Analisar o relatório do Planeador de Implementações do Azure Site Recovery
Este artigo aborda as folhas do relatório do Excel que o Planeador de Implementações do Azure Site Recovery gera para um cenário de Hyper-V para o Azure.
Resumo no local
A folha de cálculo de resumo no local proporciona uma descrição geral do ambiente do Hyper-V com perfis criados:

Start date (Data de início) e End date (Data de fim): as datas de início e de fim dos dados de criação de perfis considerados para a geração de relatórios. Por predefinição, a data de início é a data em que a criação dos perfis é iniciada e a de fim é a data em que a criação para. Estas informações podem ser os valores de "StartDate" e "EndDate", caso o relatório seja gerado com estes parâmetros.
Total number of profiling days (Número total de dias de criação de perfis): o número total de dias de criação de perfis entre as datas de início e de fim para as quais o relatório é gerado.
Number of compatible virtual machines (Número de máquinas virtuais compatíveis): o número total de máquinas virtuais compatíveis para as quais são calculadas a largura de banda de rede necessária, o número necessário de contas armazenamento e os núcleos do Azure.
Total number of disks across all compatible virtual machines (Número total de discos em todas as máquinas virtuais compatíveis): o número total de discos em todas as VMs compatíveis.
Average number of disks per compatible virtual machine (Número médio de discos por máquina virtual compatível): o número médio de discos calculado em todas as VMs compatíveis.
Average disk size (GB) (Tamanho médio de discos [GB]): o tamanho de disco médio calculado em todas as VNs compatíveis.
Desired RPO (minutes) (RPO Pretendido [minutos]): o objetivo de ponto de recuperação predefinido ou o valor transmitido para o parâmetro "DesiredRPO" no momento da geração do relatório, para calcular a largura de banda necessária.
Desired bandwidth (Mbps) (Largura de Banda Pretendida [Mbps]): o valor que transmitiu para o parâmetro "Bandwidth" no momento da geração do relatório, para calcular o objetivo de ponto de recuperação (RPO) alcançável.
Observed typical data churn per day (GB) (Alterações a dados típicas registadas por dia [GB]): a alteração a dados média registada em todos os dias de criação de perfis.
Recomendações
A folha de recomendações do relatório de Hyper-V para o Azure tem os seguintes detalhes de acordo com o RPO pretendido selecionado:

Dados de perfil

Período de dados de criação de perfis: o período durante o qual a criação de perfis foi executada. Por predefinição, a ferramenta inclui todos os dados de criação de perfis no cálculo. Se tiver utilizado a opção StartDate e EndDate na geração do relatório, gera o relatório para o período específico.
Number of Hyper-V servers profiled (Número de servidores de Hyper-V com perfis criados): o número de servidores de Hyper-V cujo relatório das VMs é gerado. Selecione o número para ver o nome dos servidores de Hyper-V. É aberta a folha On-premises Storage Requirement (Requisito de Armazenamento no Local) que mostra todos os servidores, juntamente com o respetivo requisito de armazenamento.
RPO Pretendido: o objetivo de ponto de recuperação para a sua implementação. Por predefinição, a largura de banda de rede necessária é calculada para valores de RPO de 15, 30 e 60 minutos. Com base na seleção, os valores afetados são atualizados na folha. Se tiver utilizado o parâmetro DesiredRPOinMin ao gerar o relatório, esse valor é mostrado no resultado Desired RPO (RPO Pretendido).
Descrição geral da criação de perfis

Total Profiled Virtual Machines (Total de Máquinas Virtuais para as quais Foram Criados Perfis): o número total de VMs cujos dados de criação de perfis estão disponíveis. Se VMListFile tiver nomes de VMs para as quais não foram criados perfis, essas VMs não são consideradas na geração do relatório e são excluídas da contagem total de VMs para as quais foram criados perfis.
Compatible Virtual Machines (Máquinas Virtuais Compatíveis): o número de VMs que podem ser protegidas para o Azure com o Azure Site Recovery. É o número total de VMs compatíveis para as quais são calculadas a largura de banda de rede necessária, o número de contas de armazenamento e o número de núcleos do Azure. Os detalhes de todas as VMs compatíveis estão disponíveis na secção “Compatible VMs” (“VMs Compatíveis”).
Incompatible Virtual Machines (Máquinas Virtuais Não Compatíveis): o número de VMs para as quais foram criados perfis que são incompatíveis para proteção com o Site Recovery. Os motivos da incompatibilidade estão apontados na secção “Incompatible VMs” (“VMs Incompatíveis”), abaixo. Se VMListFile tiver nomes de VMs para as quais não foram criados perfis, essas VMs são excluídas da contagem de VMs incompatíveis. Estas VMs são listadas como “Data not found” (“Dados não encontrados”), na parte final da secção “Incompatible VMs”.
Desired RPO (RPO Pretendido): o objetivo de ponto de recuperação pretendido, em minutos. O relatório é gerado para três valores de RPO: 15 (predefinição), 30 e 60 minutos. A recomendação de largura de banda no relatório é alterada com base no que selecionar na lista pendente Desired RPO (RPO Pretendido), no canto superior direito da folha. Se tiver utilizado o parâmetro -DesiredRPO com um valor personalizado para gerar o relatório, esse valor personalizado é apresentado como a predefinição na lista pendente Desired RPO.
Required network bandwidth (Mbps) (Largura de banda de rede necessária [Mbps])

To meet RPO 100 percent of the time (Para satisfazer o RPO em 100 por cento do tempo): é a largura de banda recomendada em Mbps a ser alocada para satisfazer o seu RPO pretendido durante 100 por cento do tempo. Esta quantidade de largura de banda tem de estar dedicada à replicação delta de estado estável de todas as VMs compatíveis, para evitar possíveis violações ao RPO.
To meet RPO 90% of the time (Para satisfazer o RPO em 90 por cento do tempo): talvez devido a preços de banda larga ou a outro motivo, não pode definir a largura de banda necessária para cumprir os seus RPO pretendidos 100 por cento do tempo. Se for este o caso, pode utilizar uma definição de largura de banda inferior que satisfaça o RPO pretendido em 90 por cento do tempo. Para compreender as implicações de definir esta menor largura de banda, o relatório disponibiliza uma análise de hipóteses quanto ao número e à duração das violações de RPO que podem ser esperadas.
Achieved Throughput (Débito Alcançado): débito do servidor onde executou o comando GetThroughput para a região do Azure onde está localizada a conta de armazenamento. Este número de débito indica o nível estimado que pode alcançar quando utiliza o Site Recovery para proteger as VMs compatíveis. As características de rede e de armazenamento do servidor de Hyper-V têm de ser iguais às do servidor em que executa a ferramenta.
Para todas as implementações empresariais do Site Recovery, recomendamos utilizar o ExpressRoute.
Required storage accounts (Contas de armazenamento necessárias)
O gráfico seguinte mostra o número total de contas de armazenamento (standard e premium) necessárias para proteger todas as VMs compatíveis. Para obter a conta de armazenamento a utilizar para cada VM, veja a secção "VM-storage placement” (“Colocação de armazenamento de VM").

Número de núcleos do Azure necessários
Este resultado é o número total de núcleos a configurar antes da ativação pós-falha ou da ativação pós-falha de teste de todas as VMs compatíveis. Se não estiverem disponíveis núcleos suficientes na subscrição, o Site Recovery não conseguirá criar VMs no momento da ativação pós-falha de teste ou da ativação pós-falha.

Requisito de armazenamento no local adicional
O total de armazenamento livre necessário em servidores de Hyper-V para a replicação inicial com êxito e a replicação de diferenças para garantir que a replicação de VM não causará qualquer período de inatividade indesejável para as suas aplicações de produção. Estão disponíveis mais informações sobre cada requisito de volume em Requisito de armazenamento no local (On-premises storage requirement).
Para compreender por que motivo é necessário espaço livre para a replicação, veja a secção On-premises storage requirement (Requisito de armazenamento no local).

Frequência de cópia máxima
Tem de definir a frequência de cópia máxima recomendada para a replicação alcançar o RPO pretendido. A predefinição são cinco minutos. Pode definir a frequência de cópia como 30 segundos para alcançar um RPO melhor.
Análise de hipóteses
 Essa análise descreve quantas violações podem ocorrer durante o período de criação de perfil quando você define uma largura de banda menor para que o RPO desejado seja atendido apenas 90% do tempo. Podem ocorrer uma ou mais violações de RPO num determinado dia. O gráfico mostra o pico de RPO do dia. Com base nesta análise, pode decidir se o número de violações de RPO de todos os dias e a contagem de picos do RPO por dia é aceitável com a largura de banda inferior especificada. Se for aceitável, pode alocar a largura de banda mais baixa para a replicação. Se não for inaceitável, aloque mais largura de banda, conforme sugerido para satisfazer o RPO pretendido em 100 por cento do tempo.
Essa análise descreve quantas violações podem ocorrer durante o período de criação de perfil quando você define uma largura de banda menor para que o RPO desejado seja atendido apenas 90% do tempo. Podem ocorrer uma ou mais violações de RPO num determinado dia. O gráfico mostra o pico de RPO do dia. Com base nesta análise, pode decidir se o número de violações de RPO de todos os dias e a contagem de picos do RPO por dia é aceitável com a largura de banda inferior especificada. Se for aceitável, pode alocar a largura de banda mais baixa para a replicação. Se não for inaceitável, aloque mais largura de banda, conforme sugerido para satisfazer o RPO pretendido em 100 por cento do tempo.
Recomendação para a replicação inicial com êxito
Esta secção aborda o número de batches em que as VMs devem ser protegidas e a largura de banda mínima necessária para concluir a replicação inicial (IR) com êxito.

As VMs têm de ser protegidas pela ordem dos batches especificada. Cada batch tem uma lista específica de VMs. As VMs do Batch 1 têm de ser protegidas antes das do Batch 2. As VMs do Batch 2 têm de ser protegidas antes das VMs do Batch 3 e assim sucessivamente. Depois de concluída a replicação inicial das VMs do Batch 1, pode ativar a replicação das VMs do Batch 2. Do mesmo modo, após a conclusão da replicação inicial das VMs do Batch 2, pode ativar a replicação das VMs do Batch 3 e assim sucessivamente.
Se a ordem dos batches não for seguida, poderá não existir largura de banda suficiente para a replicação inicial disponível para as VMs que são protegidas mais tarde. Como resultado, a replicação inicial de algumas VMs pode nunca ser concluída ou algumas VMs podem entrar no modo de ressincronização. A criação de batches na IR para a folha RPO selecionada tem as informações detalhadas sobre que VMs devem ser incluídas em cada batch.
O gráfico aqui apresentado mostra a distribuição de largura de banda para a replicação inicial e a replicação de diferenças em batches pela ordem de batch especificada. Se proteger o primeiro batch de VMs, a largura de banda completa estará disponível para a replicação inicial. Assim que a replicação inicial do primeiro batch tiver terminado, parte da largura de banda será necessária para a replicação delta. A largura de banda restante estará disponível para a replicação inicial do segundo batch de VMs.
A barra do Batch 2 mostra a largura de banda de replicação de diferenças necessária para as VMs do Batch 1 e a largura de banda disponível para a replicação inicial para as VMs do Batch 2. Da mesma forma, a barra do Batch 3 mostra a largura de banda necessária para a replicação delta dos batches anteriores (VMs do Batch 1 e do Batch 2) e a largura de banda disponível para a replicação inicial do Batch 3 e assim sucessivamente. Quando a replicação inicial de todos os batches estiver terminada, a última barra mostra a largura de banda necessária para a replicação delta de todas as VMs protegidas.
Por que é necessária a criação de batches na replicação inicial? O tempo de conclusão da replicação inicial baseia-se no tamanho de disco das VMs, no espaço em disco utilizado e no débito de rede disponível. Os detalhes estão disponíveis na criação de batches na IR para uma folha RPO selecionada.
Estimativa de custos
O gráfico mostra a vista de resumo do custo total estimado da recuperação após desastre (DR) para o Azure da região de destino que escolheu e a moeda que especificou para a geração do relatório.

O resumo ajuda-o a compreender o custo que tem de pagar por armazenamento, computação, rede e licenciamento quando protege todas as suas VMs compatíveis para o Azure com o Azure Site Recovery. O custo é calculado para as VMs compatíveis e não para todas as VMs para as quais foram criados perfis.
Pode ver o custo mensalmente ou anualmente. Saiba mais sobre as regiões de destino suportadas e as moedas suportadas.
Custo por componentes: o custo total de DR é dividido em quatro componentes: custo de computação, armazenamento, rede e licenciamento do Site Recovery. O custo é calculado com base no consumo incorrido durante a replicação e no momento de teste de DR. Para os cálculos, são utilizados a computação, o armazenamento (premium e standard), o ExpressRoute/VPN configurado entre o site no local e o licenciamento do Site Recovery.
Custo por estados: o custo total da recuperação após desastre é categorizado com base em dois estados diferentes - replicação e teste de DR.
Custo da replicação: o custo que é incorrido durante a replicação. Abrange o custo de armazenamento, de rede e de licenciamento do Site Recovery.
Custo de exploração de DR: o custo que é incorrido durante as ativações pós-falha de teste. O Site Recovery acelera as VMS durante a ativação pós-falha de teste. O custo de teste de DR abrange o custo de armazenamento e de computação das VMs em execução.
Custo de Armazenamento do Azure por Mês/Ano: o gráfico de barras mostra o custo total de armazenamento que é incorrido para armazenamento premium e standard para a replicação e teste de DR. Pode ver a análise de custo detalhada por VM na folha Estimativa de Custos.
Growth factor and percentile values used (Fator de crescimento e valores de percentil utilizados)
Esta secção da parte inferior da folha mostra o valor do percentil utilizado em todos os contadores de desempenho das VNs com perfis criados (a predefinição é o percentil 95). Também mostra o fator de crescimento (a predefinição é 30 por cento) utilizado em todos os cálculos.

Recomendações tendo a largura de banda disponível como entrada

Poderá haver casos em que sabe que não pode definir uma largura de banda com mais de x Mbps para a replicação do Site Recovery. Pode utilizar a ferramenta para introduzir a largura de banda disponível (mediante a utilização do parâmetro -Bandwidth durante a geração do relatório) e obter o RPO alcançável em minutos. Com este valor de RPO alcançável, pode decidir se precisa de aprovisionar largura de banda adicional ou se está satisfeito com uma solução de recuperação após desastre com este RPO.

Recomendação de colocação de armazenamento de VMs

Disk Storage Type (Tipo de Armazenamento de Disco): uma conta de armazenamento standard ou premium, que é utilizada para replicar todas as VMs correspondentes mencionadas na coluna VMs to Place (“VMs a Colocar”).
Suggested Prefix (Prefixo Sugerido): o prefixo de três carateres sugerido que pode ser utilizado para dar um nome à conta de armazenamento. Pode utilizar o seu próprio prefixo, mas a sugestão da ferramenta segue a convenção de nomenclatura de partições para contas de armazenamento.
Suggested Account Name (Nome de Conta Sugerido): o nome da conta de armazenamento depois de incluir o prefixo sugerido. Substitua o nome entre colchetes angulares (< e >) pela sua entrada personalizada.
Log Storage Account (Conta de Armazenamento de Registos): todos os registos de replicações são armazenados numa conta de armazenamento standard. Relativamente a VMs que são replicadas para uma conta de armazenamento premium, configure uma conta de armazenamento standard adicional para o armazenamento de registos. Uma conta de armazenamento de registos standard individual pode ser utilizada por várias contas de armazenamento de replicações premium. As VMs que são replicadas para contas de armazenamento standard utilizam a mesma conta de armazenamento para os registos.
Suggested Log Account Name (Nome de Conta de Registos Sugerido): o nome da conta de registos de armazenamento depois de incluir o prefixo sugerido. Substitua o nome entre colchetes angulares (< e >) pela sua entrada personalizada.
Placement Summary (Resumo da Colocação): um resumo da carga total de VMs na conta de armazenamento no momento da replicação e da ativação pós-falha de teste ou da ativação pós-falha. O resumo inclui:
- O número total de VMs mapeadas para a conta de armazenamento.
- IOPS de leitura/escrita total em todas as VMs que vão ser colocadas nesta conta de armazenamento.
- IOPS de escrita total (replicação).
- O tamanho de configuração total em todos os discos.
- O número total de discos.
VMs to Place (VMs a Colocar): uma lista de todas as VMs que devem ser colocadas nesta conta de armazenamento específica para otimizar o desempenho e a utilização.
Compatible VMs (VMs Compatíveis)
O relatório do Excel gerado pelo Planeador de Implementações do Site Recovery disponibiliza todos os detalhes das VMs compatíveis na folha "Compatible VMs" (VMs Compatíveis).
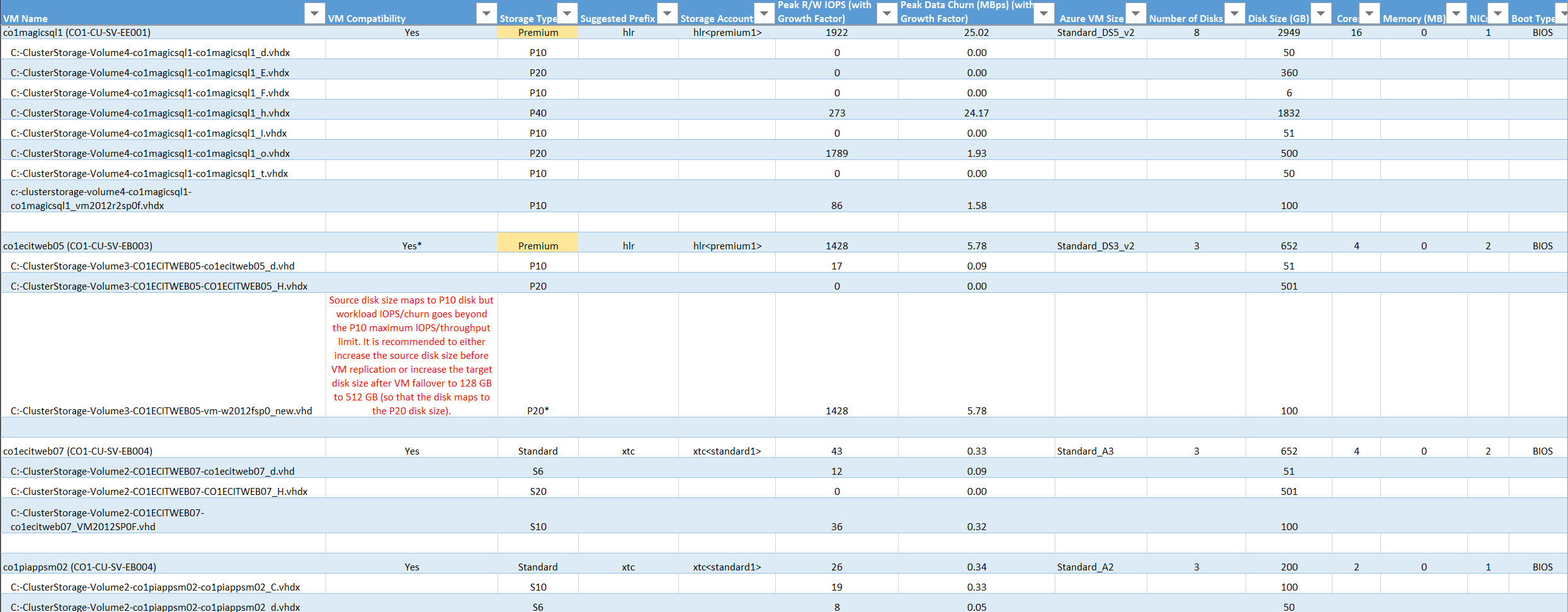
VM Name (Nome da VM): o nome da VM que é utilizado em VMListFile quando é gerado um relatório. Esta coluna também apresenta os discos (VHDs) que estão ligados às VMs. Os nomes incluem os nomes do anfitrião Hyper-V onde as VMs foram colocadas quando a ferramenta os detetou durante o período de criação de perfis.
Compatibilidade de VM: Os valores são Sim e Sim*. Sim* é para casos em que a VM é adequada para SSDs premium. Aqui, a elevada taxa de abandono da criação de perfis ou o disco IOPS encaixa num tamanho de disco premium superior ao tamanho mapeado para o disco. A conta de armazenamento decide para que tipo de disco de armazenamento premium mapear os discos com base no tamanho dos mesmos:
- <128 GB é um P10.
- 128 GB a 256 GB é P15.
- 256 GB a 512 GB é P20.
- 512 GB a 1024 GB é P30.
- 1025 GB a 2048 GB é P40.
- 2049 GB a 4095 GB é P50.
Por exemplo, se as características da carga de trabalho de um disco o colocarem na categoria P20 ou P30, mas o tamanho o mapear para um tipo de disco de armazenamento premium inferior, a ferramenta marcará essa VM como Sim*. Também lhe recomenda que altere o tamanho do disco de origem, para se enquadrar no tipo de disco de armazenamento premium aconselhado, ou que altere o tipo de disco de destino a seguir à ativação pós-falha.
Storage Type (Tipo de Armazenamento): standard ou premium.
Suggested Prefix (Prefixo Sugerido): o prefixo da conta de armazenamento de três carateres.
Storage Account (Conta de Armazenamento): o nome que utiliza o prefixo da conta de armazenamento sugerido.
Peak R/W IOPS (with Growth Factor) (Pico de IOPS de R/W [com Fator de Crescimento]): o pico de IOPS de leitura/escrita da carga de trabalho no disco (a predefinição é o percentil 95), juntamente com o fator de crescimento futuro (a predefinição são 30 por cento). O IOPS de leitura/escrita total das VMs não é sempre a soma do IOPS de leitura/escrita dos discos individuais das mesmas. O pico do IOPS de leitura/escrita das VMs é o pico da soma do IOPS de leitura/escrita dos discos individuais das mesmas durante cada minuto do período de criação de perfis.
Peak Data Churn in MB/s (with Growth Factor) (Pico de Alterações a Dados em MB/s [com Fator de Crescimento]): o pico das alterações a dados no disco (a predefinição é o percentil 95), juntamente com o fator de crescimento futuro (a predefinição é 30 por cento). O total de alterações a dados das VMs não é sempre a soma das alterações a dados dos discos individuais das mesmas. O pico das alterações a dados das VMs é o pico da soma das alterações a dados dos discos individuais das mesmas durante cada minuto do período de criação de perfis.
Azure VM Size (Tamanho da VM do Azure): o tamanho mapeado ideal da VM dos Serviços Cloud do Azure para esta VM no local. O mapeamento baseia-se na memória da VM no local, no número de discos/núcleos/NICs e no IOPS de leitura/escrita. A recomendação é sempre o tamanho de VM do Azure mais baixo que corresponda a todas as características da VM no local.
Number of Disks (Número de Discos): o número total de discos da máquina virtual (VHDs) na VM.
Disk size (GB) (Tamanho do disco [GB]): o tamanho total de todos os discos na VM. A ferramenta também mostra o tamanho dos discos individuais na VM.
Cores (Núcleos): o número de núcleos de CPU na VM.
Memory (MB) : a RAM na VM.
NICs: o número de NICs na VM.
Boot Type (Tipo de Arranque): o tipo de arranque da VM. Pode ser BIOS ou EFI.
Incompatible VMs (VMs Não Compatíveis)
O relatório do Excel gerado pelo Planeador de Implementações do Site Recovery mostra todos os detalhes das VMs não compatíveis na folha "Incompatible VMs".

VM Name (Nome da VM): o nome da VM que é utilizado em VMListFile quando é gerado um relatório. Esta coluna também apresenta os discos (VHDs) que estão ligados às VMs. Os nomes incluem os nomes do anfitrião Hyper-V onde as VMs foram colocadas quando a ferramenta os detetou durante o período de criação de perfis.
VM Compatibility (Compatibilidade de VM): indica a razão pela qual a VM especificada é incompatível para utilização com o Site Recovery. São descritas as razões para todos os discos incompatíveis da VM, que, com base nos limites do armazenamento publicados, podem ser as seguintes:
O tamanho do disco é superior a 4095 GB. Atualmente, o Armazenamento do Azure não suporta tamanhos de discos superiores a 4095 GB.
O disco do SO é superior a 2047 GB para VMs de geração 1 (tipo de arranque do BIOS). O Site Recovery não suporta tamanhos do disco de SO superiores 2047 GB para VMs de geração 1.
O disco do SO é superior a 300 GB para VMs de geração 2 (tipo de arranque do EFI). O Site Recovery não suporta tamanhos do disco de SO superiores 300 GB para VMs de geração 2.
Não são suportados nomes de VMs que contenham qualquer um dos seguintes carateres: “” [] `. A ferramenta não consegue obter dados de criação de perfis de VMs que contenham qualquer um destes carateres no nome.
É partilhado um VHD por duas ou mais VMs. O Azure não suporta VMs com VHD partilhado.
Não é suportada uma VM com Canal de Fibra Virtual. O Site Recovery não suporta VMs com o Canal de Fibra Virtual.
Um cluster do Hyper-V não contém um mediador de replicações. O Site Recovery não suporta uma VM num cluster do Hyper-V se o Mediador de Réplicas do Hyper-V não estiver configurado para o cluster.
Uma VM não é de elevada disponibilidade. O Site Recovery não suporta uma VM de um nó de cluster do Hyper-V cujos VHDs estejam armazenados no disco local em vez de no disco de cluster.
O tamanho total da VM (replicação + ativação pós-falha de teste) excede o limite de tamanho da conta de armazenamento premium suportado (35 TB). Geralmente, esta incompatibilidade ocorre quando um disco individual na VM tem uma característica de desempenho que excede os limites máximos suportados pelo Azure ou o Site Recovery relativamente ao armazenamento standard. Uma instância deste género envia a VM para a zona de armazenamento premium. No entanto, o tamanho máximo suportado das contas de armazenamento premium é 35 TB. Não é possível proteger uma VM protegida individual em várias contas de armazenamento.
Quando uma ativação pós-falha de teste é executada numa VM protegida e se um disco não gerido estiver configurado para ativação pós-falha de teste, aquela é executada na mesma conta de armazenamento na qual a replicação está em curso. Neste caso, é preciso uma quantidade de espaço de armazenamento adicional igual à da replicação. Assegura o progresso da replicação e o sucesso da ativação pós-falha de teste em paralelo. Se um disco gerido estiver configurado para ativação pós-falha de teste, não é necessário contabilizar espaço adicional para a VM de ativação pós-falha de teste.
O IOPS de origem excede o limite de IOPS de armazenamento suportado de 7500 por disco.
O IOPS de origem excede o limite de IOPS de armazenamento suportado de 80 000 por disco.
A rotatividade média de dados da VM de origem excede o limite de rotatividade de dados de Recuperação de Site suportado de 20 MB/s para tamanho médio de E/S.
A média do IOPS de escrita efetiva da VM de origem excede o limite de IOPS suportado pelo Site Recovery de 840.
O armazenamento de instantâneos calculado excede o limite de armazenamento de instantâneos suportado de 10 TB.
Peak R/W IOPS (with Growth Factor) (Pico de IOPS de R/W [com Fator de Crescimento]): o pico de IOPS da carga de trabalho no disco (a predefinição é o percentil 95), juntamente com o fator de crescimento futuro (a predefinição são 30 por cento). O IOPS de leitura/escrita total da VM não é sempre a soma do IOPS de leitura/escrita dos discos individuais da mesma. O pico do IOPS de leitura/escrita da VM é o pico da soma do IOPS de leitura/escrita dos discos individuais da mesma durante cada minuto do período de criação de perfis.
Peak Data Churn (MB/s) (with Growth Factor) (Pico de Alterações a Dados [MB/s] [com Fator de Crescimento]): o pico das alterações a dados no disco (a predefinição é o percentil 95), juntamente com o fator de crescimento futuro (a predefinição é 30 por cento). Tenha em conta que o total de alterações a dados da VM não é sempre a soma das alterações a dados dos discos individuais da mesma. O pico das alterações a dados das VMs é o pico da soma das alterações a dados dos discos individuais das mesmas durante cada minuto do período de criação de perfis.
Number of Disks (Número de Discos): o número total de VHDs na VM.
Disk size (GB) (Tamanho do disco [GB]): o tamanho total de configuração de todos os discos da VM. A ferramenta também mostra o tamanho dos discos individuais na VM.
Cores (Núcleos): o número de núcleos de CPU na VM.
Memory (MB) (Memória [MB]) : a quantidade de RAM na VM.
NICs: o número de NICs na VM.
Boot Type (Tipo de Arranque): o tipo de arranque da VM. Pode ser BIOS ou EFI.
Limites do Azure Site Recovery
A tabela seguinte mostra os limites do Site Recovery. Estes limites baseiam-se em testes, mas não abrangem todas as combinações de E/S de aplicações possíveis. Os resultados reais podem variar consoante a combinação de E/S da sua aplicação. Para obter os melhores resultados, mesmo após o planeamento da implementação, faça testes exaustivos às aplicações através da emissão de uma ativação pós-falha de teste, para ter a perspetiva verdadeira quanto ao desempenho da aplicação.
| Destino do armazenamento da replicação | Tamanho do E/S médio da VM de origem | Média das alterações a dados da VM de origem | Total de alterações a dados da VM de origem por dia |
|---|---|---|---|
| Armazenamento Standard | 8 KB | 2 MB/s por VM | 168 GB por VM |
| Armazenamento Premium | 8 KB | 5 MB/s por VM | 421 GB por VM |
| Armazenamento Premium | 16 KB ou mais | 20 MB/s por VM | 1684 GB por VM |
Estes limites são números médios, que pressupõem uma sobreposição de E/S de 30 por cento. O Site Recovery é capaz de processar um débito superior com base no rácio de sobreposição, em tamanhos de escrita maiores e no comportamento real de E/S da carga de trabalho. Os números anteriores pressupõem um atraso típico de aproximadamente cinco minutos. Ou seja, depois de os dados serem carregados, são processados e é criado um ponto de recuperação ao fim de cinco minutos.
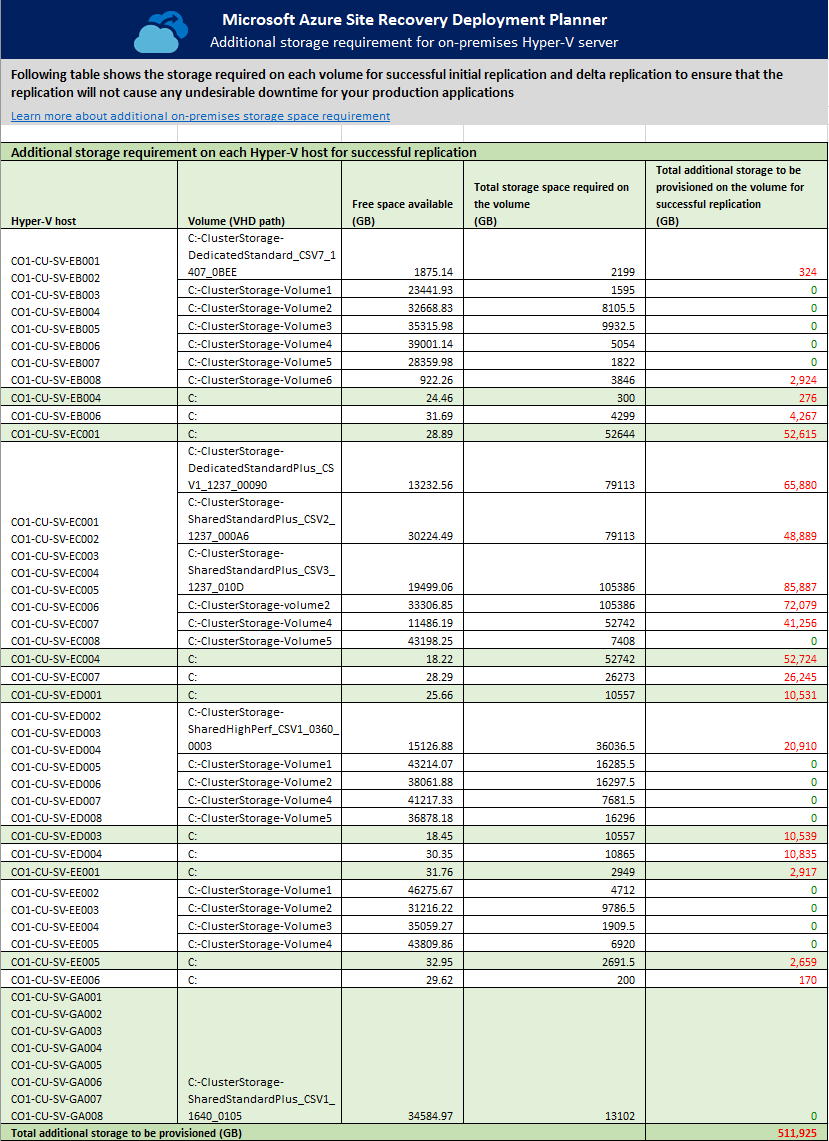
Requisito de armazenamento no local
A folha de cálculo fornece o requisito de espaço livre de armazenamento total para cada volume dos servidores Hyper-V (onde residem os VHDs) para a replicação inicial e replicação de diferenças com êxito. Antes de ativar a replicação, adicione o espaço de armazenamento necessário nos volumes, para garantir que a replicação não vai causar qualquer período de inatividade indesejável das suas aplicações de produção.
O Planeador de Implementações do Site Recovery identifica o requisito de espaço de armazenamento ideal com base no tamanho dos VHDs e na largura de banda de rede utilizados para a replicação.
Porque é que preciso de espaço livre no servidor Hyper-V para a replicação?
Quando ativa a replicação de uma VM, o Site Recovery tira um instantâneo de cada VHD da VM para a replicação inicial (IR). Enquanto a replicação inicial está em curso, as novas alterações são escritas nos discos pela aplicação. O Site Recovery controla estas alterações delta nos ficheiros de registo, o que exige espaço de armazenamento adicional. Enquanto a replicação inicial não estiver concluída, os ficheiros de registo são armazenados localmente.
Se não existir espaço suficiente disponível para os ficheiros de registo e para o instantâneo (AVHDX), a replicação entrará em modo de ressincronização e a replicação nunca será concluída. Na pior das hipóteses, precisa de 100 por cento de espaço livre adicional do tamanho do VHD para a replicação inicial.
Quando a replicação inicial terminar, a replicação delta é iniciada. O Site Recovery controla estas alterações delta nos ficheiros de registo, que são armazenados no volume onde residem os VHDs da VM. Estes ficheiros de registo são replicados para o Azure com uma frequência de cópia configurada. Com base na largura de banda de rede disponível, os ficheiros de registo demoram algum tempo a ser replicados para o Azure.
Se não estiver disponível espaço livre suficiente para armazenar os ficheiros de registo, a replicação é colocada em pausa. Em seguida, o estado de replicação da VM entra em "ressincronização necessária".
Se a largura de banda de rede não for suficiente para enviar os ficheiros de registo para o Azure, aqueles são amontoados no volume. No pior cenário, quando o tamanho dos arquivos de log é aumentado para 50% do tamanho do VHD, a replicação da VM entra em "ressincronização necessária". Na pior das hipóteses, você precisa de 50% de espaço livre adicional do tamanho do VHD para replicação delta.
Hyper-V host (Anfitrião Hyper-V): a lista de servidores Hyper-V com perfis criados. Se um servidor fizer parte de um cluster Hyper-V, todos os nós do cluster são agrupados em conjunto.
Volume (VHD path) [Volume (caminho VHD)] : cada volume de um anfitrião Hyper-V, onde existem VHDs/VHDXs.
Free space available (GB) [Espaço livre disponível (GB)]: o espaço livre disponível no volume.
Total storage space required on the volume (GB) (Total de espaço de armazenamento necessário no volume [GB]): o total de espaço de armazenamento livre necessário no volume para a replicação inicial e a replicação delta com êxito.
Total additional storage to be provisioned on the volume for successful replication (GB) (Total de armazenamento adicional a ser aprovisionado no volume para a replicação com êxito [GB]): recomenda o total de espaço adicional que tem de ser aprovisionado no volume para a replicação inicial e a replicação delta com êxito.
Criação de batches na replicação inicial
Por que é necessária a criação de batches na replicação inicial?
Se todas as VMs forem protegidas ao mesmo tempo, o requisito de armazenamento livre é muito superior. Se não estiver disponível armazenamento suficiente, a replicação das VMs entra no modo de ressincronização. Além disso, o requisito de largura de banda de rede será muito superior para concluir a replicação inicial de todas as VMs em conjunto com êxito.
Criação de batches na replicação inicial para um RPO selecionado
Esta folha de cálculo mostra a vista de detalhes de cada batch para IR. Para cada RPO, é criada uma folha de criação de batches para IR separada.
Depois de seguir a recomendação de requisito de armazenamento no local para cada volume, a informação principal que precisa de replicar é a lista de VMs que podem ser protegidas em paralelo. Estas VMs são agrupadas em conjunto num batch e podem existir vários batches. Proteja as VMs pela ordem dos batches especificada. Primeiro, proteja as VMs do Batch 1. Após a conclusão da replicação inicial, proteja as VMs do Batch 2 e assim sucessivamente. Pode aproveitar a lista de batches e VMs correspondentes desta folha.


