Tutorial: Treinar e implantar um modelo de classificação de imagem com um exemplo de Jupyter Notebook
APLICA-SE A: Python SDK azureml v1
Python SDK azureml v1
Neste tutorial, você treina um modelo de aprendizado de máquina em recursos de computação remotos. Você usa o fluxo de trabalho de treinamento e implantação do Azure Machine Learning em um Python Jupyter Notebook. Depois, pode utilizar o bloco de notas como um modelo para preparar o seu próprio modelo de machine learning com os seus dados.
Este tutorial treina uma regressão logística simples usando o conjunto de dados MNIST e o scikit-learn com o Azure Machine Learning. O MNIST é um conjunto de dados popular que consiste em 70 000 imagens em tons de cinzento. Cada imagem é um dígito manuscrito de 28 x 28 pixels, representando um número de zero a nove. O objetivo é criar um classificador multiclasses para identificar o dígito que uma determinada imagem representa.
Saiba como executar as seguintes ações:
- Faça o download de um conjunto de dados e veja os dados.
- Treine um modelo de classificação de imagem e métricas de log usando MLflow.
- Implante o modelo para fazer inferência em tempo real.
Pré-requisitos
- Conclua o Guia de início rápido: introdução ao Aprendizado de Máquina do Azure para:
- Crie um espaço de trabalho.
- Crie uma instância de computação baseada em nuvem para usar em seu ambiente de desenvolvimento.
Executar um bloco de notas a partir da sua área de trabalho
O Azure Machine Learning inclui um servidor de blocos de notas na nuvem na sua área de trabalho para uma experiência pré-configurada e sem instalação. Use seu próprio ambiente se preferir ter controle sobre seu ambiente, pacotes e dependências.
Clonar uma pasta do bloco de anotações
Conclua a configuração do experimento a seguir e execute as etapas no estúdio do Azure Machine Learning. Essa interface consolidada inclui ferramentas de aprendizado de máquina para executar cenários de ciência de dados para profissionais de ciência de dados de todos os níveis de habilidade.
Entre no estúdio do Azure Machine Learning.
Selecione sua assinatura e o espaço de trabalho que você criou.
À esquerda, selecione Blocos de Notas.
Na parte superior, selecione a guia Amostras .
Abra a pasta SDK v1 .
Selecione o botão ... à direita da pasta tutoriais e, em seguida, selecione Clonar.
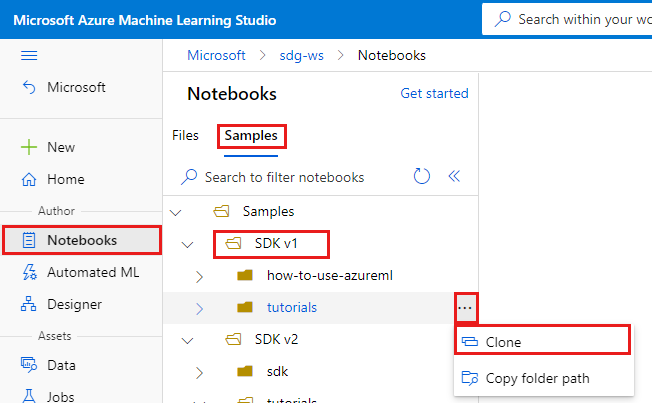
Uma lista de pastas mostra cada usuário que acessa o espaço de trabalho. Selecione sua pasta para clonar a pasta de tutoriais lá.
Abra o bloco de anotações clonado
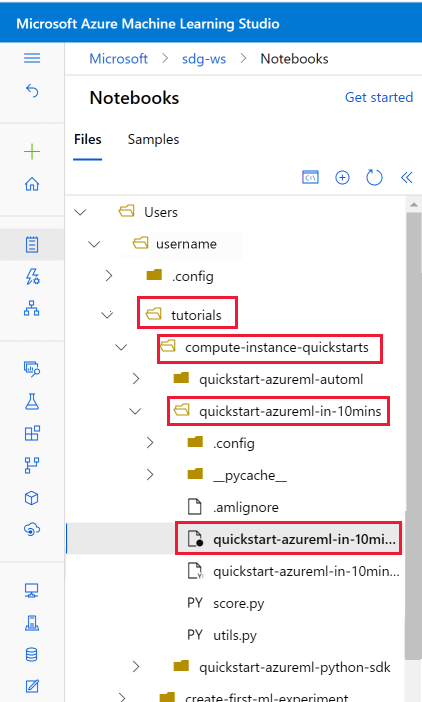
Abra a pasta de tutoriais que foi clonada na seção Arquivos de usuário.
Selecione o arquivo quickstart-azureml-in-10mins.ipynb na pasta tutorials/compute-instance-quickstarts/quickstart-azureml-in-10mins .
Instalar pacotes
Quando a instância de computação estiver em execução e o kernel aparecer, adicione uma nova célula de código para instalar os pacotes necessários para este tutorial.
Na parte superior do bloco de notas, adicione uma célula de código.
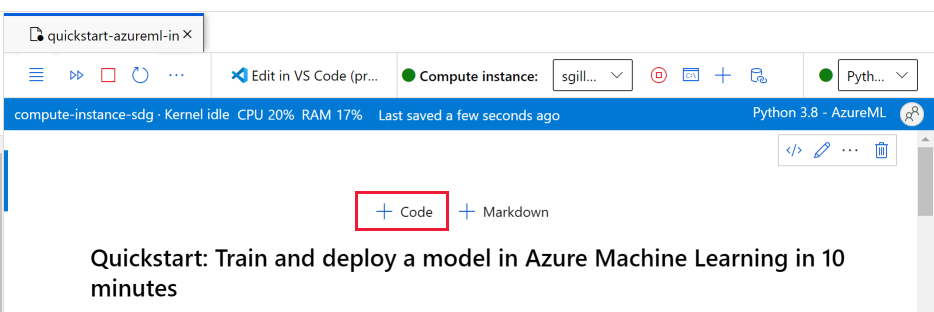
Adicione o seguinte à célula e, em seguida, execute a célula, usando a ferramenta Executar ou usando Shift+Enter.
%pip install scikit-learn==0.22.1 %pip install scipy==1.5.2
Você pode ver alguns avisos de instalação. Estes podem ser ignorados com segurança.
Executar o bloco de notas
Este tutorial e o arquivo utils.py que o acompanha também estão disponíveis no GitHub, se você quiser usá-lo em seu próprio ambiente local. Se você não estiver usando a instância de computação, adicione %pip install azureml-sdk[notebooks] azureml-opendatasets matplotlib à instalação acima.
Importante
O restante deste artigo contém o mesmo conteúdo que você vê no bloco de anotações.
Mude para o Jupyter Notebook agora se quiser executar o código enquanto lê. Para executar uma única célula de código em um bloco de anotações, clique na célula de código e pressione Shift+Enter. Ou execute o bloco de anotações inteiro escolhendo Executar tudo na barra de ferramentas superior.
Importar dados
Antes de treinar um modelo, você precisa entender os dados que está usando para treiná-lo. Nesta secção, saiba como:
- Transferir o conjunto de dados MNIST
- Apresentar algumas imagens de exemplo
Você usa o Azure Open Datasets para obter os arquivos de dados MNIST brutos. Os Conjuntos de Dados Abertos do Azure são conjuntos de dados públicos selecionados que você pode usar para adicionar recursos específicos do cenário a soluções de aprendizado de máquina para modelos melhores. Cada conjunto de dados tem uma classe correspondente, MNIST neste caso, para recuperar os dados de maneiras diferentes.
import os
from azureml.opendatasets import MNIST
data_folder = os.path.join(os.getcwd(), "/tmp/qs_data")
os.makedirs(data_folder, exist_ok=True)
mnist_file_dataset = MNIST.get_file_dataset()
mnist_file_dataset.download(data_folder, overwrite=True)
Dê uma olhada nos dados
Carregue os ficheiros comprimidos para matrizes numpy. Em seguida, utilize matplotlib para desenhar 30 imagens aleatórias do conjunto de dados com as respetivas etiquetas acima das mesmas.
Observe que esta etapa requer uma load_data função, incluída em um utils.py arquivo. Este ficheiro é colocado na mesma pasta que este bloco de notas. A load_data função simplesmente analisa os arquivos compactados em matrizes numpy.
from utils import load_data
import matplotlib.pyplot as plt
import numpy as np
import glob
# note we also shrink the intensity values (X) from 0-255 to 0-1. This helps the model converge faster.
X_train = (
load_data(
glob.glob(
os.path.join(data_folder, "**/train-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
X_test = (
load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-images-idx3-ubyte.gz"), recursive=True
)[0],
False,
)
/ 255.0
)
y_train = load_data(
glob.glob(
os.path.join(data_folder, "**/train-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
y_test = load_data(
glob.glob(
os.path.join(data_folder, "**/t10k-labels-idx1-ubyte.gz"), recursive=True
)[0],
True,
).reshape(-1)
# now let's show some randomly chosen images from the traininng set.
count = 0
sample_size = 30
plt.figure(figsize=(16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline("")
plt.axvline("")
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
O código exibe um conjunto aleatório de imagens com seus rótulos, semelhante a este:

Treinar métricas de modelo e log com MLflow
Treine o modelo usando o código a seguir. Esse código usa o registro automático MLflow para rastrear métricas e artefatos de modelo de log.
Você usará o classificador LogisticRegression da estrutura SciKit Learn para classificar os dados.
Nota
O treinamento do modelo leva aproximadamente 2 minutos para ser concluído.
# create the model
import mlflow
import numpy as np
from sklearn.linear_model import LogisticRegression
from azureml.core import Workspace
# connect to your workspace
ws = Workspace.from_config()
# create experiment and start logging to a new run in the experiment
experiment_name = "azure-ml-in10-mins-tutorial"
# set up MLflow to track the metrics
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.set_experiment(experiment_name)
mlflow.autolog()
# set up the Logistic regression model
reg = 0.5
clf = LogisticRegression(
C=1.0 / reg, solver="liblinear", multi_class="auto", random_state=42
)
# train the model
with mlflow.start_run() as run:
clf.fit(X_train, y_train)
Ver experiência
No menu à esquerda no estúdio do Azure Machine Learning, selecione Trabalhos e, em seguida, selecione o seu trabalho (azure-ml-in10-mins-tutorial). Um trabalho é um agrupamento de muitas execuções a partir de um script ou pedaço de código especificado. Vários trabalhos podem ser agrupados como um experimento.
As informações para a execução são armazenadas sob esse trabalho. Se o nome não existir quando você enviar um trabalho, se você selecionar sua execução, verá várias guias contendo métricas, logs, explicações, etc.
Controle de versão dos seus modelos com o registo de modelos
Você pode usar o registro de modelo para armazenar e fazer a versão de seus modelos em seu espaço de trabalho. Os modelos registados são identificados por nome e versão. Sempre que registar um modelo com o mesmo nome de um modelo já existente, o registo aumenta a versão. O código abaixo registra e formata o modelo que você treinou acima. Depois de executar a célula de código a seguir, você verá o modelo no Registro selecionando Modelos no menu à esquerda no estúdio de Aprendizado de Máquina do Azure.
# register the model
model_uri = "runs:/{}/model".format(run.info.run_id)
model = mlflow.register_model(model_uri, "sklearn_mnist_model")
Implante o modelo para inferência em tempo real
Nesta seção, saiba como implantar um modelo para que um aplicativo possa consumir (inferência) o modelo sobre REST.
Criar configuração de implantação
A célula de código obtém um ambiente com curadoria, que especifica todas as dependências necessárias para hospedar o modelo (por exemplo, os pacotes como scikit-learn). Além disso, você cria uma configuração de implantação, que especifica a quantidade de computação necessária para hospedar o modelo. Neste caso, o computador tem 1CPU e 1 GB de memória.
# create environment for the deploy
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.webservice import AciWebservice
# get a curated environment
env = Environment.get(
workspace=ws,
name="AzureML-sklearn-1.0"
)
env.inferencing_stack_version='latest'
# create deployment config i.e. compute resources
aciconfig = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=1,
tags={"data": "MNIST", "method": "sklearn"},
description="Predict MNIST with sklearn",
)
Implementar o modelo
Esta próxima célula de código implanta o modelo na Instância de Contêiner do Azure.
Nota
A implantação leva aproximadamente 3 minutos para ser concluída. Mas pode ser mais longo até que esteja disponível para uso, talvez até 15 minutos.**
%%time
import uuid
from azureml.core.model import InferenceConfig
from azureml.core.environment import Environment
from azureml.core.model import Model
# get the registered model
model = Model(ws, "sklearn_mnist_model")
# create an inference config i.e. the scoring script and environment
inference_config = InferenceConfig(entry_script="score.py", environment=env)
# deploy the service
service_name = "sklearn-mnist-svc-" + str(uuid.uuid4())[:4]
service = Model.deploy(
workspace=ws,
name=service_name,
models=[model],
inference_config=inference_config,
deployment_config=aciconfig,
)
service.wait_for_deployment(show_output=True)
O arquivo de script de pontuação mencionado no código anterior pode ser encontrado na mesma pasta deste bloco de anotações e tem duas funções:
- Uma
initfunção que é executada uma vez quando o serviço é iniciado - nesta função você normalmente obtém o modelo do registro e define variáveis globais - Uma
run(data)função que é executada cada vez que uma chamada é feita para o serviço. Nessa função, você normalmente formata os dados de entrada, executa uma previsão e produz o resultado previsto.
Ver ponto final
Depois que o modelo for implantado com êxito, você poderá exibir o ponto de extremidade navegando até Pontos de extremidade no menu à esquerda no estúdio do Azure Machine Learning. Você verá o estado do ponto de extremidade (íntegro/não íntegro), logs e consumo (como os aplicativos podem consumir o modelo).
Testar o serviço modelo
Você pode testar o modelo enviando uma solicitação HTTP bruta para testar o serviço Web.
# send raw HTTP request to test the web service.
import requests
# send a random row from the test set to score
random_index = np.random.randint(0, len(X_test) - 1)
input_data = '{"data": [' + str(list(X_test[random_index])) + "]}"
headers = {"Content-Type": "application/json"}
resp = requests.post(service.scoring_uri, input_data, headers=headers)
print("POST to url", service.scoring_uri)
print("label:", y_test[random_index])
print("prediction:", resp.text)
Clean up resources (Limpar recursos)
Se você não vai continuar a usar esse modelo, exclua o serviço Modelo usando:
# if you want to keep workspace and only delete endpoint (it will incur cost while running)
service.delete()
Se você quiser controlar ainda mais o custo, pare a instância de computação selecionando o botão "Parar computação" ao lado da lista suspensa Computação . Em seguida, inicie a instância de computação novamente na próxima vez que precisar dela.
Excluir tudo
Use estas etapas para excluir seu espaço de trabalho do Azure Machine Learning e todos os recursos de computação.
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, selecione Grupos de recursos na extremidade esquerda.
Na lista, selecione o grupo de recursos que você criou.
Selecione Eliminar grupo de recursos.
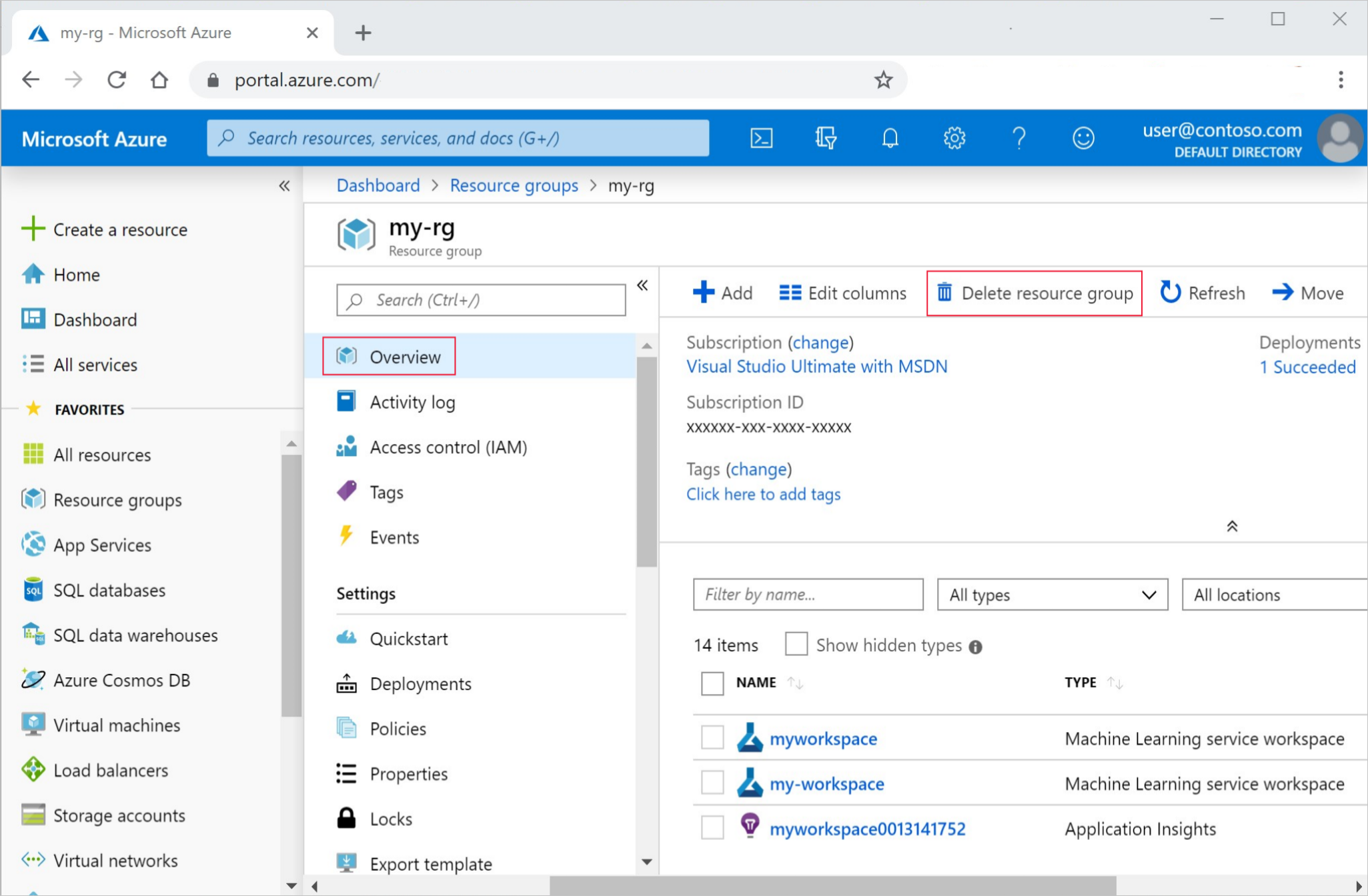
Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Recursos relacionados
- Saiba mais sobre todas as opções de implantação do Azure Machine Learning.
- Saiba como autenticar no modelo implantado.
- Faça previsões sobre grandes quantidades de dados de forma assíncrona.
- Monitore seus modelos do Azure Machine Learning com o Application Insights.