Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Os fluxos de avaliação são um tipo especial de fluxo de prompt que calcula métricas para avaliar quão bem os resultados de uma corrida atendem a critérios e metas específicos. Você pode criar ou personalizar fluxos de avaliação e métricas adaptadas às suas tarefas e objetivos, e usá-los para avaliar outros fluxos de prompt. Este artigo explica os fluxos de avaliação, como desenvolvê-los e personalizá-los e como usá-los em execuções em lote de fluxo de prompt para avaliar o desempenho do fluxo.
Compreender os fluxos de avaliação
Um fluxo de prompt é uma sequência de nós que processam a entrada e geram a saída. Os fluxos de avaliação também consomem entradas necessárias e produzem saídas correspondentes que geralmente são pontuações ou métricas. Os fluxos de avaliação diferem dos fluxos padrão em sua experiência de criação e uso.
Os fluxos de avaliação geralmente são executados após a execução que eles estão testando, recebendo suas saídas e usando as saídas para calcular pontuações e métricas. Métricas de log de fluxos de avaliação usando a função SDK log_metric() de fluxo de prompt.
As saídas do fluxo de avaliação são resultados que medem o desempenho do fluxo que está sendo testado. Os fluxos de avaliação podem ter um nó de agregação que calcula o desempenho geral do fluxo que está sendo testado no conjunto de dados de teste.
As próximas seções descrevem como definir entradas e saídas nos fluxos de avaliação.
Entradas
Os fluxos de avaliação calculam métricas ou pontuações para execuções em lote observando as saídas da execução que estão testando. Por exemplo, se o fluxo que está sendo testado for um fluxo QnA que gera uma resposta com base em uma pergunta, você pode nomear uma entrada de avaliação como answer. Se o fluxo que está sendo testado for um fluxo de classificação que classifica um texto em uma categoria, você pode nomear uma entrada de avaliação como category.
Você pode precisar de outras entradas como verdade básica. Por exemplo, se você quiser calcular a precisão de um fluxo de classificação, precisará fornecer a category coluna do conjunto de dados como verdade básica. Se você quiser calcular a precisão de um fluxo QnA, você precisa fornecer a answer coluna do conjunto de dados como a verdade básica. Você pode precisar de algumas outras entradas para calcular métricas, como question e context em cenários de QnA ou geração aumentada de recuperação (RAG).
Você define as entradas do fluxo de avaliação da mesma forma que define as entradas de um fluxo padrão. Por padrão, a avaliação usa o mesmo conjunto de dados que a execução que está sendo testada. No entanto, se os rótulos correspondentes ou os valores de verdade do terreno de destino estiverem em um conjunto de dados diferente, você poderá alternar facilmente para esse conjunto de dados.
Descrições de entrada
Para descrever as entradas necessárias para calcular métricas, você pode adicionar descrições. As descrições aparecem quando você mapeia as fontes de entrada em envios de execução em lote.
Para adicionar descrições para cada entrada, selecione Mostrar descrição na seção de entrada ao desenvolver seu método de avaliação e insira as descrições.

Para ocultar as descrições do formulário de entrada, selecione Ocultar descrição.

Saídas e métricas
Os outputs de uma avaliação são resultados que mostram o desempenho do fluxo que está a ser testado. A saída geralmente contém métricas, como pontuações, e também pode incluir texto para raciocínio e sugestões.
Pontuações de saída
Um fluxo de prompt processa uma linha de dados de cada vez e gera um registro de saída. Os fluxos de avaliação também podem calcular pontuações para cada linha de dados, para que você possa verificar o desempenho de um fluxo em cada ponto de dados individual.
Você pode registrar as pontuações de cada instância de dados como saídas de fluxo de avaliação especificando-as na seção de saída do fluxo de avaliação. A experiência de criação é a mesma que definir uma saída de fluxo padrão.
Você pode visualizar as pontuações individuais na guia Saídas ao selecionar Exibir saídas, da mesma forma que verifica as saídas de uma execução de lote de fluxo padrão. Você pode acrescentar essas pontuações no nível da instância à saída do fluxo testado.
Agregação e registro de métricas
O fluxo de avaliação também fornece uma avaliação geral para a corrida. Para distinguir os resultados gerais das pontuações de saída individuais, esses valores gerais de desempenho de execução são chamados de métricas.
Para calcular um valor de avaliação geral com base em pontuações individuais, marque a caixa de seleção Agregação em um nó Python em um fluxo de avaliação para transformá-lo em um nó de redução . Em seguida, o nó recebe as entradas como uma lista e as processa como um lote.

Usando a agregação, você pode calcular e processar todas as pontuações de cada saída de fluxo e calcular um resultado geral usando cada pontuação. Por exemplo, para calcular a precisão de um fluxo de classificação, você pode calcular a precisão de cada saída de pontuação e, em seguida, calcular a precisão média de todas as saídas de pontuação. Em seguida, você pode registrar a precisão média como uma métrica usando promptflow_sdk.log_metric(). As métricas devem ser numéricas, como float ou int. Não há suporte para o registro de métricas de tipo de cadeia de caracteres.
O trecho de código a seguir é um exemplo de cálculo da precisão geral pela média da pontuação grades de precisão de todos os pontos de dados. A precisão geral é registrada como uma métrica usando promptflow_sdk.log_metric().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Como você chama essa função no nó Python, não precisa atribuí-la em outro lugar e pode visualizar as métricas mais tarde. Depois de usar esse método de avaliação em uma execução em lote, você pode exibir a métrica que mostra o desempenho geral selecionando a guia Métricas ao exibir as saídas.

Desenvolver um fluxo de avaliação
Para desenvolver seu próprio fluxo de avaliação, selecione Criar na página Fluxo de prompt do estúdio do Azure Machine Learning. Na página Criar um novo fluxo, você pode:
Selecione Criar no cartão de fluxo de avaliação em Criar por tipo. Esta seleção fornece um modelo para o desenvolvimento de um novo método de avaliação.
Selecione Fluxo de avaliação na galeria Explorar e selecione um dos fluxos internos disponíveis. Selecione Exibir detalhes para obter um resumo de cada fluxo e selecione Clonar para abrir e personalizar o fluxo. O assistente de criação de fluxo ajuda você a modificar o fluxo para seu próprio cenário.

Calcular pontuações para cada ponto de dados
Os fluxos de avaliação calculam pontuações e métricas para fluxos executados em conjuntos de dados. O primeiro passo nos fluxos de avaliação é calcular as pontuações para cada saída de dados individual.
Por exemplo, no fluxo interno de Avaliação de Precisão de Classificação, o grade que mede a precisão de cada saída gerada pelo fluxo para sua verdade de solo correspondente é calculado no nó Python de grau .
Se você usar o modelo de fluxo de avaliação, calculará essa pontuação no nó line_process Python. Você também pode substituir o nó python line_process por um nó LLM (modelo de linguagem grande) para usar um LLM para calcular a pontuação ou usar vários nós para executar o cálculo.

Você especifica as saídas desse nó como as saídas do fluxo de avaliação, o que indica que as saídas são as pontuações calculadas para cada amostra de dados. Você também pode gerar raciocínio para obter mais informações, e é a mesma experiência que definir saídas em um fluxo padrão.
Calcular e registrar métricas
O próximo passo na avaliação é calcular métricas gerais para avaliar a corrida. Você calcula métricas em um nó Python que tem a opção Agregação selecionada. Esse nó recebe as pontuações do nó de cálculo anterior e as organiza em uma lista e, em seguida, calcula os valores gerais.
Se você usar o modelo de avaliação, essa pontuação será calculada no nó agregado . O trecho de código a seguir mostra o modelo para o nó de agregação.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Você pode usar sua própria lógica de agregação, como calcular a média, a mediana ou o desvio padrão da pontuação.
Registre as métricas usando a promptflow.log_metric() função. Você pode registrar várias métricas em um único fluxo de avaliação. As métricas devem ser numéricas (float/int).
Usar fluxos de avaliação
Depois de criar seu próprio fluxo de avaliação e métricas, você pode usar o fluxo para avaliar o desempenho de um fluxo padrão. Por exemplo, você pode avaliar um fluxo QnA para testar como ele funciona em um grande conjunto de dados.
No estúdio do Azure Machine Learning, abra o fluxo que você deseja avaliar e selecione Avaliar na barra de menus superior.

No assistente Batch run & Evaluation, conclua as configurações Basic e Batch run para carregar o conjunto de dados para teste e configurar o mapeamento de entrada. Para obter mais informações, consulte Enviar execução em lote e avaliar um fluxo.
Na etapa Selecionar avaliação, você pode selecionar uma ou mais de suas avaliações personalizadas ou avaliações internas para executar. A avaliação personalizada lista todos os fluxos de avaliação que você criou, clonou ou personalizou. Os fluxos de avaliação criados por outras pessoas que trabalham no mesmo projeto não aparecem nesta seção.
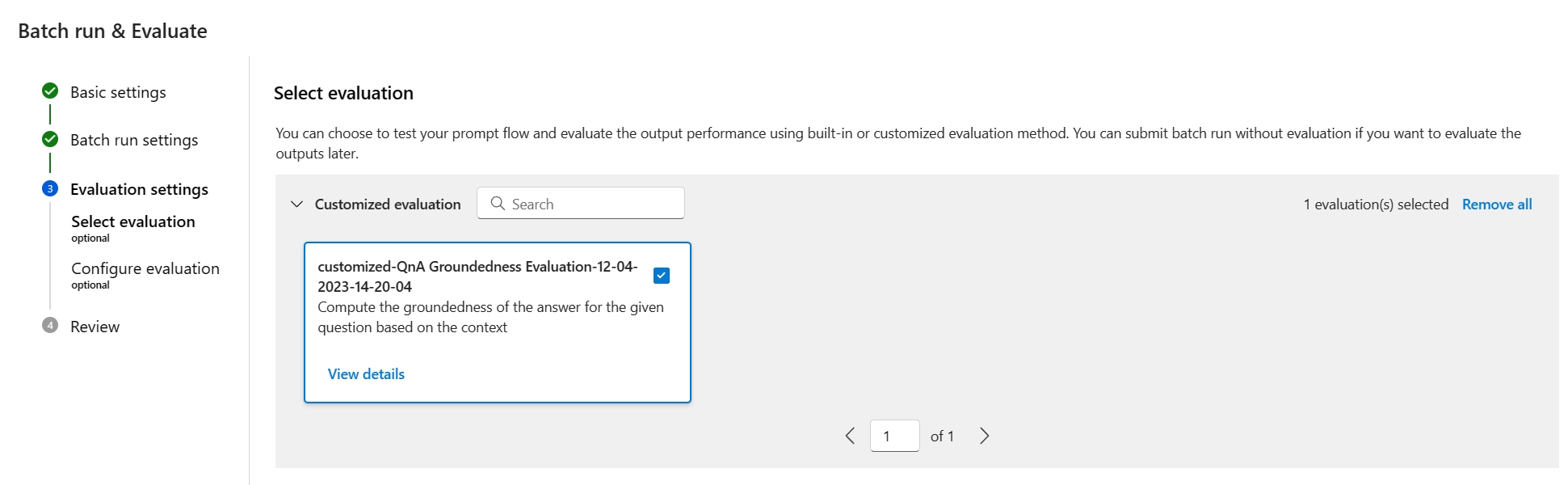
Na tela Configurar avaliação, especifique as fontes de quaisquer dados de entrada necessários para o método de avaliação. Por exemplo, a coluna verdade básica pode vir de um conjunto de dados. Se o seu método de avaliação não exigir dados de um conjunto de dados, você não precisará selecionar um conjunto de dados ou fazer referência a qualquer coluna de conjunto de dados na seção de mapeamento de entrada.
Na seção Mapeamento de entrada de avaliação, você pode indicar as fontes de entradas necessárias para a avaliação. Se a fonte de dados for da saída de execução, defina a fonte como
${run.outputs.[OutputName]}. Se os dados forem do seu conjunto de dados de teste, defina a origem como${data.[ColumnName]}. Todas as descrições definidas para as entradas de dados também aparecem aqui. Para obter mais informações, consulte Enviar execução em lote e avaliar um fluxo.
Importante
Se o fluxo de avaliação tiver um nó LLM ou exigir uma conexão para consumir credenciais ou outras chaves, você deverá inserir os dados de conexão na seção Conexão desta tela para poder usar o fluxo de avaliação.
Selecione Rever + enviar e, em seguida, selecione Enviar para executar o fluxo de avaliação.
Após a conclusão do fluxo de avaliação, você poderá ver as pontuações no nível da instância selecionando Exibir execuções>em lote Exibir saídas de execução em lote mais recentes na parte superior do fluxo avaliado. Selecione sua execução de avaliação na lista suspensa Acrescentar resultados relacionados para ver a nota de cada linha de dados.



