Implementar modelos de machine learning no Azure
APLICA-SE A: Extensão de ml da CLI do Azure v1SDK python azureml v1
Extensão de ml da CLI do Azure v1SDK python azureml v1
Saiba como implementar o modelo de machine learning ou aprendizagem profunda como um serviço Web na cloud do Azure.
Nota
Os Pontos Finais do Azure Machine Learning (v2) proporcionam uma experiência de implementação melhorada e mais simples. Os pontos finais suportam cenários de inferência em tempo real e em lotes. Os pontos finais fornecem uma interface unificada para invocar e gerir implementações de modelos em tipos de computação. Veja O que são pontos finais do Azure Machine Learning?.
Fluxo de trabalho para implementar um modelo
O fluxo de trabalho é semelhante, independentemente de onde implementa o modelo:
- Registar o modelo.
- Preparar um script de entrada.
- Preparar uma configuração de inferência.
- Implemente o modelo localmente para garantir que tudo funciona.
- Escolha um destino de computação.
- Implemente o modelo na cloud.
- Teste o serviço Web resultante.
Para obter mais informações sobre os conceitos envolvidos no fluxo de trabalho de implementação de machine learning, veja Gerir, implementar e monitorizar modelos com o Azure Machine Learning.
Pré-requisitos
APLICA-SE A:Extensão de ml da CLI do Azure v1
Importante
Os comandos da CLI do Azure neste artigo requerem a extensão , ou v1, para o azure-cli-mlAzure Machine Learning. O suporte para a extensão v1 terminará a 30 de setembro de 2025. Poderá instalar e utilizar a extensão v1 até essa data.
Recomendamos que faça a transição para a mlextensão , ou v2, antes de 30 de setembro de 2025. Para obter mais informações sobre a extensão v2, veja Extensão da CLI do Azure ML e SDK Python v2.
- Uma área de trabalho do Azure Machine Learning. Para obter mais informações, veja Criar recursos da área de trabalho.
- Um modelo. Os exemplos neste artigo utilizam um modelo pré-preparado.
- Uma máquina virtual que pode executar o Docker, como uma instância de computação.
Ligar à sua área de trabalho
APLICA-SE A:Extensão de ml da CLI do Azure v1
Para ver as áreas de trabalho às quais tem acesso, utilize os seguintes comandos:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Registar o modelo
Uma situação típica de um serviço de machine learning implementado é que precisa dos seguintes componentes:
- Recursos que representam o modelo específico que pretende implementar (por exemplo: um ficheiro de modelo pytorch).
- Código que irá executar no serviço que executa o modelo numa determinada entrada.
O Azure Machine Learnings permite-lhe separar a implementação em dois componentes separados, para que possa manter o mesmo código e atualizar apenas o modelo. Definimos o mecanismo através do qual carrega um modelo separadamente do seu código como "registar o modelo".
Quando regista um modelo, nós carregamos o modelo na cloud (na conta de armazenamento predefinida da sua área de trabalho) e, em seguida, montamos esse modelo na mesma computação em que o seu serviço Web está em execução.
Os exemplos seguintes demonstram como registar um modelo.
Importante
Apenas deve utilizar modelos criados por si ou que tenha obtido a partir de uma origem fidedigna. Deve tratar os modelos serializados como código, pois foram descobertas vulnerabilidades de segurança em vários formatos populares. Além disso, os modelos podem ser preparados propositadamente com a intenção maliciosa de fornecer saídas tendenciosas ou imprecisas.
APLICA-SE A:Extensão de ml da CLI do Azure v1
Os seguintes comandos transferem um modelo e, em seguida, registam-no na área de trabalho do Azure Machine Learning:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Defina -p como o caminho de uma pasta ou um ficheiro que pretende registar.
Para obter mais informações sobre az ml model register, veja a documentação de referência.
Registar um modelo a partir de uma tarefa de preparação do Azure Machine Learning
Se precisar de registar um modelo criado anteriormente através de uma tarefa de preparação do Azure Machine Learning, pode especificar a experimentação, a execução e o caminho para o modelo:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
O --asset-path parâmetro refere-se à localização na cloud do modelo. Neste exemplo, é utilizado o caminho de um único ficheiro. Para incluir vários ficheiros no registo do modelo, defina --asset-path como o caminho de uma pasta que contém os ficheiros.
Para obter mais informações sobre az ml model register, veja a documentação de referência.
Nota
Também pode registar um modelo a partir de um ficheiro local através do portal de IU da Área de Trabalho.
Atualmente, existem duas opções para carregar um ficheiro de modelo local na IU:
- A partir de ficheiros locais, que registarão um modelo v2.
- A partir de ficheiros locais (com base na arquitetura), que registarão um modelo v1.
Tenha em atenção que apenas os modelos registados através da entrada De ficheiros locais (com base na arquitetura) (conhecidos como modelos v1) podem ser implementados como webservices com o SDKv1/CLIv1.
Definir um script de entrada fictício
O script de entrada recebe os dados enviados para um serviço Web implementado e transmite-os para o modelo. Em seguida, devolve a resposta do modelo ao cliente. O script é específico do modelo. O script de entrada tem de compreender os dados esperados e devolvidos pelo modelo.
As duas coisas que precisa de realizar no script de entrada são:
- Carregar o modelo (utilizando uma função chamada
init()) - Executar o modelo em dados de entrada (utilizando uma função chamada
run())
Para a implementação inicial, utilize um script de entrada fictício que imprima os dados que recebe.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Guarde este ficheiro como echo_score.py dentro de um diretório chamado source_dir. Este script fictício devolve os dados que lhe envia, para que não utilize o modelo. No entanto, é útil testar que o script de classificação está em execução.
Definir uma configuração de inferência
Uma configuração de inferência descreve o contentor do Docker e os ficheiros a utilizar ao inicializar o seu serviço Web. Todos os ficheiros no diretório de origem, incluindo subdiretórios, serão fechados e carregados para a cloud quando implementar o seu serviço Web.
A configuração de inferência abaixo especifica que a implementação de machine learning utilizará o ./source_dir ficheiro echo_score.py no diretório para processar pedidos recebidos e que utilizará a imagem do Docker com os pacotes Python especificados no project_environment ambiente.
Pode utilizar todos os ambientes organizados de inferência do Azure Machine Learning como a imagem base do Docker ao criar o seu ambiente de projeto. Vamos instalar as dependências necessárias na parte superior e armazenar a imagem do Docker resultante no repositório associado à sua área de trabalho.
Nota
O carregamento do diretório de origem da inferência do Azure Machine Learning não respeita .gitignore ou .amlignore
APLICA-SE A:Extensão de ml da CLI do Azure v1
Uma configuração mínima de inferência pode ser escrita como:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Guarde este ficheiro com o nome dummyinferenceconfig.json.
Veja este artigo para uma discussão mais aprofundada sobre as configurações de inferência.
Definir uma configuração de implementação
Uma configuração de implementação especifica a quantidade de memória e núcleos de que o webservice precisa para ser executado. Também fornece detalhes de configuração do webservice subjacente. Por exemplo, uma configuração de implementação permite-lhe especificar que o seu serviço precisa de 2 gigabytes de memória, 2 núcleos de CPU, 1 núcleo de GPU e que pretende ativar o dimensionamento automático.
As opções disponíveis para uma configuração de implementação diferem consoante o destino de computação que escolher. Numa implementação local, tudo o que pode especificar é em que porta será servido o seu webservice.
APLICA-SE A:Extensão de ml da CLI do Azure v1
As entradas no mapa do deploymentconfig.json documento para os parâmetros para LocalWebservice.deploy_configuration. A tabela seguinte descreve o mapeamento entre as entidades no documento JSON e os parâmetros do método:
| Entidade JSON | Parâmetro do método | Description |
|---|---|---|
computeType |
ND | O destino de computação. Para destinos locais, o valor tem de ser local. |
port |
port |
A porta local na qual pretende expor o ponto final HTTP do serviço. |
Este JSON é um exemplo de configuração de implementação para utilização com a CLI:
{
"computeType": "local",
"port": 32267
}
Guarde este JSON como um ficheiro chamado deploymentconfig.json.
Para obter mais informações, veja o esquema de implementação.
Implementar o modelo de machine learning
Está agora pronto para implementar o modelo.
APLICA-SE A:Extensão de ml da CLI do Azure v1
Substitua bidaf_onnx:1 pelo nome do modelo e pelo respetivo número de versão.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Chamar para o modelo
Vamos verificar se o modelo de eco foi implementado com êxito. Deverá conseguir fazer um pedido de liveness simples, bem como um pedido de classificação:
APLICA-SE A:Extensão de ml da CLI do Azure v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definir um script de entrada
Chegou a altura de carregar o modelo. Primeiro, modifique o script de entrada:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Guarde este ficheiro como score.py dentro de source_dir.
Repare na utilização da variável de AZUREML_MODEL_DIR ambiente para localizar o modelo registado. Agora que adicionou alguns pacotes pip.
APLICA-SE A:Extensão de ml da CLI do Azure v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Guardar este ficheiro como inferenceconfig.json
Implementar novamente e chamar o seu serviço
Implemente o seu serviço novamente:
APLICA-SE A:Extensão de ml da CLI do Azure v1
Substitua bidaf_onnx:1 pelo nome do modelo e pelo respetivo número de versão.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Em seguida, certifique-se de que pode enviar um pedido pós-pedido para o serviço:
APLICA-SE A:Extensão de ml da CLI do Azure v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Escolher um destino de computação
O destino de computação que utiliza para alojar o modelo afetará o custo e a disponibilidade do ponto final implementado. Utilize esta tabela para escolher um destino de computação adequado.
| Destino de computação | Utilizado para | Suporte de GPU | Descrição |
|---|---|---|---|
| Serviço Web local | Testar/depurar | Utilize para testes e resolução de problemas limitados. A aceleração de hardware depende da utilização de bibliotecas no sistema local. | |
| Pontos finais do Azure Machine Learning (apenas SDK/CLI v2) | Inferência em tempo real Inferência de lote |
Yes | Computação totalmente gerida em tempo real (pontos finais online geridos) e classificação em lote (pontos finais de lote) em computação sem servidor. |
| Azure Machine Learning Kubernetes | Inferência em tempo real Inferência de lote |
Yes | Execute a inferência de cargas de trabalho nos clusters do Kubernetes no local, na cloud e no edge. |
| Azure Container Instances (apenas SDK/CLI v1) | Inferência em tempo real Recomendado apenas para fins de desenvolvimento/teste. |
Utilize para cargas de trabalho baseadas em CPU de baixa escala que requerem menos de 48 GB de RAM. Não requer a gestão de um cluster. Suportado no estruturador. |
Nota
Ao escolher um SKU de cluster, primeiro aumente verticalmente e, em seguida, aumente horizontalmente. Comece com um computador que tenha 150% da RAM de que o seu modelo necessita, crie o perfil do resultado e localize um computador que tenha o desempenho de que precisa. Assim que tiver aprendido, aumente o número de máquinas para se adaptarem à sua necessidade de inferência simultânea.
Nota
As instâncias de contentor requerem o SDK ou a CLI v1 e são adequadas apenas para modelos pequenos com menos de 1 GB de tamanho.
Implementar na cloud
Depois de confirmar que o seu serviço funciona localmente e escolheu um destino de computação remoto, está pronto para implementar na cloud.
Altere a configuração de implementação para corresponder ao destino de computação que escolheu, neste caso Azure Container Instances:
APLICA-SE A:Extensão de ml da CLI do Azure v1
As opções disponíveis para uma configuração de implementação diferem consoante o destino de computação que escolher.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Guarde este ficheiro como re-deploymentconfig.json.
Para obter mais informações, veja esta referência.
Implemente o seu serviço novamente:
APLICA-SE A:Extensão de ml da CLI do Azure v1
Substitua pelo bidaf_onnx:1 nome do modelo e pelo respetivo número de versão.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Para ver os registos de serviço, utilize o seguinte comando:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Chamar o seu webservice remoto
Ao implementar remotamente, poderá ter a autenticação de chave ativada. O exemplo abaixo mostra como obter a sua chave de serviço com Python para fazer um pedido de inferência.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Veja o artigo sobre aplicações cliente para consumir serviços Web para obter mais exemplos de clientes noutros idiomas.
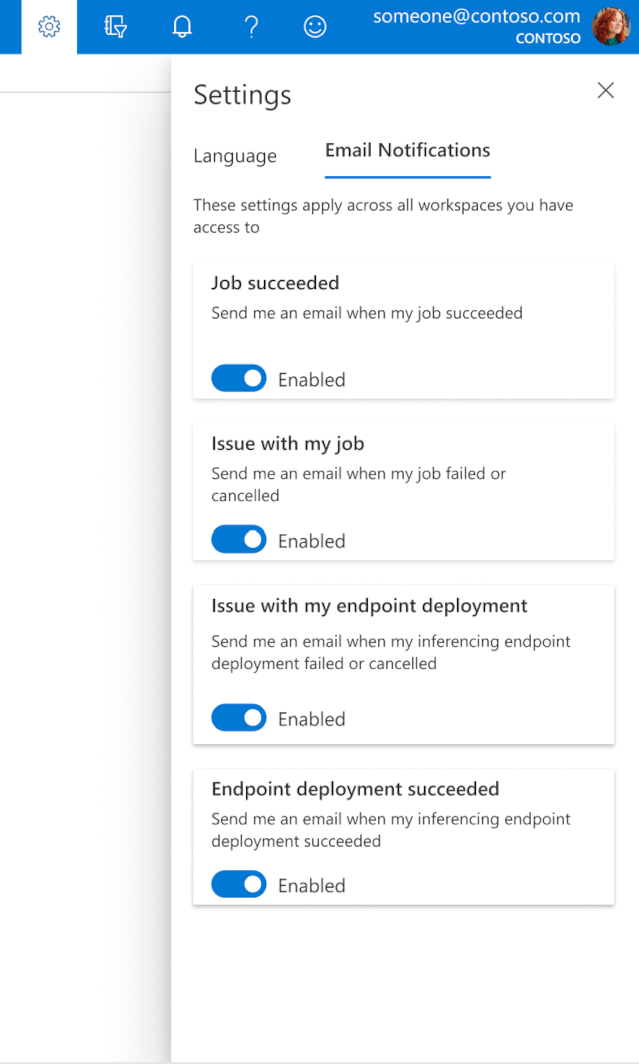
Como configurar e-mails no estúdio
Para começar a receber e-mails quando o seu trabalho, ponto final online ou ponto final de lote estiver concluído ou se existir um problema (com falha, cancelado), siga os seguintes passos:
- No Azure ML Studio, aceda às definições ao selecionar o ícone de engrenagem.
- Selecione o separador Email notificações.
- Alterne para ativar ou desativar notificações por e-mail para um evento específico.
Compreender o estado do serviço
Durante a implementação do modelo, poderá ver a alteração do estado do serviço durante a implementação completa.
A tabela seguinte descreve os diferentes estados de serviço:
| Estado do serviço Web | Descrição | Estado final? |
|---|---|---|
| Em transição | O serviço está em processo de implementação. | No |
| Mau estado de funcionamento | O serviço foi implementado, mas está atualmente inacessível. | No |
| Não agendada | Não é possível implementar o serviço neste momento devido à falta de recursos. | No |
| Com falhas | O serviço não foi implementado devido a um erro ou falha. | Yes |
| Bom estado de funcionamento | O serviço está em bom estado de funcionamento e o ponto final está disponível. | Yes |
Dica
Ao implementar, as imagens do Docker para destinos de computação são criadas e carregadas a partir de Azure Container Registry (ACR). Por predefinição, o Azure Machine Learning cria um ACR que utiliza o escalão de serviço básico . Alterar o ACR da área de trabalho para o escalão standard ou premium pode reduzir o tempo necessário para criar e implementar imagens nos seus destinos de computação. Para obter mais informações, veja Escalões de serviço do Azure Container Registry (ACR).
Nota
Se estiver a implementar um modelo no Azure Kubernetes Service (AKS), recomendamos que ative o Azure Monitor para esse cluster. Este procedimento ajudará a compreender o estado de funcionamento geral do cluster e a utilização dos recursos. Os seguintes recursos também poderão ser úteis:
- Verificar se existem eventos do Resource Health a afetar o cluster do AKS
- Diagnóstico do Azure Kubernetes Service
Se estiver a tentar implementar um modelo num cluster em mau estado de funcionamento ou sobrecarregado, poderão ocorrer problemas. Se precisar de ajuda para resolver problemas do cluster do AKS, contacte o Suporte do AKS.
Eliminar recursos
APLICA-SE A:Extensão de ml da CLI do Azure v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Para eliminar um webservice implementado, utilize az ml service delete <name of webservice>.
Para eliminar um modelo registado da área de trabalho, utilize az ml model delete <model id>
Leia mais sobre como eliminar um serviço Web e eliminar um modelo.
Passos seguintes
- Resolver problemas de uma implementação com falhas
- Atualizar serviços Web
- Implementação com um clique para execuções de ML automatizadas no estúdio do Azure Machine Learning
- Utilizar o TLS para proteger um serviço Web através do Azure Machine Learning
- Monitorizar os modelos do Azure Machine Learning com o Application Insights
- Criar alertas de eventos e acionadores para implementações de modelos