Executar ou redefinir indexadores, habilidades ou documentos
No Azure AI Search, há várias maneiras de executar um indexador:
- Execute imediatamente após a criação do indexador, supondo que ele não seja criado no modo "desativado".
- Execute em um cronograma para invocar a execução em intervalos regulares.
- Executar sob demanda, com ou sem um "reset".
Este artigo explica como executar indexadores sob demanda, com e sem uma redefinição. Ele também descreve a execução, duração e simultaneidade do indexador.
Como os indexadores se conectam aos recursos do Azure
Os indexadores são um dos poucos subsistemas que fazem chamadas de saída explícitas para outros recursos do Azure. Em termos de funções do Azure, os indexadores não têm identidades separadas: uma conexão do mecanismo de pesquisa com outro recurso do Azure é feita usando o sistema ou a identidade gerenciada atribuída pelo usuário de um serviço de pesquisa. Se o indexador se conectar a um recurso do Azure em uma rede virtual, você deverá criar um link privado compartilhado para essa conexão. Para obter mais informações sobre conexões seguras, consulte Segurança na Pesquisa de IA do Azure.
Execução do indexador
Um serviço de pesquisa executa um trabalho de indexador por unidade de pesquisa. Cada serviço de pesquisa começa com uma unidade de pesquisa, mas cada nova partição ou réplica aumenta as unidades de pesquisa do seu serviço. Você pode verificar a contagem de unidades de pesquisa na seção Essencial do portal da página Visão geral . Se precisar de processamento simultâneo, certifique-se de ter réplicas suficientes. Os indexadores não são executados em segundo plano, portanto, você pode detetar mais limitação de consulta do que o normal se o serviço estiver sob pressão.
A captura de tela a seguir mostra o número de unidades de pesquisa, que determina quantos indexadores podem ser executados ao mesmo tempo.

Depois que a execução do indexador for iniciada, você não poderá pausá-la ou pará-la. A execução do indexador é interrompida quando não há mais documentos para carregar ou atualizar ou quando o limite máximo de tempo de execução é atingido.
Você pode executar vários indexadores ao mesmo tempo, assumindo capacidade suficiente, mas cada indexador em si é de instância única. Iniciar uma nova instância enquanto o indexador já está em execução produz este erro: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Um trabalho de indexador é executado em um ambiente de execução gerenciado. Atualmente, existem dois ambientes. Não é possível controlar ou configurar qual ambiente é usado. O Azure AI Search determina o ambiente com base na composição do trabalho e na capacidade do serviço de mover um trabalho de indexador para um processador de conteúdo (alguns recursos de segurança bloqueiam o ambiente multilocatário).
Os ambientes de execução do indexador incluem:
Um ambiente de execução privado que é executado em processadores de conteúdo específicos para o seu serviço de pesquisa.
Um ambiente multilocatário com processadores de conteúdo, gerenciado e protegido pela Microsoft sem custo extra. Esse ambiente é usado para descarregar o processamento computacionalmente intensivo, deixando recursos específicos do serviço disponíveis para operações de rotina. Sempre que possível, a maioria dos trabalhos de indexador é executada no ambiente multilocatário.
Os limites do indexador variam para cada ambiente:
| Carga de trabalho | Duração máxima | Máximo de postos de trabalho | Ambiente de execução |
|---|---|---|---|
| Execução privada | 24 horas | Um trabalho indexador por unidade de pesquisa 1. | A indexação não é executada em segundo plano. Em vez disso, o serviço de pesquisa equilibrará todos os trabalhos de indexação em relação a consultas contínuas e ações de gerenciamento de objetos (como criar ou atualizar índices). Ao executar indexadores, você deve esperar ver alguma latência de consulta se os volumes de indexação forem grandes. |
| Multi-inquilino | 2 horas 2 | Indeterminado 3 | Como o cluster de processamento de conteúdo é multilocatário, os processadores de conteúdo são adicionados para atender à demanda. Se você tiver um atraso na execução sob demanda ou agendada, provavelmente é porque o sistema está adicionando processadores ou aguardando que um fique disponível. |
1 As unidades de pesquisa podem ser combinações flexíveis de partições e réplicas, mas os trabalhos de indexador não estão vinculados a uma ou a outra. Em outras palavras, se você tiver 12 unidades, poderá ter 12 trabalhos de indexador em execução simultânea na execução privada, independentemente de como as unidades de pesquisa forem implantadas.
