em segundo plano. Essa configuração controla a quantidade de memória que a montagem pode usar para armazenar blocos aguardando liberação para o cache de disco local. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Aplica-se apenas ao cache baseado em blocos. Número de threads em segundo plano que o cache baseado em blocos usa para gravar blocos baixados no disco local do destino de computação. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
U64 | 30 | Tempo em segundos para unmount concluir (graciosamente) todas as operações pendentes (por exemplo, chamadas de liberação) antes de encerrar à força o loop de mensagem de montagem. |
Em seu trabalho, você pode alterar os padrões acima definindo as variáveis de ambiente, por exemplo:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Modo aberto baseado em blocos
O modo aberto baseado em blocos divide cada arquivo em blocos de um tamanho predefinido (exceto para o último bloco). Uma solicitação de leitura de uma posição especificada solicita um bloco correspondente do armazenamento e retorna os dados solicitados imediatamente. Uma leitura também aciona a pré-busca em segundo plano de N próximos blocos, usando vários threads (otimizados para leitura sequencial). Os blocos baixados são armazenados em cache em duas camadas de cache (RAM e disco local).
| Vantagens | Desvantagens |
|---|---|
| Entrega rápida de dados para o script de treinamento (menos bloqueio para partes que ainda não foram solicitadas). | Leituras aleatórias podem desperdiçar blocos pré-buscados para frente. |
| Mais descargas de trabalho para threads em segundo plano (pré-busca/cache). A formação pode então prosseguir. | Adicionada sobrecarga para navegar entre caches, em comparação com leituras diretas de um arquivo em um cache de disco local (por exemplo, no modo de cache de arquivo inteiro). |
| Somente os dados solicitados (mais a pré-busca) são lidos do armazenamento. | |
| Para dados suficientemente pequenos, é utilizado cache rápido baseado em RAM. |
Quando usar o modo aberto baseado em blocos
Recomendado para a maioria dos cenários , exceto quando você precisa de leituras rápidas de locais de arquivos aleatórios. Nesses casos, use o modo aberto de cache de arquivos inteiro.
Modo aberto de cache de arquivos inteiros
Quando um arquivo em uma pasta de montagem é aberto (por exemplo, f = open(path, args)) no modo de arquivo inteiro, a chamada é bloqueada até que todo o arquivo seja baixado em uma pasta de cache de destino de computação no disco. Todas as chamadas de leitura subsequentes redirecionam para o arquivo armazenado em cache, portanto, nenhuma interação de armazenamento é necessária. Se o cache não tiver espaço disponível suficiente para caber no arquivo atual, a montagem tentará remover o arquivo usado menos recentemente do cache. Nos casos em que o arquivo não cabe no disco (em relação às configurações de cache), o tempo de execução de dados volta ao modo de streaming.
| Vantagens | Desvantagens |
|---|---|
| Nenhuma confiabilidade de armazenamento / dependências de taxa de transferência depois que o arquivo é aberto. | A chamada aberta é bloqueada até que todo o arquivo seja baixado. |
| Leituras aleatórias rápidas (leitura de pedaços de lugares aleatórios do arquivo). | O arquivo inteiro é lido do armazenamento, mesmo quando algumas partes do arquivo podem não ser necessárias. |
Quando Utilizar
Quando leituras aleatórias são necessárias para arquivos relativamente grandes que excedem 128 MB.
Utilização
Defina a variável DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED de ambiente como false no seu trabalho:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montagem: Listando arquivos
Ao trabalhar com milhões de ficheiros, evite uma listagem recursiva - por exemplo ls -R /mnt/dataset/folder/. Uma listagem recursiva dispara muitas chamadas para listar o conteúdo do diretório pai. Em seguida, requer uma chamada recursiva separada para cada diretório dentro, em todos os níveis filho. Normalmente, o Armazenamento do Azure permite que apenas 5000 elementos sejam retornados por solicitação de lista única. Como resultado, uma listagem recursiva de 1 milhão de pastas contendo 10 arquivos cada requer 1,000,000 / 5000 + 1,000,000 = 1,000,200 solicitações para armazenamento. Em comparação, 1.000 pastas com 10.000 arquivos precisariam apenas de 1001 solicitações de armazenamento para uma listagem recursiva.
A montagem do Azure Machine Learning lida com a listagem de forma preguiçosa. Portanto, para listar muitos arquivos pequenos, é melhor usar uma chamada iterativa de biblioteca de cliente (por exemplo, os.scandir() em Python) em vez de uma chamada de biblioteca de cliente que retorna a lista completa (por exemplo, os.listdir() em Python). Uma chamada iterativa de biblioteca de cliente retorna um gerador, o que significa que ele não precisa esperar até que toda a lista seja carregada. Pode, então, avançar mais rapidamente.
Esta tabela compara o tempo necessário para o Python os.scandir() e funções para listar os.listdir() uma pasta que contém ~ 4M arquivos em uma estrutura plana:
| Métrica | os.scandir() |
os.listdir() |
|---|---|---|
| Hora de obter a primeira entrada (segs) | 0.67 | 553.79 |
| Tempo para obter as primeiras 50k entradas (segs) | 9.56 | 562.73 |
| Tempo para obter todas as entradas (segs) | 558.35 | 582.14 |
Configurações de montagem ideais para cenários comuns
Para determinados cenários comuns, mostramos as configurações de montagem ideais que você precisa definir em seu trabalho do Azure Machine Learning.
Leitura de arquivo grande sequencialmente uma vez (linhas de processamento no arquivo csv)
Inclua estas configurações de montagem na environment_variables seção do seu trabalho do Azure Machine Learning:
Nota
Para usar computação sem servidor, exclua compute="cpu-cluster", este código.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Leitura de arquivo grande uma vez a partir de vários threads (processamento de arquivo csv particionado em vários threads)
Inclua estas configurações de montagem na environment_variables seção do seu trabalho do Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Leitura de milhões de pequenos arquivos (imagens) de vários threads uma vez (treinamento de época única em imagens)
Inclua estas configurações de montagem na environment_variables seção do seu trabalho do Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Leitura de milhões de pequenos arquivos (imagens) de vários threads várias vezes (várias épocas treinando em imagens)
Inclua estas configurações de montagem na environment_variables seção do seu trabalho do Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Leitura de arquivo grande com buscas aleatórias (como servir banco de dados de arquivos da pasta montada)
Inclua estas configurações de montagem na environment_variables seção do seu trabalho do Azure Machine Learning:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnosticar e resolver gargalos de carregamento de dados
Quando um trabalho do Azure Machine Learning é executado com dados, o de uma entrada determina como os mode bytes são lidos do armazenamento e armazenados em cache no disco SSD local de destino de computação. Para o modo de download, todos os dados são armazenados em cache no disco, antes que o código do usuário inicie sua execução. Por conseguinte, fatores como
- Número de threads paralelos
- o número de ficheiros
- tamanho do ficheiro
ter um efeito sobre as velocidades máximas de download. Para montagem, o código do usuário deve começar a abrir arquivos antes que os dados comecem a armazenar em cache. Diferentes configurações de montagem resultam em diferentes comportamentos de leitura e cache. Vários fatores afetam a velocidade com que os dados são carregados do armazenamento:
- Localidade de dados a ser computada: seus locais de armazenamento e destino de computação devem ser os mesmos. Se o destino de armazenamento e computação estiver localizado em regiões diferentes, o desempenho será prejudicado porque os dados devem ser transferidos entre regiões. Para obter mais informações sobre como garantir que seus dados sejam colocados com computação, visite Colocate data with compute.
- O tamanho do destino de computação: Pequenos cálculos têm contagens de núcleos mais baixas (menos paralelismo) e menor largura de banda de rede esperada em comparação com tamanhos de computação maiores - ambos os fatores afetam o desempenho de carregamento de dados.
- Por exemplo, se você usar um tamanho de VM pequeno, como
Standard_D2_v2(2 núcleos, 1500 Mbps NIC), e tentar carregar 50.000 MB (50 GB) de dados, o melhor tempo de carregamento de dados alcançável seria ~270 segundos (supondo que você saturar a NIC com taxa de transferência de 187,5 MB/s). Em contraste, umStandard_D5_v2(16 núcleos, 12.000 Mbps) carregaria os mesmos dados em ~33 segundos (supondo que você saturasse a NIC com taxa de transferência de 1500 MB/s).
- Por exemplo, se você usar um tamanho de VM pequeno, como
- Nível de armazenamento: para a maioria dos cenários, incluindo LLM (Large Language Models), o armazenamento padrão oferece o melhor perfil de custo/desempenho. No entanto, se você tiver muitos arquivos pequenos, o armazenamento premium oferece um melhor perfil de custo/desempenho. Para obter mais informações, leia Opções de armazenamento do Azure.
- Carga de armazenamento: se a conta de armazenamento estiver sob alta carga - por exemplo, muitos nós de GPU em um cluster solicitando dados - você corre o risco de atingir a capacidade de saída do armazenamento. Para obter mais informações, leia Carga de armazenamento. Se você tiver muitos arquivos pequenos que precisam de acesso em paralelo, poderá atingir os limites de solicitação de armazenamento. Leia informações atualizadas sobre os limites da capacidade de saída e das solicitações de armazenamento em Dimensionar destinos para contas de armazenamento padrão.
- Padrão de acesso a dados no código do usuário: Quando você usa o modo de montagem, os dados são buscados com base nas ações de abertura/leitura em seu código. Por exemplo, ao ler seções aleatórias de um arquivo grande, as configurações padrão de pré-busca de dados de montagens podem levar a downloads de blocos que não serão lidos. Talvez seja necessário ajustar algumas configurações para atingir a taxa de transferência máxima. Para obter mais informações, leia Configurações de montagem ideais para cenários comuns.
Usando logs para diagnosticar problemas
Para acessar os logs do tempo de execução de dados do seu trabalho:
- Selecione a guia Saídas+Logs na página do trabalho.
- Selecione a pasta system_logs , seguida por data_capability pasta.
- Você verá dois arquivos de log:
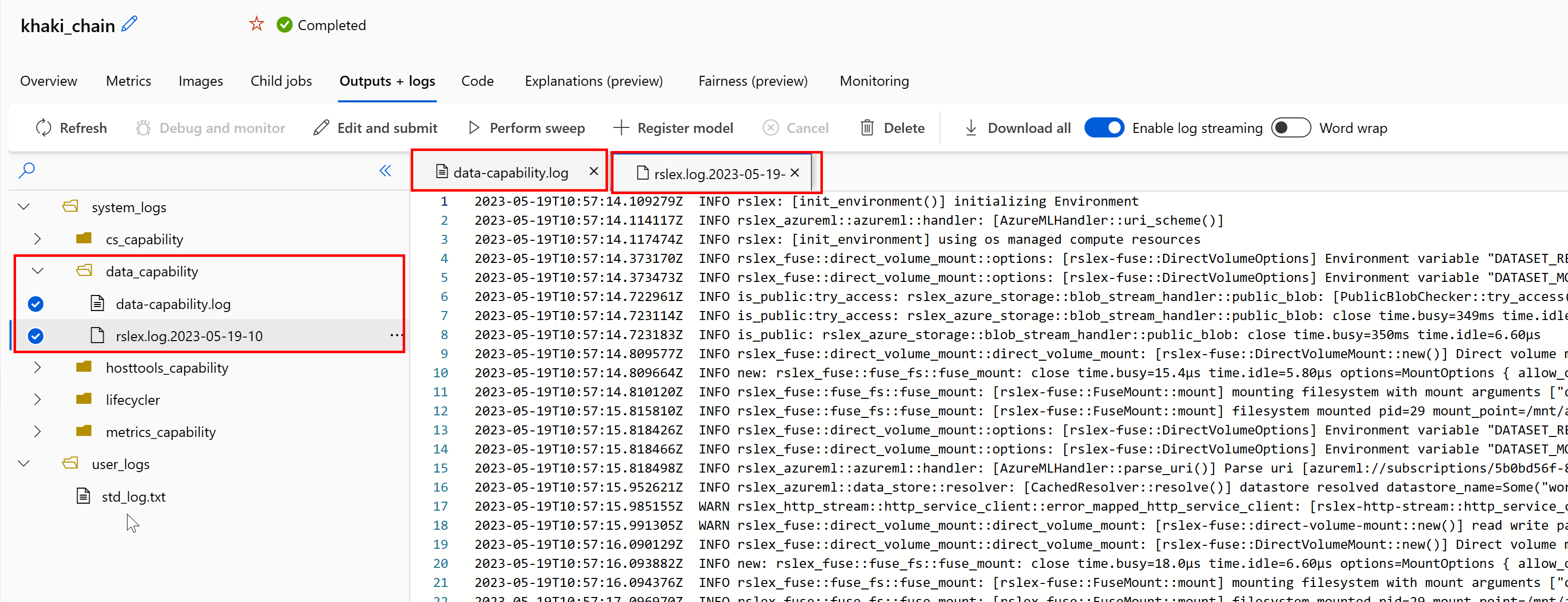

A data-capability.log do arquivo de log mostra as informações de alto nível sobre o tempo gasto nas principais tarefas de carregamento de dados. Por exemplo, quando você baixa dados, o tempo de execução registra os horários de início e término da atividade de download:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Se a taxa de transferência de download for uma fração da largura de banda de rede esperada para o tamanho da VM, você poderá inspecionar o arquivo de log rslex.log.<CARIMBO DE DATA/HORA>. Este arquivo contém todo o log de grão fino do tempo de execução baseado em Rust; Por exemplo, paralelização:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
O arquivo rslex.log fornece detalhes sobre toda a cópia do arquivo, quer você tenha escolhido ou não os modos de montagem ou download. Ele também descreve as configurações (variáveis de ambiente) usadas. Para iniciar a depuração, verifique se você definiu as configurações de montagem Optimum para cenários comuns.
Monitorar o armazenamento do Azure
No portal do Azure, você pode selecionar sua conta de armazenamento e, em seguida , Métricas, para ver as métricas de armazenamento:

Em seguida, plote o SuccessE2ELatency com SuccessServerLatency. Se as métricas mostrarem alto SuccessE2ELatency e baixo SuccessServerLatency, você tiver threads disponíveis limitados ou executar poucos recursos como CPU, memória ou largura de banda de rede, você deverá:
- Use o modo de exibição de monitoramento no estúdio do Azure Machine Learning para verificar a utilização da CPU e da memória do seu trabalho. Se você tiver pouca CPU e memória, considere aumentar o tamanho da VM de destino de computação.
- Considere aumentar
RSLEX_DOWNLOADER_THREADSse você estiver baixando e não utilizar a CPU e a memória. Se você usar montagem, você deve aumentarDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTpara fazer mais pré-busca e aumentarDATASET_MOUNT_READ_THREADSpara mais threads de leitura.
Se as métricas mostrarem baixo SuccessE2ELatency e baixo SuccessServerLatency, mas o cliente experimentar alta latência, você terá um atraso na solicitação de armazenamento que chega ao serviço. Deve verificar:
- Se o número de threads usados para montagem/download (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) está definido como muito baixo, em relação ao número de núcleos disponíveis no destino de computação. Se a configuração for muito baixa, aumente o número de threads. - Se o número de novas tentativas para download (
AZUREML_DATASET_HTTP_RETRY_COUNT) está definido como muito alto. Em caso afirmativo, diminua o número de tentativas.
Monitorar o uso do disco durante um trabalho
No estúdio do Azure Machine Learning, você também pode monitorar a E/S do disco de destino de computação e o uso durante a execução do trabalho. Navegue até o seu trabalho e selecione a guia Monitoramento . Esta guia fornece informações sobre os recursos do seu trabalho, em uma base contínua de 30 dias. Por exemplo:

Nota
A monitorização de tarefas suporta apenas recursos de computação que o Azure Machine Learning gere. Os trabalhos com um tempo de execução inferior a 5 minutos não terão dados suficientes para preencher esta vista.
O tempo de execução de dados do Azure Machine Learning não usa os últimos RESERVED_FREE_DISK_SPACE bytes de espaço em disco para manter a computação íntegra (o valor padrão é 150MB). Se o disco estiver cheio, o código está gravando arquivos no disco sem declarar os arquivos como uma saída. Portanto, verifique seu código para certificar-se de que os dados não estão sendo gravados erroneamente no disco temporário. Se você precisar gravar arquivos no disco temporário e esse recurso estiver ficando cheio, considere:
- Aumentando o tamanho da VM para um que tenha um disco temporário maior
- Definindo um TTL nos dados armazenados em cache (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL), para limpar os dados do disco
Colocalizar dados com computação
Atenção
Se o armazenamento e a computação estiverem em regiões diferentes, o desempenho será prejudicado porque os dados devem ser transferidos entre regiões. Isso aumenta os custos. Verifique se a conta de armazenamento e os recursos de computação estão na mesma região.
Se seus dados e o Espaço de Trabalho do Azure Machine Learning estiverem armazenados em regiões diferentes, recomendamos que você copie os dados para uma conta de armazenamento na mesma região com o utilitário azcopy . O AzCopy usa APIs de servidor para servidor, para que os dados sejam copiados diretamente entre os servidores de armazenamento. Essas operações de cópia não usam a largura de banda de rede do seu computador. Você pode aumentar a taxa de transferência dessas operações com a AZCOPY_CONCURRENCY_VALUE variável de ambiente. Para saber mais, consulte Aumentar a simultaneidade.
Carga de armazenamento
Uma única conta de armazenamento pode ficar limitada quando está sob alta carga, quando:
- Seu trabalho usa muitos nós de GPU
- Sua conta de armazenamento tem muitos usuários/aplicativos simultâneos que acessam os dados à medida que você executa seu trabalho
Esta seção mostra os cálculos para determinar se a limitação pode se tornar um problema para sua carga de trabalho e como abordar as reduções de limitação.
Calcular limites de largura de banda
Uma conta de Armazenamento do Azure tem um limite de saída padrão de 120 Gbit/s. As VMs do Azure têm larguras de banda de rede diferentes, que têm um efeito sobre o número teórico de nós de computação necessários para atingir a capacidade máxima de saída padrão de armazenamento:
| Tamanho | Placa GPU | vCPU | Memória: GiB | Armazenamento (SSD) temporário GiB | Número de placas GPU | Memória GPU: GiB | Largura de banda de rede esperada (Gbit/s) | Padrão de saída da conta de armazenamento Max (Gbit/s)* | Número de nós a atingir a capacidade de saída padrão |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6.000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Ambos os SKUs A100/V100 têm uma largura de banda de rede máxima por nó de 24 Gbit/s. Se cada nó que lê dados de uma única conta puder ler perto do máximo teórico de 24 Gbit/s, a capacidade de saída ocorreria com cinco nós. O uso de seis ou mais nós de computação começaria a degradar a taxa de transferência de dados em todos os nós.
Importante
Se sua carga de trabalho precisar de mais de 6 nós de A100/V100, ou se você acredita que excederá a capacidade de saída padrão de armazenamento (120Gbit/s), entre em contato com o suporte (por meio do Portal do Azure) e solicite um aumento do limite de saída de armazenamento.
Dimensionamento em várias contas de armazenamento
Você pode exceder a capacidade máxima de saída de armazenamento e/ou atingir os limites de taxa de solicitação. Se esses problemas ocorrerem, sugerimos que você entre em contato com o suporte primeiro, para aumentar esses limites na conta de armazenamento.
Se não for possível aumentar a capacidade máxima de saída ou o limite da taxa de solicitação, considere replicar os dados em várias contas de armazenamento. Copie os dados para várias contas com o Azure Data Factory, o Azure Storage Explorer ou azcopyo , e monte todas as contas em seu trabalho de treinamento. Somente os dados acessados em uma montagem são baixados. Portanto, seu código de treinamento pode ler a RANK variável de ambiente, para escolher qual das várias entradas monta a partir da qual ler. Sua definição de trabalho passa em uma lista de contas de armazenamento:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Seu código python de treinamento pode ser usado RANK para obter a conta de armazenamento específica para esse nó:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problema de muitos arquivos pequenos
A leitura de arquivos do armazenamento envolve fazer solicitações para cada arquivo. A contagem de solicitações por arquivo varia, com base nos tamanhos dos arquivos e nas configurações do software que lida com as leituras dos arquivos.
Os arquivos são geralmente lidos em blocos de 1-4 MB de tamanho. Os ficheiros mais pequenos do que um bloco são lidos com um único pedido (GET file.jpg 0-4MB), e os ficheiros maiores do que um bloco têm um pedido feito por bloco (GET file.jpg 0-4MB, GET file.jpg 4-8 MB). Esta tabela mostra que arquivos menores que um bloco de 4 MB resultam em mais solicitações de armazenamento em comparação com arquivos maiores:
| # Arquivos | Tamanho do Ficheiro | Tamanho total dos dados | Tamanho do bloco | # Pedidos de armazenamento |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB | 4 MB | 2,000,000 |
| 1,000 | 1 GB | 1 TB | 4 MB | 256,000 |
Para arquivos pequenos, o intervalo de latência envolve principalmente o tratamento das solicitações para armazenamento, em vez de transferências de dados. Portanto, oferecemos estas recomendações para aumentar o tamanho do arquivo:
- Para dados não estruturados (imagens, texto, vídeo, etc.), arquive (zip/tar) pequenos arquivos juntos, para armazená-los como um arquivo maior que pode ser lido em vários blocos. Esses arquivos arquivados maiores podem ser abertos no recurso de computação, e o PyTorch Archive DataPipes pode extrair os arquivos menores.
- Para dados estruturados (CSV, parquet, etc.), examine seu processo ETL, para se certificar de que ele aglutina arquivos para aumentar o tamanho. O Spark tem
repartition()métodos paracoalesce()ajudar a aumentar o tamanho dos arquivos.
Se não conseguir aumentar os tamanhos dos ficheiros, explore as opções de Armazenamento do Azure.
Opções de Armazenamento do Azure
O Armazenamento do Azure oferece duas camadas : standard e premium:
| Armazenamento | Cenário |
|---|---|
| Blob do Azure - Standard (HDD) | Seus dados são estruturados em blobs maiores - imagens, vídeo, etc. |
| Azure Blob - Premium (SSD) | Altas taxas de transação, objetos menores ou requisitos de latência de armazenamento consistentemente baixos |
Gorjeta
Para "muitos" arquivos pequenos (magnitude KB), recomendamos o uso de premium (SSD) porque o custo de armazenamento é menor do que os custos de execução da computação GPU.
Ler ativos de dados V1
Esta seção explica como ler V1 FileDataset e TabularDataset entidades de dados em um trabalho V2.
Leia um FileDataset
Input No objeto, especifique as e mode as AssetTypes.MLTABLE type InputOutputModes.EVAL_MOUNT:
Nota
Para usar computação sem servidor, exclua compute="cpu-cluster", este código.
Para obter mais informações sobre o objeto MLClient, as opções de inicialização do objeto MLClient e como se conectar a um espaço de trabalho, visite Conectar a um espaço de trabalho.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Leia um TabularDataset
Input No objeto, especifique as type as AssetTypes.MLTABLE, e mode as InputOutputModes.DIRECT:
Nota
Para usar computação sem servidor, exclua compute="cpu-cluster", este código.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint