O que é a recuperação após desastre?
Um desastre é um evento único e importante com um impacto maior e mais duradouro do que um aplicativo pode mitigar por meio da parte de alta disponibilidade de seu projeto. A recuperação de desastres (DR) consiste na recuperação de eventos de alto impacto, como desastres naturais ou implantações com falha, que resultam em tempo de inatividade e perda de dados. Independentemente da causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que suporte ativamente a DR.
Objetivos de recuperação
Um plano de DR completo deve especificar os seguintes requisitos de negócios críticos para cada processo implementado pelo aplicativo:
O RPO (Recovery Point Objetive, objetivo de ponto de recuperação) é a duração máxima da perda de dados aceitável. O RPO é medido em unidades de tempo, não em volume, como "30 minutos de dados" ou "quatro horas de dados". RPO é sobre limitar e recuperar da perda de dados, não roubo de dados.
O RTO (Recovery Time Objetive, objetivo de tempo de recuperação) é a duração máxima aceitável do tempo de inatividade, onde o "tempo de inatividade" é definido pela sua especificação. Por exemplo, se a duração aceitável do tempo de inatividade em um desastre for de oito horas, o RTO será de oito horas.
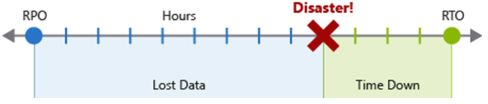
Cada processo ou carga de trabalho importante que um aplicativo implementa deve ter valores de RPO e RTO separados, examinando riscos de cenário de desastre e estratégias de recuperação potenciais. O processo de especificação de um RPO e RTO cria efetivamente requisitos de DR para seu aplicativo como resultado de suas preocupações comerciais exclusivas (custos, impacto, perda de dados, etc.).
Conceber para a recuperação após desastre
A recuperação de desastres não é um recurso automático, mas deve ser projetada, criada e testada. Para dar suporte a uma estratégia sólida de DR, você deve criar um aplicativo com DR em mente desde o início. O Azure oferece serviços, recursos e orientação para ajudá-lo a dar suporte à DR ao criar aplicativos.
Recuperação de dados
Durante um desastre, há dois métodos principais de restauração de dados: backups e replicação.
O backup restaura os dados para um point-in-time específico. Usando o backup, você pode fornecer soluções simples, seguras e econômicas para fazer backup e recuperar seus dados na nuvem do Microsoft Azure. Use o Backup do Azure para criar instantâneos de dados somente leitura de longa duração para uso na recuperação.
A replicação de dados cria cópias em tempo real ou quase em tempo real de dados em tempo real em várias réplicas de armazenamento de dados com perda mínima de dados em mente. O objetivo da replicação é manter as réplicas sincronizadas com o mínimo de latência possível, conservando a capacidade de resposta da aplicação. A maioria dos sistemas de banco de dados com recursos completos e outros produtos e serviços de armazenamento de dados incluem algum tipo de replicação como um recurso totalmente integrado, devido aos seus requisitos funcionais e de desempenho. Um exemplo disso é o armazenamento com redundância geográfica (GRS).
Diferentes projetos de replicação colocam prioridades diferentes na consistência, no desempenho e no custo dos dados.
A Replicação Ativa requer atualizações para ocorrer em várias réplicas ao mesmo tempo, garantindo a consistência ao custo de débito.
A replicação passiva faz a sincronização em segundo plano, removendo a replicação como uma restrição no desempenho do aplicativo, mas aumentando o RPO.
A replicação ativa-ativa ou multimaster permite o uso de várias réplicas simultaneamente, permitindo o balanceamento de carga ao custo de complicar a consistência dos dados.
A replicação ativa-passiva reserva réplicas apenas para uso em tempo real durante o failover.
Nota
A maioria dos sistemas de banco de dados com recursos completos e outros produtos e serviços de armazenamento de dados incluem algum tipo de replicação, como o armazenamento com redundância geográfica (GRS), devido aos seus requisitos funcionais e de desempenho.
Criação de aplicações resilientes
Os cenários de desastre também geralmente resultam em tempo de inatividade, seja devido a problemas de conectividade de rede, interrupções do datacenter, máquinas virtuais (VMs) danificadas ou implantações de software corrompidas. Na maioria dos casos, a recuperação de aplicativos envolve failover para uma implantação separada e funcional. Como resultado, pode ser necessário recuperar processos em outra região do Azure no caso de um desastre de grande escala. Considerações adicionais podem incluir: locais de recuperação, número de ambientes replicados e como manter esses ambientes.
Dependendo do design do seu aplicativo, você pode usar várias estratégias diferentes e recursos do Azure, como o Azure Site Recovery, para melhorar o suporte do seu aplicativo para recuperação de processos após um desastre.
Recursos de recuperação de desastres específicos do serviço
A maioria dos serviços executados na plataforma Azure como um serviço (PaaS), ofertas como o Serviço de Aplicativo do Azure, fornece recursos e orientação para dar suporte à DR. Para alguns cenários, você pode usar recursos específicos do serviço para oferecer suporte à recuperação rápida. Por exemplo, o SQL Server do Azure suporta a georreplicação para restaurar rapidamente o serviço noutra região. O Serviço de Aplicações do Azure dispõe de um recurso de Cópia de segurança e de Restauro e a documentação inclui orientações de utilização do Gestor de Tráfego do Microsoft Azure para suportar o encaminhamento de tráfego para uma região secundária.