Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
Este tutorial apresenta algumas das funcionalidades mais utilizadas do serviço Azure Machine Learning. Você cria, regista e implementa um modelo. Este tutorial ajuda você a se familiarizar com os principais conceitos do Azure Machine Learning e seu uso mais comum.
Neste quickstart, treina, regista e implementa um modelo de aprendizagem automática usando Azure Machine Learning — tudo a partir de um caderno Python. No final, terá um endpoint funcional que pode aceder para obter previsões.
Você aprende a:
- Executar um trabalho de formação em computação em nuvem escalável
- Registe o teu modelo treinado
- Implantar o modelo como um ponto de extremidade online
- Testar o ponto de extremidade com dados de amostra
Você cria um script de treinamento para lidar com a preparação de dados, treinar e registrar um modelo. Depois de treinares o modelo, implementas-no como endpoint e depois chamas o endpoint para inferência.
Os passos que você toma são:
- Configurar um identificador para seu espaço de trabalho do Azure Machine Learning
- Crie seu script de treinamento
- Criar um recurso de computação escalável, um cluster de computação
- Criar e executar um trabalho de comando que execute o script de treino no cluster de computação, configurado com o ambiente de trabalho apropriado
- Exibir a saída do seu script de treinamento
- Implantar o modelo recém-treinado como um ponto de extremidade
- Chamar o ponto de extremidade do Azure Machine Learning para inferência
Pré-requisitos
-
Para usar o Azure Machine Learning, você precisa de um espaço de trabalho. Se você não tiver um, conclua Criar recursos necessários para começar a criar um espaço de trabalho e saiba mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez seja necessário adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes Python. Para obter mais informações, consulte Cenário: acessar pacotes públicos de aprendizado de máquina.
-
Entre no estúdio e selecione seu espaço de trabalho se ele ainda não estiver aberto.
-
Abra ou crie um bloco de notas na sua área de trabalho:
- Se quiser copiar e colar código em células, crie um novo bloco de anotações.
- Ou abra tutoriais/get-started-notebooks/quickstart.ipynb na seção Amostras do estúdio. Em seguida, selecione Clonar para adicionar o bloco de anotações aos seus arquivos. Para localizar blocos de notas de exemplo, consulte Aprender com blocos de notas de exemplo.
Defina seu kernel e abra no Visual Studio Code (VS Code)
Na barra superior acima do bloco de anotações aberto, crie uma instância de computação se ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Aguarde até que a instância de computação esteja em execução. Em seguida, certifique-se de que o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar este kernel.
Se você não vir esse kernel, verifique se sua instância de computação está em execução. Se estiver, selecione o botão Atualizar no canto superior direito do bloco de anotações.
Se você vir um banner dizendo que precisa ser autenticado, selecione Autenticar.
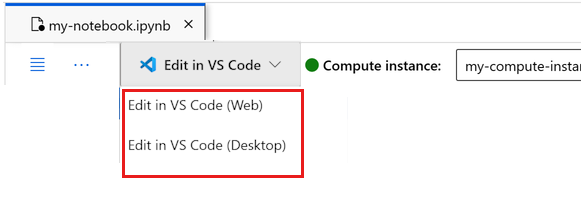
Você pode executar o bloco de anotações aqui ou abri-lo no VS Code para um ambiente de desenvolvimento integrado (IDE) completo com o poder dos recursos do Azure Machine Learning. Selecione Abrir no VS Code e, em seguida, selecione a opção Web ou desktop. Quando iniciado dessa forma, o VS Code é anexado à sua instância de computação, ao kernel e ao sistema de arquivos do espaço de trabalho.




Importante
O restante deste tutorial contém células do bloco de anotações do tutorial. Copie-os e cole-os no seu novo bloco de notas ou mude para o bloco de notas agora se o tiver clonado.
Criar identificador para espaço de trabalho
Antes de mergulhar no código, você precisa de uma maneira de fazer referência ao seu espaço de trabalho. A área de trabalho é o recurso de nível superior do Azure Machine Learning que proporciona um local centralizado para trabalhar com todos os artefactos que cria quando utiliza o Azure Machine Learning.
Crie ml_client como um handle para o seu espaço de trabalho — este cliente gere todos os seus recursos e tarefas.
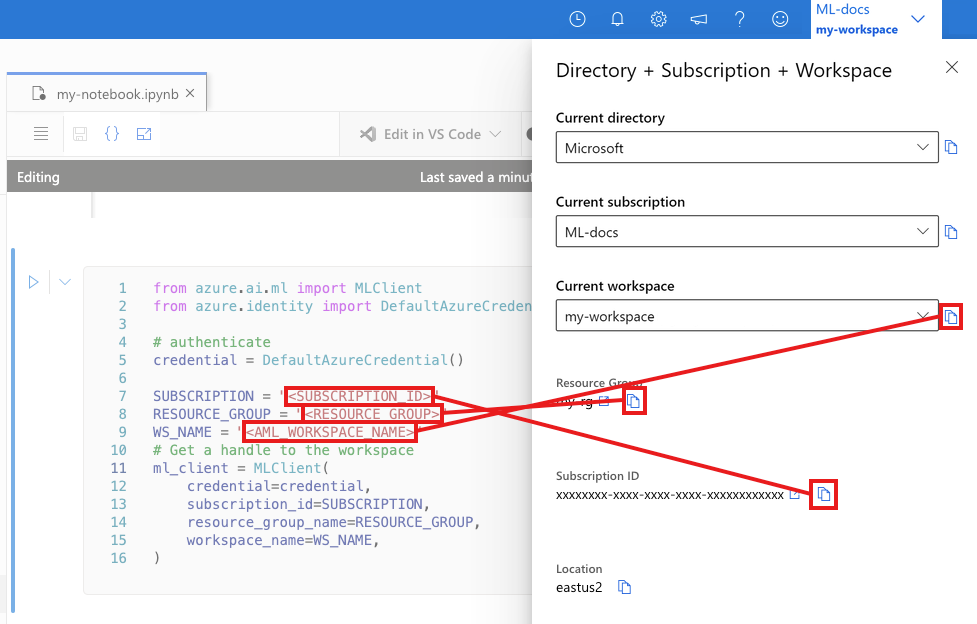
Na célula seguinte, introduza o ID da Subscrição, o nome do Grupo de Recursos e o nome da Área de Trabalho. Para encontrar estes valores:
- Na barra de ferramentas do estúdio do Azure Machine Learning no canto superior direito, selecione o nome do seu espaço de trabalho.
- Copie o valor para espaço de trabalho, grupo de recursos e ID de assinatura para o código.
- Copia um valor, fecha a área e cola-o. Depois volta para o próximo valor.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
A criação do MLClient não estabelece ligação ao espaço de trabalho. A inicialização do cliente é preguiçosa. Espera até à primeira vez que precisa de fazer uma chamada. Esta ação acontece na célula de código seguinte.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Criar script de treinamento
Cria o script de treino, que é o ficheiro Python main.py .
Primeiro, crie uma pasta de origem para o script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Este script pré-processa os dados e divide-os em conjuntos de dados de teste e treino. Treina um modelo baseado em árvore usando estes dados e devolve o modelo de saída.
Durante a execução do pipeline, utilize o MLFlow para registrar os parâmetros e métricas.
A célula seguinte usa magia IPython para escrever o script de treino no diretório que acabou de criar.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Quando o modelo é treinado, o script guarda e regista o ficheiro do modelo no espaço de trabalho. Pode usar o modelo registado para inferir endpoints.
Talvez seja necessário selecionar Atualizar para ver a nova pasta e o novo script em seus arquivos.
Configurar o comando
Agora tens um script que pode executar as tarefas desejadas e um cluster de computação para executar o script. Usa um comando de uso geral que possa executar ações na linha de comandos. Esta ação de linha de comando pode chamar diretamente comandos do sistema ou executar um script.
Crie variáveis de entrada para especificar os dados de entrada, razão de divisão, taxa de aprendizagem e nome registado do modelo. O script de comando:
- Utiliza um ambiente que define o software e as bibliotecas de tempo de execução necessárias para o script de treinamento. O Azure Machine Learning fornece muitos ambientes selecionados ou prontos, que são úteis para cenários comuns de treinamento e inferência. Você usa um desses ambientes aqui. Em Tutorial: Treinar um modelo no Azure Machine Learning, você aprenderá a criar um ambiente personalizado.
- Configura a própria ação da linha de comandos –
python main.pyneste caso. As entradas e saídas são acessíveis no comando através da${{ ... }}notação. - Acede aos dados a partir de um ficheiro na internet.
- Como não especificaste um recurso de computação, o script corre num cluster de computação serverless que é criado automaticamente.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
Submeter o trabalho
Submeta o trabalho para correr no Azure Machine Learning. Desta vez, use create_or_update em ml_client.
ml_client.create_or_update(job)
Visualize a saída do trabalho e aguarde a conclusão do trabalho
Exiba o trabalho no estúdio do Azure Machine Learning selecionando o link na saída da célula anterior.
A saída deste trabalho tem esta aparência no estúdio do Azure Machine Learning. Explore as abas para ver vários detalhes, como métricas, resultados e muito mais. Uma vez concluído, o trabalho regista um modelo no seu espaço de trabalho como resultado do treinamento.
Importante
Espere até que o estado do trabalho mostre Concluído antes de continuar — normalmente 2-3 minutos. Se o cluster de computação escalar para zero, espere até 10 minutos enquanto se abastece.
Enquanto espera, explore os detalhes do trabalho no estúdio:
- Aba de Métricas: Visualizar métricas de treino registadas pelo MLflow
- Aba de saídas e registos: Verifique os registos de treino
- Modelos : Veja o modelo registado (após a conclusão do registo)
Implantar o modelo como um ponto de extremidade online
Implemente o seu modelo de aprendizagem automática como um serviço web na cloud Azure usando um online endpoint.
Para implementar um serviço de aprendizagem automática, use o modelo que registou.
Criar um novo ponto de extremidade online
Agora que registaste um modelo, cria o teu endpoint online. O nome do ponto de extremidade precisa ser exclusivo em toda a região do Azure. Para este tutorial, crie um nome único usando UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Cria o endpoint.
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Nota
Espere que a criação do ponto de extremidade demore alguns minutos.
Após criar o endpoint, recupere-o conforme mostrado no seguinte código:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Implantar o modelo no ponto de extremidade
Depois de criares o endpoint, implementa o modelo usando o script de entrada. Cada ponto de extremidade pode ter várias implantações. Pode especificar regras para direcionar o tráfego para estas implementações. Neste exemplo, cria-se uma única implementação que gere 100% do tráfego recebido. Escolha um nome de cor para a implantação, como azul, verde ou vermelho. A escolha é arbitrária.
Para encontrar a versão mais recente do seu modelo registado, consulte a página de Modelos no Azure Machine Learning Studio. Em alternativa, use o seguinte código para obter o número de versão mais recente.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Implante a versão mais recente do modelo.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Nota
Espere que essa implantação demore aproximadamente 6 a 8 minutos.
Quando a implantação terminar, está pronto para testá-la.
Teste com uma consulta de exemplo
Depois de implantares o modelo no endpoint, executa inferência usando o modelo.
Crie um ficheiro de pedido de exemplo que siga o design esperado no método run do script de pontuação.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Clean up resources (Limpar recursos)
Se não precisares do endpoint, apaga-o para deixares de usar o recurso. Certifica-te de que nenhuma outra implementação usa um endpoint antes de o apagar.
Nota
Espere que a exclusão completa demore aproximadamente 20 minutos.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Parar instância de computação
Se não precisar agora, pare a instância de computação:
- No estúdio, no painel esquerdo, selecione Computar.
- Nas guias superiores, selecione Instâncias de computação.
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Eliminar todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.
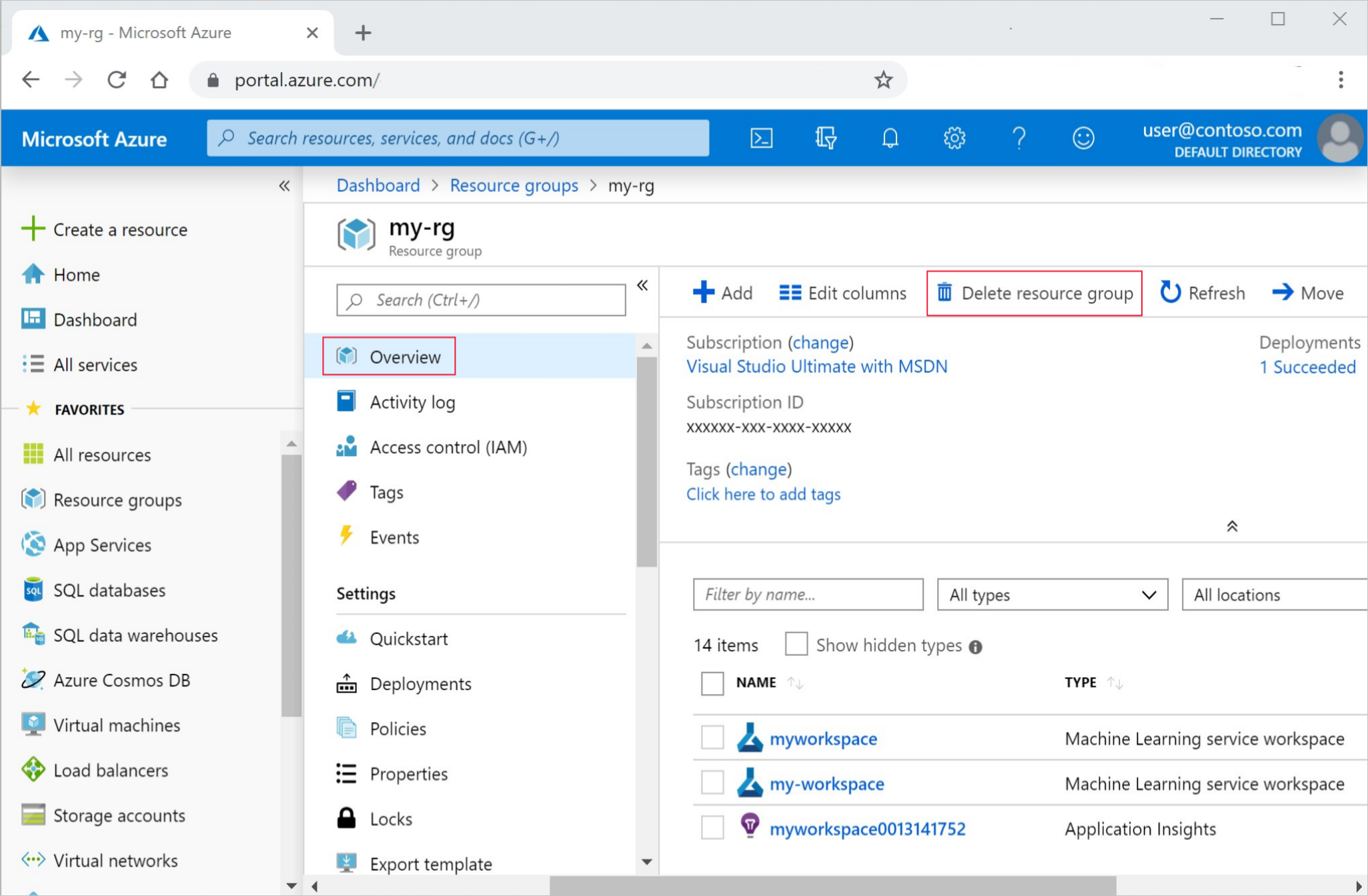
Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Próximos passos
Explore mais formas de construir com Azure Machine Learning:
| Guia de Aprendizagem | Descrição |
|---|---|
| Carregue, aceda e explore os seus dados | Armazene grandes volumes de dados na cloud e acede-os a partir dos cadernos |
| Desenvolvimento de modelos em uma estação de trabalho na nuvem | Prototipar e desenvolver modelos de forma interativa |
| Implantar um modelo como um ponto de extremidade online | Aprenda configurações avançadas de implantação |
| Criar cadeias de produção | Construir fluxos de trabalho de ML automatizados e reutilizáveis |