Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo descreve o suporte à confiabilidade no Azure HDInsight e aborda zonas de disponibilidade, recuperação entre regiões e continuidade de negócios. Para obter uma visão geral mais detalhada da confiabilidade no Azure, consulte Confiabilidade do Azure.
Suporte à zona de disponibilidade
As zonas de disponibilidade são grupos fisicamente separados de centros de dados dentro de uma região Azure. Quando uma zona falha, os serviços podem ser transferidos para uma das zonas restantes.
O Azure HDInsight dá suporte a uma configuração de implantação zonal. Os nós de cluster do Azure HDInsight são colocados em uma única zona selecionada na região selecionada. Um cluster HDInsight zonal é isolado de quaisquer interrupções que ocorram em outras zonas. No entanto, se uma interrupção afetar a zona específica escolhida para o cluster HDInsight, o cluster não estará disponível. Esse modelo de implantação fornece conectividade de rede barata e de baixa latência dentro do cluster. Replicar esse modelo de implantação em várias zonas de disponibilidade pode fornecer um nível mais alto de disponibilidade para proteção contra falhas de hardware.
Importante
Para implantações em que os utilizadores não especificam uma zona específica, os tipos de nó não são resilentes à zona e podem enfrentar períodos de inatividade durante uma interrupção em qualquer zona dessa região.
Pré-requisitos
As zonas de disponibilidade só são suportadas para clusters criados após 15 de junho de 2023. As configurações da zona de disponibilidade não podem ser atualizadas após a criação do cluster. Também não é possível atualizar um cluster de zona de indisponibilidade existente para usar zonas de disponibilidade.
Os clusters devem ser criados em uma VNet personalizada.
Você precisa fornecer a sua própria base de dados SQL para a Ambari DB e o metastore externo, como o metastore do Hive, para que possa configurar essas bases de dados na mesma zona de disponibilidade.
Os clusters HDInsight devem ser criados com a opção de zona de disponibilidade em uma das seguintes regiões:
- Leste da Austrália
- Sul do Brasil
- Canadá Central
- E.U.A. Central
- E.U.A. Leste
- E.U.A. Leste 2
- Centro de França
- Alemanha Centro-Oeste
- Leste do Japão
- Coreia Central
- Europa do Norte
- Catar Central
- Sudeste Asiático
- E.U.A. Centro-Sul
- Sul do Reino Unido
- US Gov - Virginia
- Europa Ocidental
- E.U.A. Oeste 2
Criar um cluster HDInsight usando a zona de disponibilidade
Você pode usar o modelo ARM (Azure Resource Manager) para iniciar um cluster HDInsight em uma zona de disponibilidade especificada.
Na seção de recursos, você precisa adicionar uma seção de 'zonas' e fornecer em qual zona de disponibilidade você deseja que esse cluster seja implantado.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Verificar nós dentro de uma zona de disponibilidade entre zonas
Quando o cluster HDInsight estiver pronto, você poderá verificar o local para ver em qual zona de disponibilidade eles serão implantados.
Obtenha a resposta da API:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Aumentar a escala do cluster
Você pode escalar um cluster HDInsight com mais nós de processamento. Os nós de trabalho recém-adicionados serão colocados na mesma zona de disponibilidade deste cluster.
Migração da zona de disponibilidade
Atualmente, os clusters do Azure HDInsight não dão suporte à migração in-loco de instâncias de cluster existentes para o suporte à zona de disponibilidade. No entanto, você pode optar por recriar seu cluster e escolher uma zona ou região de disponibilidade diferente durante a criação do cluster. Um cluster secundário em espera em uma região diferente e uma zona de disponibilidade diferente podem ser usados em cenários de recuperação de desastres.
Experiência de redução de intensidade
Quando uma zona de disponibilidade fica inativa:
- Não é possível ssh para este cluster.
- Não é possível excluir, aumentar ou reduzir esse cluster.
- Não é possível enviar trabalhos ou ver o histórico de trabalhos.
- Você ainda pode enviar uma nova solicitação de criação de cluster em uma região diferente.
Recuperação de desastres entre regiões e continuidade de negócios
A recuperação de desastres (DR) refere-se a práticas que as organizações usam para se recuperar de eventos de alto impacto, como desastres naturais ou implantações com falha que resultam em tempo de inatividade e perda de dados. Independentemente da causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que suporte ativamente a DR. Antes de começar a criar seu plano de recuperação de desastres, consulte Recomendações para projetar uma estratégia de recuperação de desastres.
Para DR, a Microsoft usa o modelo de responsabilidade compartilhada . Neste modelo, a Microsoft garante que a infraestrutura de linha de base e os serviços da plataforma estejam disponíveis. No entanto, muitos serviços do Azure não replicam dados automaticamente nem possuem mecanismos de fallback para mudar de uma região com falha para outra região ativada. Para esses serviços, você é responsável por configurar um plano de recuperação de desastres que funcione para sua carga de trabalho. A maioria dos serviços executados nas ofertas da plataforma Azure como serviço (PaaS) fornece recursos e orientações para dar suporte à DR. Você pode usar recursos específicos do serviço para apoiar a recuperação rápida e ajudar a desenvolver o seu plano de DR.
Os clusters do Azure HDInsight dependem de muitos serviços do Azure, como armazenamento, bancos de dados, Ative Directory, Serviços de Domínio Ative Directory, rede e Cofre da Chave. Um aplicativo de análise bem projetado, altamente disponível e tolerante a falhas deve ser projetado com redundância suficiente para resistir a interrupções regionais ou locais em um ou mais desses serviços. Esta seção fornece uma visão geral das práticas recomendadas, disponibilidade de uma e várias regiões e opções de otimização para o planejamento de continuidade de negócios.
Recuperação de desastres em geografia de várias regiões
Melhorar a continuidade de negócios usando a recuperação de desastres de alta disponibilidade entre regiões requer projetos arquitetônicos de maior complexidade e maior custo. As tabelas a seguir detalham algumas áreas técnicas que podem aumentar o custo total de propriedade.
Otimizações de custos
| Area | Causa da escalada de custos | Estratégias de otimização |
|---|---|---|
| Armazenamento de dados | Duplicação de dados/tabelas primários em uma região secundária | Replicar apenas dados selecionados |
| Egressão de Dados | As transferências de dados de saída entre regiões têm um preço. Revise as diretrizes de preços de largura de banda | Replicar apenas dados cuidadosamente selecionados para reduzir o tráfego de saída da região |
| Computação em cluster | Cluster/s HDInsight adicionais na região secundária | Use scripts automatizados para implantar a computação secundária após a falha primária. Use o dimensionamento automático para manter o tamanho do cluster secundário ao mínimo. Use SKUs VM mais baratas. Crie secundários em regiões onde as SKUs de VM podem ser descontadas. |
| Authentication | Cenários multiusuário na região secundária incorrem em configurações extras dos Serviços de Domínio Microsoft Entra | Evite configurações multiusuário na região secundária. |
Otimizações de complexidade
| Area | Causa do escalonamento da complexidade | Estratégias de otimização |
|---|---|---|
| Padrões de leitura e escrita | Exigir que o primário e o secundário estejam habilitados para leitura e gravação | Desenhe o secundário para ser somente leitura |
| Zero RPO e RTO | Exigindo zero perda de dados (RPO=0) e zero tempo de inatividade (RTO=0) | Projete RPO e RTO de forma a reduzir o número de componentes que precisam fazer failover. Para obter mais informações sobre RTO e RPO, consulte O que são continuidade de negócios, alta disponibilidade e recuperação de desastres?. |
| Funcionalidade empresarial | Exigência de funcionalidade de negócio completa do sistema primário no secundário | Avalie se é possível operar o subconjunto crítico mínimo das funcionalidades de negócio num ambiente secundário. |
| Connectivity | Exigindo que todos os sistemas a montante e a jusante do primário se conectem ao secundário também | Limite a conectividade secundária a um subconjunto crítico mínimo. |
Ao criar seu plano de recuperação de desastres em várias regiões, considere as seguintes recomendações:
Determine a funcionalidade mínima de negócios necessária se houver um desastre e por quê. Por exemplo, avalie se você precisa de recursos de failover para a camada de transformação de dados (mostrada em amarelo) e a camada de serviço de dados (mostrada em azul), ou se você só precisa de failover para a camada de serviço de dados.
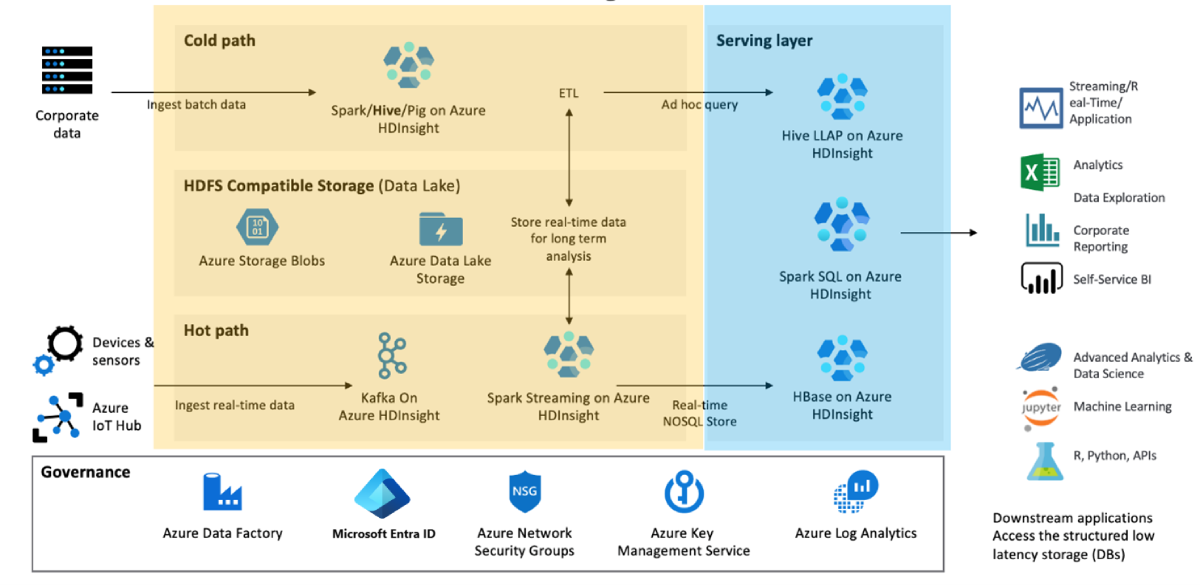
Segmente seus clusters com base na carga de trabalho, no ciclo de vida de desenvolvimento e nos departamentos. Ter mais clusters reduz as chances de uma única grande falha afetar vários processos de negócios diferentes.
Torne suas regiões secundárias somente leitura. Regiões de failover com recursos de leitura e gravação podem levar a arquiteturas complexas.
Clusters transitórios são mais fáceis de gerenciar quando há um desastre. Projete suas cargas de trabalho de forma que os clusters possam ser alternados e nenhum estado seja mantido nos clusters.
Muitas vezes, as cargas de trabalho são deixadas inacabadas se houver um desastre e precisarem ser reiniciadas na nova região. Projete suas cargas de trabalho para serem idempotentes por natureza.
Use automação durante os desdobramentos de clusters e garanta que as definições de configuração do cluster sejam programadas tanto quanto possível para assegurar uma implantação rápida e totalmente automatizada em caso de desastre.
Deteção, notificação e gerenciamento de interrupções
Use as ferramentas de monitoramento do Azure no HDInsight para detetar comportamentos anormais no cluster e definir as notificações de alerta correspondentes. Você pode implantar as soluções de gerenciamento específicas de cluster HDInsight pré-configuradas que coletam métricas de desempenho importantes do tipo de cluster específico. Para obter mais informações, consulte Monitoramento do Azure para HDInsight.
Assine os alertas de integridade do Azure para ser notificado sobre problemas de serviço, manutenção planejada, avisos de integridade e segurança de uma assinatura, serviço ou região. As notificações de saúde que incluem a causa do problema e a estimativa de tempo de resolução ajudam a executar melhor o failover e os failbacks. Para obter mais informações, consulte a documentação do Azure Service Health.
Recuperação de desastres em geografia de uma única região
Cada componente de um sistema HDInsight básico tem seus próprios mecanismos de tolerância a falhas de região única. Lembre-se de que nem sempre é necessário um evento catastrófico para afetar a funcionalidade dos negócios. Incidentes de serviço em um ou mais dos seguintes serviços em uma única região também podem levar à perda da funcionalidade de negócios esperada.
Computação (máquinas virtuais): grupo de Azure HDInsight. O HDInsight oferece um SLA de disponibilidade de 99,9%. Para fornecer alta disponibilidade em uma única implantação, o HDInsight é acompanhado por muitos serviços que estão no modo de alta disponibilidade por padrão. Os mecanismos de tolerância a falhas no HDInsight são fornecidos pelos serviços de alta disponibilidade do ecossistema Microsoft e Apache OSS.
Os seguintes componentes de infraestrutura são projetados para serem altamente disponíveis:
- Nodos principais ativos e em espera
- Vários nós de gateway
- Três nós do Quórum Zookeeper
- Nós de trabalho distribuídos por domínios de falha e atualização
Os seguintes serviços também são projetados para serem altamente disponíveis:
- Servidor Apache Ambari
- Interrupções na linha temporal de aplicações para YARN
- Servidor de histórico de trabalho para Hadoop MapReduce
- Apache Lívio
- HDFS (Sistema de Arquivos Distribuídos Hadoop)
- Gerente de Recursos YARN
- HBase Master
Para saber mais, consulte Serviços de alta disponibilidade suportados pelo Azure HDInsight.
Metastore(s): Banco de Dados SQL do Azure. O HDInsight usa o Banco de Dados SQL do Azure como um metastore, que fornece um SLA de 99,99%. Três réplicas de dados persistem em um data center com replicação síncrona. Se houver uma perda de réplica, uma réplica alternativa será servida de forma contínua. A replicação geográfica ativa é suportada de imediato com um máximo de quatro centros de dados. Quando ocorre um failover, seja ele manual ou devido a um centro de dados, a primeira réplica na hierarquia torna-se automaticamente capaz de ler e gravar. Para obter mais informações, consulte Continuidade de negócios do Banco de Dados SQL do Azure.
Armazenamento: Azure Data Lake Gen2 ou Blob storage. O HDInsight recomenda o Azure Data Lake Storage Gen2 como a camada de armazenamento subjacente. O Armazenamento do Azure, incluindo o Azure Data Lake Storage Gen2, fornece um SLA de 99,9%. O HDInsight usa o serviço LRS, no qual três réplicas de dados persistem em um data center e a replicação é síncrona. Quando há uma perda de réplica, uma réplica é servida sem interrupção.
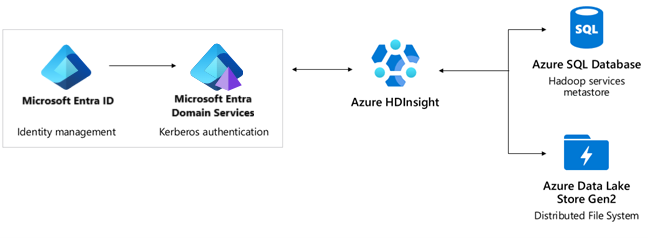
Autenticação: Microsoft Entra ID, Microsoft Entra Domain Services, Enterprise Security Package.
- O Microsoft Entra ID fornece um SLA de 99,9%. O Ative Directory é um serviço global com vários níveis de redundância interna e capacidade de recuperação automática. Para obter mais informações, consulte como a Microsoft está melhorando continuamente a confiabilidade do Microsoft Entra ID.
- O Microsoft Entra Domain Services fornece um SLA de 99,9%. O Microsoft Entra Domain Services é um serviço altamente disponível hospedado em data centers distribuídos globalmente. Os conjuntos de réplicas são um recurso de visualização nos Serviços de Domínio Microsoft Entra que permite a recuperação de desastres geográficos se uma região do Azure ficar offline. Para obter mais informações, consulte os conceitos e recursos de conjuntos de réplicas dos Serviços de Domínio Microsoft Entra.
- O DNS do Azure fornece um SLA de 100%. O HDInsight usa o DNS do Azure em vários locais para resolução de nomes de domínio.
Serviços opcionais, como o Azure Key Vault e o Azure Data Factory.