Resolver problemas de Computação do Kubernetes
Neste artigo, você aprenderá a solucionar erros comuns de carga de trabalho na computação do Kubernetes. Os erros comuns incluem trabalhos de treinamento e erros de ponto final.
Guia de inferência
Os erros comuns de ponto de extremidade do Kubernetes na computação do Kubernetes são categorizados em dois escopos: escopo de computação e escopo de cluster. Os erros de escopo de computação estão relacionados ao destino de computação, como o destino de computação não foi encontrado ou o destino de computação não está acessível. Os erros de escopo do cluster estão relacionados ao cluster Kubernetes subjacente, como o cluster em si não está acessível ou o cluster não foi encontrado.
Erros de computação do Kubernetes
A seguir estão os tipos de erro comuns no escopo de computação que você pode encontrar ao usar a computação do Kubernetes para criar pontos de extremidade online e implantações on-line para inferência de modelo em tempo real. Você pode solucionar problemas seguindo as seções vinculadas para diretrizes:
- ERRO: GenericComputeError
- ERRO: ComputeNotFound
- ERRO: ComputeNotAccessible
- ERRO: InvalidComputeInformation
- ERRO: InvalidComputeNoKubernetesConfiguration
ERRO: GenericComputeError
A mensagem de erro é como:
Failed to get compute information.
Este erro deve ocorrer quando o sistema não conseguiu obter as informações de computação do cluster Kubernetes. Você pode verificar os seguintes itens para solucionar o problema:
- Verifique o status do cluster Kubernetes. Se o cluster não estiver em execução, você precisará iniciá-lo primeiro.
- Verifique a integridade do cluster do Kubernetes.
- Você pode exibir o relatório de verificação de integridade do cluster para quaisquer problemas, por exemplo, se o cluster não estiver acessível.
- Você pode ir ao portal do espaço de trabalho para verificar o status da computação.
- Verifique se os tipos de instância são informações estão corretas. Você pode verificar os tipos de instância suportados na documentação de computação do Kubernetes.
- Tente desanexar e reanexar a computação ao espaço de trabalho, se aplicável.
Nota
Para solucionar erros reanexando, garanta reanexar com exatamente a mesma configuração da computação desanexada anteriormente, como o mesmo nome de computação e namespace, caso contrário, você poderá encontrar outros erros.
ERRO: ComputeNotFound
A mensagem de erro é a seguinte:
Cannot find Kubernetes compute.
Este erro deve ocorrer quando:
- O sistema não consegue encontrar a computação ao criar/atualizar um novo ponto de extremidade/implantação online.
- A computação de endpoints/implantações on-line existentes foi removida.
Você pode verificar os seguintes itens para solucionar o problema:
- Tente recriar o ponto de extremidade e a implantação.
- Tente desanexar e reanexar a computação ao espaço de trabalho. Preste atenção a mais notas sobre reanexar.
ERRO: ComputeNotAccessible
A mensagem de erro é a seguinte:
The Kubernetes compute is not accessible.
Este erro deve ocorrer quando o MSI (identidade gerenciada) do espaço de trabalho não tem acesso ao cluster AKS. Você pode verificar se o espaço de trabalho MSI tem acesso ao AKS e, se não, você pode seguir este documento para gerenciar o acesso e a identidade.
ERRO: InvalidComputeInformation
A mensagem de erro é a seguinte:
The compute information is invalid.
Há um processo de validação de destino de computação ao implantar modelos no cluster do Kubernetes. Este erro deve ocorrer quando as informações de computação são inválidas. Por exemplo, o destino de computação não foi encontrado ou a configuração da extensão do Azure Machine Learning foi atualizada no cluster do Kubernetes.
Você pode verificar os seguintes itens para solucionar o problema:
- Verifique se o destino de computação usado está correto e existe em seu espaço de trabalho.
- Tente desanexar e reanexar a computação ao espaço de trabalho. Preste atenção a mais notas sobre reanexar.
ERRO: InvalidComputeNoKubernetesConfiguration
A mensagem de erro é a seguinte:
The compute kubeconfig is invalid.
Este erro deve ocorrer quando o sistema não conseguiu encontrar qualquer configuração para se conectar ao cluster, como:
- Para o cluster Arc-Kubernetes, não é possível encontrar nenhuma configuração do Azure Relay.
- Para o cluster AKS, não é possível encontrar nenhuma configuração AKS.
Para reconstruir a configuração da conexão de computação em seu cluster, você pode tentar desanexar e reanexar a computação ao espaço de trabalho. Preste atenção a mais notas sobre reanexar.
Erro de cluster do Kubernetes
Abaixo está uma lista de tipos de erro no escopo do cluster que você pode encontrar ao usar a computação do Kubernetes para criar pontos de extremidade online e implantações on-line para inferência de modelo em tempo real, que você pode solucionar seguindo a diretriz:
- ERRO: GenericClusterError
- ERRO: ClusterNotReachable
- ERRO: ClusterNotFound
- ERRO: ClusterServiceNotFound
- ERRO: ClusterUnauthorized
ERRO: GenericClusterError
A mensagem de erro é a seguinte:
Failed to connect to Kubernetes cluster: <message>
Este erro deve ocorrer quando o sistema não conseguiu se conectar ao cluster Kubernetes por um motivo desconhecido. Você pode verificar os seguintes itens para solucionar o problema:
Para clusters AKS:
- Verifique se o cluster AKS está desligado.
- Se o cluster não estiver em execução, você precisará iniciá-lo primeiro.
- Verifique se o cluster AKS habilitou a rede selecionada usando intervalos de IP autorizados.
- Se o cluster AKS tiver ativado intervalos IP autorizados, certifique-se de que todos os intervalos IP do plano de controlo do Azure Machine Learning foram ativados para o cluster AKS. Mais informações você pode ver este documento.
Para um cluster AKS ou um cluster Kubernetes habilitado para Azure Arc:
- Verifique se o servidor de API do Kubernetes está acessível executando
kubectlo comando no cluster.
ERRO: ClusterNotReachable
A mensagem de erro é a seguinte:
The Kubernetes cluster is not reachable.
Este erro deve ocorrer quando o sistema não consegue se conectar a um cluster. Você pode verificar os seguintes itens para solucionar o problema:
Para clusters AKS:
- Verifique se o cluster AKS está desligado.
- Se o cluster não estiver em execução, você precisará iniciá-lo primeiro.
Para um cluster AKS ou um cluster Kubernetes habilitado para Azure Arc:
- Verifique se o servidor de API do Kubernetes está acessível executando
kubectlo comando no cluster.
ERRO: ClusterNotFound
A mensagem de erro é a seguinte:
Cannot found Kubernetes cluster.
Este erro deve ocorrer quando o sistema não consegue encontrar o cluster AKS/Arc-Kubernetes.
Você pode verificar os seguintes itens para solucionar o problema:
- Primeiro, verifique a ID do recurso de cluster no portal do Azure para verificar se o recurso de cluster do Kubernetes ainda existe e está sendo executado normalmente.
- Se o cluster existir e estiver em execução, você poderá tentar desanexar e reanexar a computação ao espaço de trabalho. Preste atenção a mais notas sobre reanexar.
ERRO: ClusterServiceNotFound
A mensagem de erro é a seguinte:
AzureML extension service not found in cluster.
Este erro deve ocorrer quando o serviço de entrada de propriedade da extensão não tem pods de back-end suficientes.
Pode:
- Acesse o cluster e verifique o status do serviço
azureml-ingress-nginx-controllere seu pod de back-end sob oazuremlnamespace. - Se o cluster não tiver nenhum pod de back-end em execução, verifique o motivo descrevendo o pod. Por exemplo, se o pod não tiver recursos suficientes para ser executado, você poderá excluir alguns pods para liberar recursos suficientes para o pod de entrada.
ERRO: ClusterUnauthorized
A mensagem de erro é a seguinte:
Request to Kubernetes cluster unauthorized.
Esse erro só deve ocorrer no cluster habilitado para TA, o que significa que o token de acesso expirou durante a implantação.
Você pode tentar novamente depois de alguns minutos.
Gorjeta
Mais informações sobre erros comuns ao criar/atualizar os endpoints e implantações online do Kubernetes, você pode encontrar em Como solucionar problemas de endpoints online.
Erro de identidade
ERRO: RefreshExtensionIdentityNotSet
Este erro ocorre quando a extensão está instalada, mas a identidade da extensão não está atribuída corretamente. Você pode tentar reinstalar a extensão para corrigi-lo.
Observe que esse erro é apenas para clusters gerenciados
Como verificar se sslCertPemFile e sslKeyPemFile está correto?
Para permitir que quaisquer erros conhecidos sejam revelados, você pode usar os comandos para executar uma verificação de linha de base para seu certificado e chave. Espere que o segundo comando retorne "RSA key ok" sem solicitar a senha.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Execute os comandos para verificar se sslCertPemFile e sslKeyPemFile são correspondentes:
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Para sslCertPemFile, é o certificado público. Ele deve incluir a cadeia de certificados que inclui os seguintes certificados e deve estar na sequência do certificado do servidor, do certificado de autoridade de certificação intermediário e do certificado de autoridade de certificação raiz:
- O certificado do servidor: o servidor apresenta ao cliente durante o handshake TLS. Ele contém a chave pública do servidor, nome de domínio e outras informações. O certificado do servidor é assinado por uma autoridade de certificação (CA) intermediária que garante a identidade do servidor.
- O certificado de autoridade de certificação intermediário: a autoridade de certificação intermediária apresenta ao cliente para provar sua autoridade para assinar o certificado do servidor. Ele contém a chave pública, o nome e outras informações da autoridade de certificação intermediária. O certificado de autoridade de certificação intermediária é assinado por uma autoridade de certificação raiz que garante a identidade da autoridade de certificação intermediária.
- O certificado de autoridade de certificação raiz: a autoridade de certificação raiz apresenta ao cliente para provar sua autoridade para assinar o certificado de autoridade de certificação intermediário. Ele contém a chave pública, o nome e outras informações da autoridade de certificação raiz. O certificado de autoridade de certificação raiz é autoassinado e confiável pelo cliente.
Guia de formação
Quando o trabalho de treinamento estiver em execução, você poderá verificar o status do trabalho no portal do espaço de trabalho. Quando você encontrar algum status de trabalho anormal, como o trabalho repetido várias vezes, ou o trabalho foi bloqueado no estado de inicialização, ou até mesmo o trabalho eventualmente falhou, você pode seguir o guia para solucionar o problema.
Depuração de nova tentativa de trabalho
Se o pod de trabalho de treinamento em execução no cluster foi encerrado devido à execução do nó para OOM do nó (falta de memória), o trabalho será automaticamente repetido para outro nó disponível.
Para depurar ainda mais a causa raiz da tentativa de trabalho, você pode ir para o portal de espaço de trabalho para verificar o log de repetição de trabalho.
- Cada log de repetição é registrado em uma nova pasta de log com o formato de "número> de retry-retry<" (como: retry-001).
Em seguida, você pode obter as informações de mapeamento do nó do trabalho de repetição para descobrir em qual nó o trabalho de repetição está sendo executado.
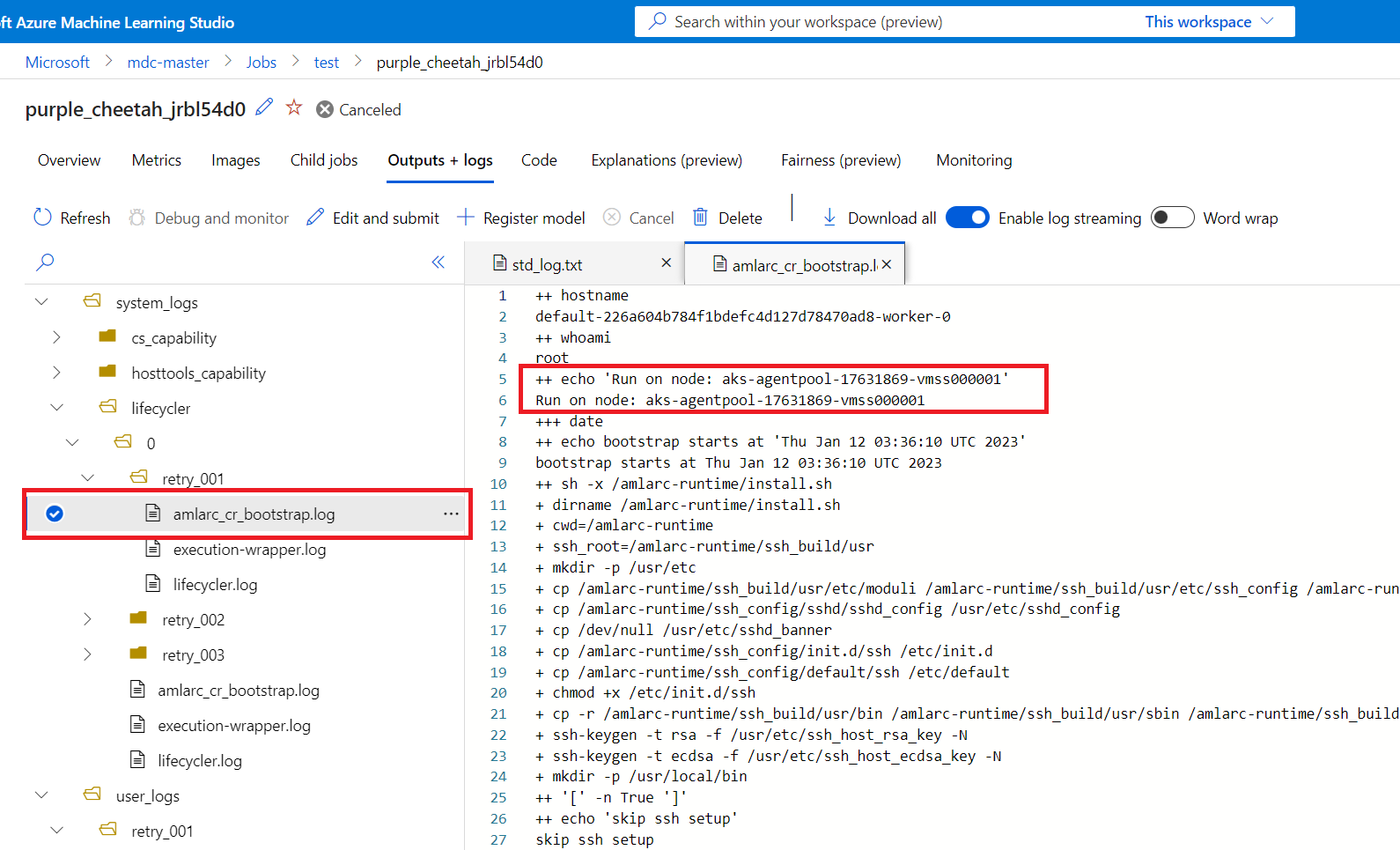
Você pode obter informações de mapeamento de nó de trabalho do amlarc_cr_bootstrap.log em system_logs pasta.
O nome do host do nó, no qual o pod de trabalho está sendo executado, é indicado neste log, por exemplo:
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
"ask-agentpool-17631869-vmss0000" representa o nome do host do nó que executa esse trabalho no cluster AKS. Em seguida, você pode acessar o cluster para verificar o status do nó para investigação adicional.
Job pod ficar preso no estado Init
Se o trabalho for executado por mais tempo do que o esperado e se você achar que seus pods de trabalho estão ficando presos em um estado Init com esse aviso Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matched, o problema pode estar ocorrendo porque a extensão do Azure Machine Learning não oferece suporte ao modo de download para dados de entrada.
Para resolver esse problema, altere para o modo de montagem para seus dados de entrada.
Erros comuns de falha de trabalho
Abaixo está uma lista de tipos de erro comuns que você pode encontrar ao usar a computação do Kubernetes para criar e executar um trabalho de treinamento, que você pode solucionar seguindo a diretriz:
- O trabalho falhou. 137
- O trabalho falhou. E45004
- O trabalho falhou. 400
- Fornecer uma chave de conta ou token de SAS
- Falha na autorização do AzureBlob
O trabalho falhou. 137
Se a mensagem de erro for:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Verifique sua configuração de proxy e verifique se 127.0.0.1 foi adicionado ao proxy-skip-range ao usar az connectedk8s connect seguindo esta configuração de rede.
O trabalho falhou. E45004
Se a mensagem de erro for:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Verifique se você definiu enableTraining=True ao fazer a instalação da extensão do Azure Machine Learning. Mais detalhes podem ser encontrados em Implantar a extensão do Azure Machine Learning no cluster AKS ou Arc Kubernetes
O trabalho falhou. 400
Se a mensagem de erro for:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Você pode seguir a seção de solução de problemas de Link privado para verificar suas configurações de rede.
Fornecer uma chave de conta ou token de SAS
Se você precisar acessar o Azure Container Registry (ACR) para imagem do Docker e acessar a Conta de Armazenamento para dados de treinamento, esse problema deve ocorrer quando a computação não é especificada com uma identidade gerenciada.
Para acessar o Azure Container Registry (ACR) a partir de um cluster de computação do Kubernetes para imagens do Docker ou acessar uma conta de armazenamento para dados de treinamento, você precisa anexar a computação do Kubernetes com uma identidade gerenciada atribuída pelo sistema ou pelo usuário habilitada.
No cenário de treinamento acima, essa identidade de computação é necessária para que a computação do Kubernetes seja usada como uma credencial para se comunicar entre o recurso ARM vinculado ao espaço de trabalho e o cluster de computação do Kubernetes. Assim, sem essa identidade, o trabalho de treinamento falha e relata a falta de chave de conta ou token sas. Por exemplo, se você não especificar uma identidade gerenciada para sua computação do Kubernetes, o trabalho falhará com a seguinte mensagem de erro:
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
A causa é que a conta de armazenamento padrão do espaço de trabalho de aprendizado de máquina sem credenciais não está acessível para trabalhos de treinamento na computação do Kubernetes.
Para atenuar esse problema, você pode atribuir a Identidade Gerenciada à computação na etapa de anexação de computação ou pode atribuir a Identidade Gerenciada à computação depois que ela for anexada. Mais detalhes podem ser encontrados em Atribuir identidade gerenciada ao destino de computação.
Falha na autorização do AzureBlob
Se você precisar acessar o AzureBlob para upload ou download de dados em seus trabalhos de treinamento na computação do Kubernetes, o trabalho falhará com a seguinte mensagem de erro:
Unable to upload project files to working directory in AzureBlob because the authorization failed.
A causa é a falha de autorização quando o trabalho tenta carregar os arquivos de projeto para o AzureBlob. Você pode verificar os seguintes itens para solucionar o problema:
- Verifique se a conta de armazenamento habilitou as exceções de "Permitir que os serviços do Azure na lista de serviços confiáveis acessem esta conta de armazenamento" e se o espaço de trabalho está na lista de instâncias de recursos.
- Verifique se o espaço de trabalho tem uma identidade gerenciada atribuída ao sistema.
Problema de link privado
Poderíamos usar o método para verificar a configuração do link privado fazendo login em um pod no cluster do Kubernetes e, em seguida, verificar as configurações de rede relacionadas.
Encontre a ID do espaço de trabalho no portal do Azure ou obtenha essa ID executando
az ml workspace showna linha de comando.Mostrar todos os pods azureml-fe executados por
kubectl get po -n azureml -l azuremlappname=azureml-fe.Inicie sessão em qualquer um deles executado
kubectl exec -it -n azureml {scorin_fe_pod_name} bash.Se o cluster não usar proxy, execute
nslookup {workspace_id}.workspace.{region}.api.azureml.ms. Se você configurar o link privado da VNet para o espaço de trabalho corretamente, o IP interno na VNet deverá ser respondido por meio da ferramenta DNSLookup .Se o cluster usa proxy, você pode tentar espaço de
curltrabalho
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Quando o proxy e o espaço de trabalho estão configurados corretamente com um link privado, você deve observar uma tentativa de se conectar a um IP interno. Uma resposta com um código de status HTTP 401 é esperada neste cenário se um token não for fornecido.
Outros problemas conhecidos
A atualização de computação do Kubernetes não entra em vigor
No momento, a CLI v2 e o SDK v2 não permitem atualizar nenhuma configuração de uma computação existente do Kubernetes. Por exemplo, alterar o namespace não entra em vigor.
O nome do espaço de trabalho ou do grupo de recursos termina com '-'
Uma causa comum da falha "InternalServerError" ao criar cargas de trabalho, como implantações, pontos de extremidade ou trabalhos em uma computação do Kubernetes, é ter os caracteres especiais como '-' no final do nome do espaço de trabalho ou do grupo de recursos.
Próximos passos
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários