Tutorial: Treinar um modelo TensorFlow de classificação de imagem usando a Extensão de Código do Visual Studio do Azure Machine Learning (visualização)
APLICA-SE A: Extensão ml da CLI do Azure v2 (atual)
Extensão ml da CLI do Azure v2 (atual)
Saiba como treinar um modelo de classificação de imagem para reconhecer números escritos à mão usando o TensorFlow e a Extensão de Código do Azure Machine Learning Visual Studio.
Importante
Esta funcionalidade está atualmente em pré-visualização pública. Esta versão de pré-visualização é fornecida sem um contrato de nível de serviço e não a recomendamos para cargas de trabalho de produção. Algumas funcionalidades poderão não ser suportadas ou poderão ter capacidades limitadas.
Para obter mais informações, veja Termos Suplementares de Utilização para Pré-visualizações do Microsoft Azure.
Neste tutorial, você aprenderá as seguintes tarefas:
- Compreender o código
- Criar uma área de trabalho
- Preparar um modelo
Pré-requisitos
- Subscrição do Azure. Se não tiver uma, inscreva-se para experimentar a versão gratuita ou paga do Azure Machine Learning. Se você estiver usando a assinatura gratuita, apenas clusters de CPU serão suportados.
- Instale o Visual Studio Code, um editor de código leve e multiplataforma.
- Extensão de código do Visual Studio do estúdio de Aprendizado de Máquina do Azure. Para obter instruções de instalação, consulte o guia de extensão de código do Visual Studio do Azure Machine Learning de configuração
- CLI (v2). Para obter instruções de instalação, consulte Instalar, configurar e usar a CLI (v2)
- Clone o repositório orientado pela comunidade
git clone https://github.com/Azure/azureml-examples.git
Compreender o código
O código para este tutorial usa o TensorFlow para treinar um modelo de aprendizado de máquina de classificação de imagem que categoriza dígitos manuscritos de 0 a 9. Ele faz isso criando uma rede neural que toma os valores de pixel de imagem de 28 px x 28 px como entrada e produz uma lista de 10 probabilidades, uma para cada um dos dígitos que estão sendo classificados. Este é um exemplo da aparência dos dados.

Criar uma área de trabalho
A primeira coisa que você precisa fazer para criar um aplicativo no Aprendizado de Máquina do Azure é criar um espaço de trabalho. Um espaço de trabalho contém os recursos para treinar modelos e os próprios modelos treinados. Para obter mais informações, consulte o que é um espaço de trabalho.
Abra o diretório azureml-examples/cli/jobs/single-step/tensorflow/mnist do repositório orientado pela comunidade no Visual Studio Code.
Na barra de atividades do Visual Studio Code, selecione o ícone do Azure para abrir o modo de exibição do Azure Machine Learning.
Na vista Azure Machine Learning, clique com o botão direito do rato no nó da subscrição e selecione Criar Espaço de Trabalho.
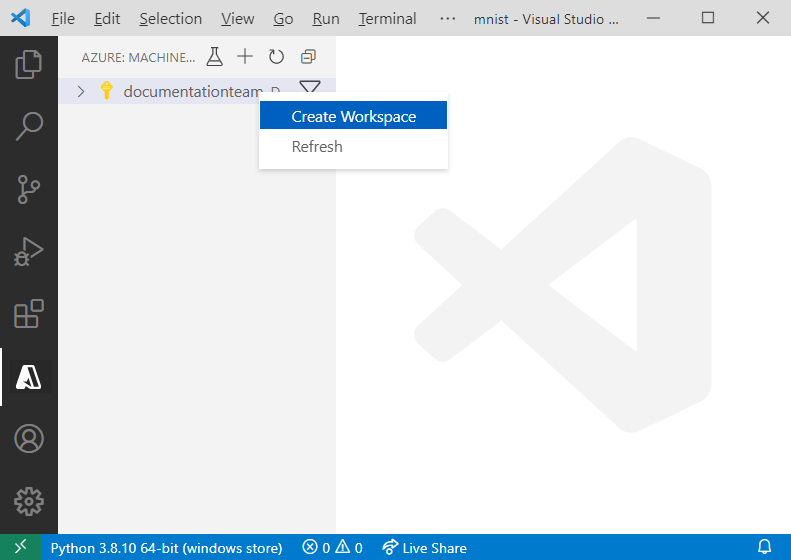
Um arquivo de especificação é exibido. Configure o arquivo de especificação com as seguintes opções.
$schema: https://azuremlschemas.azureedge.net/latest/workspace.schema.json name: TeamWorkspace location: WestUS2 display_name: team-ml-workspace description: A workspace for training machine learning models tags: purpose: training team: ml-teamO arquivo de especificação cria um espaço de trabalho chamado
TeamWorkspacenaWestUS2região. O restante das opções definidas no arquivo de especificação fornecem nomenclatura, descrições e tags amigáveis para o espaço de trabalho.Clique com o botão direito do mouse no arquivo de especificação e selecione AzureML: Executar YAML. A criação de um recurso usa as opções de configuração definidas no arquivo de especificação YAML e envia um trabalho usando a CLI (v2). Neste ponto, uma solicitação ao Azure é feita para criar um novo espaço de trabalho e recursos dependentes em sua conta. Após alguns minutos, o novo espaço de trabalho aparece no nó da assinatura.
Defina
TeamWorkspacecomo seu espaço de trabalho padrão. Isso coloca recursos e trabalhos criados no espaço de trabalho por padrão. Selecione o botão Definir Espaço de Trabalho do Azure Machine Learning na barra de status do Visual Studio Code e siga as instruções para definirTeamWorkspacecomo seu espaço de trabalho padrão.
Para obter mais informações sobre espaços de trabalho, consulte como gerenciar recursos no VS Code.
Preparar o modelo
Durante o processo de treinamento, um modelo TensorFlow é treinado processando os dados de treinamento e padrões de aprendizagem incorporados nele para cada um dos respetivos dígitos que estão sendo classificados.
Como espaços de trabalho e destinos de computação, os trabalhos de treinamento são definidos usando modelos de recursos. Para este exemplo, a especificação é definida no arquivo job.yml , que se parece com o seguinte:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >
python train.py
environment: azureml:AzureML-tensorflow-2.4-ubuntu18.04-py37-cuda11-gpu:48
resources:
instance_type: Standard_NC12
instance_count: 3
experiment_name: tensorflow-mnist-example
description: Train a basic neural network with TensorFlow on the MNIST dataset.
Este arquivo de especificação envia um trabalho de treinamento chamado tensorflow-mnist-example para o destino do computador recém-criado gpu-cluster que executa o código no script train.py Python. O ambiente usado é um dos ambientes selecionados fornecidos pelo Azure Machine Learning, que contém o TensorFlow e outras dependências de software necessárias para executar o script de treinamento. Para obter mais informações sobre ambientes com curadoria, consulte Ambientes com curadoria do Azure Machine Learning.
Para submeter o trabalho de formação:
- Abra o arquivo job.yml .
- Clique com o botão direito do mouse no arquivo no editor de texto e selecione AzureML: Executar YAML.
Neste ponto, uma solicitação é enviada ao Azure para executar seu experimento no destino de computação selecionado em seu espaço de trabalho. Este processo demora vários minutos. A quantidade de tempo para executar o trabalho de treinamento é afetada por vários fatores, como o tipo de computação e o tamanho dos dados de treinamento. Para acompanhar o progresso da sua experiência, clique com o botão direito do rato no nó de execução atual e selecione Ver Trabalho no portal do Azure.
Quando a caixa de diálogo solicitando a abertura de um site externo for exibida, selecione Abrir.
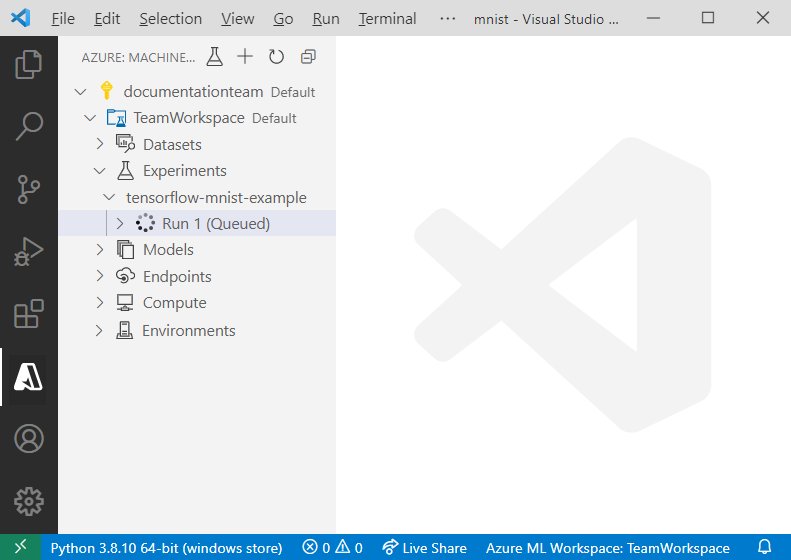
Quando o modelo termina o treinamento, o rótulo de status ao lado do nó de execução é atualizado para "Concluído".
Próximos passos
- Iniciar o Visual Studio Code integrado com o Azure Machine Learning (visualização)
- Para obter um passo a passo de como editar, executar e depurar código localmente, consulte o tutorial hello-world do Python.
- Execute o Jupyter Notebooks no Visual Studio Code usando um servidor Jupyter remoto.
- Para obter um passo a passo de como treinar com o Azure Machine Learning fora do Visual Studio Code, consulte Tutorial: Treinar e implantar um modelo com o Azure Machine Learning.