Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Automatize o ajuste eficiente de hiperparâmetros usando o SDK do Azure Machine Learning v2 e a CLI v2 por meio do tipo SweepJob.
- Definir o espaço de pesquisa de parâmetros para a versão experimental
- Especifique o algoritmo de amostragem para seu trabalho de varredura
- Especificar o objetivo a otimizar
- Especificar a política de rescisão antecipada para trabalhos de baixo desempenho
- Definir limites para o trabalho de varredura
- Iniciar uma experiência com a configuração definida
- Visualize os trabalhos de treinamento
- Selecione a melhor configuração para o seu modelo
O que é o ajuste de hiperparâmetros?
Os hiperparâmetros são parâmetros ajustáveis que permitem controlar o processo de treinamento do modelo. Por exemplo, com redes neurais, você decide o número de camadas ocultas e o número de nós em cada camada. O desempenho do modelo depende fortemente dos hiperparâmetros.
O ajuste de hiperparâmetros, também chamado de otimização de hiperparâmetros, é o processo de encontrar a configuração de hiperparâmetros que resulta no melhor desempenho. O processo é tipicamente computacionalmente caro e manual.
O Azure Machine Learning permite-lhe automatizar o ajuste de hiperparâmetros e executar experiências em paralelo para otimizar eficientemente os hiperparâmetros.
Definir o espaço de pesquisa
Ajuste os hiperparâmetros explorando o intervalo de valores definidos para cada hiperparâmetro.
Os hiperparâmetros podem ser discretos ou contínuos e têm uma distribuição de valores descrita por uma expressão de parâmetro.
Hiperparâmetros discretos
Os hiperparâmetros discretos são especificados como um Choice entre valores discretos.
Choice pode ser:
- um ou mais valores separados por vírgulas
- um
rangeobjeto - qualquer objeto arbitrário
list
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
Neste caso, batch_size um dos valores [16, 32, 64, 128] e number_of_hidden_layers toma um dos valores [1, 2, 3, 4].
Os seguintes hiperparâmetros discretos avançados também podem ser especificados usando uma distribuição:
-
QUniform(min_value, max_value, q)- Devolve um valor como round(Uniform(min_value, max_value) / q) * q -
QLogUniform(min_value, max_value, q)- Devolve um valor como round(exp(Uniform(min_value, max_value)) / q) * q -
QNormal(mu, sigma, q)- Devolve um valor como round(Normal(mu, sigma) / q) * q -
QLogNormal(mu, sigma, q)- Devolve um valor como round(exp(Normal(mu, sigma)) / q) * q
Hiperparâmetros contínuos
Os hiperparâmetros contínuos são especificados como uma distribuição em um intervalo contínuo de valores:
-
Uniform(min_value, max_value)- Devolve um valor uniformemente distribuído entre min_value e max_value -
LogUniform(min_value, max_value)- Devolve um valor desenhado de acordo com exp(Uniform(min_value, max_value)) para que o logaritmo do valor de retorno seja uniformemente distribuído -
Normal(mu, sigma)- Devolve um valor real que é normalmente distribuído com mu médio e desvio padrão sigma -
LogNormal(mu, sigma)- Devolve um valor desenhado de acordo com exp(Normal(mu, sigma)) para que o logaritmo do valor de retorno seja normalmente distribuído
Um exemplo de uma definição de espaço de parâmetro:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Este código define um espaço de pesquisa com dois parâmetros - learning_rate e keep_probability.
learning_rate tem uma distribuição normal com valor médio 10 e desvio padrão de 3.
keep_probability tem uma distribuição uniforme com um valor mínimo de 0,05 e um valor máximo de 0,1.
Para a CLI, você pode usar o esquema YAML de trabalho de varredura para definir o espaço de pesquisa em seu YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Amostragem do espaço de hiperparâmetros
Especifique o método de amostragem de parâmetros a ser usado no espaço de hiperparâmetros. O Azure Machine Learning dá suporte aos seguintes métodos:
- Amostragem aleatória
- Amostragem em grelha
- Amostragem bayesiana
Amostragem aleatória
A amostragem aleatória suporta hiperparâmetros discretos e contínuos. Apoia a cessação antecipada de trabalhos de baixo desempenho. Alguns usuários fazem uma pesquisa inicial com amostragem aleatória e, em seguida, refinam o espaço de pesquisa para melhorar os resultados.
Na amostragem aleatória, os valores de hiperparâmetros são selecionados aleatoriamente a partir do espaço de pesquisa definido. Depois de criar seu trabalho de comando, você pode usar o parâmetro sweep para definir o algoritmo de amostragem.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol é um tipo de amostragem aleatória suportada por tipos de trabalho de varredura. Você pode usar sobol para reproduzir seus resultados usando seed e cobrir a distribuição de espaço de pesquisa de forma mais uniforme.
Para usar sobol, use a classe RandomParameterSampling para adicionar a semente e a regra, conforme mostrado no exemplo abaixo.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Amostragem em grelha
A amostragem em grelha suporta hiperparâmetros discretos. Use a amostragem de grade se puder fazer um orçamento para pesquisar exaustivamente no espaço de pesquisa. Suporta a rescisão antecipada de trabalhos de baixo desempenho.
A amostragem de grade faz uma pesquisa de grade simples sobre todos os valores possíveis. A amostragem em grelha só pode ser utilizada com choice hiperparâmetros. Por exemplo, o espaço a seguir tem seis exemplos:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Amostragem bayesiana
A amostragem bayesiana é baseada no algoritmo de otimização bayesiana. Ele seleciona amostras com base em como as amostras anteriores fizeram, para que novas amostras melhorem a métrica primária.
A amostragem bayesiana é recomendada se você tiver orçamento suficiente para explorar o espaço de hiperparâmetros. Para obter melhores resultados, recomendamos um número máximo de trabalhos maior ou igual a 20 vezes o número de hiperparâmetros que estão sendo ajustados.
O número de trabalhos simultâneos tem impacto na eficácia do processo de ajuste. Um número menor de trabalhos simultâneos pode levar a uma melhor convergência amostral, uma vez que o menor grau de paralelismo aumenta o número de trabalhos que se beneficiam de trabalhos concluídos anteriormente.
A amostragem bayesiana suporta choiceapenas , uniforme quniform distribuições sobre o espaço de pesquisa.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Especificar o objetivo da varredura
Defina o objetivo do seu trabalho de varredura especificando a métrica principal e a meta que você deseja otimizar o ajuste de hiperparâmetros. Cada trabalho de treinamento é avaliado pela métrica primária. A política de rescisão antecipada usa a métrica principal para identificar trabalhos de baixo desempenho.
-
primary_metric: O nome da métrica primária precisa corresponder exatamente ao nome da métrica registrada pelo script de treinamento -
goal: Pode ser um ouMaximizeMinimizee determina se a métrica primária será maximizada ou minimizada ao avaliar os trabalhos.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Esta amostra maximiza a "precisão".
Métricas de log para ajuste de hiperparâmetros
O script de treinamento para seu modelo deve registrar a métrica primária durante o treinamento do modelo usando o mesmo nome de métrica correspondente para que o SweepJob possa acessá-la para ajuste de hiperparâmetros.
Registre a métrica principal em seu script de treinamento com o seguinte trecho de exemplo:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
O script de treinamento calcula e val_accuracy registra como a métrica primária "precisão". Cada vez que a métrica é registrada, ela é recebida pelo serviço de ajuste de hiperparâmetros. Cabe a você determinar a frequência dos relatórios.
Para obter mais informações sobre o registro de valores para trabalhos de treinamento, consulte Habilitar o registro em log em trabalhos de treinamento do Azure Machine Learning.
Especificar a política de rescisão antecipada
Termine automaticamente trabalhos com baixo desempenho com uma política de rescisão antecipada. A terminação antecipada melhora a eficiência computacional.
Você pode configurar os seguintes parâmetros que controlam quando uma política é aplicada:
-
evaluation_interval: a frequência de aplicação da apólice. Cada vez que o script de treinamento registra, a métrica primária conta como um intervalo. Umevaluation_intervalde 1 aplicará a política sempre que o script de treinamento relatar a métrica principal. Umevaluation_intervalde 2 aplicará a política a cada duas vezes. Se não for especificado,evaluation_intervalé definido como 0 por padrão. -
delay_evaluation: atrasa a primeira avaliação da política para um número especificado de intervalos. Este é um parâmetro opcional que evita o encerramento prematuro de trabalhos de treinamento, permitindo que todas as configurações sejam executadas por um número mínimo de intervalos. Se especificado, a política aplica todos os múltiplos de evaluation_interval que são maiores ou iguais a delay_evaluation. Se não for especificado,delay_evaluationé definido como 0 por padrão.
O Azure Machine Learning dá suporte às seguintes políticas de encerramento antecipado:
- Política de bandidos
- Mediana da política de paragem
- Política de seleção de truncamento
- Nenhuma política de rescisão
Política de bandidos
A política de bandidos é baseada no fator de folga/quantidade de folga e intervalo de avaliação. A política de bandit encerra um trabalho quando a métrica principal não está dentro do fator de folga/quantidade de folga especificada do trabalho mais bem-sucedido.
Especifique os seguintes parâmetros de configuração:
slack_factorouslack_amount: a folga permitida em relação ao trabalho de formação com melhor desempenho.slack_factorespecifica a folga permitida como uma proporção.slack_amountespecifica a margem disponível permitida como um montante absoluto, em vez de um rácio.Por exemplo, considere uma política de bandidos aplicada no intervalo 10. Suponha que o trabalho com melhor desempenho no intervalo 10 relatou uma métrica primária é 0,8 com o objetivo de maximizar a métrica primária. Se a política especificar um
slack_factorde 0,2, todos os trabalhos de treinamento cuja melhor métrica no intervalo 10 seja inferior a 0,66 (0,8/(1+slack_factor)) serão encerrados.evaluation_interval: (facultativo) a frequência de aplicação da apólicedelay_evaluation: (opcional) atrasa a primeira avaliação da política para um número especificado de intervalos
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
Neste exemplo, a política de rescisão antecipada é aplicada em todos os intervalos em que as métricas são relatadas, começando no intervalo de avaliação 5. Qualquer trabalho cuja melhor métrica seja inferior a (1/(1+0,1) ou 91% dos trabalhos com melhor desempenho será encerrado.
Mediana da política de paragem
A parada mediana é uma política de rescisão antecipada baseada em médias de execução de métricas primárias relatadas pelos trabalhos. Esta política calcula as médias em execução em todos os trabalhos de formação e interrompe os trabalhos cujo valor métrico principal é pior do que a mediana das médias.
Esta política utiliza os seguintes parâmetros de configuração:
-
evaluation_interval: a frequência de aplicação da política (parâmetro opcional). -
delay_evaluation: atrasa a primeira avaliação da política para um número especificado de intervalos (parâmetro opcional).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
Neste exemplo, a política de rescisão antecipada é aplicada em todos os intervalos a partir do intervalo de avaliação 5. Um trabalho é interrompido no intervalo 5 se sua melhor métrica primária for pior do que a mediana das médias de execução em intervalos de 1:5 em todos os trabalhos de treinamento.
Política de seleção de truncamento
A seleção de truncamento cancela uma porcentagem de trabalhos com desempenho mais baixo em cada intervalo de avaliação. Os trabalhos são comparados usando a métrica principal.
Esta política utiliza os seguintes parâmetros de configuração:
-
truncation_percentage: a percentagem de trabalhos com pior desempenho a terminar em cada intervalo de avaliação. Um valor inteiro entre 1 e 99. -
evaluation_interval: (facultativo) a frequência de aplicação da apólice -
delay_evaluation: (opcional) atrasa a primeira avaliação da política para um número especificado de intervalos -
exclude_finished_jobs: especifica se os trabalhos concluídos devem ser excluídos ao aplicar a política
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Neste exemplo, a política de rescisão antecipada é aplicada em todos os intervalos a partir do intervalo de avaliação 5. Um trabalho termina no intervalo 5 se o seu desempenho no intervalo 5 estiver nos 20% mais baixos de desempenho de todos os trabalhos no intervalo 5 e excluirá os trabalhos concluídos ao aplicar a política.
Nenhuma política de rescisão (padrão)
Se nenhuma política for especificada, o serviço de ajuste de hiperparâmetros permitirá que todos os trabalhos de treinamento sejam executados até a conclusão.
sweep_job.early_termination = None
Escolher uma política de rescisão antecipada
- Para uma política conservadora que proporcione economia sem encerrar empregos promissores, considere uma Política de Parada Mediana com
evaluation_interval1 edelay_evaluation5. Essas são configurações conservadoras que podem fornecer aproximadamente 25% a 35% de economia sem perda na métrica primária (com base em nossos dados de avaliação). - Para economias mais agressivas, use a Política de Bandido com uma folga permitida menor ou a Política de Seleção de Truncamento com uma porcentagem de truncamento maior.
Defina limites para o seu trabalho de varredura
Controle seu orçamento de recursos definindo limites para seu trabalho de varredura.
-
max_total_trials: Número máximo de trabalhos experimentais. Deve ser um número inteiro entre 1 e 1000. -
max_concurrent_trials: (opcional) Número máximo de trabalhos de avaliação que podem ser executados simultaneamente. Se não for especificado, max_total_trials número de trabalhos será iniciado em paralelo. Se especificado, deve ser um número inteiro entre 1 e 1000. -
timeout: Tempo máximo em segundos que todo o trabalho de varredura pode ser executado. Uma vez atingido esse limite, o sistema cancela o trabalho de varredura, incluindo todas as suas avaliações. -
trial_timeout: Tempo máximo em segundos que cada trabalho de avaliação pode ser executado. Uma vez atingido este limite, o sistema cancela a versão experimental.
Nota
Se o max_total_trials e o tempo limite forem especificados, o experimento de ajuste de hiperparâmetros será encerrado quando o primeiro desses dois limites for atingido.
Nota
O número de trabalhos de avaliação simultânea é limitado aos recursos disponíveis no destino de computação especificado. Certifique-se de que o destino de computação tenha os recursos disponíveis para a simultaneidade desejada.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Esse código configura o experimento de ajuste de hiperparâmetros para usar um máximo de 20 trabalhos de avaliação totais, executando quatro trabalhos de avaliação de cada vez com um tempo limite de 1.200 segundos para todo o trabalho de varredura.
Configurar experimento de ajuste de hiperparâmetros
Para configurar seu experimento de ajuste de hiperparâmetros, forneça o seguinte:
- O espaço de pesquisa de hiperparâmetros definido
- O seu algoritmo de amostragem
- A sua política de rescisão antecipada
- O seu objetivo
- Limites de recursos
- CommandJob ou CommandComponent
- Varredura
SweepJob pode executar uma varredura de hiperparâmetros no Command ou Command Component.
Nota
O destino de computação usado deve sweep_job ter recursos suficientes para satisfazer seu nível de simultaneidade. Para obter mais informações sobre destinos de computação, consulte Destinos de computação.
Configure seu experimento de ajuste de hiperparâmetros:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
O command_job é chamado como uma função para que possamos aplicar as expressões de parâmetro para as entradas de varredura. A sweep função é então configurada com trial, sampling-algorithm, objective, limitse compute. O trecho de código acima é retirado do bloco de anotações de exemplo Executar varredura de hiperparâmetros em um Command ou CommandComponent. Nesta amostra, os learning_rate parâmetros e boosting são ajustados. A paragem antecipada de postos de trabalho é determinada por um MedianStoppingPolicy, que interrompe um trabalho cujo valor métrico primário é pior do que a mediana das médias em todos os trabalhos de formação.( consulte MedianStoppingPolicy referência de classe).
Para ver como os valores de parâmetro são recebidos, analisados e passados para o script de treinamento a ser ajustado, consulte este exemplo de código
Importante
Cada trabalho de varredura de hiperparâmetros reinicia o treinamento do zero, incluindo a reconstrução do modelo e de todos os carregadores de dados. Você pode minimizar esse custo usando um pipeline do Azure Machine Learning ou um processo manual para fazer o máximo de preparação de dados possível antes de seus trabalhos de treinamento.
Enviar experimento de ajuste de hiperparâmetro
Depois de definir sua configuração de ajuste de hiperparâmetro, envie o trabalho:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Visualizar trabalhos de ajuste de hiperparâmetros
Você pode visualizar todos os seus trabalhos de ajuste de hiperparâmetros no estúdio do Azure Machine Learning. Para obter mais informações sobre como exibir um experimento no portal, consulte Exibir registros de trabalho no estúdio.
Gráfico de métricas: esta visualização rastreia as métricas registradas para cada trabalho filho do hyperdrive durante a duração do ajuste do hiperparâmetro. Cada linha representa um trabalho filho e cada ponto mede o valor da métrica primária nessa iteração de tempo de execução.
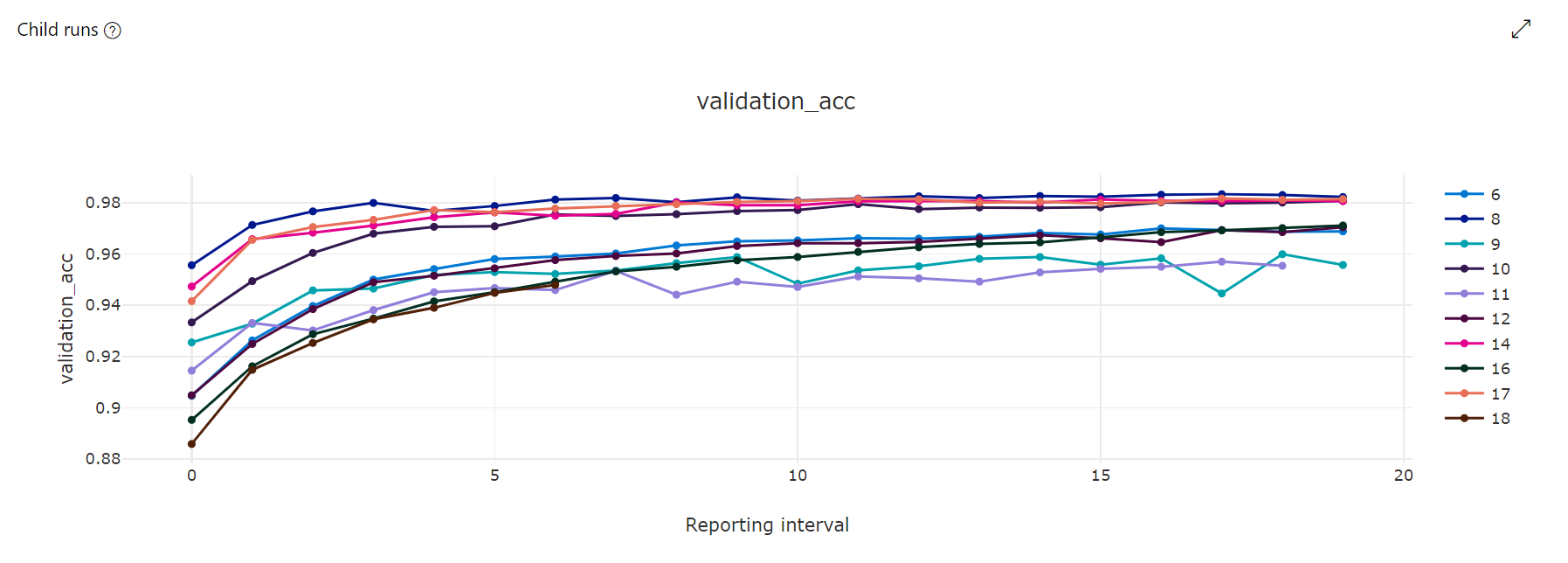
Gráfico de coordenadas paralelas: esta visualização mostra a correlação entre o desempenho da métrica primária e os valores de hiperparâmetros individuais. O gráfico é interativo através do movimento de eixos (selecione e arraste pelo rótulo do eixo) e destacando valores em um único eixo (selecione e arraste verticalmente ao longo de um único eixo para destacar um intervalo de valores desejados). O gráfico de coordenadas paralelas inclui um eixo na parte mais à direita do gráfico que plota o melhor valor métrico correspondente aos hiperparâmetros definidos para essa instância de trabalho. Este eixo é fornecido para projetar a legenda do gradiente do gráfico nos dados de uma forma mais legível.
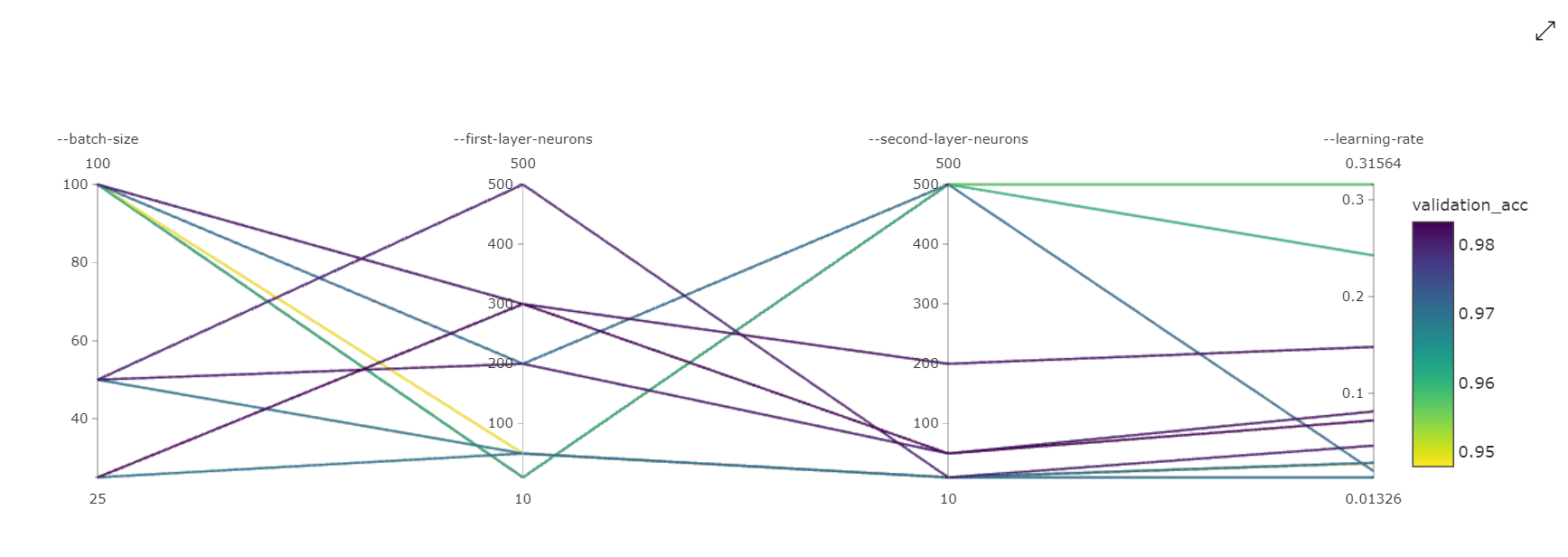
Gráfico de Dispersão 2-Dimensional: Esta visualização mostra a correlação entre quaisquer dois hiperparâmetros individuais, juntamente com o seu valor métrico primário associado.
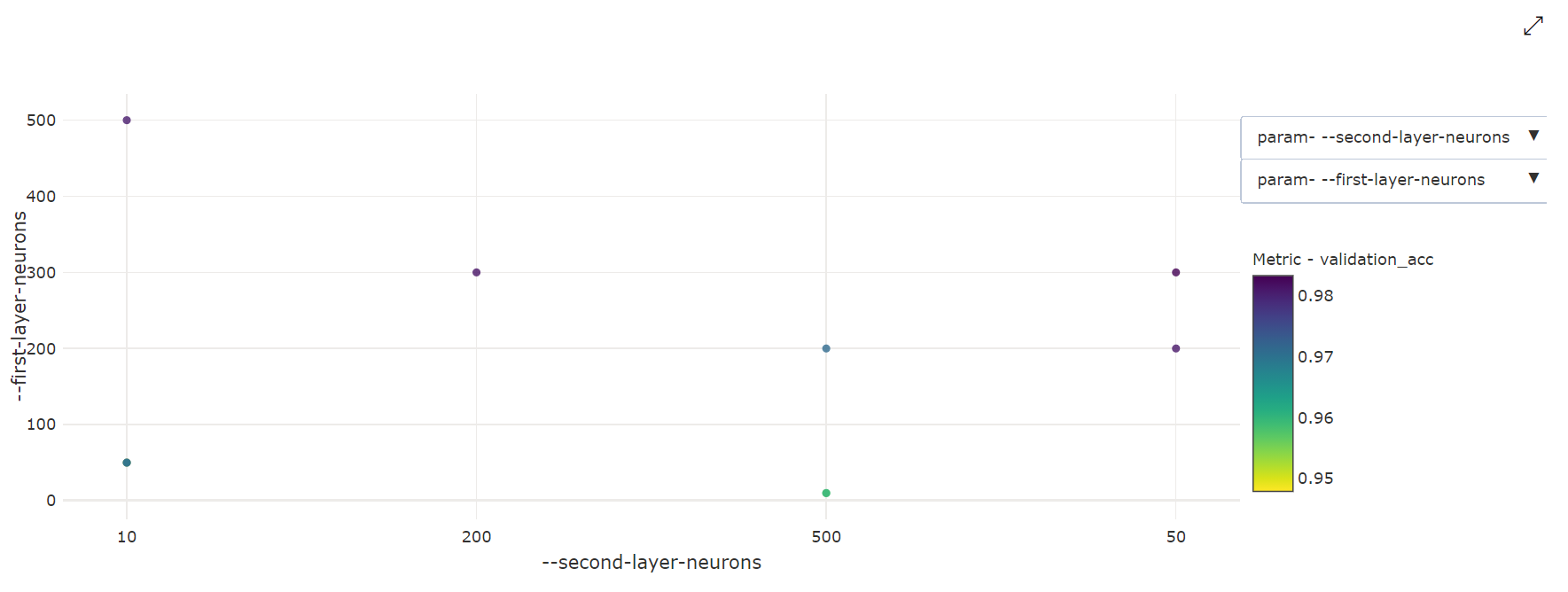
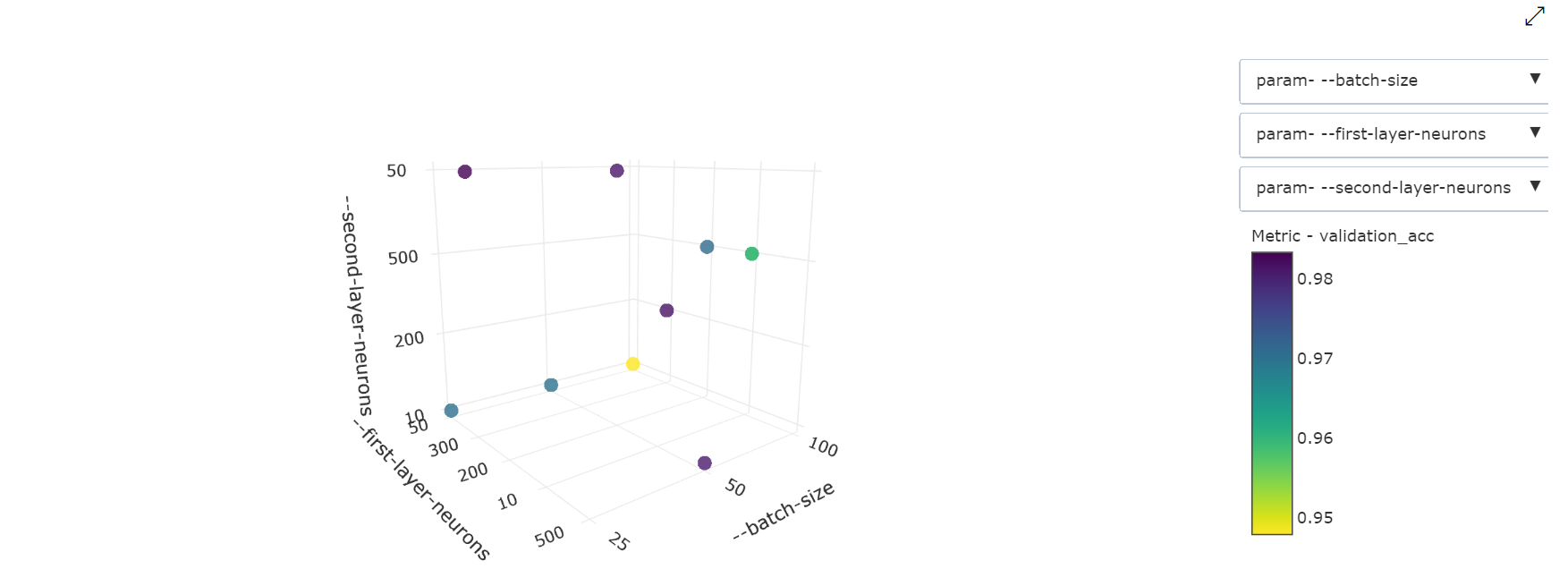
Gráfico de Dispersão 3-Dimensional: Esta visualização é a mesma que 2D, mas permite três dimensões hipermétricas de correlação com o valor métrico primário. Você também pode selecionar e arrastar para reorientar o gráfico para visualizar diferentes correlações no espaço 3D.
Encontre o melhor trabalho de avaliação
Quando todos os trabalhos de ajuste de hiperparâmetros forem concluídos, recupere suas melhores saídas de avaliação:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Você pode usar a CLI para baixar todas as saídas padrão e nomeadas do melhor trabalho de avaliação e logs do trabalho de varredura.
az ml job download --name <sweep-job> --all
Opcionalmente, para baixar apenas a melhor saída de avaliação
az ml job download --name <sweep-job> --output-name model