Classificação semântica na Pesquisa de IA do Azure
No Azure AI Search, o classificador semântico é um recurso que melhora de forma mensurável a relevância da pesquisa usando os modelos de compreensão de linguagem da Microsoft para reclassificar os resultados da pesquisa. Este artigo é uma introdução de alto nível para ajudá-lo a entender os comportamentos e benefícios do ranker semântico.
O ranker semântico é um recurso premium, cobrado pelo uso. Recomendamos este artigo para plano de fundo, mas se preferir começar, siga estas etapas.
Nota
O ranker semântico não usa IA generativa ou vetores. Se você estiver procurando suporte a vetores e pesquisa de similaridade, consulte Pesquisa vetorial na Pesquisa de IA do Azure para obter detalhes.
O que é ranking semântico?
O classificador semântico é uma coleção de recursos do lado da consulta que melhoram a qualidade de um resultado de pesquisa inicial classificado como BM25 ou RRF para consultas baseadas em texto, consultas vetoriais e consultas híbridas. Quando você o habilita em seu serviço de pesquisa, a classificação semântica estende o pipeline de execução de consulta de duas maneiras:
Primeiro, adiciona classificação secundária sobre um conjunto de resultados inicial que foi pontuado usando BM25 ou Reciprocal Rank Fusion (RRF). Esta classificação secundária utiliza modelos multilingues de aprendizagem profunda adaptados do Microsoft Bing para promover os resultados semanticamente mais relevantes.
Em segundo lugar, ele extrai e retorna legendas e respostas na resposta, que você pode renderizar em uma página de pesquisa para melhorar a experiência de pesquisa do usuário.
Aqui estão as capacidades do reranker semântico.
| Capacidade | Description |
|---|---|
| Classificação L2 | Usa o contexto ou o significado semântico de uma consulta para calcular uma nova pontuação de relevância sobre resultados pré-classificados. |
| Legendas semânticas e destaques | Extrai frases literais e frases dos campos que melhor resumem o conteúdo, com destaques sobre as principais passagens para facilitar a digitalização. As legendas que resumem um resultado são úteis quando os campos de conteúdo individuais são muito densos para a página de resultados da pesquisa. O texto realçado eleva os termos e frases mais relevantes para que os usuários possam determinar rapidamente por que uma correspondência foi considerada relevante. |
| Respostas semânticas | Uma subestrutura opcional e extra retornada de uma consulta semântica. Ele fornece uma resposta direta para uma consulta que se parece com uma pergunta. Exige que um documento tenha texto com as características de uma resposta. |
Como funciona o ranker semântico
O classificador semântico alimenta uma consulta e os resultados para modelos de compreensão de linguagem hospedados pela Microsoft e verifica se há melhores correspondências.
A ilustração a seguir explica o conceito. Considere o termo "capital". Tem significados diferentes dependendo se o contexto é finanças, direito, geografia ou gramática. Através da compreensão da linguagem, o classificador semântico pode detetar o contexto e promover resultados que se ajustam à intenção da consulta.
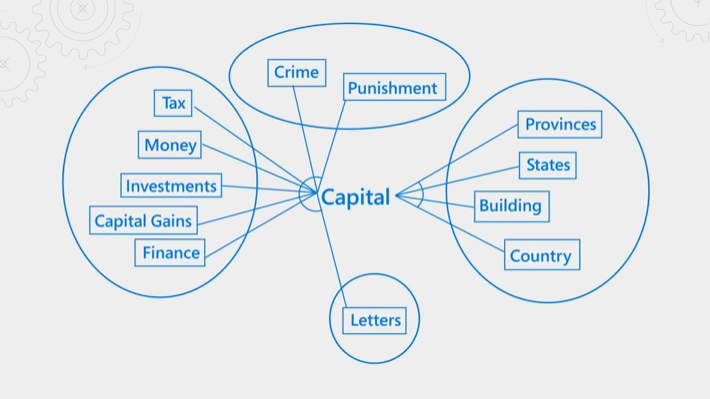
A classificação semântica consome muitos recursos e tempo. Para concluir o processamento dentro da latência esperada de uma operação de consulta, as entradas para o classificador semântico são consolidadas e reduzidas para que a etapa de reclassificação possa ser concluída o mais rápido possível.
Existem três passos para a classificação semântica:
- Coletar e resumir entradas
- Resultados da pontuação usando o classificador semântico
- Resultados remarcados de saída, legendas e respostas
Como os inputs são recolhidos e resumidos
Na classificação semântica, o subsistema de consulta passa os resultados da pesquisa como uma entrada para modelos de resumo e classificação. Como os modelos de classificação têm restrições de tamanho de entrada e são de processamento intensivo, os resultados da pesquisa devem ser dimensionados e estruturados (resumidos) para um tratamento eficiente.
O classificador semântico começa com um resultado classificado como BM25 de uma consulta de texto ou um resultado classificado como RRF de uma consulta vetorial ou híbrida. Apenas campos de texto são usados no exercício de reclassificação, e apenas os 50 melhores resultados progridem para a classificação semântica, mesmo que os resultados incluam mais de 50. Normalmente, os campos usados na classificação semântica são informativos e descritivos.
Para cada documento no resultado da pesquisa, o modelo de resumo aceita até 2.000 tokens, onde um token tem aproximadamente 10 caracteres. As entradas são montadas a partir dos campos "title", "keyword" e "content" listados na configuração semântica.
Cordas excessivamente longas são cortadas para garantir que o comprimento total atenda aos requisitos de entrada da etapa de sumarização. Este exercício de corte é o motivo pelo qual é importante adicionar campos à sua configuração semântica em ordem de prioridade. Se você tiver documentos muito grandes com campos de texto pesado, qualquer coisa após o limite máximo será ignorada.
Campo semântico Limite de tokens "título" 128 fichas "Palavras-chave 128 fichas "conteúdo" Tokens restantes A saída de resumo é uma cadeia de caracteres de resumo para cada documento, composta pelas informações mais relevantes de cada campo. As cadeias de caracteres de resumo são enviadas para o classificador para pontuação e para modelos de compreensão de leitura automática para legendas e respostas.
O comprimento máximo de cada cadeia de caracteres de resumo gerada passada para o classificador semântico é de 256 tokens.
Como a classificação é pontuada
A pontuação é feita sobre a legenda e qualquer outro conteúdo da cadeia de caracteres de resumo que preenche o comprimento do token 256.
As legendas são avaliadas quanto à relevância conceitual e semântica, em relação à consulta fornecida.
Um @search.rerankerScore é atribuído a cada documento com base na relevância semântica do documento para a consulta dada. Os escores variam de 4 a 0 (alto a baixo), onde uma pontuação maior indica maior relevância.
Resultado Significado 4.0 O documento é altamente relevante e responde completamente à pergunta, embora a passagem possa conter texto extra não relacionado com a pergunta. 3.0 O documento é relevante, mas carece de detalhes que o tornem completo. 2.0 O documento é algo relevante; Responde à pergunta parcialmente ou aborda apenas alguns aspetos da questão. 1.0 O documento está relacionado com a pergunta e responde a uma pequena parte dela. 0.0 O documento é irrelevante. As correspondências são listadas em ordem decrescente por pontuação e incluídas na carga útil de resposta da consulta. A carga inclui respostas, texto sem formatação e legendas realçadas, além de quaisquer campos marcados como recuperáveis ou especificados em uma cláusula select.
Nota
Para qualquer consulta, as distribuições de @search.rerankerScore podem apresentar pequenas variações devido às condições no nível da infraestrutura. Sabe-se também que as atualizações do modelo de classificação afetam a distribuição. Por esses motivos, se você estiver escrevendo código personalizado para limites mínimos ou definindo a propriedade threshold para consultas vetoriais e híbridas, não torne os limites muito granulares.
Saídas do classificador semântico
A partir de cada seqüência de resumo, os modelos de compreensão de leitura de máquina encontram passagens que são as mais representativas.
Os resultados são:
Uma legenda semântica para o documento. Cada legenda está disponível em uma versão de texto simples e uma versão de realce, e geralmente tem menos de 200 palavras por documento.
Uma resposta semântica opcional, supondo que você especificou o
answersparâmetro, a consulta foi colocada como uma pergunta e uma passagem é encontrada na cadeia de caracteres longa que fornece uma resposta provável para a pergunta.
As legendas e as respostas são sempre texto literal do seu índice. Não há nenhum modelo de IA generativa neste fluxo de trabalho que crie ou componha novo conteúdo.
Capacidades e limitações semânticas
O ranker semântico é uma tecnologia mais recente, por isso é importante definir expectativas sobre o que pode ou não fazer. O que pode fazer:
Promova correspondências semanticamente mais próximas da intenção da consulta original.
Encontre cadeias de caracteres para usar como legendas e respostas. As legendas e respostas são retornadas na resposta e podem ser renderizadas em uma página de resultados de pesquisa.
O que o classificador semântico não pode fazer é executar novamente a consulta em todo o corpus para encontrar resultados semanticamente relevantes. A classificação semântica reclassifica o conjunto de resultados existente, consistindo nos 50 melhores resultados pontuados pelo algoritmo de classificação padrão. Além disso, o classificador semântico não pode criar novas informações ou cadeias de caracteres. As legendas e as respostas são extraídas literalmente do seu conteúdo, portanto, se os resultados não incluírem texto semelhante a uma resposta, os modelos de linguagem não produzirão um.
Embora a classificação semântica não seja benéfica em todos os cenários, determinados conteúdos podem se beneficiar significativamente de seus recursos. Os modelos de linguagem no ranker semântico funcionam melhor em conteúdo pesquisável que é rico em informações e estruturado como prosa. Uma base de conhecimento, documentação on-line ou documentos que contêm conteúdo descritivo obtêm mais ganhos com os recursos de classificação semântica.
A tecnologia subjacente é do Bing e da Microsoft Research e está integrada na infraestrutura do Azure AI Search como um recurso complementar. Para obter mais informações sobre a pesquisa e os investimentos em IA que apoiam o ranking semântico, consulte Como a IA do Bing está alimentando a Pesquisa de IA do Azure (Blog de Pesquisa da Microsoft).
O vídeo a seguir fornece uma visão geral dos recursos.
Disponibilidade e preços
O classificador semântico está disponível em serviços de pesquisa nos níveis Básico e superior, sujeito à disponibilidade regional.
Ao habilitar o classificador semântico, escolha um plano de preços para o recurso:
- Em volumes de consulta mais baixos (abaixo de 1000 mensais), a classificação semântica é gratuita.
- Em volumes de consulta mais altos, escolha o plano de preços padrão.
A página de preços do Azure AI Search mostra a taxa de cobrança para diferentes moedas e intervalos.
As cobranças pelo classificador semântico são cobradas quando as solicitações de consulta são incluídas queryType=semantic e a cadeia de caracteres de pesquisa não está vazia (por exemplo, search=pet friendly hotels in New York). Se a cadeia de caracteres de pesquisa estiver vazia (search=*), você não será cobrado, mesmo que queryType esteja definido como semântico.
Como começar a usar o ranker semântico
Verifique a disponibilidade regional.
Entre no portal do Azure para verificar se seu serviço de pesquisa é Básico ou superior.
Configure o classificador semântico em um índice de pesquisa.
Configure consultas para retornar legendas semânticas e destaques.