Tutorial: Estruturador – preparar um modelo de regressão "no-code"
Treine um modelo de regressão linear que prevê os preços dos carros usando o designer do Azure Machine Learning. Este tutorial é a primeira parte de uma série composta por duas partes.
Este tutorial usa o designer do Azure Machine Learning, para obter mais informações, consulte O que é o designer do Azure Machine Learning?
Nota
O Designer suporta dois tipos de componentes, componentes pré-construídos clássicos (v1) e componentes personalizados (v2). Estes dois tipos de componentes NÃO são compatíveis.
Os componentes pré-construídos clássicos fornecem componentes pré-construídos principalmente para processamento de dados e tarefas tradicionais de aprendizado de máquina, como regressão e classificação. Este tipo de componente continua a ser suportado, mas não terá novos componentes adicionados.
Os componentes personalizados permitem que você envolva seu próprio código como um componente. Ele suporta o compartilhamento de componentes entre espaços de trabalho e a criação contínua nas interfaces Studio, CLI v2 e SDK v2.
Para novos projetos, sugerimos que você use o componente personalizado, que é compatível com o AzureML V2 e continuará recebendo novas atualizações.
Este artigo se aplica a componentes pré-criados clássicos e não são compatíveis com CLI v2 e SDK v2.
Na primeira parte do tutorial, você aprenderá a:
- Criar um novo pipeline.
- Import data.
- Prepare os dados.
- Treine um modelo de aprendizado de máquina.
- Avalie um modelo de aprendizado de máquina.
Na segunda parte do tutorial, você implanta seu modelo como um ponto de extremidade de inferência em tempo real para prever o preço de qualquer carro com base nas especificações técnicas enviadas.
Nota
Uma versão completa deste tutorial está disponível como um pipeline de exemplo.
Para encontrá-lo, vá para o designer em seu espaço de trabalho. Na seção Novo pipeline, selecione Amostra 1 - Regressão: Previsão de preço do automóvel (básico).
Importante
Se você não vir elementos gráficos mencionados neste documento, como botões no estúdio ou designer, talvez não tenha o nível correto de permissões para o espaço de trabalho. Entre em contato com o administrador da assinatura do Azure para verificar se você recebeu o nível correto de acesso. Para obter mais informações, veja Gerir utilizadores e funções.
Criar um novo pipeline
Os pipelines do Azure Machine Learning organizam várias etapas de aprendizado de máquina e processamento de dados em um único recurso. Os pipelines permitem organizar, gerenciar e reutilizar fluxos de trabalho complexos de aprendizado de máquina entre projetos e usuários.
Para criar um pipeline do Azure Machine Learning, você precisa de um espaço de trabalho do Azure Machine Learning. Nesta seção, você aprenderá a criar esses dois recursos.
Criar uma nova área de trabalho
Você precisa de um espaço de trabalho do Azure Machine Learning para usar o designer. O espaço de trabalho é o recurso de nível superior para o Azure Machine Learning, ele fornece um local centralizado para trabalhar com todos os artefatos que você cria no Azure Machine Learning. Para obter instruções sobre como criar um espaço de trabalho, consulte Criar recursos de espaço de trabalho.
Nota
Se seu espaço de trabalho usa uma rede virtual, há etapas de configuração adicionais que você deve usar para usar o designer. Para obter mais informações, consulte Usar o estúdio do Azure Machine Learning em uma rede virtual do Azure
Criar o pipeline
Nota
O Designer suporta dois tipos de componentes, componentes pré-construídos clássicos e componentes personalizados. Estes dois tipos de componentes não são compatíveis.
Os componentes pré-construídos clássicos fornecem componentes pré-construídos principalmente para processamento de dados e tarefas tradicionais de aprendizado de máquina, como regressão e classificação. Este tipo de componente continua a ser suportado, mas não terá novos componentes adicionados.
Os componentes personalizados permitem que você forneça seu próprio código como um componente. Suportam a partilha entre áreas de trabalho e a criação totalmente fácil transversalmente nas interfaces do Studio, da CLI e do SDK.
Este artigo aplica-se a componentes pré-construídos clássicos.
Entre no ml.azure.com e selecione o espaço de trabalho com o qual deseja trabalhar.
Selecione Designer -Classic pré-construído>
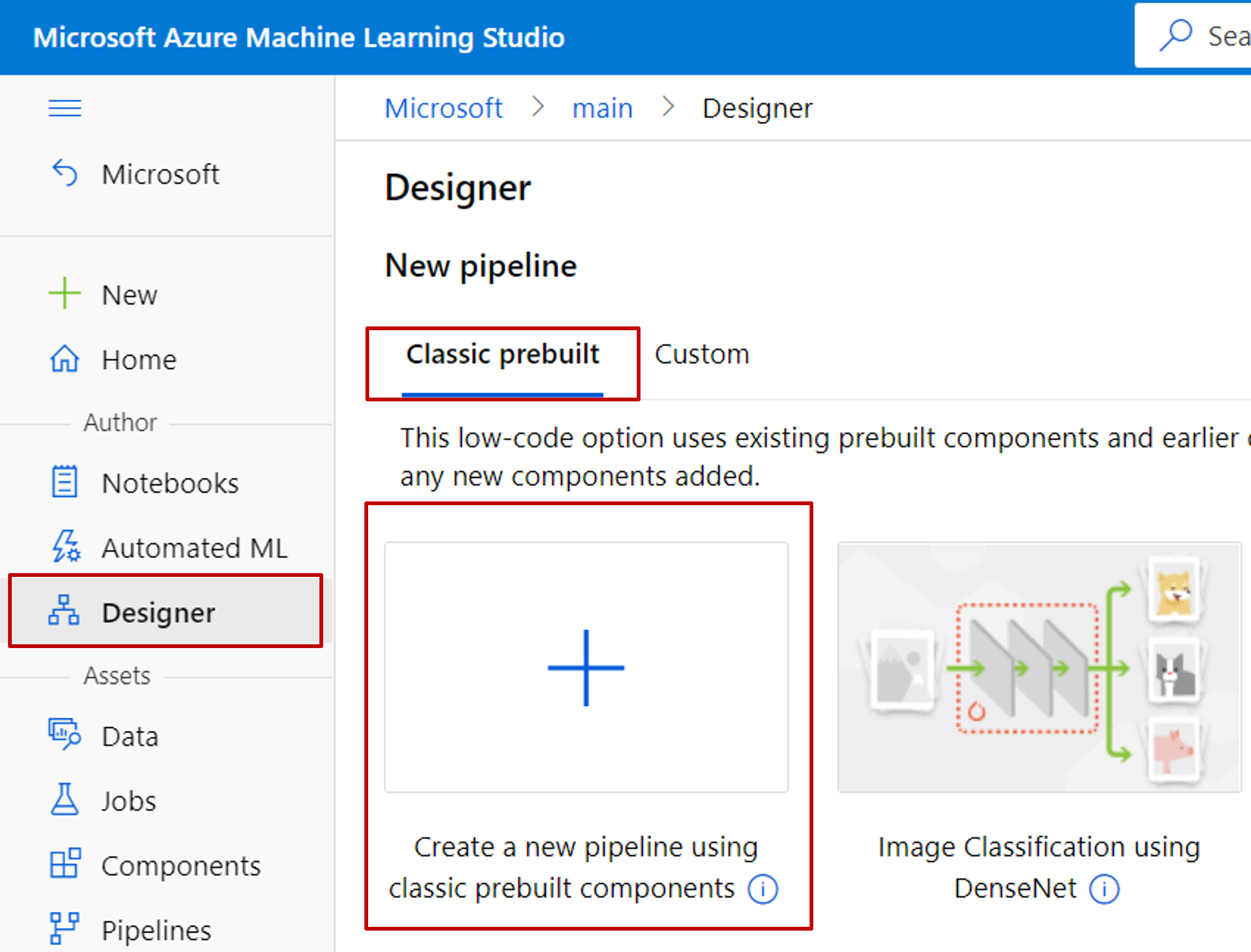
Selecione Criar um novo pipeline usando componentes pré-construídos clássicos.
Clique no ícone de lápis ao lado do nome de rascunho do pipeline gerado automaticamente, renomeie-o para Previsão de preço do automóvel. O nome não tem de ser exclusivo.
Importar dados
Há vários conjuntos de dados de exemplo incluídos no designer para você experimentar. Para este tutorial, use Dados de preço do automóvel (Raw).
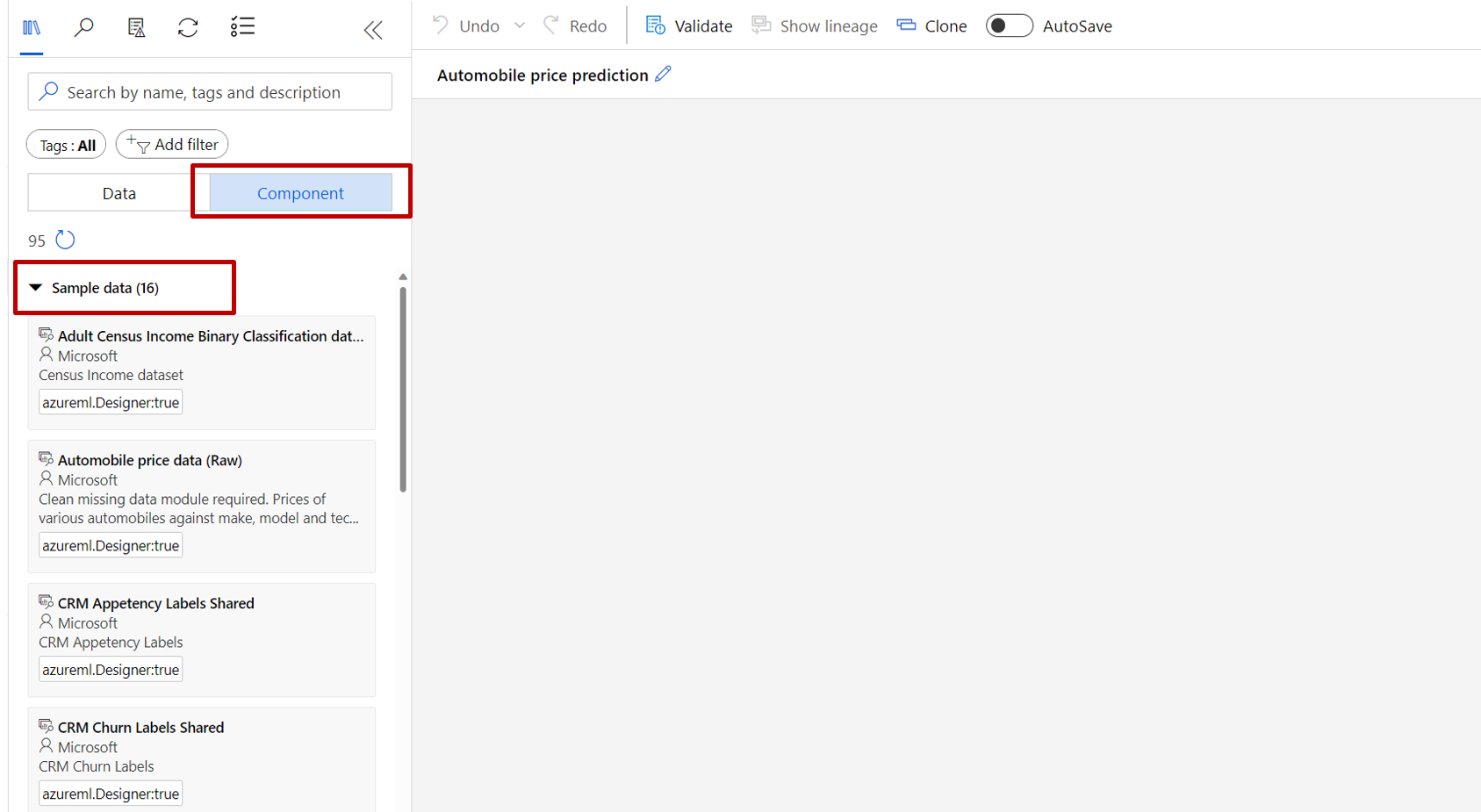
À esquerda da tela do pipeline está uma paleta de conjuntos de dados e componentes. Selecione Componente ->Dados de exemplo.
Selecione o conjunto de dados Dados de preço do automóvel (Raw) e arraste-o para a tela.
Ver os dados
Você pode visualizar os dados para entender o conjunto de dados que usará.
Clique com o botão direito do mouse nos dados de preço do automóvel (bruto) e selecione Visualizar dados.
Selecione as diferentes colunas na janela de dados para visualizar informações sobre cada uma delas.
Cada linha representa um automóvel e as variáveis associadas a cada automóvel aparecem como colunas. Há 205 linhas e 26 colunas neste conjunto de dados.
Preparar dados
Os conjuntos de dados normalmente requerem algum pré-processamento antes da análise. Você pode ter notado alguns valores ausentes quando inspecionou o conjunto de dados. Esses valores ausentes devem ser limpos para que o modelo possa analisar os dados corretamente.
Remover uma coluna
Quando você treina um modelo, você tem que fazer algo sobre os dados que estão faltando. Neste conjunto de dados, a coluna de perdas normalizadas está faltando muitos valores, portanto, você excluirá essa coluna do modelo completamente.
Na paleta de conjuntos de dados e componentes à esquerda da tela, clique em Componente e procure o componente Selecionar Colunas no Conjunto de Dados.
Arraste o componente Selecionar colunas no conjunto de dados para a tela. Solte o componente abaixo do componente do conjunto de dados.
Conecte o conjunto de dados de preço do automóvel (bruto) ao componente Selecionar colunas no conjunto de dados. Arraste da porta de saída do conjunto de dados, que é o pequeno círculo na parte inferior do conjunto de dados na tela, para a porta de entrada de Selecionar Colunas no Conjunto de Dados, que é o pequeno círculo na parte superior do componente.
Gorjeta
Você cria um fluxo de dados através do pipeline quando conecta a porta de saída de um componente a uma porta de entrada de outro.
Selecione o componente Selecionar colunas no conjunto de dados.
Clique no ícone de seta em Configurações à direita da tela para abrir o painel de detalhes do componente. Como alternativa, você pode clicar duas vezes no componente Selecionar colunas no conjunto de dados para abrir o painel de detalhes.
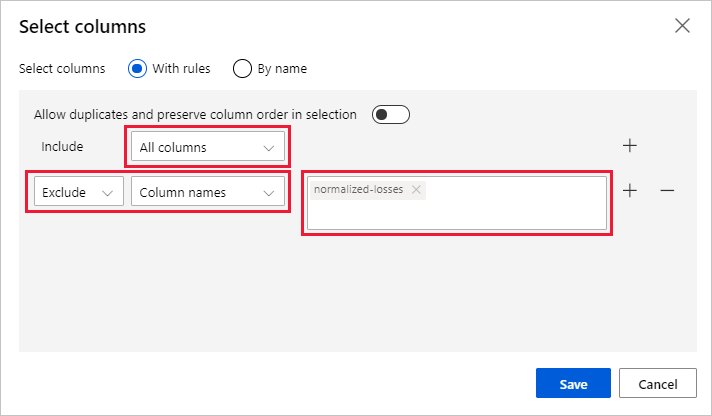
Selecione Editar coluna à direita do painel.
Expanda a lista suspensa Nomes de colunas ao lado de Incluir e selecione Todas as colunas.
Selecione a + opção para adicionar uma nova regra.
Nos menus suspensos, selecione Excluir e Nomes de coluna.
Insira perdas normalizadas na caixa de texto.
No canto inferior direito, selecione Salvar para fechar o seletor de coluna.
No painel de detalhes do componente Selecionar Colunas no Conjunto de Dados, expanda Informações do Nó.
Selecione a caixa de texto Comentário e digite Excluir perdas normalizadas.
Os comentários aparecerão no gráfico para ajudá-lo a organizar seu pipeline.
Limpar dados em falta
Seu conjunto de dados ainda tem valores ausentes depois que você remove a coluna de perdas normalizadas . Você pode remover os dados ausentes restantes usando o componente Limpar dados ausentes.
Gorjeta
Limpar os valores ausentes dos dados de entrada é um pré-requisito para usar a maioria dos componentes no designer.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Limpar Dados Ausentes.
Arraste o componente Limpar dados ausentes para a tela do pipeline. Conecte-o ao componente Selecionar colunas no conjunto de dados.
Selecione o componente Limpar dados ausentes.
Clique no ícone de seta em Configurações à direita da tela para abrir o painel de detalhes do componente. Como alternativa, você pode clicar duas vezes no componente Limpar dados ausentes para abrir o painel de detalhes.
Selecione Editar coluna à direita do painel.
Na janela Colunas a serem limpas exibida, expanda o menu suspenso ao lado de Incluir. Selecionar, Todas as colunas
Selecione Guardar
No painel de detalhes do componente Limpar Dados Ausentes, em Modo de limpeza, selecione Remover linha inteira.
No painel de detalhes do componente Limpar Dados Ausentes, expanda Informações do Nó.
Selecione a caixa de texto Comentário e digite Remover linhas de valor ausentes.
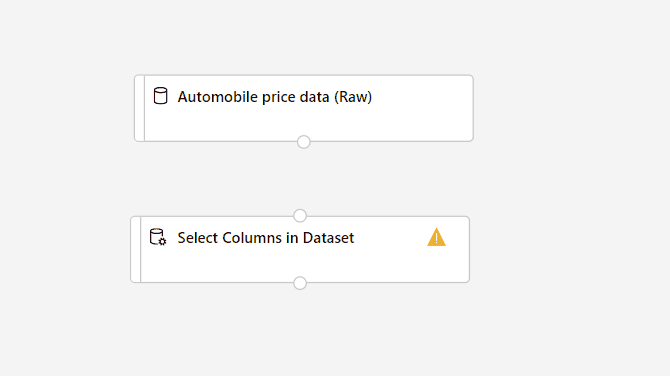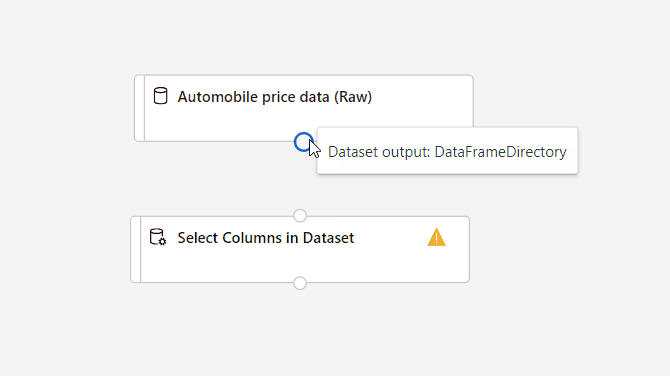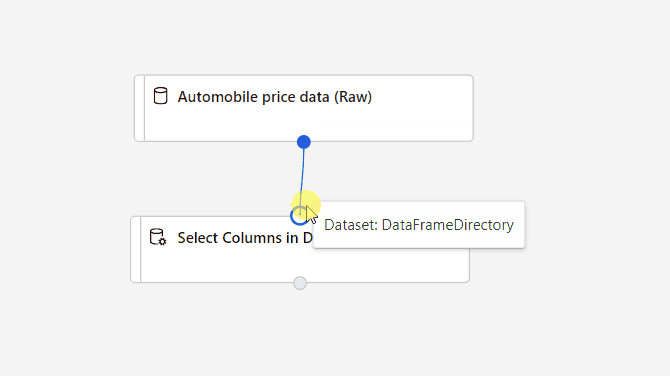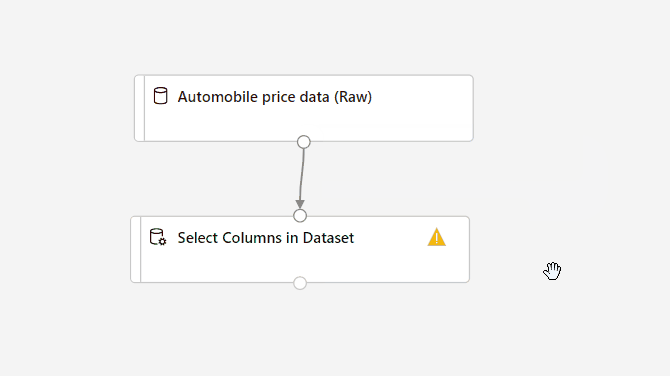
Seu pipeline agora deve ter esta aparência:
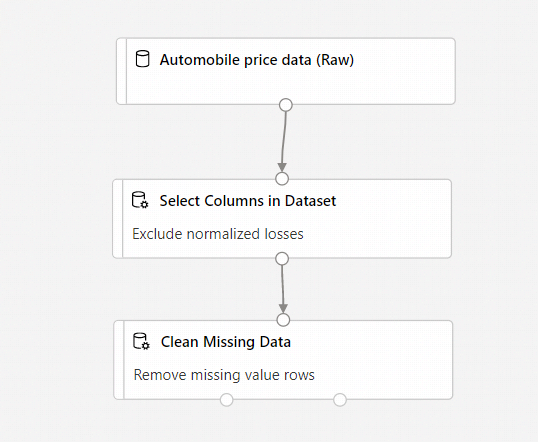
Preparar um modelo de machine learning
Agora que você tem os componentes no lugar para processar os dados, você pode configurar os componentes de treinamento.
Como você deseja prever o preço, que é um número, você pode usar um algoritmo de regressão. Para este exemplo, você usa um modelo de regressão linear.
Dividir os dados
Dividir dados é uma tarefa comum no aprendizado de máquina. Você dividirá seus dados em dois conjuntos de dados separados. Um conjunto de dados treina o modelo e o outro testará o desempenho do modelo.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Dados Divididos .
Arraste o componente Dados Divididos para a tela do pipeline.
Conecte a porta esquerda do componente Limpar dados ausentes ao componente Dados divididos .
Importante
Certifique-se de que a porta de saída esquerda de Limpar Dados Ausentes se conecta a Dados Divididos. A porta esquerda contém os dados limpos. A porta direita contém os dados descartados.
Selecione o componente Dividir dados .
Clique no ícone de seta em Configurações à direita da tela para abrir o painel de detalhes do componente. Como alternativa, você pode clicar duas vezes no componente Dados divididos para abrir o painel de detalhes.
No painel de detalhes DadosDivididos, defina a Fração de linhas no primeiro conjunto de dados de saída como 0,7.
Essa opção divide 70% dos dados para treinar o modelo e 30% para testá-lo. O conjunto de dados de 70% será acessível através da porta de saída esquerda. Os dados restantes estão disponíveis através da porta de saída correta.
No painel de detalhes Dados Divididos, expanda Informações do Nó.
Selecione a caixa de texto Comentário e digite Dividir o conjunto de dados em conjunto de treinamento (0,7) e conjunto de teste (0,3).
Preparar o modelo
Treine o modelo dando-lhe um conjunto de dados que inclua o preço. O algoritmo constrói um modelo que explica a relação entre os recursos e o preço conforme apresentado pelos dados de treinamento.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Regressão Linear .
Arraste o componente Regressão Linear para a tela do pipeline.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Modelo de Trem.
Arraste o componente Train Model para a tela do pipeline.
Conecte a saída do componente Regressão Linear à entrada esquerda do componente Modelo de Trem.
Conecte a saída de dados de treinamento (porta esquerda) do componente Split Data à entrada direita do componente Train Model.
Importante
Certifique-se de que a porta de saída esquerda de Split Data se conecta ao Train Model. A porta esquerda contém o conjunto de treinamento. A porta direita contém o conjunto de teste.
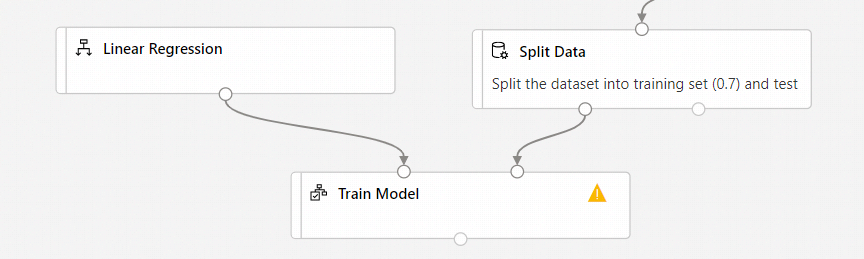
Selecione o componente Modelo de trem.
Clique no ícone de seta em Configurações à direita da tela para abrir o painel de detalhes do componente. Como alternativa, você pode clicar duas vezes no componente Modelo de trem para abrir o painel de detalhes.
Selecione Editar coluna à direita do painel.
Na janela Coluna do rótulo exibida, expanda o menu suspenso e selecione Nomes das colunas.
Na caixa de texto, insira o preço para especificar o valor que seu modelo vai prever.
Importante
Certifique-se de inserir o nome da coluna exatamente. Não capitalize o preço.
Seu pipeline deve ter esta aparência:
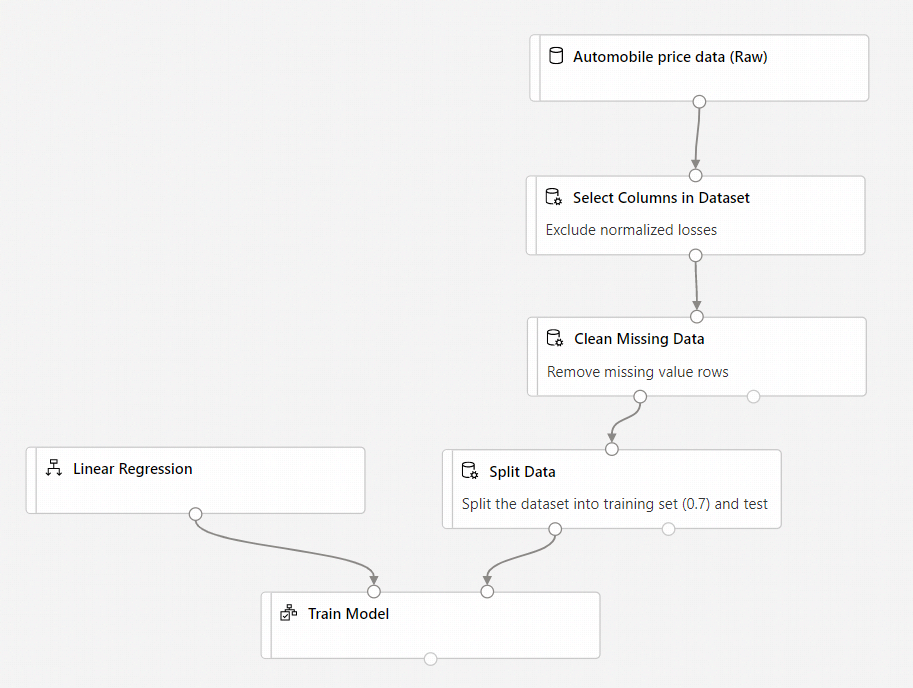
Adicionar o componente Modelo de pontuação
Depois de treinar seu modelo usando 70% dos dados, você pode usá-lo para pontuar os outros 30% para ver como seu modelo funciona.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Modelo de pontuação.
Arraste o componente Modelo de pontuação para a tela do pipeline.
Conecte a saída do componente Train Model à porta de entrada esquerda do Score Model. Conecte a saída de dados de teste (porta direita) do componente Split Data à porta de entrada direita do Score Model.
Adicionar o componente Avaliar modelo
Use o componente Avaliar modelo para avaliar o quão bem seu modelo pontuou o conjunto de dados de teste.
Nos conjuntos de dados e na paleta de componentes à esquerda da tela, clique em Componente e procure o componente Avaliar modelo .
Arraste o componente Avaliar modelo para a tela do pipeline.
Conecte a saída do componente Modelo de pontuação à entrada esquerda de Avaliar modelo.
O pipeline final deve ter esta aparência:
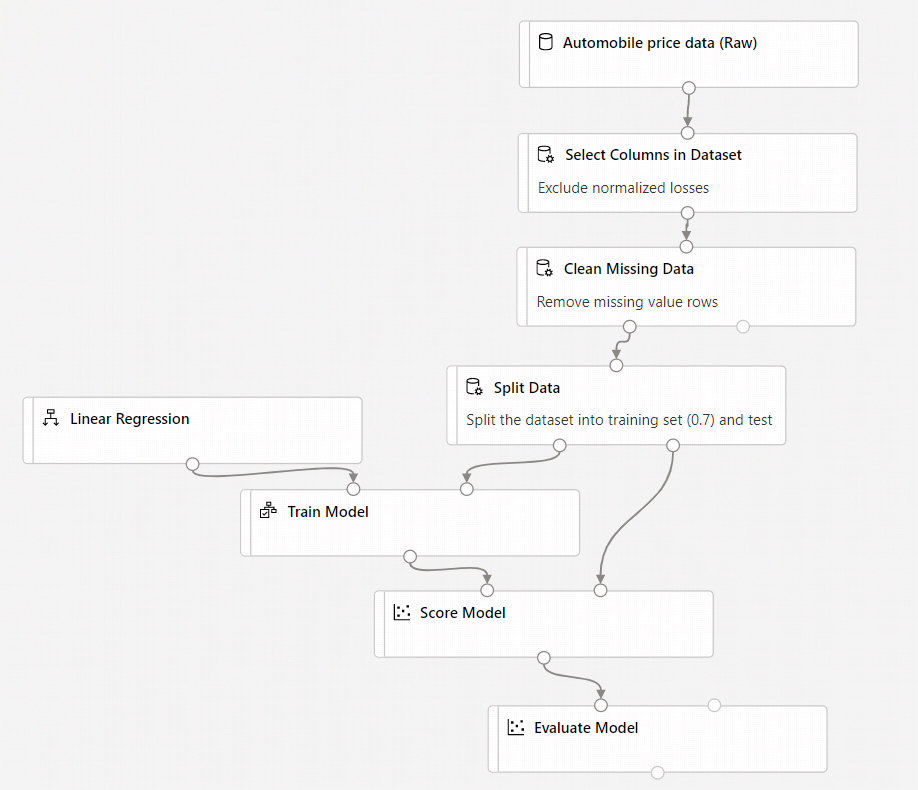
Enviar pipeline
Selecione Configurar & Enviar no canto superior direito para enviar o pipeline.

Em seguida, você verá um assistente passo a passo, siga o assistente para enviar o trabalho de pipeline.
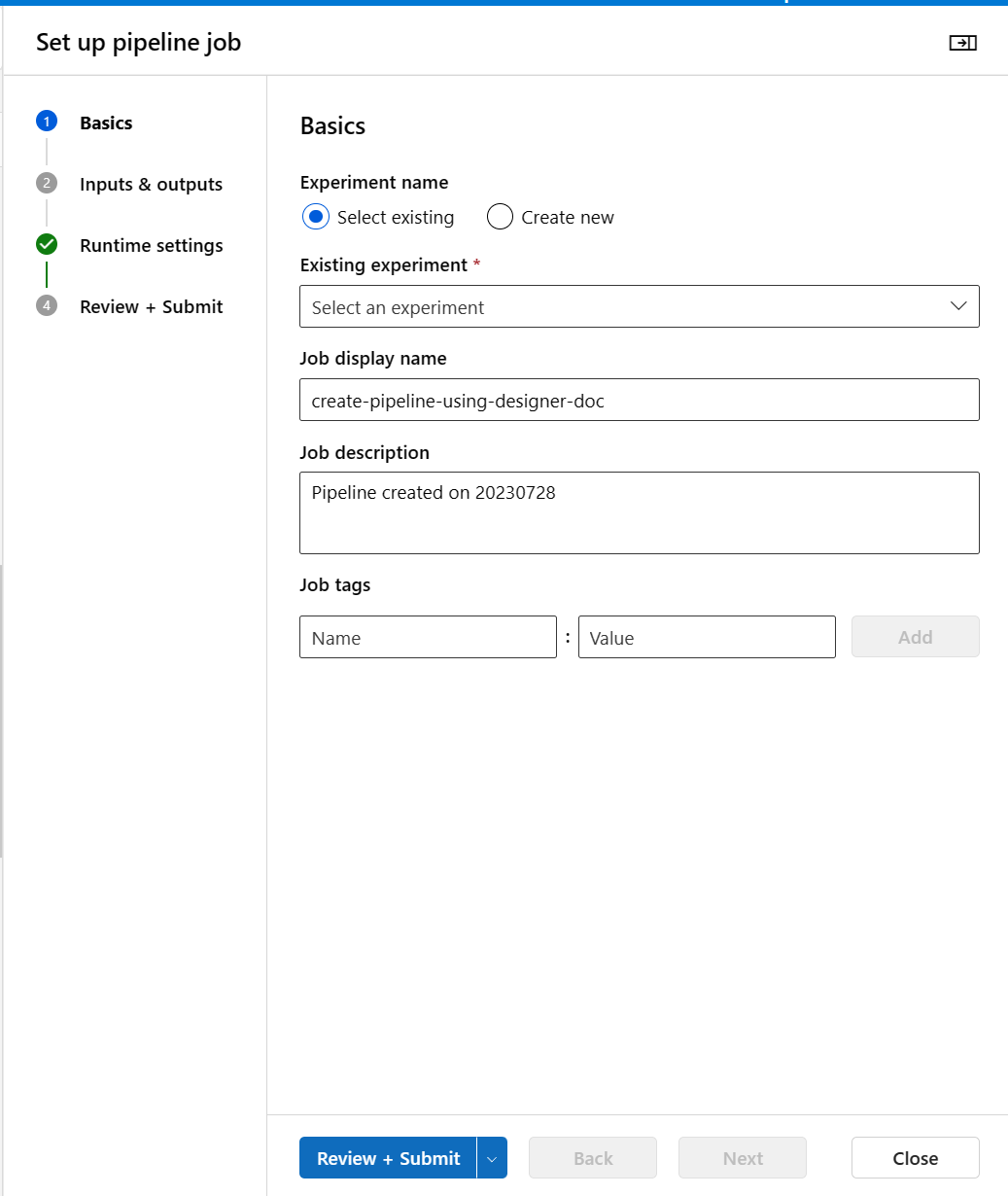

Na etapa Noções básicas, você pode configurar o experimento, o nome de exibição do trabalho, a descrição do trabalho, etc.
Na etapa Inputs & Outputs, você pode atribuir valor às Entradas/Saídas que são promovidas para o nível de pipeline. Neste exemplo, ele estará vazio porque não promovemos nenhuma entrada/saída para o nível do pipeline.
Nas configurações de tempo de execução, você pode configurar o armazenamento de dados padrão e a computação padrão para o pipeline. É o armazenamento de dados/computação padrão para todos os componentes no pipeline. No entanto, se você definir uma computação ou armazenamento de dados diferente para um componente explicitamente, o sistema respeitará a configuração de nível de componente. Caso contrário, ele usa o padrão.
A etapa Revisar + Enviar é a última etapa para revisar todas as configurações antes de enviar. O assistente lembrará sua última configuração se você enviar o pipeline.
Depois de enviar o trabalho de pipeline, haverá uma mensagem na parte superior com um link para os detalhes do trabalho. Você pode selecionar este link para revisar os detalhes da vaga.

Ver etiquetas pontuadas
Na página de detalhes do trabalho, você pode verificar o status do trabalho de pipeline, os resultados e os logs.
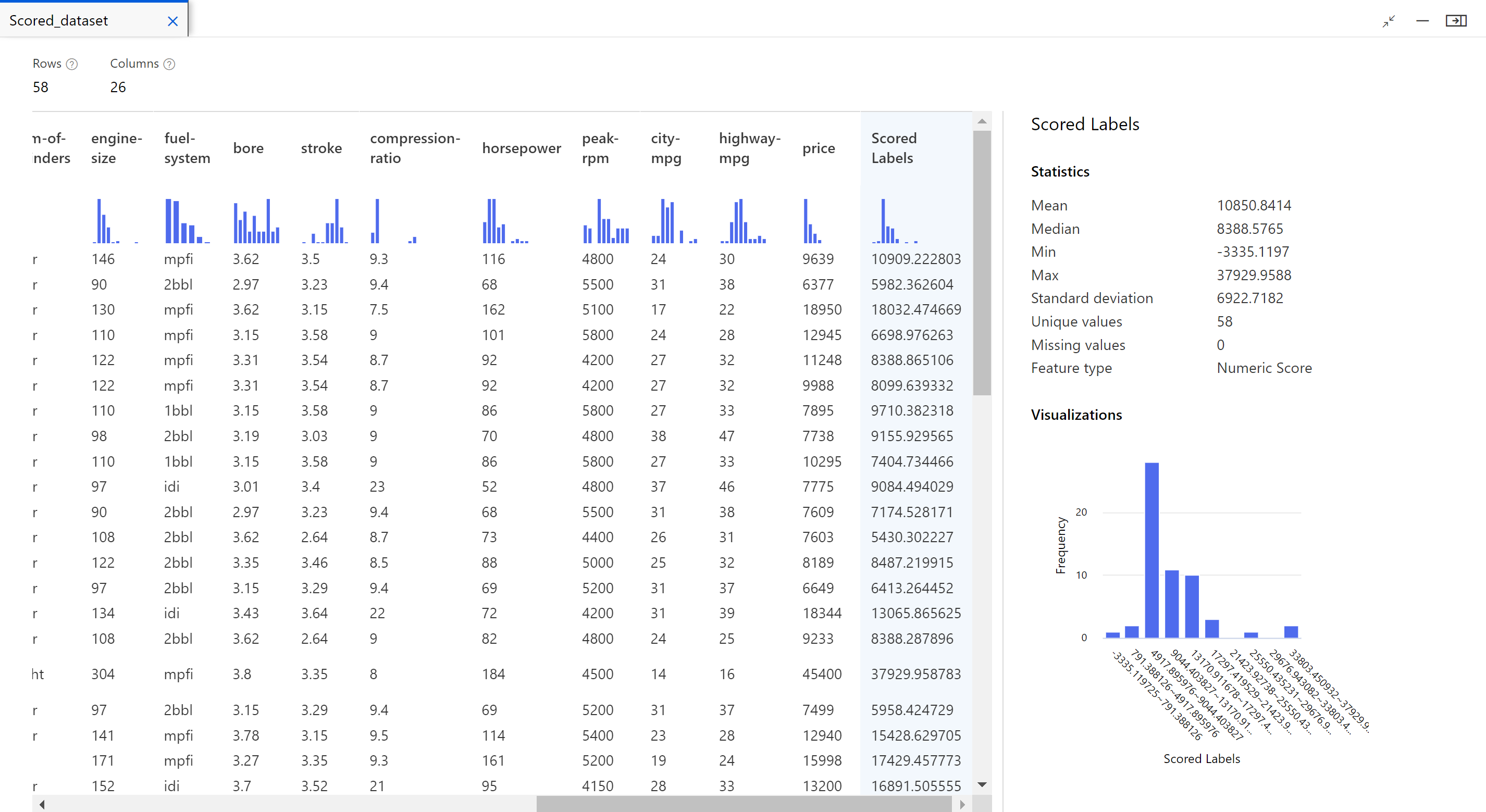
Após a conclusão do trabalho, você poderá visualizar os resultados do trabalho de pipeline. Primeiro, observe as previsões geradas pelo modelo de regressão.
Clique com o botão direito do mouse no componente Modelo de pontuação e selecione Visualizar conjunto>de dados Pontuação para exibir sua saída.
Aqui você pode ver os preços previstos e os preços reais a partir dos dados de teste.
Avaliar modelos
Use o Modelo de Avaliação para ver o desempenho do modelo treinado no conjunto de dados de teste.
- Clique com o botão direito do mouse no componente Avaliar modelo e selecione Visualizar dados>Resultados da avaliação para exibir sua saída.
As seguintes estatísticas são mostradas para o seu modelo:
- Erro Absoluto Médio (MAE): A média dos erros absolutos. Um erro é a diferença entre o valor previsto e o valor real.
- Raiz quadrada da média dos erros (RMSE): A raiz quadrada da média dos erros ao quadrado das predições efetuadas no conjunto de dados de teste.
- Erro relativo absoluto: A média dos erros absolutos relativos à diferença absoluta entre os valores reais e a média de todos os valores reais.
- Erro ao quadrado absoluto: A média dos erros ao quadrado relativos à diferença ao quadrado entre os valores reais e a média de todos os valores reais.
- Coeficiente de Determinação: Também conhecido como valor R ao quadrado, esta métrica estatística indica quão bem um modelo se ajusta aos dados.
Em cada uma das estatísticas de erros, quanto mais pequeno, melhor. Um valor menor indica que as previsões estão mais próximas dos valores reais. Para o coeficiente de determinação, quanto mais próximo o seu valor for de um (1,0), melhores serão as previsões.
Clean up resources (Limpar recursos)
Ignore esta seção se quiser continuar com a parte 2 do tutorial, implantando modelos.
Importante
Você pode usar os recursos criados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Excluir tudo
Se você não planeja usar nada do que criou, exclua todo o grupo de recursos para não incorrer em cobranças.
No portal do Azure, selecione Grupos de recursos no lado esquerdo da janela.
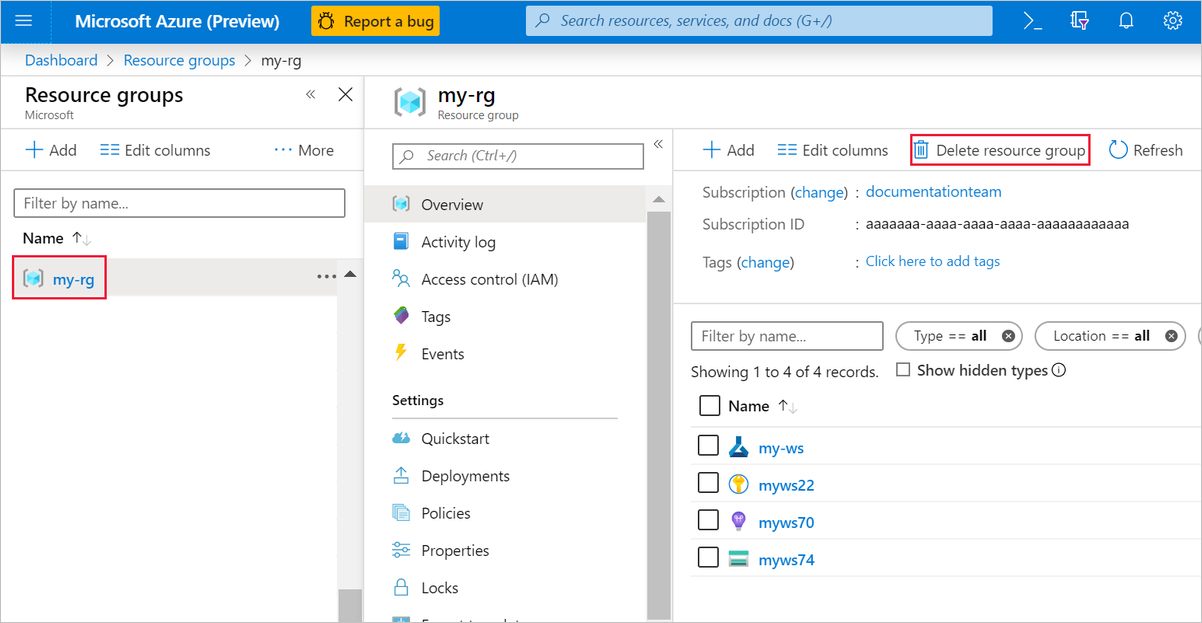
Na lista, selecione o grupo de recursos que você criou.
Selecione Eliminar grupo de recursos.
A exclusão do grupo de recursos também exclui todos os recursos criados no designer.
Excluir ativos individuais
No designer onde você criou seu experimento, exclua ativos individuais selecionando-os e, em seguida, selecionando o botão Excluir .
O destino de computação que você criou aqui é automaticamente dimensionado para zero nós quando não está sendo usado. Esta ação é tomada para minimizar as cobranças. Se você quiser excluir o destino de computação, execute estas etapas:
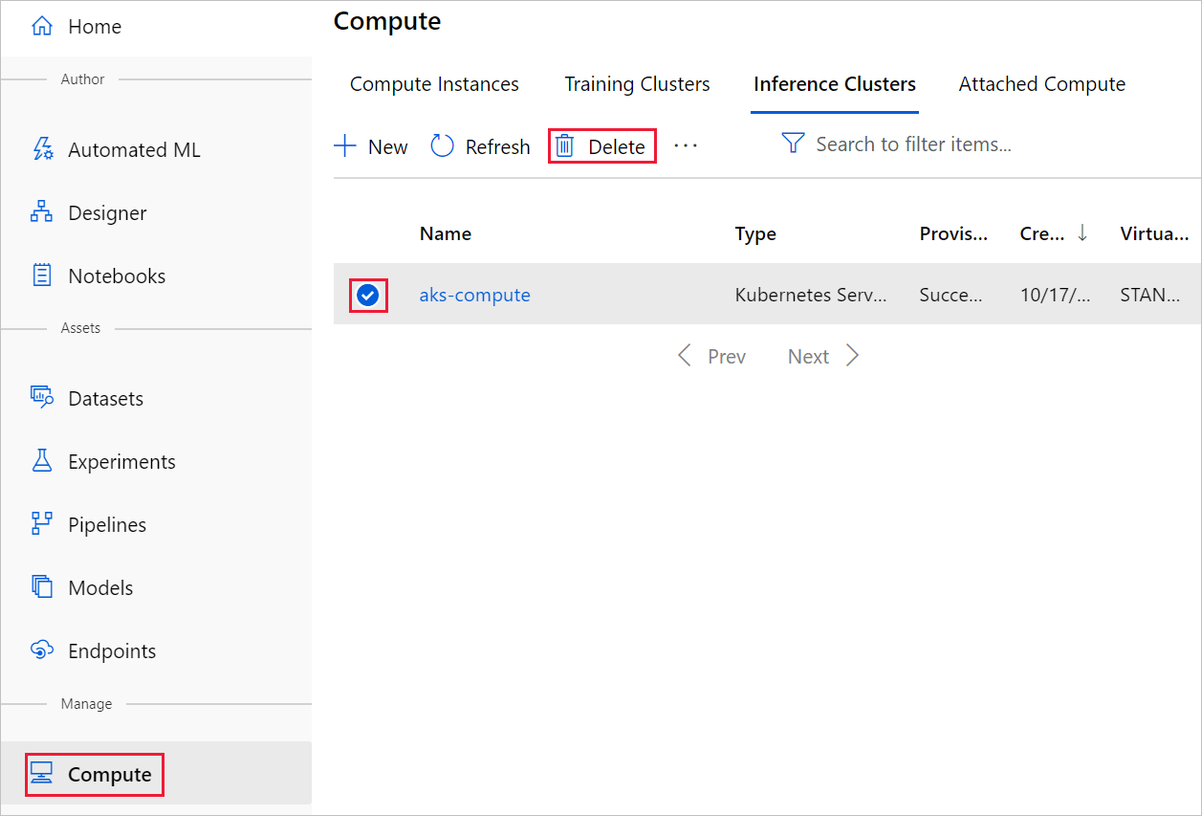
Você pode cancelar o registro de conjuntos de dados do seu espaço de trabalho selecionando cada conjunto de dados e selecionando Cancelar registro.
Para excluir um conjunto de dados, vá para a conta de armazenamento usando o portal do Azure ou o Gerenciador de Armazenamento do Azure e exclua manualmente esses ativos.
Próximos passos
Na segunda parte, você aprenderá como implantar seu modelo como um ponto de extremidade em tempo real.