2 Se forem necessárias mais de duas horas para processar todos os dados, habilite a deteção de alterações e agende a execução do indexador em intervalos de duas horas. Consulte Indexação de um grande conjunto de dados para obter mais estratégias.
3 "Indeterminado" significa que o limite não é quantificado pelo número de postos de trabalho. Algumas cargas de trabalho, como o processamento de conjunto de habilidades, podem ser executadas em paralelo, o que pode resultar em muitos trabalhos, mesmo que apenas um indexador esteja envolvido. Embora o ambiente não imponha restrições, os limites do indexador para o seu serviço de pesquisa ainda se aplicam.
Executar sem reposição
Uma operação Run Indexer detetará e processará apenas o necessário para sincronizar o índice de pesquisa com as alterações na fonte de dados subjacente. A indexação incremental começa localizando uma marca d'água interna para localizar o último documento de pesquisa atualizado, que se torna o ponto de partida para a execução do indexador sobre documentos novos e atualizados na fonte de dados.
A deteção de alterações é essencial para determinar o que há de novo ou atualizado na fonte de dados. Os indexadores usam os recursos de deteção de alterações da fonte de dados subjacente para determinar o que há de novo ou atualizado na fonte de dados.
O Armazenamento do Azure tem deteção de alterações interna por meio de sua propriedade LastModified.
Outras fontes de dados, como o Azure SQL ou o Azure Cosmos DB, precisam ser configuradas para deteção de alterações antes que o indexador possa ler linhas novas e atualizadas.
Se o conteúdo subjacente não for alterado, uma operação de execução não terá efeito. Nesse caso, o histórico de execução do indexador indicará 0\0 os documentos processados.
Você precisará redefinir o indexador, conforme explicado na próxima seção, para reprocessar na íntegra.
Redefinição de indexadores
Após a execução inicial, um indexador controla quais documentos de pesquisa foram indexados por meio de uma marca de água alta interna. O marcador nunca é exposto, mas internamente o indexador sabe onde parou pela última vez.
Se você precisar reconstruir todo ou parte de um índice, poderá limpar a marca de água alta do indexador por meio de uma redefinição. As APIs de redefinição estão disponíveis em níveis decrescentes na hierarquia de objetos:
- Redefinir indexadores limpa a marca d'água alta e executa uma reindexação completa de todos os documentos
- Redefinir documentos (visualização) reindexa um documento específico ou uma lista de documentos
- Redefinir habilidades (visualização) invoca o processamento de habilidades para uma habilidade específica
Após a redefinição, siga com um comando Executar para reprocessar documentos novos e existentes. Os documentos de pesquisa órfãos que não tenham contrapartida na fonte de dados não podem ser removidos por meio de redefinição/execução. Se você precisar excluir documentos, consulte Documentos - Índice .
Como redefinir e executar indexadores
Redefinir limpa a marca de água alta. Todos os documentos no índice de pesquisa serão sinalizados para substituição total, sem atualizações embutidas ou mesclagem em conteúdo existente. Para indexadores com um conjunto de habilidades e cache de enriquecimento, redefinir o índice também redefinirá implicitamente o conjunto de habilidades.
O trabalho real ocorre quando você segue uma redefinição com um comando Executar:
- Todos os novos documentos encontrados na fonte subjacente são adicionados ao índice de pesquisa.
- Todos os documentos existentes na fonte de dados e no índice de pesquisa serão substituídos no índice de pesquisa.
- Qualquer conteúdo enriquecido criado a partir de conjuntos de habilidades será reconstruído. O cache de enriquecimento, se estiver habilitado, será atualizado.
Como observado anteriormente, a redefinição é uma operação passiva: você deve acompanhar uma solicitação Run para reconstruir o índice.
As operações de redefinição/execução aplicam-se a um índice de pesquisa ou a um armazenamento de conhecimento, a documentos ou projeções específicos e a enriquecimentos armazenados em cache se uma redefinição incluir habilidades explícita ou implicitamente.
Redefinir também se aplica a operações de criação e atualização. Não desencadeará a eliminação ou limpeza de documentos órfãos no índice de pesquisa. Para obter mais informações sobre como excluir documentos, consulte Documentos - Índice.
Depois de redefinir um indexador, não é possível desfazer a ação.
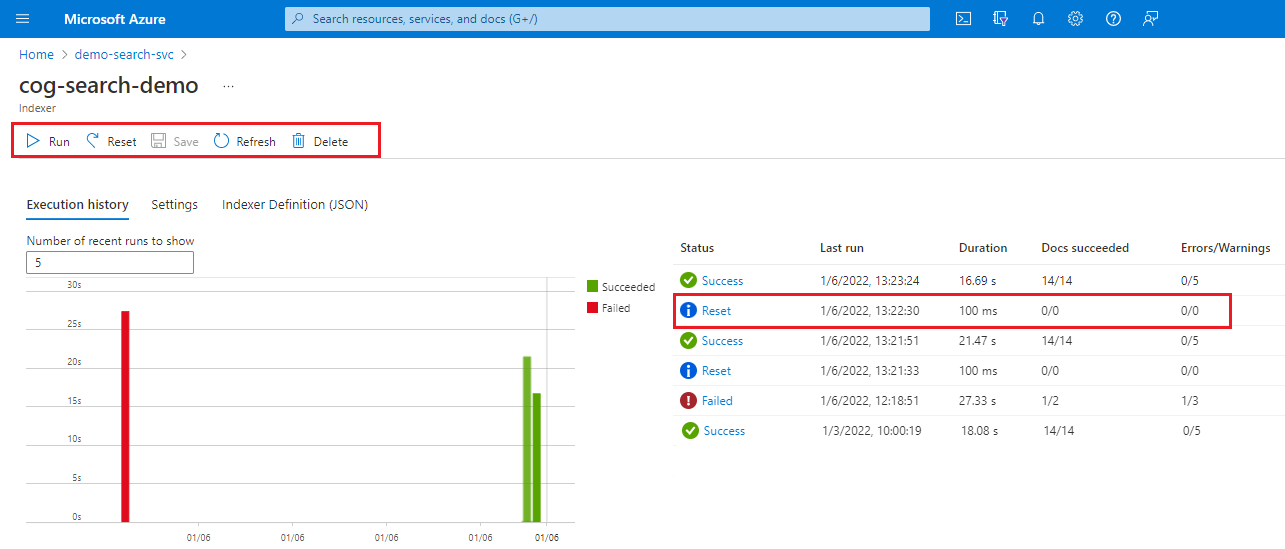
Entre no portal do Azure e abra a página do serviço de pesquisa.
Na página Visão geral, selecione a guia Indexadores.
Selecione um indexador.
Selecione o comando Redefinir e, em seguida, selecione Sim para confirmar a ação.
Atualize a página para mostrar o status. Você pode selecionar o item para visualizar seus detalhes.
Selecione Executar para iniciar o processamento do indexador ou aguarde a próxima execução agendada.
Como redefinir habilidades (visualização)
Para indexadores que têm conjuntos de habilidades, você pode redefinir habilidades individuais para forçar o processamento apenas dessa habilidade e de quaisquer habilidades downstream que dependem de sua saída. O cache de enriquecimento, se você o tiver habilitado, também será atualizado.
Atualmente, o Reset Skills é apenas REST, disponível até 2020-06-30-preview ou posterior. Recomendamos a API de visualização mais recente.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Você pode especificar habilidades individuais, conforme indicado no exemplo acima, mas se qualquer uma dessas habilidades exigir saída de habilidades não listadas (#2 a #4), as habilidades não listadas serão executadas, a menos que o cache possa fornecer as informações necessárias. Para que isso seja verdade, os enriquecimentos armazenados em cache para as habilidades #2 a #4 não devem ter dependência de #1 (listado para redefinição).
Se nenhuma habilidade for especificada, todo o conjunto de habilidades será executado e, se o cache estiver habilitado, o cache também será atualizado.
Lembre-se de seguir com Run Indexer para invocar o processamento real.
Como redefinir documentos (visualização)
O Indexadores - Redefinir documentos aceita uma lista de chaves de documento para que você possa atualizar documentos específicos. Se especificado, os parâmetros de redefinição tornam-se o único determinante do que é processado, independentemente de outras alterações nos dados subjacentes. Por exemplo, se 20 blobs foram adicionados ou atualizados desde a última execução do indexador, mas você redefine apenas um documento, somente esse documento é processado.
Por documento, todos os campos desse documento de pesquisa são atualizados com valores da fonte de dados. Não é possível escolher quais campos atualizar.
Se o documento for enriquecido por meio de um conjunto de habilidades e tiver dados armazenados em cache, o conjunto de habilidades será invocado apenas para os documentos especificados e o cache será atualizado para os documentos reprocessados.
Quando você está testando essa API pela primeira vez, as APIs a seguir podem ajudá-lo a validar e testar os comportamentos. Você pode usar a versão da API de visualização 2020-06-30-preview e posterior. Recomendamos a API de visualização mais recente.
Indexadores de chamadas - Obtenha status com uma versão de API de visualização para verificar o status de redefinição e o status de execução. Você pode encontrar informações sobre a solicitação de redefinição no final da resposta de status.
Indexadores de chamadas - Redefina o documento com uma versão de API de visualização para especificar quais documentos processar.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }As chaves de documento fornecidas na solicitação são valores do índice de pesquisa, que podem ser diferentes dos campos correspondentes na fonte de dados. Se você não tiver certeza do valor da chave, envie uma consulta para retornar o valor. Você pode usar
selectpara retornar apenas o campo de chave do documento.Para blobs que são analisados em vários documentos de pesquisa (onde parsingMode é definido como jsonLines ou jsonArrays, ou delimitedText), a chave do documento é gerada pelo indexador e pode ser desconhecida para você. Nesse cenário, uma consulta para a chave do documento para retornar o valor correto.
Chame o Indexador de Execução (qualquer versão da API) para processar os documentos especificados. Apenas esses documentos específicos são indexados.
Chame o Run Indexer uma segunda vez para processar a partir da última marca de água alta.
Chame Documentos de Pesquisa para verificar se há valores atualizados e também para retornar chaves de documento se não tiver certeza do valor. Use
"select": "<field names>"se quiser limitar quais campos aparecem na resposta.
Substituindo a lista de chaves do documento
Chamar a API Reset Documents várias vezes com chaves diferentes acrescenta as novas chaves à lista de chaves de documento redefinidas. Chamar a API com o overwrite parâmetro definido como true substituirá a lista atual pela nova:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Verifique o status de redefinição "currentState"
Para verificar o status de redefinição e ver quais chaves de documento estão na fila para processamento, siga estas etapas.
Chame Get Indexer Status com uma API de visualização.
A API de visualização retornará a
currentStateseção, encontrada no final da resposta."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Verifique o "modo":
Para Redefinir habilidades, o "modo" deve ser definido como
indexingAllDocs(porque potencialmente todos os documentos são afetados, em termos dos campos que são preenchidos por enriquecimento de IA).Para Redefinir documentos, "modo" deve ser definido como
indexingResetDocs. O indexador mantém esse status até que todas as chaves de documento fornecidas na chamada de redefinição de documentos sejam processadas, durante o qual nenhum outro trabalho de indexador será executado enquanto a operação estiver progredindo. Encontrar todos os documentos na lista de chaves de documento requer quebrar cada documento para localizar e corresponder na chave, e isso pode demorar um pouco se o conjunto de dados for grande. Se um contêiner de blob contiver centenas de blobs e os documentos que você deseja redefinir estiverem no final, o indexador não encontrará os blobs correspondentes até que todos os outros tenham sido verificados primeiro.Depois que os documentos forem reprocessados, execute Get Indexer Status novamente. O indexador retorna ao
indexingAllDocsmodo e processará quaisquer documentos novos ou atualizados na próxima execução.
Próximos passos
As APIs de redefinição são usadas para informar o escopo da próxima execução do indexador. Para o processamento real, você precisará invocar uma execução de indexador sob demanda ou permitir que um trabalho agendado conclua o trabalho. Depois que a execução for concluída, o indexador retornará ao processamento normal, seja em um cronograma ou processamento sob demanda.
Depois de redefinir e executar novamente os trabalhos do indexador, você pode monitorar o status do serviço de pesquisa ou obter informações detalhadas por meio do log de recursos.