Tutorial: Treine seu primeiro modelo de aprendizado de máquina (SDK v1, parte 2 de 3)
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Este tutorial mostra como treinar um modelo de aprendizado de máquina no Azure Machine Learning. Este tutorial é a parte 2 de uma série de tutoriais em duas partes.
Na Parte 1: Executar "Olá mundo!" da série, você aprendeu como usar um script de controle para executar um trabalho na nuvem.
Neste tutorial, você dá o próximo passo enviando um script que treina um modelo de aprendizado de máquina. Este exemplo ajuda você a entender como o Aprendizado de Máquina do Azure facilita o comportamento consistente entre depuração local e execuções remotas.
Neste tutorial:
- Crie um script de treinamento.
- Use o Conda para definir um ambiente do Azure Machine Learning.
- Crie um script de controle.
- Compreender as classes do Azure Machine Learning (
Environment,MetricsRun, ). - Envie e execute seu script de treinamento.
- Veja a saída do seu código na nuvem.
- Registre métricas no Azure Machine Learning.
- Veja as suas métricas na nuvem.
Pré-requisitos
- Conclusão da parte 1 da série.
Criar scripts de treinamento
Primeiro, você define a arquitetura de rede neural em um arquivo model.py . Todo o seu código de treinamento vai para o src subdiretório, incluindo model.py.
O código de treinamento é retirado deste exemplo introdutório do PyTorch. Os conceitos do Azure Machine Learning aplicam-se a qualquer código de aprendizagem automática, não apenas ao PyTorch.
Crie um arquivo model.py na subpasta src . Copie este código para o arquivo:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xNa barra de ferramentas, selecione Salvar para salvar o arquivo. Feche a guia se desejar.
Em seguida, defina o script de treinamento, também na subpasta src . Este script baixa o conjunto de dados CIFAR10 usando APIs PyTorch
torchvision.dataset, configura a rede definida em model.py e treina-o para duas épocas usando SGD padrão e perda de entropia cruzada.Crie um script train.py na subpasta src :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Agora você tem a seguinte estrutura de pastas:
Teste localmente
Selecione Salvar e executar script no terminal para executar o script train.py diretamente na instância de computação.
Após a conclusão do script, selecione Atualizar acima das pastas de arquivo. Você vê a nova pasta de dados chamada get-started/data Expanda esta pasta para exibir os dados baixados.
Criar um ambiente Python
O Azure Machine Learning fornece o conceito de um ambiente para representar um ambiente Python reproduzível e versionado para executar experimentos. É fácil criar um ambiente a partir de um ambiente local de Conda ou pip.
Primeiro, você cria um arquivo com as dependências do pacote.
Crie um novo arquivo na pasta de introdução chamada
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionNa barra de ferramentas, selecione Salvar para salvar o arquivo. Feche a guia se desejar.
Criar o script de controle
A diferença entre o script de controle a seguir e aquele que você usou para enviar "Olá mundo!" é que você adiciona algumas linhas extras para definir o ambiente.
Crie um novo arquivo Python na pasta de introdução chamada run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Gorjeta
Se você usou um nome diferente quando criou seu cluster de computação, certifique-se de ajustar o nome no código compute_target='cpu-cluster' também.
Compreender as alterações de código
env = ...
Faz referência ao arquivo de dependência criado acima.
config.run_config.environment = env
Adiciona o ambiente a ScriptRunConfig.
Enviar a execução para o Azure Machine Learning
Selecione Salvar e executar script no terminal para executar o script run-pytorch.py .
Você verá um link na janela do terminal que se abre. Selecione o link para visualizar o trabalho.
Nota
Você pode ver alguns avisos começando com Falha ao carregar azureml_run_type_providers.... Você pode ignorar esses avisos. Use o link na parte inferior desses avisos para visualizar sua saída.
Ver a saída
- Na página que se abre, você vê o status do trabalho. Na primeira vez que você executa esse script, o Aprendizado de Máquina do Azure cria uma nova imagem do Docker a partir do seu ambiente PyTorch. Todo o trabalho pode levar cerca de 10 minutos para ser concluído. Esta imagem será reutilizada em trabalhos futuros para torná-los executados muito mais rapidamente.
- Você pode ver os logs de compilação do Docker no estúdio do Azure Machine Learning. Para exibir os logs de compilação:
- Selecione o separador Saídas + registos.
- Selecione a pasta azureml-logs .
- Selecione 20_image_build_log.txt.
- Quando o status do trabalho for Concluído, selecione Saída + logs.
- Selecione user_logs e, em seguida , std_log.txt para ver a saída do seu trabalho.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Se vir um erro Your total snapshot size exceeds the limit, a pasta de dados está localizada no source_directory valor utilizado em ScriptRunConfig.
Selecione o ... no final da pasta e, em seguida, selecione Mover para mover dados para a pasta de introdução .
Registrar métricas de treinamento
Agora que você tem um treinamento de modelo no Azure Machine Learning, comece a acompanhar algumas métricas de desempenho.
O script de treinamento atual imprime métricas no terminal. O Azure Machine Learning fornece um mecanismo para registrar métricas com mais funcionalidade. Ao adicionar algumas linhas de código, você ganha a capacidade de visualizar métricas no estúdio e comparar métricas entre vários trabalhos.
Modificar train.py para incluir o registro em log
Modifique o script train.py para incluir mais duas linhas de código:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Salve este arquivo e, em seguida, feche a guia, se desejar.
Compreender as duas linhas de código adicionais
No train.py, você acessa o objeto run de dentro do próprio script de treinamento usando o Run.get_context() método e o usa para registrar métricas:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
As métricas no Azure Machine Learning são:
- Organizado por experiência e execução, por isso é fácil acompanhar e comparar métricas.
- Equipado com uma interface do usuário para que você possa visualizar o desempenho do treinamento no estúdio.
- Projetado para escalar, para que você mantenha esses benefícios mesmo enquanto executa centenas de experimentos.
Atualizar o arquivo de ambiente Conda
O train.py roteiro acabou de assumir uma nova dependência do azureml.core. Atualize pytorch-env.yml para refletir esta alteração:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Certifique-se de salvar esse arquivo antes de enviar a execução.
Enviar a execução para o Azure Machine Learning
Selecione a guia para o script run-pytorch.py e, em seguida, selecione Salvar e executar script no terminal para executar novamente o script run-pytorch.py . Certifique-se de salvar suas alterações primeiro pytorch-env.yml .
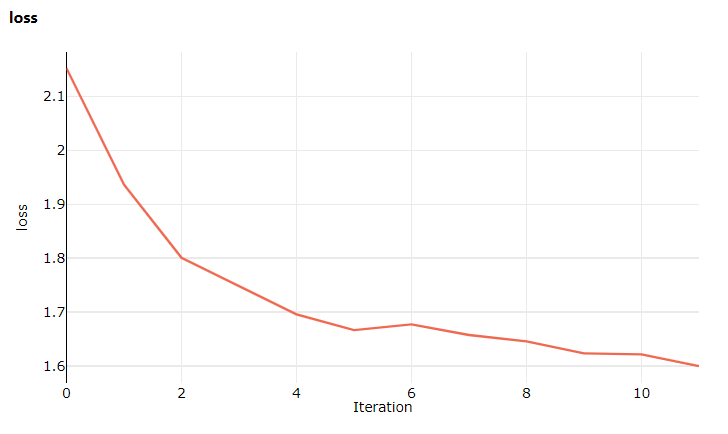
Desta vez, quando você visitar o estúdio, vá para a guia Métricas , onde agora você pode ver atualizações ao vivo sobre a perda de treinamento do modelo! Pode demorar 1 a 2 minutos antes do início do treino.
Clean up resources (Limpar recursos)
Se você planeja continuar agora para outro tutorial, ou para iniciar seus próprios trabalhos de treinamento, pule para Recursos relacionados.
Parar instância de computação
Se você não vai usá-lo agora, pare a instância de computação:
- No estúdio, à esquerda, selecione Computar.
- Nas guias superiores, selecione Instâncias de computação
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Eliminar todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.
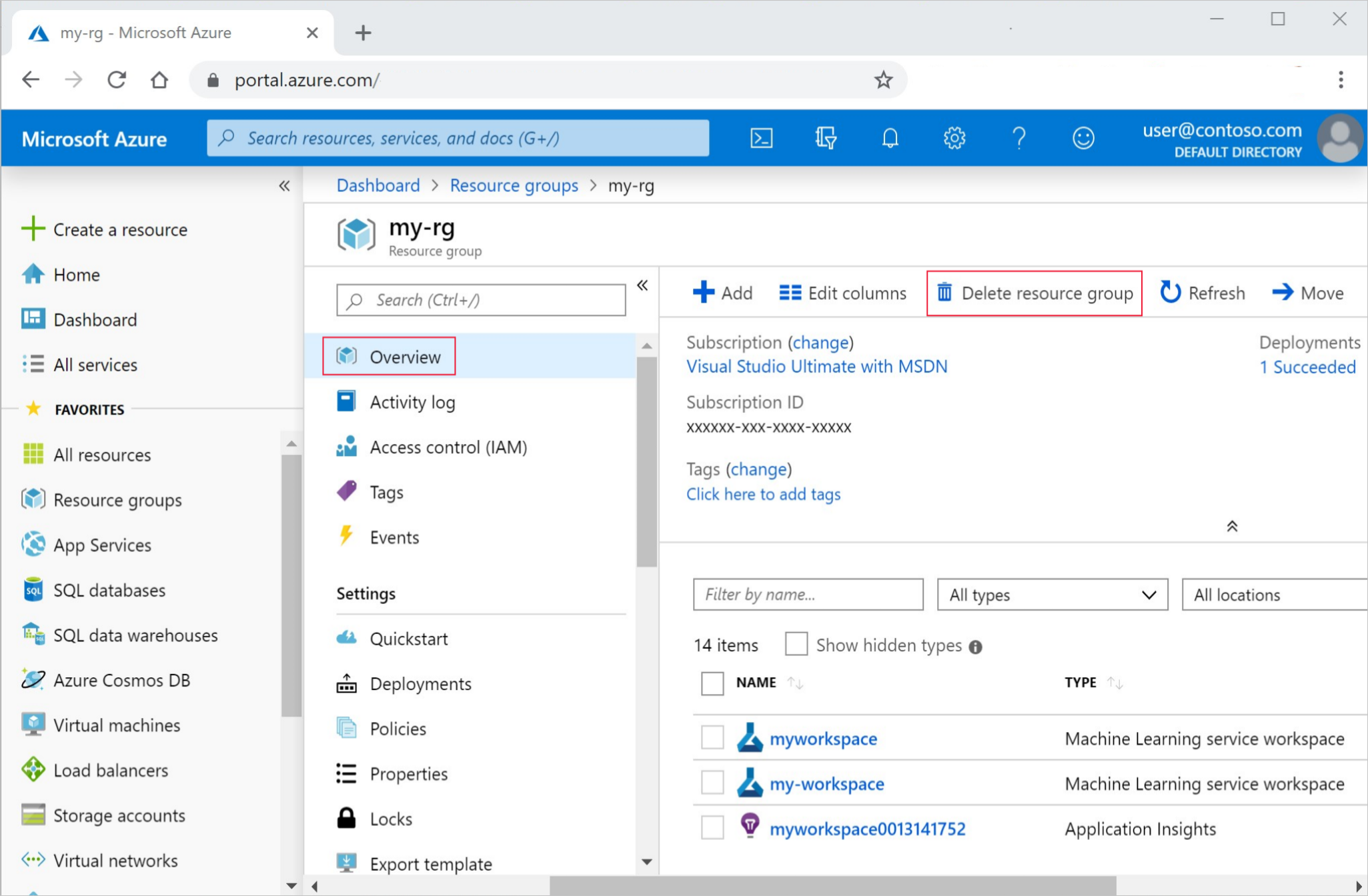
Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Você também pode manter o grupo de recursos, mas excluir um único espaço de trabalho. Exiba as propriedades do espaço de trabalho e selecione Excluir.
Recursos relacionados
Nesta sessão, você atualizou de um script básico "Hello world!" para um script de treinamento mais realista que exigia um ambiente Python específico para ser executado. Você viu como usar ambientes do Azure Machine Learning com curadoria. Finalmente, você viu como, em algumas linhas de código, você pode registrar métricas no Azure Machine Learning.
Há outras maneiras de criar ambientes do Azure Machine Learning, inclusive a partir de um arquivo pip requirements.txt ou de um ambiente Conda local existente.