Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
No Azure AI Search, um conjunto de habilidades coordena as ações de habilidades que analisam, transformam ou criam conteúdo pesquisável. Frequentemente, o resultado de uma habilidade torna-se a entrada de outra. Quando as entradas dependem de saídas, erros nas definições do conjunto de habilidades e associações de campo podem resultar em operações e dados perdidos.
Debug Sessions é uma ferramenta do portal do Azure que fornece uma visualização holística de um conjunto de habilidades que é executado na Pesquisa de IA do Azure. Usando esta ferramenta, pode aprofundar-se em etapas específicas para ver facilmente onde uma ação pode falhar.
Neste tutorial, você usa Debug Sessions para localizar e corrigir entradas e saídas ausentes. O tutorial é completo. Ele fornece dados de exemplo, um arquivo REST que cria objetos e instruções para depurar problemas no conjunto de habilidades.
Pré-requisitos
Uma conta do Azure com uma assinatura ativa. Crie uma conta gratuitamente.
Azure AI Search. Crie um serviço ou encontre um serviço existente na sua subscrição atual. Você pode usar um serviço gratuito para este tutorial. A camada Gratuita não fornece suporte de identidade gerenciada para um serviço de Pesquisa de IA do Azure. Você deve usar chaves para conexões com o Armazenamento do Azure.
Conta de Armazenamento do Azure com armazenamento de Blob, usada para hospedar dados de exemplo e para persistir dados armazenados em cache criados durante uma sessão de depuração. Se estiver a utilizar um serviço de pesquisa gratuito, a conta de armazenamento tem de ter chaves de acesso partilhadas ativadas e tem de permitir o acesso à rede pública.
Exemplo do ficheiro debug-sessions.rest utilizado para criar o pipeline de enriquecimento.
Nota
Este tutorial também usa os serviços de IA do Azure para deteção de idioma, reconhecimento de entidade e extração de frases-chave. Como a carga de trabalho é muito pequena, os serviços de IA do Azure são aproveitados nos bastidores para processamento gratuito de até 20 transações. Isso significa que você pode concluir este exercício sem precisar criar um recurso faturável de serviços de IA do Azure.
Configurar os dados de exemplo
Esta seção cria o conjunto de dados de exemplo no Armazenamento de Blobs do Azure para que o indexador e o conjunto de habilidades tenham conteúdo para trabalhar.
Download de dados de amostra (clinical-trials-pdf-19), consistindo em 19 arquivos.
Crie uma conta de Armazenamento do Azure ou localize uma conta existente.
Escolha a mesma região que o Azure AI Search para evitar cobranças de largura de banda.
Escolha o tipo de conta StorageV2 (V2 de uso geral).
Vá para as páginas de serviços de Armazenamento do Azure no portal do Azure e crie um contêiner de Blob. A melhor prática é especificar o nível de acesso "privado". Atribua um nome ao seu contentor
clinicaltrialdataset.No contêiner, selecione Carregar para carregar os arquivos de exemplo baixados e descompactados na primeira etapa.
No portal do Azure, selecione Configurações>de Chaves de Acesso e copie a cadeia de conexão para o Armazenamento do Azure.
Copiar uma chave e um URL
Este tutorial usa chaves de API para autenticação e autorização. Você precisa do ponto de extremidade do serviço de pesquisa e de uma chave de API, que pode ser obtida no portal do Azure.
Entre no portal do Azure, vá para a página Visão geral e copie a URL. Um ponto final de exemplo poderá ser parecido com
https://mydemo.search.windows.net.Em Configurações>Teclas, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Existem duas chaves de administração intercambiáveis. Copie qualquer uma delas.
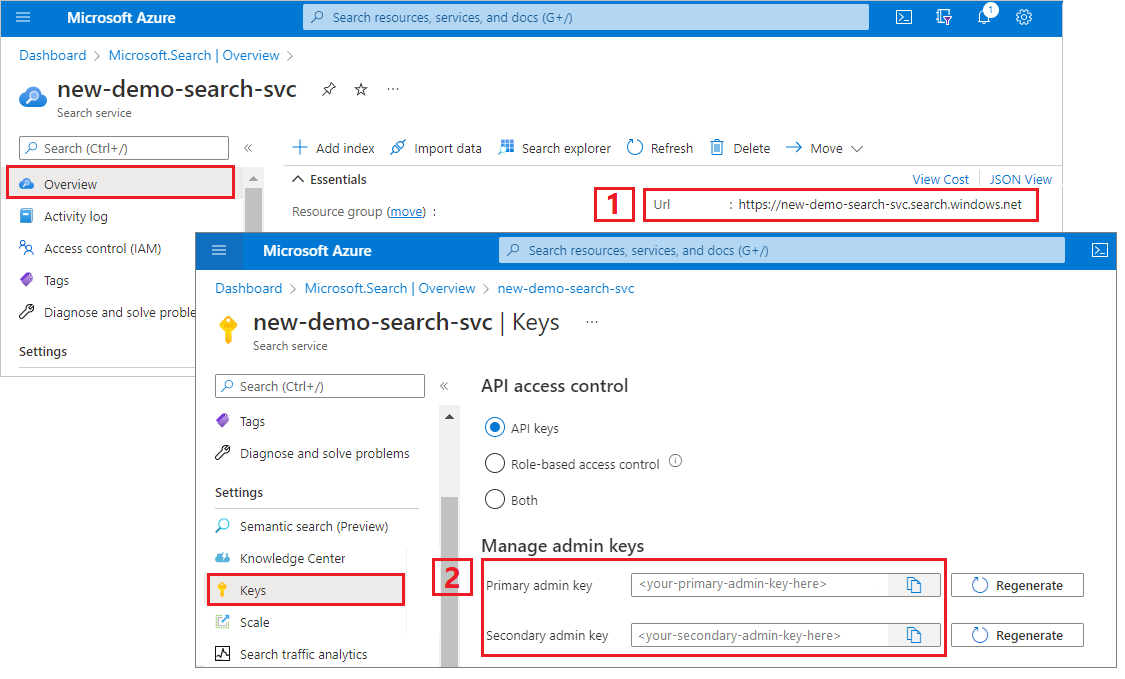
Uma chave de API válida estabelece confiança, por solicitação, entre o aplicativo que envia a solicitação e o serviço de pesquisa que a manipula.
Criar fonte de dados, conjunto de habilidades, índice e indexador
Nesta seção, crie um fluxo de trabalho defeituoso que você possa corrigir neste tutorial.
Inicie o Visual Studio Code e abra o
debug-sessions.restarquivo.Forneça as seguintes variáveis: URL do serviço de pesquisa, chave da API de administração dos serviços de pesquisa, cadeia de conexão de armazenamento e o nome do contêiner de blob que armazena os PDFs.
Envie cada pedido por vez. A criação do indexador leva vários minutos para ser concluída.
Feche o arquivo.
Verificar resultados no portal do Azure
O código de exemplo cria intencionalmente um índice de bugs como consequência de problemas que ocorreram durante a execução do conjunto de habilidades. O problema é que faltam dados no índice.
No portal do Azure, na página Visão geral do serviço de pesquisa, selecione o separador Índices.
Selecione ensaios clínicos.
Insira essa cadeia de caracteres de consulta JSON na visualização JSON do explorador de pesquisa. Ele retorna campos para documentos específicos (identificados pelo campo exclusivo
metadata_storage_path)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueExecutar a consulta. Você deve ver valores vazios para
organizationselocations.Esses campos devem ter sido preenchidos por meio da habilidade de Reconhecimento de Entidade do conjunto de competências, usada para detetar organizações e locais em qualquer parte do conteúdo do blob. No próximo exercício, você depura o conjunto de habilidades para determinar o que deu errado.
Outra maneira de investigar erros e avisos é por meio do portal do Azure.
Na guia Indexadores , selecione clinical-trials-idxr.
Observe que, embora o trabalho do indexador tenha sido bem-sucedido no geral, houve avisos.
Selecione Êxito para visualizar os avisos. Se houver principalmente erros, o link de detalhes é Falha. Você deve ver uma longa lista de todos os avisos emitidos pelo indexador.

Inicie sua sessão de depuração
No painel de navegação esquerdo do serviço de pesquisa, em Gerenciamento de pesquisa, selecione Depurar sessões.
Selecione + Adicionar sessão de depuração.
Dê um nome à sessão.
No modelo Indexador, forneça o nome do indexador. O indexador tem referências à fonte de dados, ao conjunto de habilidades e ao índice.
Selecione a conta de armazenamento.
Salve a sessão.
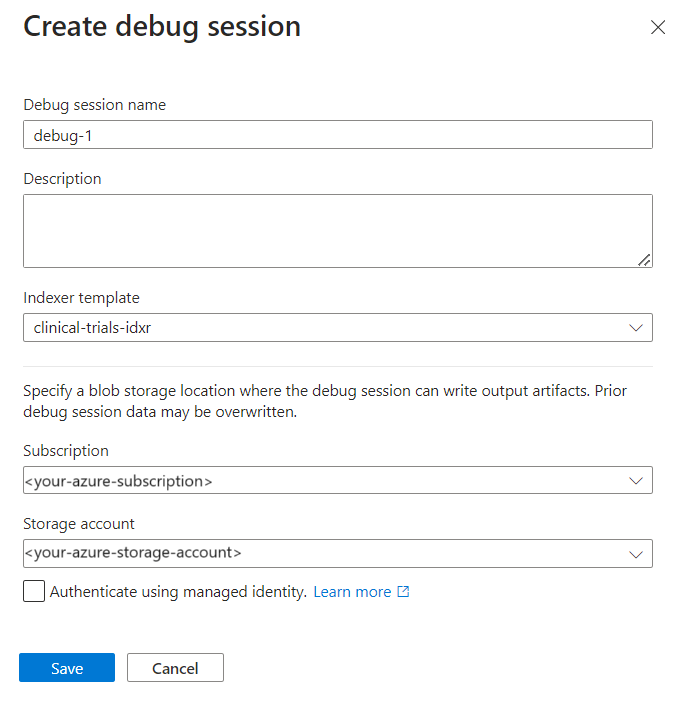
Uma sessão de depuração é aberta na página de configurações. Você pode fazer modificações na configuração inicial e substituir quaisquer predefinições. Uma sessão de depuração só funciona com um único documento. O padrão é aceitar o primeiro documento da coleção como base de suas sessões de depuração. Você pode escolher um documento específico para depurar fornecendo seu URI no Armazenamento do Azure.
Quando a sessão de depuração terminar de inicializar, você verá um fluxo de trabalho de habilidades com mapeamentos e um índice de pesquisa. A estrutura de dados do documento enriquecida aparece em um painel de detalhes ao lado. Nós o excluímos da captura de tela a seguir para que você pudesse ver mais do fluxo de trabalho.
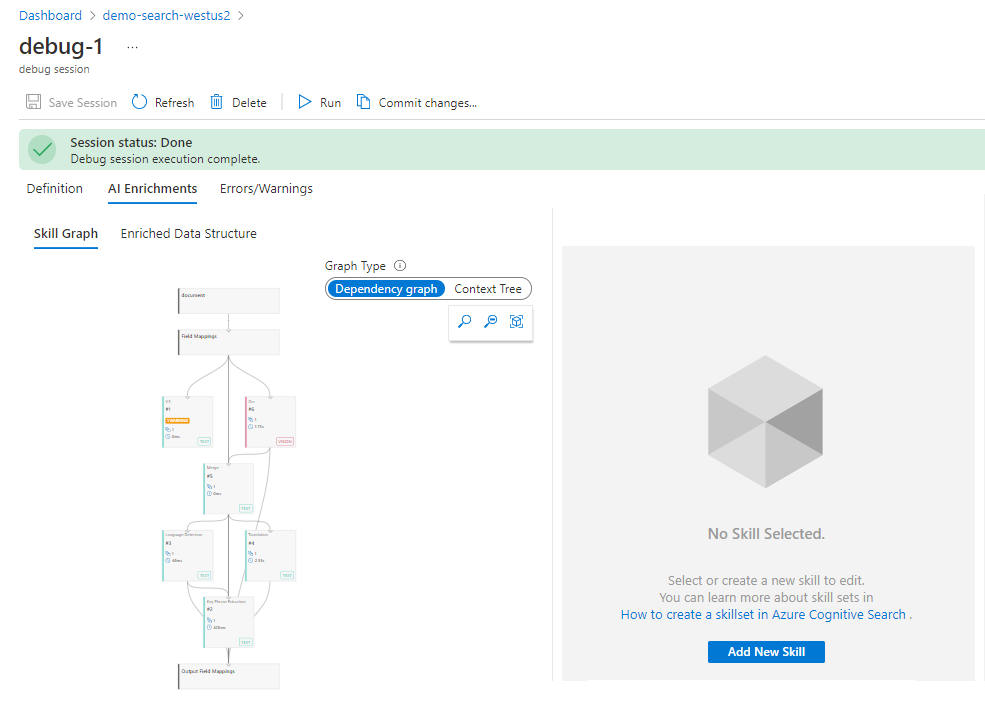


Identifique problemas com as habilidades
Quaisquer problemas relatados pelo indexador são indicados como Erros e Avisos.
Observe que o número de erros e avisos é uma lista menor do que a exibida anteriormente, porque essa lista está apenas detalhando os erros de um único documento. Como a lista exibida pelo indexador, você pode selecionar uma mensagem de aviso e ver os detalhes desse aviso.
Selecione Avisos para rever as notificações. Você deve ver quatro:
"Não foi possível executar habilidade porque uma ou mais entradas de habilidade eram inválidas. Falta a entrada de habilidades necessárias. Nome: 'texto', Fonte: '/documento/conteúdo'."
"Não foi possível mapear 'locais' do campo de saída para pesquisar o índice. Verifique a propriedade 'outputFieldMappings' do seu indexador. Valor em falta '/document/merged_content/locations'."
Não foi possível mapear o campo de saída 'organizações' para o índice de pesquisa. Verifique a propriedade 'outputFieldMappings' do seu indexador. Valor em falta '/document/merged_content/organizations'.'
"Habilidade executada, mas pode ter resultados inesperados porque uma ou mais entradas de habilidade foram inválidas. A entrada de habilidades opcionais está em falta. Nome: 'languageCode', Fonte: '/document/languageCode'. Problemas de análise de linguagem de expressão: valor ausente '/document/languageCode'."
Muitas habilidades têm um parâmetro "languageCode". Ao inspecionar a operação, você pode ver que essa entrada de código de linguagem está ausente do EntityRecognitionSkill.#1, que é a mesma habilidade de reconhecimento de entidade que está tendo problemas com a saída 'locais' e 'organizações'.
Como todas as quatro notificações são sobre esta competência, o seu próximo passo é corrigi-la. Se possível, comece resolvendo os problemas de entrada primeiro antes de passar para os problemas de saída.
Corrigir valores de entrada de habilidade ausentes
Na área de trabalho, selecione a função que está relatando os avisos. Neste tutorial, é a competência de reconhecimento de entidades.
O painel Detalhes da habilidade é aberto à direita com seções para iterações e suas respetivas entradas e saídas, configurações de habilidade para a definição JSON da habilidade e mensagens para quaisquer erros e avisos que essa habilidade esteja emitindo.
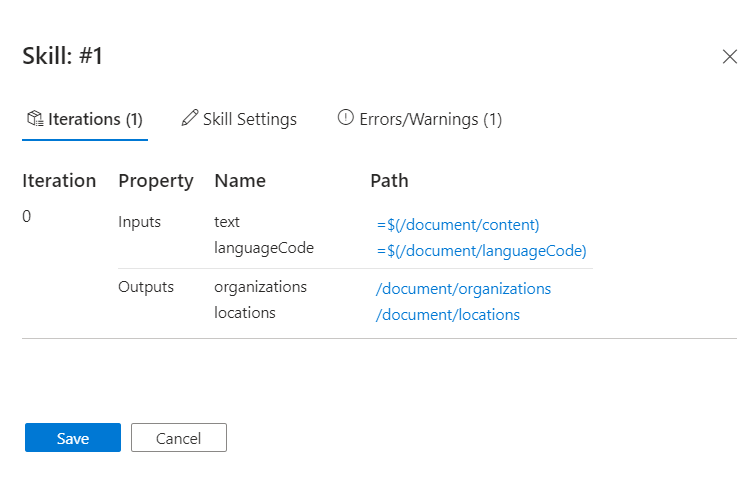
Passe o cursor sobre cada input (ou selecione um input) para mostrar os valores no Avaliador de expressões. Observe que o resultado exibido para essa entrada não se parece com uma entrada de texto. Parece uma série de novos caracteres
\n \n\n\n\nde linha em vez de texto. A falta de texto significa que nenhuma entidade pode ser identificada. Ou este documento não atende aos pré-requisitos da habilidade, ou há outra entrada que deve ser usada em vez disso.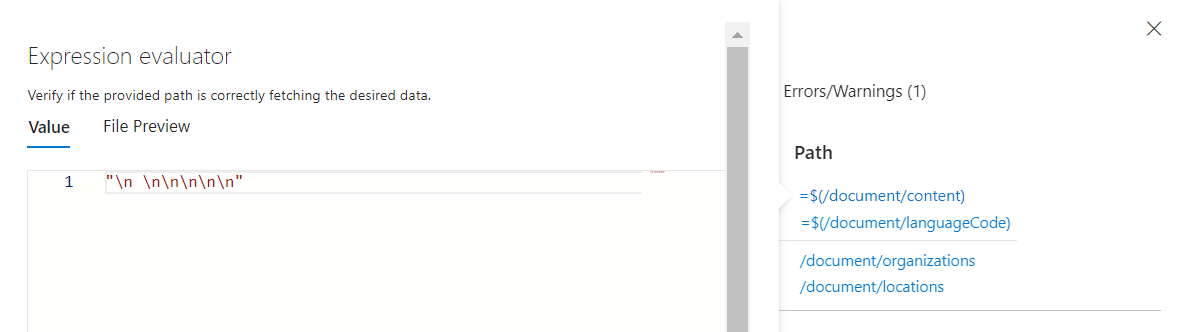
Volte para Estrutura de dados enriquecida e revise os nós de enriquecimento para este documento. Observe que o
\n \n\n\n\npara "conteúdo" não tem fonte de origem, mas outro valor para "merged_content" tem saída OCR. Embora não haja indicação, o conteúdo deste PDF parece ser um arquivo JPEG, como evidenciado pelo texto extraído e processado em "merged_content".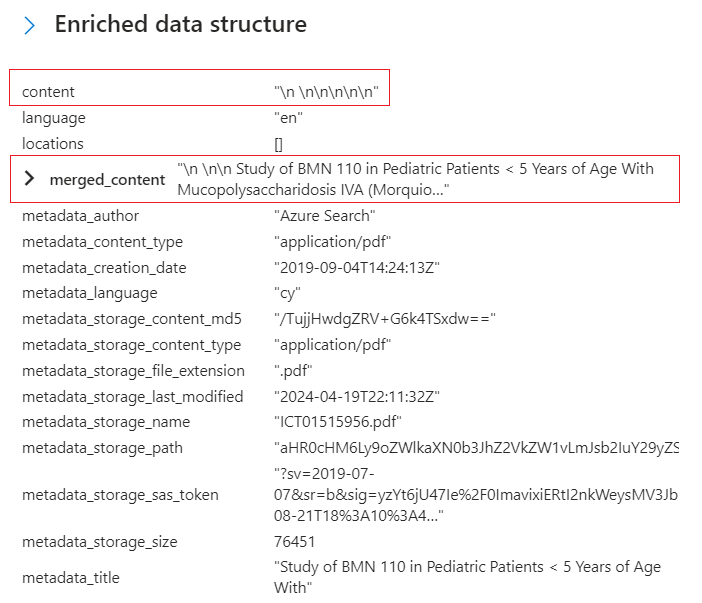
Volte para a habilidade e selecione Configurações do conjunto de habilidades para abrir a definição JSON.
Altere a expressão de
/document/contentpara/document/merged_contente, em seguida, selecione Guardar. Observe que o aviso não está mais listado.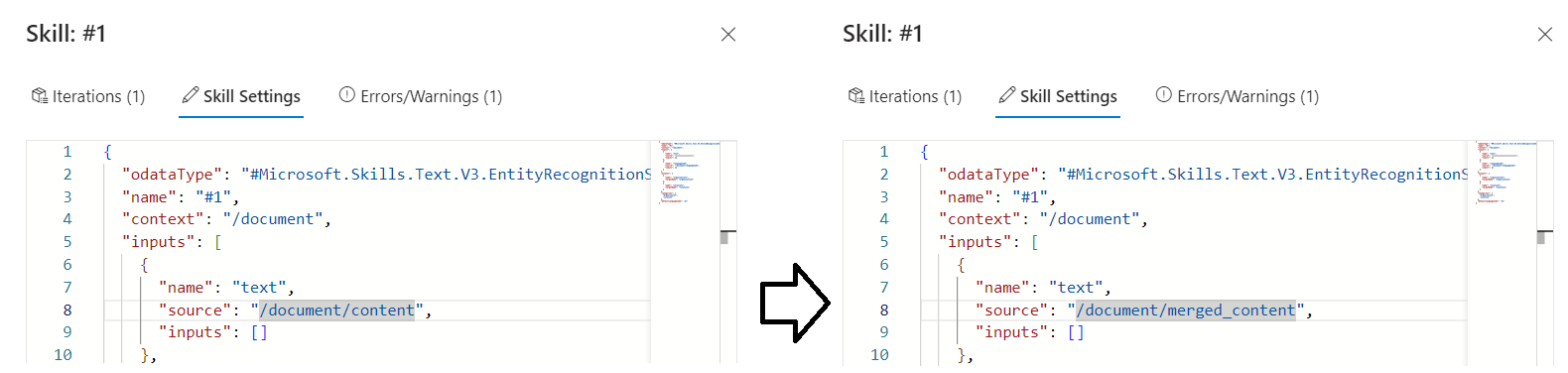
Selecione Executar no menu da janela da sessão. Isso inicia outra execução do conjunto de habilidades usando o documento.
Quando a execução da sessão de depuração for concluída, observe que a contagem de avisos foi reduzida em um. Os avisos mostram que o erro de entrada de texto desapareceu, mas os outros avisos permanecem. O próximo passo é abordar o aviso sobre o valor
/document/languageCodeausente ou vazio.
Selecione a habilidade e passe o mouse sobre
/document/languageCode. O valor dessa entrada é null, o que não é uma entrada válida.Como na edição anterior, comece revisando a estrutura de dados enriquecida para obter evidências de seus nós. Observe que não há um nó "languageCode", mas há um para "language". Então, há um erro de digitação nas configurações de habilidade.
Copie a expressão
/document/language.No painel Detalhes da habilidade, selecione Configurações de habilidade para a habilidade #1 e cole o novo valor,
/document/language.Selecione Guardar.
Selecione Executar.
Após a conclusão da execução da sessão de depuração, pode verificar os resultados no painel de detalhes das Habilidades. Ao passar o rato sobre
/document/language, deve verencomo o valor no avaliador de expressão.
Observe que os avisos de entrada desapareceram. Agora restam apenas os dois avisos sobre campos de saída para organizações e locais.
Corrigir os valores de saída de habilidade ausentes
As mensagens dizem para verificar a propriedade 'outputFieldMappings' do seu indexador, então começaremos por aí.
Selecione Mapeamentos de Campo de Saída na superfície de trabalho. Observe que os mapeamentos de campo de saída estão faltando.
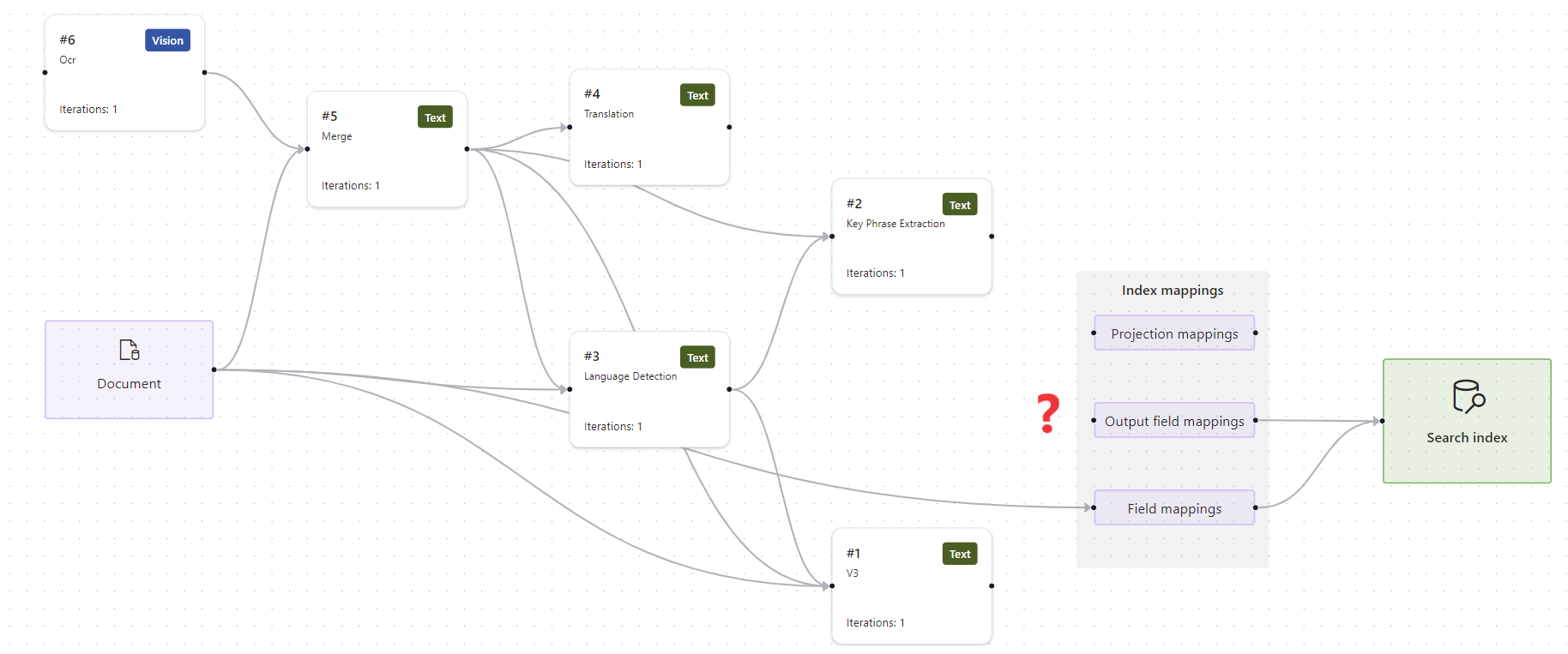
Como primeiro passo, confirme se o índice de pesquisa tem os campos esperados. Neste caso, o índice tem campos para "locais" e "organizações".
Se não houver nenhum problema com o índice, o próximo passo é verificar os resultados das habilidades. Como antes, selecione a Estrutura de dados enriquecida e role os nós para encontrar "locais" e "organizações". Note que o pai é "conteúdo" em vez de "merged_content". O contexto está errado.
Volte para o painel de detalhes das habilidades para a capacidade de reconhecimento de entidades.
Em Configurações de habilidade, mude
contextparadocument/merged_content. Neste ponto, você deve ter três modificações na definição de habilidade ao todo.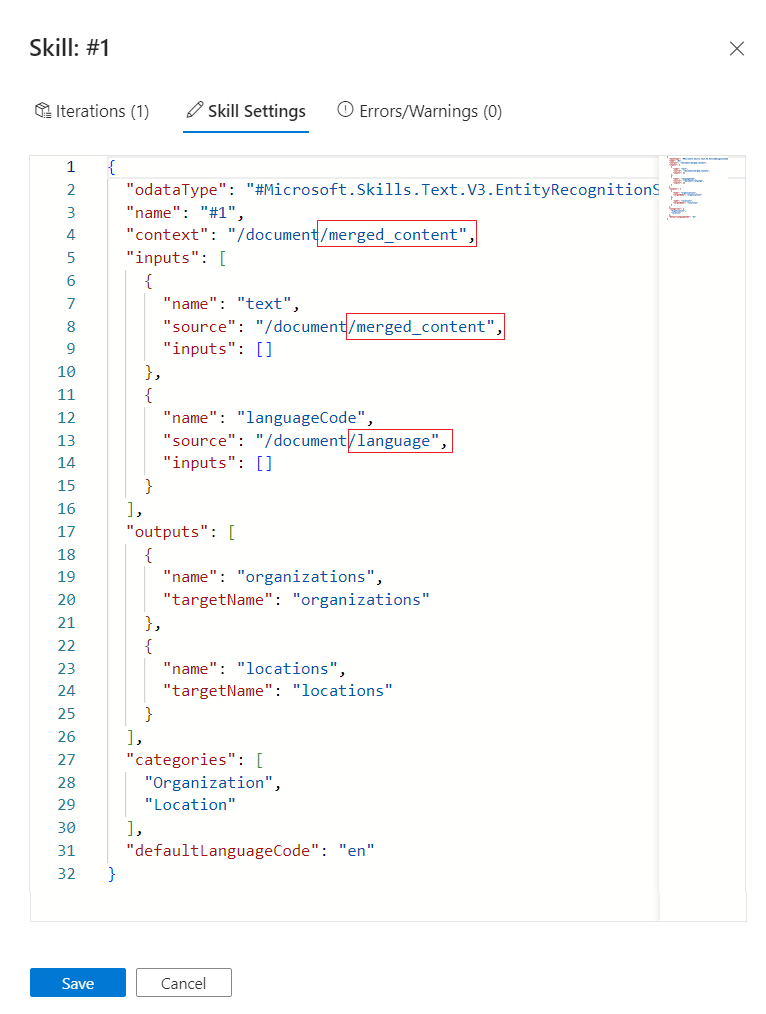
Selecione Guardar.
Selecione Executar.
Todos os erros são resolvidos.
Confirmar alterações no conjunto de competências
Quando a sessão de depuração foi iniciada, o serviço de pesquisa criou uma cópia do conjunto de habilidades. Isso foi feito para proteger o conjunto de habilidades original em seu serviço de pesquisa. Agora que você depurou seu conjunto de habilidades, as correções podem ser confirmadas (substituir o conjunto de habilidades original).
Como alternativa, se você não estiver pronto para confirmar alterações, poderá salvar a sessão de depuração e reabri-la mais tarde.
Selecione Confirmar alterações no menu principal de sessões de depuração.
Selecione OK para confirmar que deseja atualizar seu conjunto de habilidades.
Feche a sessão de depuração e abra Indexadores no painel esquerdo.
Selecione 'clinical-trials-idxr'.
Selecione Repor.
Selecione Executar.
Selecione Atualizar para mostrar o status dos comandos de redefinição e execução.
Quando o indexador terminar a execução, deve haver uma marca de seleção verde e a palavra Êxito ao lado do carimbo de data/hora da última execução na guia Histórico de execução. Para garantir que as alterações sejam aplicadas:
No painel esquerdo, abra Índices.
Selecione o índice 'ensaios clínicos' e, no separador Explorador de pesquisa, introduza esta cadeia de consulta:
$select=metadata_storage_path, organizations, locations&$count=truepara devolver campos para documentos específicos (identificados pelo campo exclusivometadata_storage_path).Selecione Pesquisar.
Os resultados devem mostrar que organizações e locais estão agora preenchidos com os valores esperados.
Limpar recursos
Ao trabalhar na sua própria subscrição, recomendamos que verifique, depois de concluir um projeto, se ainda vai precisar dos recursos que criou. Deixar recursos em execução pode custar-lhe dinheiro. Pode eliminar recursos individualmente ou eliminar o grupo de recursos para eliminar todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal do Azure, usando o link Todos os recursos ou Grupos de recursos no painel de navegação esquerdo.
O serviço gratuito é limitado a três índices, indexadores e fontes de dados. Você pode excluir itens individuais no portal do Azure para permanecer abaixo do limite.
Próximos passos
Este tutorial abordou vários aspetos da definição e processamento do conjunto de habilidades. Para saber mais sobre conceitos e fluxos de trabalho, consulte os seguintes artigos: