Recuperação de desastres geográficos do Barramento de Serviço do Azure
O recurso de Recuperação de Desastres Geográficos do Service Bus é uma das opções para isolar os aplicativos do Barramento de Serviço do Azure contra interrupções e desastres e visa principalmente ajudar a preservar a integridade da configuração do aplicativo composto.
Nota
Esse recurso está disponível para a camada Premium do Barramento de Serviço do Azure.
O recurso Geo-Disaster Recovery garante que toda a configuração de um namespace (entidades, configuração, propriedades) seja replicada continuamente de um namespace primário para um namespace secundário com o qual ele é emparelhado e permite que você inicie uma mudança de failover única do primário para o secundário a qualquer momento. A movimentação de failover reaponta o nome do alias escolhido para o namespace para o namespace secundário e, em seguida, quebra o emparelhamento. O failover é quase instantâneo uma vez iniciado.
Pontos importantes a considerar
- O recurso permite a continuidade instantânea de operações com a mesma configuração, mas não replica as mensagens mantidas em filas ou assinaturas de tópicos ou filas de mensagens mortas. Para preservar a semântica da fila, essa replicação requer não apenas a replicação de dados de mensagens, mas de todas as alterações de estado no broker, que são oferecidas no recurso de replicação geográfica (visualização pública).
- As atribuições RBAC (controle de acesso baseado em função) do Microsoft Entra para entidades do Service Bus no namespace primário não são replicadas para o namespace secundário. Crie atribuições de função manualmente no namespace secundário para proteger o acesso a elas.
- As configurações a seguir não são replicadas.
- Configurações de rede virtual
- Ligações de ponto final privado
- Todos os acessos a redes ativados
- Acesso a serviços confiáveis habilitado
- Acesso à rede pública
- Ação de rede padrão
- Identidades e configurações de criptografia (criptografia de chave gerenciada pelo cliente ou criptografia de traga sua própria chave (BYOK))
- Ativar dimensionamento automático
- Desativar autenticação local
- Subscrições da Grelha de Eventos do Azure
- Não há suporte para emparelhamento de um namespace particionado com um namespace não particionado.
- Se
AutoDeleteOnIdleestiver habilitada para uma entidade, a entidade pode não estar presente no namespace secundário quando o failover ocorrer. Quando o secundário se torna primário, o último status de acesso, que não faz parte dos metadados, não estará disponível para o novo primário e a entidade poderá ser excluída como parte daAutoDeleteOnIdlelimpeza.
Gorjeta
Para replicar o conteúdo de filas e assinaturas de tópicos e operar namespaces correspondentes em configurações ativas/ativas para lidar com interrupções e desastres, não se apoie neste conjunto de recursos de Recuperação de Desastres Geográficos, mas use o recurso de Replicação Geográfica ou siga as diretrizes de replicação.
Conceitos e termos básicos
O recurso Geo-Disaster Recovery implementa a recuperação de desastres de metadados e depende de namespaces de recuperação de desastres primários e secundários. O recurso Geo-Disaster Recovery está disponível apenas para a camada Premium. Não é necessário fazer alterações na cadeia de conexão, pois a conexão é feita por meio de um alias.
Os seguintes termos são usados neste artigo:
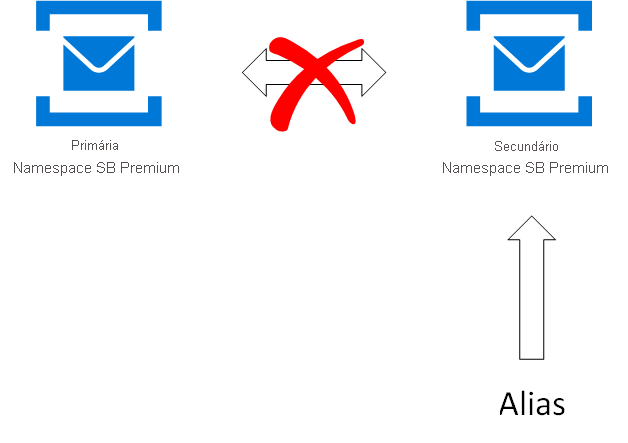
Alias: o nome de uma configuração de recuperação de desastres que você configurou. O alias fornece uma única cadeia de conexão estável FQDN (Fully Qualified Domain Name). Os aplicativos usam essa cadeia de conexão de alias para se conectar a um namespace. O uso de um alias garante que a cadeia de conexão permaneça inalterada quando o failover for acionado.
Namespace primário/secundário: os namespaces que correspondem ao alias. O namespace principal é "ativo" e recebe mensagens (pode ser um namespace existente ou novo). O namespace secundário é "passivo" e não recebe mensagens. Os metadados entre ambos estão sincronizados, para que ambos possam aceitar mensagens sem qualquer código de aplicativo ou alterações na cadeia de conexão. Para garantir que apenas o namespace ativo receba mensagens, você deve usar o alias.
Metadados: entidades como filas, tópicos e assinaturas e suas propriedades do serviço associadas ao namespace. Somente entidades e suas configurações são replicadas automaticamente. As mensagens não são replicadas.
Failover: O processo de ativação do namespace secundário.
Configurar
A seção a seguir é uma visão geral para configurar o emparelhamento entre os namespaces.
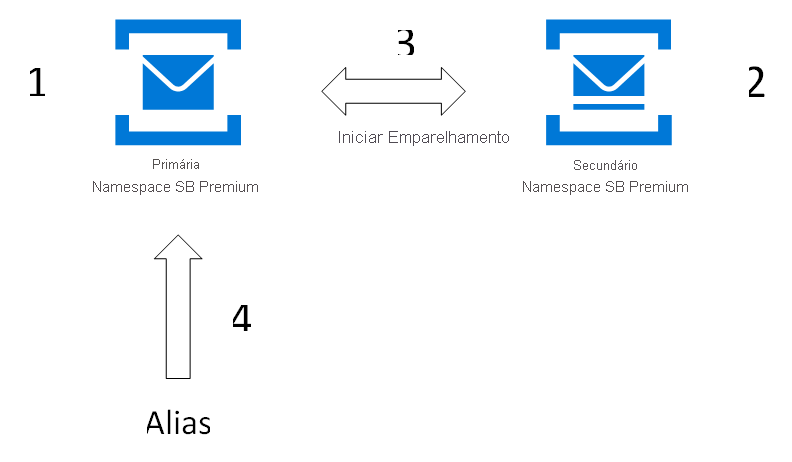
Primeiro, você cria ou usa um namespace primário existente e um novo namespace secundário e, em seguida, emparelha os dois. Esse emparelhamento fornece um alias que você pode usar para se conectar. Como você usa um alias, não é necessário alterar cadeias de conexão. Somente novos namespaces podem ser adicionados ao seu emparelhamento de failover.
Crie o namespace primário de camada premium.
Crie o namespace secundário de camada premium em uma região diferente. Este passo é opcional. Você pode criar o namespace secundário enquanto cria o emparelhamento na próxima etapa.
No portal do Azure, navegue até seu namespace principal.
Selecione Geo-Recovery no menu à esquerda e selecione Iniciar emparelhamento na barra de ferramentas.
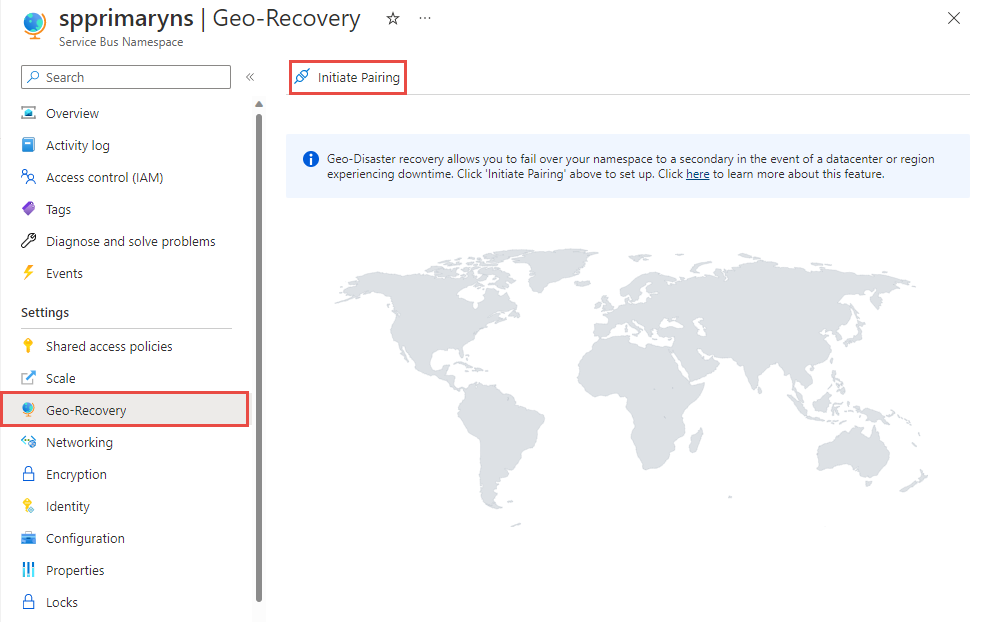
Na página Iniciar emparelhamento, siga estes passos:
Selecione um namespace secundário existente ou crie um em uma região diferente. Neste exemplo, um namespace existente é usado como o namespace secundário.
Para Alias, insira um alias para o emparelhamento Geo-Disaster Recovery.
Em seguida, selecione Criar.
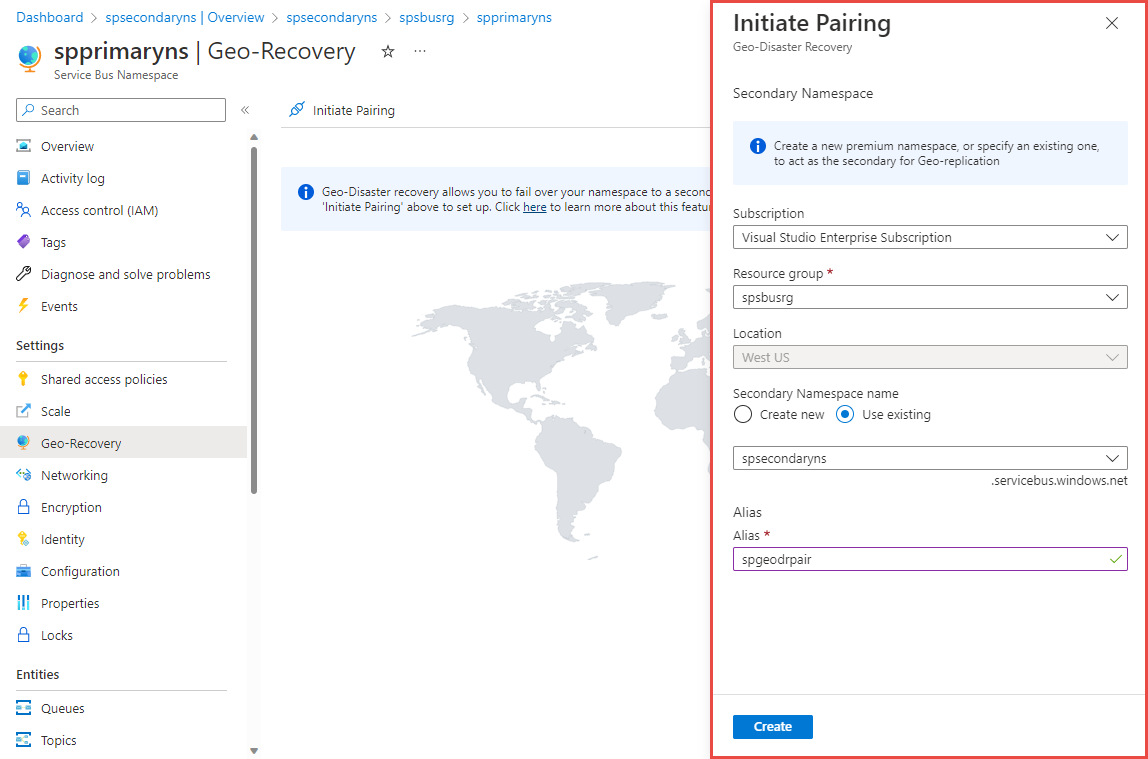
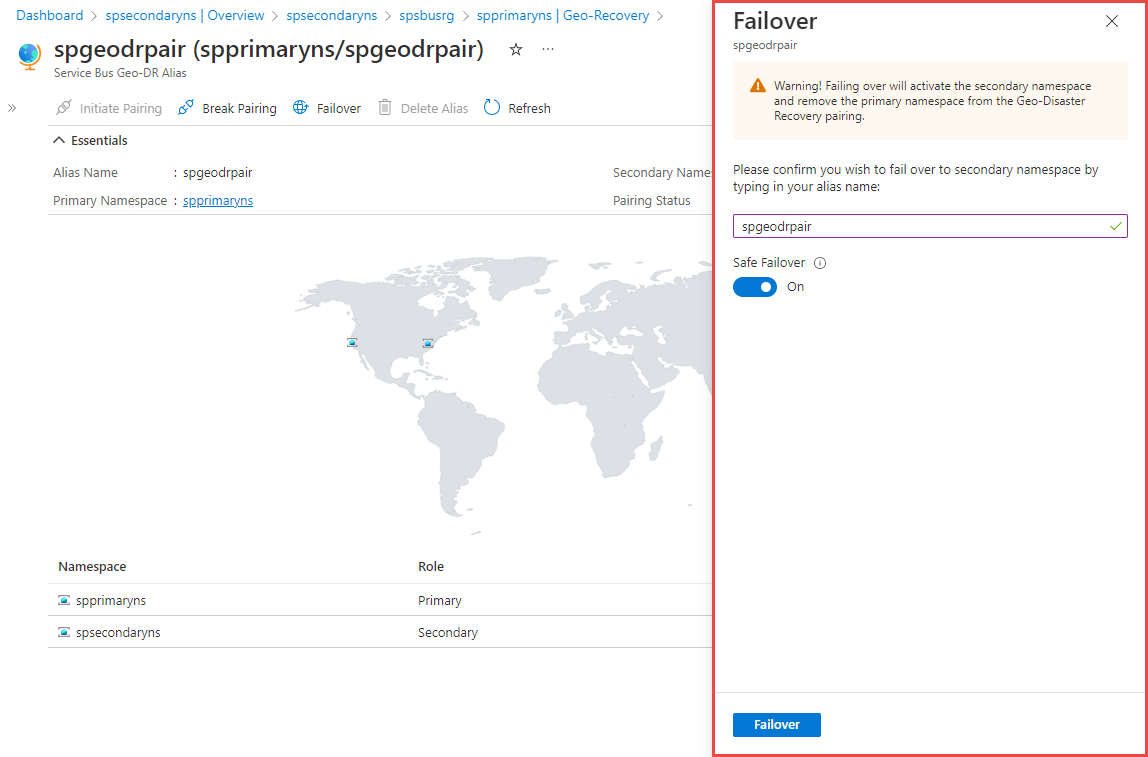
Você deve ver a página Alias Geo-DR do Service Bus, conforme mostrado na imagem a seguir. Você também pode navegar até a página Alias Geo-DR na página de namespace principal selecionando Geo-Recovery no menu à esquerda.
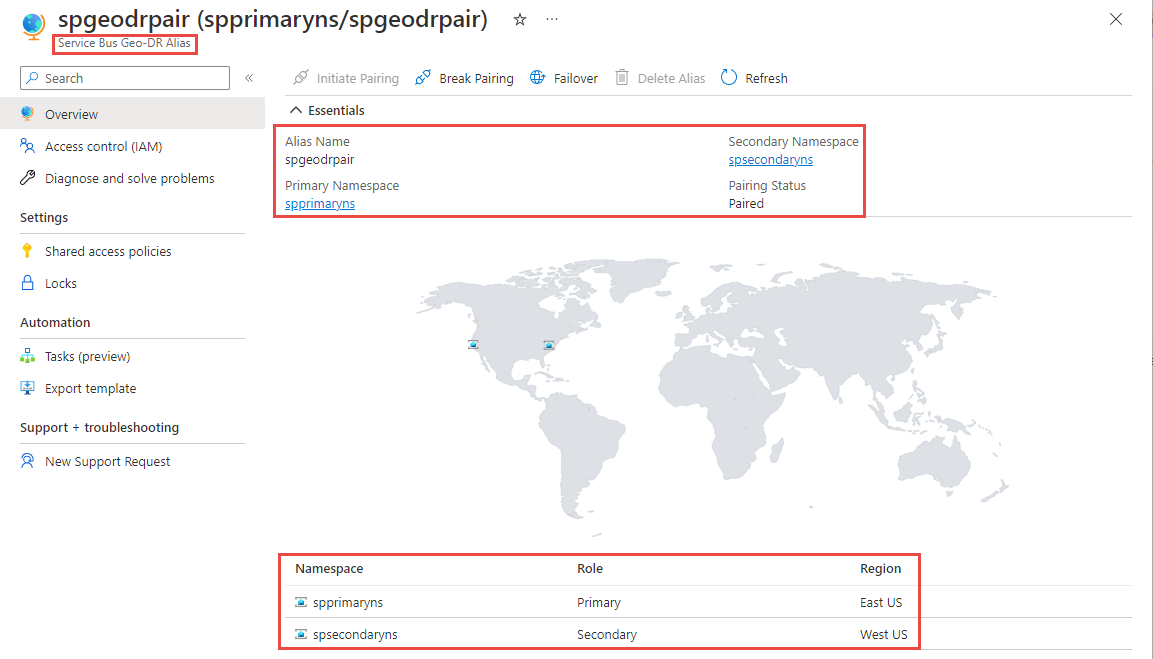
Na página Alias Geo-DR, selecione Políticas de acesso compartilhado no menu à esquerda para acessar a cadeia de conexão primária para o alias. Use essa cadeia de conexão em vez de usar a cadeia de conexão diretamente para o namespace primário/secundário. Inicialmente, o alias aponta para o namespace principal.
Alterne para a página Visão geral . Você pode executar as seguintes ações:
- Quebre o emparelhamento entre namespaces primários e secundários. Selecione Quebrar emparelhamento na barra de ferramentas.
- Faça failover manualmente para o namespace secundário.
Selecione Failover na barra de ferramentas.
Confirme que deseja fazer failover para o namespace secundário digitando seu alias.
Ative a opção Failover seguro para fazer failover com segurança para o namespace secundário.
Nota
- O failover seguro garante que as replicações pendentes do Geo-Disaster Recovery sejam concluídas antes de mudar para o secundário. Como alternativa, o failover forçado ou manual não espera que as replicações pendentes sejam concluídas antes de mudar para o secundário.
- Atualmente, o failover seguro falhará se os namespaces primário e secundário não estiverem na mesma assinatura do Azure.
Em seguida, selecione Failover.
Importante
O failover ativa o namespace secundário e remove o namespace primário do emparelhamento Geo-Disaster Recovery. Crie outro namespace para ter um novo par Geo-Disaster Recovery.
Finalmente, você deve adicionar algum monitoramento para detetar se um failover é necessário. Na maioria dos casos, o serviço é uma parte de um grande ecossistema, portanto, failovers automáticos raramente são possíveis, pois muitas vezes os failovers devem ser executados em sincronia com o subsistema ou infraestrutura restante.
Barramento de serviço padrão para premium
Se você migrou seu namespace do Azure Service Bus Standard para o Azure Service Bus Premium, deverá usar o alias pré-existente (ou seja, sua cadeia de conexão de namespace do Service Bus Standard) para criar a configuração de recuperação de desastres por meio da API PS/CLI ou REST.
Isso ocorre porque, durante a migração, a própria cadeia de conexão de namespace padrão do Barramento de Serviço do Azure/nome DNS se torna um alias para seu namespace premium do Barramento de Serviço do Azure.
Seus aplicativos cliente devem utilizar esse alias (ou seja, a cadeia de conexão de namespace padrão do Barramento de Serviço do Azure) para se conectar ao namespace premium onde o emparelhamento de recuperação de desastres foi configurado.
Se você usar o portal do Azure para configurar a configuração de recuperação de desastres, o portal abstrai essa advertência de você.
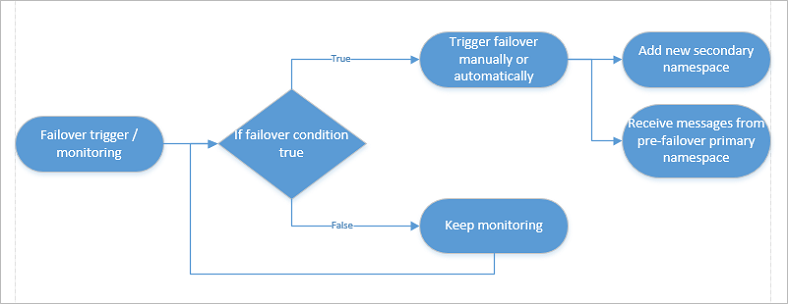
Fluxo de failover
Um failover é acionado manualmente pelo cliente (explicitamente por meio de um comando ou por meio da lógica de negócios de propriedade do cliente que aciona o comando) e nunca pelo Azure. Ele dá ao cliente total propriedade e visibilidade para a resolução de interrupções no backbone do Azure.
Depois que o failover for acionado -
A cadeia de conexão de alias é atualizada para apontar para o namespace Premium Secundário.
Os clientes (remetentes e destinatários) se conectam automaticamente ao namespace secundário.
O emparelhamento existente entre o namespace premium Primário e Secundário foi quebrado.
Uma vez iniciado o failover -
Se ocorrer outra interrupção, você deseja poder falhar novamente. Portanto, configure outro namespace secundário e atualize o emparelhamento.
Extraia mensagens do namespace principal anterior quando ele estiver disponível novamente. Depois disso, use esse namespace para mensagens regulares fora da configuração do Geo-Disaster Recovery ou exclua o namespace primário antigo.
Nota
Apenas a semântica de avanço de falha é suportada. Nesse cenário, você faz failover e, em seguida, emparelhar novamente com um novo namespace. Não há suporte para failback; por exemplo, como em um cluster SQL.
Você pode automatizar o failover com sistemas de monitoramento ou com soluções de monitoramento personalizadas. No entanto, essa automação exige planejamento e trabalho extras, o que está fora do escopo deste artigo.
Gestão
Se você cometeu um erro, por exemplo, emparelhou as regiões erradas durante a configuração inicial, poderá interromper o emparelhamento dos dois namespaces a qualquer momento. Se você quiser usar os namespaces emparelhados como namespaces regulares, exclua o alias.
Usar namespace existente como alias
Se você tiver um cenário no qual não pode alterar as conexões de produtores e consumidores, poderá reutilizar o nome do namespace como o nome do alias. Veja o código de exemplo no GitHub aqui.
Exemplos
Os exemplos no GitHub mostram como configurar e iniciar um failover. Estes exemplos demonstram os seguintes conceitos:
- Um exemplo .NET e configurações que são necessárias na ID do Microsoft Entra para usar o Azure Resource Manager com Service Bus, para configurar e habilitar a Recuperação de Desastres Geográficos.
- Etapas necessárias para executar o código de exemplo.
- Como usar um namespace existente como um alias.
- Etapas para habilitar alternativamente a Recuperação de Desastres Geográficos via PowerShell ou CLI.
- Envie e receba do namespace primário ou secundário atual usando o alias.
Considerações
Observe as seguintes considerações a ter em mente com esta versão:
- No planejamento de failover, você também deve considerar o fator tempo. Por exemplo, se você perder a conectividade por mais de 15 a 20 minutos, poderá decidir iniciar o failover.
- O fato de nenhum dado ser replicado significa que as sessões ativas atualmente não são replicadas. Além disso, a deteção de duplicados e mensagens agendadas podem não funcionar. Novas sessões, novas mensagens agendadas e novas duplicatas funcionam.
- O failover de uma infraestrutura distribuída complexa deve ser ensaiado pelo menos uma vez.
- A sincronização de entidades pode levar algum tempo, aproximadamente 50-100 entidades por minuto. Subscrições e regras também contam como entidades.
Pontos finais privados
Esta seção fornece mais considerações ao usar a Recuperação de Desastres Geográficos com namespaces que usam pontos de extremidade privados. Para saber mais sobre como usar pontos de extremidade privados com o Service Bus em geral, consulte Integrar o Barramento de Serviço do Azure com o Azure Private Link.
Novos emparelhamentos
Se você tentar criar um emparelhamento entre um namespace primário com um ponto de extremidade privado e um namespace secundário sem um ponto de extremidade privado, o emparelhamento falhará. O emparelhamento será bem-sucedido somente se os namespaces primário e secundário tiverem pontos de extremidade privados. Recomendamos que você use as mesmas configurações nos namespaces primário e secundário e em redes virtuais nas quais pontos de extremidade privados são criados.
Nota
Quando você tenta emparelhar o namespace primário com um ponto de extremidade privado e o namespace secundário, o processo de validação verifica apenas se existe um ponto de extremidade privado no namespace secundário. Ele não verifica se o ponto de extremidade funciona ou funciona após o failover. É sua responsabilidade garantir que o namespace secundário com ponto de extremidade privado funcione conforme o esperado após o failover.
Para testar se as configurações de ponto de extremidade privado são as mesmas, envie uma solicitação Get queues para o namespace secundário de fora da rede virtual e verifique se você recebeu uma mensagem de erro do serviço.
Emparelhamentos existentes
Se o emparelhamento entre namespace primário e secundário já existir, a criação de ponto de extremidade privado no namespace primário falhará. Para resolver, crie primeiro um ponto de extremidade privado no namespace secundário e, em seguida, crie um para o namespace primário.
Nota
Embora permitamos acesso somente leitura ao namespace secundário, atualizações para as configurações de ponto de extremidade privado são permitidas.
Configuração recomendada
Ao criar uma configuração de recuperação de desastres para seu aplicativo e Service Bus, você deve criar pontos de extremidade privados para namespaces primários e secundários do Service Bus em redes virtuais que hospedam instâncias primárias e secundárias do seu aplicativo.
Digamos que você tenha duas redes virtuais: VNET-1, VNET-2 e esses namespaces primários e secundários: ServiceBus-Namespace1-Primary, ServiceBus-Namespace2-Secondary. Você precisa fazer as seguintes etapas:
- No
ServiceBus-Namespace1-Primary, crie dois pontos de extremidade privados que usam sub-redes de VNET-1 e VNET-2 - No
ServiceBus-Namespace2-Secondary, crie dois pontos de extremidade privados que usam as mesmas sub-redes de VNET-1 e VNET-2
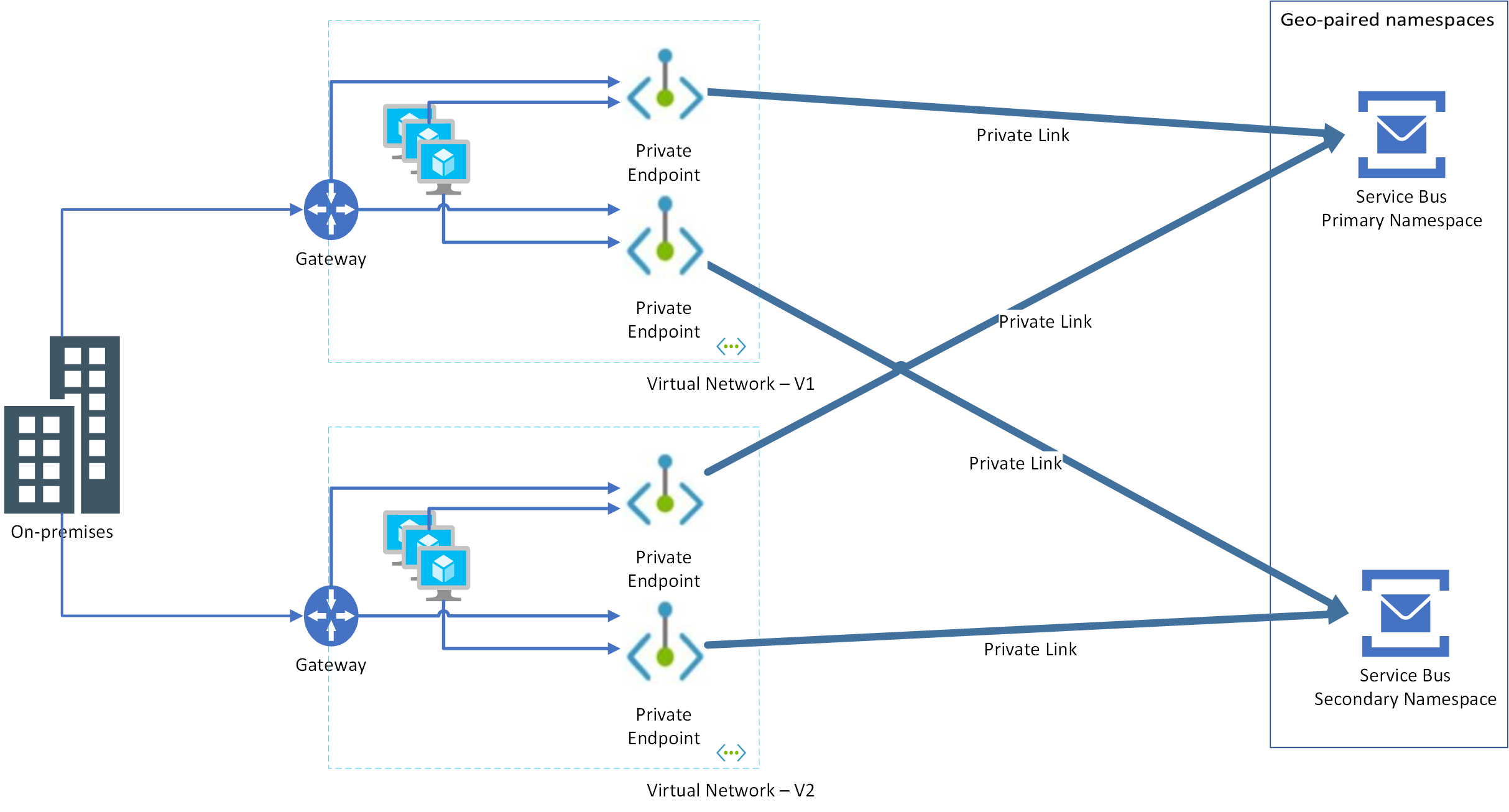
A vantagem dessa abordagem é que o failover pode ocorrer na camada de aplicativo independentemente do namespace do Service Bus. Considere os seguintes cenários:
Failover somente de aplicativo: aqui, o aplicativo não existe em VNET-1, mas é movido para VNET-2. Como ambos os pontos de extremidade privados são configurados em VNET-1 e VNET-2 para namespaces primários e secundários, o aplicativo simplesmente funciona.
Failover somente de namespace do Service Bus: aqui novamente, como ambos os pontos de extremidade privados são configurados em ambas as redes virtuais para namespaces primários e secundários, o aplicativo simplesmente funciona.
Nota
Para obter orientação sobre a recuperação de desastres geográficos de uma rede virtual, consulte Rede virtual - continuidade de negócios.
Controlo de acesso baseado em funções
As atribuições RBAC (controle de acesso baseado em função) do Microsoft Entra para entidades do Service Bus no namespace primário não são replicadas para o namespace secundário. Crie atribuições de função manualmente no namespace secundário para proteger o acesso a elas.
Próximos passos
- Consulte a referência da API REST de recuperação de desastres geográficos aqui.
- Execute o exemplo de Geo-Disaster Recovery no GitHub.
- Consulte o exemplo de Geo-Disaster Recovery que envia mensagens para um alias.
Para saber mais sobre as mensagens do Service Bus, consulte os seguintes artigos: