Solucionar problemas de latência de replicação no Banco de Dados do Azure para MySQL - Servidor Flexível
APLICA-SE A:  Banco de Dados do Azure para MySQL - Servidor Único Banco de Dados do Azure para MySQL - Servidor Flexível
Banco de Dados do Azure para MySQL - Servidor Único Banco de Dados do Azure para MySQL - Servidor Flexível
Importante
O servidor único do Banco de Dados do Azure para MySQL está no caminho de desativação. É altamente recomendável que você atualize para o Banco de Dados do Azure para o servidor flexível MySQL. Para obter mais informações sobre como migrar para o Banco de Dados do Azure para servidor flexível MySQL, consulte O que está acontecendo com o Banco de Dados do Azure para Servidor Único MySQL?
Nota
Este artigo faz referência a um termo que a Microsoft não usa mais. Quando o termo for removido do software, iremos removê-lo deste artigo.
O recurso de réplica de leitura permite replicar dados de um Banco de Dados do Azure para um servidor MySQL para um servidor de réplica somente leitura. Você pode expandir cargas de trabalho roteando consultas de leitura e relatório do aplicativo para servidores de réplica. Essa configuração reduz a pressão sobre o servidor de origem e melhora o desempenho geral e a latência do aplicativo à medida que ele é dimensionado.
As réplicas são atualizadas de forma assíncrona usando a tecnologia de replicação baseada na posição do arquivo binário nativo (binlog) do mecanismo MySQL. Para obter mais informações, consulte Visão geral da configuração de replicação baseada em posição do arquivo binlog MySQL.
O atraso de replicação nas réplicas de leitura secundárias depende de vários fatores. Esses fatores incluem, mas não estão limitados a:
- Latência na rede.
- Volume de transações no servidor de origem.
- Camada de computação do servidor de origem e do servidor de réplica de leitura secundário.
- Consultas em execução no servidor de origem e no servidor secundário.
Neste artigo, você aprenderá como solucionar problemas de latência de replicação no Banco de Dados do Azure para MySQL. Você também terá uma ideia melhor de algumas causas comuns do aumento da latência de replicação em servidores de réplica.
Nota
Este artigo poderá conter referências ao termo slave (secundário), um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
Conceitos de replicação
Quando um log binário é habilitado, o servidor de origem grava transações confirmadas no log binário. O log binário é usado para replicação. Ele é ativado por padrão para todos os servidores recém-provisionados que suportam até 16 TB de armazenamento. Em servidores de réplica, dois threads são executados em cada servidor de réplica. Um thread é o thread IO e o outro é o thread SQL:
- O thread de E/S se conecta ao servidor de origem e solicita logs binários atualizados. Este thread recebe as atualizações de log binário. Essas atualizações são salvas em um servidor de réplica, em um log local chamado log de retransmissão.
- O thread SQL lê o log de retransmissão e, em seguida, aplica as alterações de dados em servidores de réplica.
Monitorando a latência de replicação
O Banco de Dados do Azure para MySQL fornece a métrica de atraso de replicação em segundos no Azure Monitor. Essa métrica está disponível apenas em servidores de réplica de leitura. É calculado pela métrica seconds_behind_master disponível no MySQL.
Para entender a causa do aumento da latência de replicação, conecte-se ao servidor de réplica usando o MySQL Workbench ou o Azure Cloud Shell. Em seguida, execute o seguinte comando.
Nota
No código, substitua os valores de exemplo pelo nome do servidor de réplica e pelo nome de usuário do administrador. O nome de usuário admin requer @\<servername> o Banco de Dados do Azure para MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Veja como fica a experiência no terminal do Cloud Shell:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
No mesmo terminal do Cloud Shell, execute o seguinte comando:
mysql> SHOW SLAVE STATUS;
Aqui está uma saída típica:
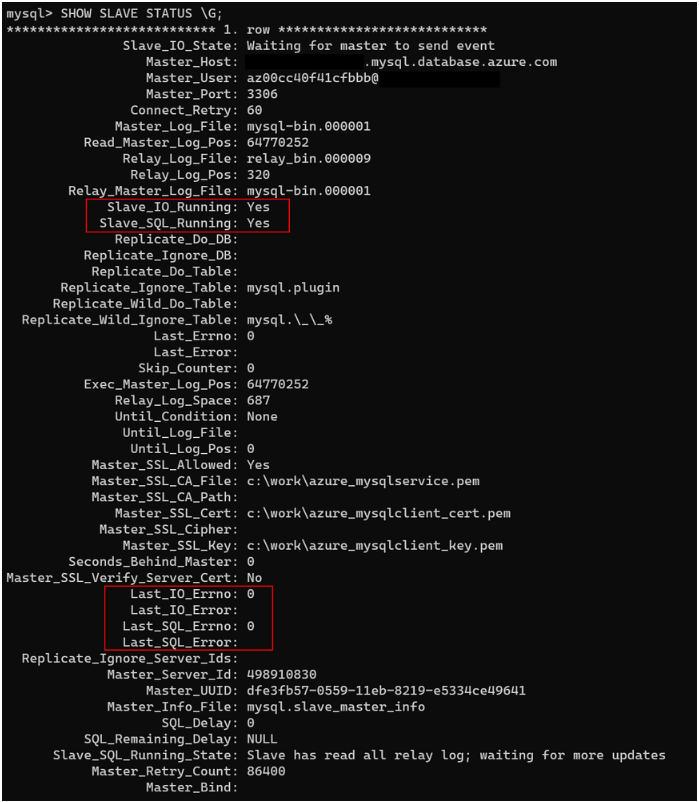
A saída contém inúmeras informações. Normalmente, você precisa se concentrar apenas nas linhas descritas na tabela a seguir.
| Métrico | Description |
|---|---|
| Slave_IO_State | Representa o status atual do thread de E/S. Normalmente, o status é "Aguardando evento mestre para enviar" se o servidor de origem (mestre) estiver sincronizando. Um status como "Conectando-se ao mestre" indica que a réplica perdeu a conexão com o servidor de origem. Verifique se o servidor de origem está em execução ou verifique se um firewall está bloqueando a conexão. |
| Master_Log_File | Representa o arquivo de log binário no qual o servidor de origem está gravando. |
| Read_Master_Log_Pos | Indica onde o servidor de origem está gravando no arquivo de log binário. |
| Relay_Master_Log_File | Representa o arquivo de log binário que o servidor de réplica está lendo do servidor de origem. |
| Slave_IO_Running | Indica se o thread de E/S está em execução. O valor deve ser Yes. Se o valor for NO, é provável que a replicação seja interrompida. |
| Slave_SQL_Running | Indica se o thread SQL está em execução. O valor deve ser Yes. Se o valor for NO, é provável que a replicação seja interrompida. |
| Exec_Master_Log_Pos | Indica a posição do Relay_Master_Log_File que a réplica está aplicando. Se houver latência, essa sequência de posição deve ser menor que Read_Master_Log_Pos. |
| Relay_Log_Space | Indica o tamanho total combinado de todos os arquivos de log de retransmissão existentes. Você pode verificar o tamanho do limite superior consultando SHOW GLOBAL VARIABLES como relay_log_space_limit. |
| Seconds_Behind_Master | Exibe a latência de replicação em segundos. |
| Last_IO_Errno | Exibe o código de erro do thread de E/S, se houver. Para obter mais informações sobre esses códigos, consulte a referência de mensagem de erro do servidor MySQL. |
| Last_IO_Error | Exibe a mensagem de erro do thread de E/S, se houver. |
| Last_SQL_Errno | Exibe o código de erro do thread SQL, se houver. Para obter mais informações sobre esses códigos, consulte a referência de mensagem de erro do servidor MySQL. |
| Last_SQL_Error | Exibe a mensagem de erro do thread SQL, se houver. |
| Slave_SQL_Running_State | Indica o status atual do thread SQL. Neste estado, System lock é normal. Também é normal ver um status de Waiting for dependent transaction to commit. Esse status indica que a réplica está aguardando outros threads de trabalho do SQL para atualizar as transações confirmadas. |
Se Slave_IO_Running for Yes e Slave_SQL_Running for Yes, a replicação está funcionando bem.
Em seguida, verifique Last_IO_Errno, Last_IO_Error, Last_SQL_Errno e Last_SQL_Error. Esses campos exibem o número do erro e a mensagem de erro do erro mais recente que causou a interrupção do thread SQL. Um número de erro e 0 uma mensagem vazia significa que não há erro. Investigue qualquer valor de erro diferente de zero verificando o código de erro na referência da mensagem de erro do servidor MySQL.
Cenários comuns para alta latência de replicação
As seções a seguir abordam cenários nos quais a alta latência de replicação é comum.
Latência de rede ou alto consumo de CPU no servidor de origem
Se você vir os seguintes valores, a latência de replicação provavelmente será causada pela alta latência da rede ou pelo alto consumo de CPU no servidor de origem.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
Nesse caso, o thread de E/S está em execução e aguardando no servidor de origem. O servidor de origem já gravou no arquivo de log binário número 20. A réplica recebeu apenas até o número de arquivo 10. Os principais fatores para a alta latência de replicação nesse cenário são a velocidade da rede ou a alta utilização da CPU no servidor de origem.
No Azure, a latência de rede dentro de uma região normalmente pode ser medida em milissegundos. Entre regiões, a latência varia de milissegundos a segundos.
Na maioria dos casos, o atraso de conexão entre threads de E/S e o servidor de origem é causado pela alta utilização da CPU no servidor de origem. Os threads de E/S são processados lentamente. Você pode detetar esse problema usando o Azure Monitor para verificar a utilização da CPU e o número de conexões simultâneas no servidor de origem.
Se você não vir alta utilização da CPU no servidor de origem, o problema pode ser a latência da rede. Se a latência da rede for repentinamente anormalmente alta, verifique a página de status do Azure para problemas conhecidos ou interrupções.
Altas explosões de transações no servidor de origem
Se você vir os seguintes valores, uma grande explosão de transações no servidor de origem provavelmente está causando a latência de replicação.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
A saída mostra que a réplica pode recuperar o log binário atrás do servidor de origem. Mas o thread de E/S da réplica indica que o espaço do log de retransmissão já está cheio.
A velocidade da rede não está causando o atraso. A réplica está a tentar recuperar o atraso. Mas o tamanho do log binário atualizado excede o limite superior do espaço do log de retransmissão.
Para solucionar esse problema, habilite o log de consulta lenta no servidor de origem. Use logs de consulta lentos para identificar transações de longa execução no servidor de origem. Em seguida, ajuste as consultas identificadas para reduzir a latência no servidor.
A latência de replicação desse tipo geralmente é causada pela carga de dados no servidor de origem. Quando os servidores de origem têm cargas de dados semanais ou mensais, a latência de replicação é, infelizmente, inevitável. Os servidores de réplica eventualmente alcançam o atraso após a conclusão da carga de dados no servidor de origem.
Lentidão no servidor de réplica
Se você observar os seguintes valores, o problema pode estar no servidor de réplica.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
Nesse cenário, a saída mostra que o thread de E/S e o thread SQL estão funcionando bem. A réplica lê o mesmo arquivo de log binário que o servidor de origem grava. No entanto, alguma latência no servidor de réplica reflete a mesma transação do servidor de origem.
As seções a seguir descrevem causas comuns desse tipo de latência.
Nenhuma chave primária ou chave exclusiva em uma tabela
O Banco de Dados do Azure para MySQL usa replicação baseada em linha. O servidor de origem grava eventos no log binário, registrando as alterações em linhas individuais da tabela. Em seguida, o thread SQL replica essas alterações para as linhas de tabela correspondentes no servidor de réplica. Quando uma tabela não possui uma chave primária ou uma chave exclusiva, o thread SQL verifica todas as linhas da tabela de destino para aplicar as alterações. Esta verificação pode causar latência da replicação.
No MySQL, a chave primária é um índice associado que garante um desempenho de consulta rápido porque não pode incluir valores NULL. Se você usar o mecanismo de armazenamento InnoDB, os dados da tabela serão fisicamente organizados para fazer pesquisas e classificações ultrarrápidas com base na chave primária.
Recomendamos que você adicione uma chave primária em tabelas no servidor de origem antes de criar o servidor de réplica. Adicione chaves primárias no servidor de origem e recrie réplicas de leitura para ajudar a melhorar a latência da replicação.
Use a consulta a seguir para descobrir quais tabelas estão faltando uma chave primária no servidor de origem:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Consultas de longa execução no servidor de réplica
A carga de trabalho no servidor de réplica pode fazer com que o thread SQL fique atrás do thread de E/S. Consultas de longa execução no servidor de réplica são uma das causas comuns de alta latência de replicação. Para solucionar esse problema, habilite o log de consulta lenta no servidor de réplica.
Consultas lentas podem aumentar o consumo de recursos ou tornar o servidor mais lento para que a réplica não possa alcançar o servidor de origem. Nesse cenário, ajuste as consultas lentas. Consultas mais rápidas evitam o bloqueio do thread SQL e melhoram significativamente a latência de replicação.
Consultas DDL no servidor de origem
No servidor de origem, um comando DDL (linguagem de definição de dados) como ALTER TABLE pode levar muito tempo. Enquanto o comando DDL está em execução, milhares de outras consultas podem estar sendo executadas em paralelo no servidor de origem.
Quando a DDL é replicada, para garantir a consistência do banco de dados, o mecanismo MySQL executa a DDL em um único thread de replicação. Durante essa tarefa, todas as outras consultas replicadas são bloqueadas e devem aguardar até que a operação DDL seja concluída no servidor de réplica. Até mesmo as operações DDL on-line causam esse atraso. As operações DDL aumentam a latência de replicação.
Se você habilitou o log de consulta lenta no servidor de origem, poderá detetar esse problema de latência verificando se há um comando DDL executado no servidor de origem. Através da queda de índice, renomeação e criação, você pode usar o algoritmo INPLACE para a ALTER TABLE. Talvez seja necessário copiar os dados da tabela e reconstruí-la.
Normalmente, DML simultâneo é suportado para o algoritmo INPLACE. Mas você pode pegar brevemente um bloqueio de metadados exclusivo na tabela quando preparar e executar a operação. Portanto, para a instrução CREATE INDEX, você pode usar as cláusulas ALGORITHM e LOCK para influenciar o método de cópia de tabela e o nível de simultaneidade para leitura e gravação. Você ainda pode impedir operações DML adicionando um índice FULLTEXT ou um índice ESPACIAL.
O exemplo a seguir cria um índice usando as cláusulas ALGORITHM e LOCK.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Infelizmente, para uma instrução DDL que requer um bloqueio, não é possível evitar a latência de replicação. Para reduzir os efeitos potenciais, faça este tipo de operações DDL fora das horas de ponta, por exemplo, durante a noite.
Servidor de réplica rebaixado
No Banco de Dados do Azure para MySQL, as réplicas de leitura usam a mesma configuração de servidor que o servidor de origem. Você pode alterar a configuração do servidor de réplica depois que ele for criado.
Se o servidor de réplica for rebaixado, a carga de trabalho poderá consumir mais recursos, o que, por sua vez, pode levar à latência da replicação. Para detetar esse problema, use o Azure Monitor para verificar o consumo de CPU e memória do servidor de réplica.
Nesse cenário, recomendamos que você mantenha a configuração do servidor de réplica em valores iguais ou maiores que os valores do servidor de origem. Essa configuração permite que a réplica acompanhe o servidor de origem.
Melhorando a latência de replicação ajustando os parâmetros do servidor de origem
No Banco de Dados do Azure para MySQL, por padrão, a replicação é otimizada para ser executada com threads paralelos em réplicas. Quando cargas de trabalho de alta simultaneidade no servidor de origem fazem com que o servidor de réplica fique para trás, você pode melhorar a latência de replicação configurando o parâmetro binlog_group_commit_sync_delay no servidor de origem.
O parâmetro binlog_group_commit_sync_delay controla quantos microssegundos a confirmação de log binário aguarda antes de sincronizar o arquivo de log binário. O benefício desse parâmetro é que, em vez de aplicar imediatamente todas as transações confirmadas, o servidor de origem envia as atualizações de log binário em massa. Esse atraso reduz a E/S na réplica e ajuda a melhorar o desempenho.
Pode ser útil definir o parâmetro binlog_group_commit_sync_delay para 1000 ou mais. Em seguida, monitore a latência da replicação. Defina esse parâmetro com cautela e use-o apenas para cargas de trabalho de alta simultaneidade.
Importante
No servidor de réplica, binlog_group_commit_sync_delay parâmetro é recomendado como 0. Isso é recomendado porque, ao contrário do servidor de origem, o servidor de réplica não terá alta simultaneidade e aumentar o valor de binlog_group_commit_sync_delay no servidor de réplica pode inadvertidamente fazer com que o atraso de replicação aumente.
Para cargas de trabalho de baixa simultaneidade que incluem muitas transações singleton, a configuração binlog_group_commit_sync_delay pode aumentar a latência. A latência pode aumentar porque o thread de E/S aguarda atualizações de log binário em massa, mesmo que apenas algumas transações sejam confirmadas.
Opções avançadas de solução de problemas
Se o uso do comando show slave status não fornecer informações suficientes para solucionar problemas de latência de replicação, tente visualizar essas opções adicionais para saber quais processos estão ativos ou aguardando.
Ver a tabela de threads
A performance_schema.threads tabela mostra o estado do processo. Um processo com o estado Aguardando bloqueio lock_type indica que há um bloqueio em uma das tabelas, impedindo que o thread de replicação atualize a tabela.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Para obter mais informações, consulte General Thread States.
Ver a tabela replication_connection_status
A tabela performance_schema.replication_connection_status mostra o status atual do thread de E/S de replicação que lida com a conexão da réplica com a origem e é alterado com mais frequência. A tabela contém valores que variam durante a conexão.
SELECT * FROM performance_schema.replication_connection_status;
Ver a tabela replication_applier_status_by_worker
A performance_schema.replication_applier_status_by_worker tabela mostra o status dos threads de trabalho, a última transação vista, juntamente com o número do último erro e a mensagem, que ajudam você a encontrar a transação com problema e identificar a causa raiz.
Você pode executar os comandos abaixo na replicação Data-in para ignorar erros ou transações:
az_replication_skip_counter
ou
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
Veja a instrução SHOW RELAYLOG EVENTS
A show relaylog events instrução mostra os eventos no log de retransmissão de uma réplica.
· Para replicação baseada em GITD (réplica de leitura), a instrução mostra a transação GTID e o arquivo binlog e sua posição, você pode usar mysqlbinlog para obter conteúdo e instruções sendo executados. · Para a replicação de posição binlog do MySQL (usada para replicação de dados), ele mostra instruções sendo executadas, o que ajudará a saber em quais transações de tabela estão sendo executadas
Verifique a saída do Monitor Padrão InnoDB e do Monitor de Bloqueio
Você também pode tentar verificar a saída do InnoDB Standard Monitor e do Lock Monitor para ajudar na resolução de bloqueios e deadlocks e minimizar o atraso de replicação. O Monitor de bloqueio é o mesmo que o Monitor padrão, exceto que inclui informações de bloqueio adicionais. Para exibir essas informações adicionais de bloqueio e impasse, execute o comando show engine innodb status\G.
Próximos passos
Confira a visão geral da replicação binlog do MySQL.