Cada batch fornece as seguintes informações:
Hyper-V host (Anfitrião Hyper-V): o anfitrião Hyper-V a proteger.
Virtual Machine (Máquina Virtual): a VM a ser protegida.
Comments (Comentários): se for precisa qualquer ação para um volume específico de uma VM, o comentário é fornecido aqui. Por exemplo, se não estiver disponível num volume espaço livre suficiente, o comentário diz "Adicionar armazenamento adicional para proteger esta VM".
Volume (VHD path) (Volume [caminho do VHD]): o nome do volume onde residem os VHDs da VM.
Free space available on the volume (GB) (Espaço livre disponível no volume [GB]): o espaço em disco livre disponível no volume para a VM. Ao calcular o espaço livre disponível nos volumes, considera o espaço em disco utilizado para a replicação de diferenças pelas VMs dos batches anteriores cujos VHDs estão no mesmo volume.
Por exemplo, VM1, VM2 e VM3 residem num volume, digamos E:\VHDpath. Antes da replicação, o espaço livre no volume é 500 GB. A VM1 faz parte do Batch 1, a VM2 do Batch 2 e a VM3 do Batch 3. Para a VM1, o espaço livre disponível é 500 GB. Para a VM2, o espaço livre disponível é 500 – o espaço em disco necessário para a replicação delta da VM1. Se a VM1 precisar de 300 GB de espaço para a replicação delta, o espaço livre disponível para a VM2 será 500 GB – 300 GB = 200 GB. Da mesma forma, a VM2 precisa de 300 GB para a replicação de diferenças. O espaço livre disponível para a VM3 será 200 GB - 300 GB = -100 GB.
Storage required on the volume for initial replication (GB) [Armazenamento necessário no volume para a replicação inicial (GB)]: o espaço de armazenamento livre necessário no volume para a VM para a replicação inicial.
Storage required on the volume for delta replication (GB) (Armazenamento necessário no volume para a replicação delta [GB]): o espaço de armazenamento livre necessário no volume para a VM para a replicação delta.
Additional storage required based on deficit to avoid replication failure (GB) [Armazenamento adicional necessário com base no défice para evitar a falha da replicação (GB)]: o espaço de armazenamento adicional necessário no volume para a VM. É o requisito máximo de espaço de armazenamento para a replicação inicial e a replicação delta menos o espaço livre disponível no volume.
Minimum bandwidth required for initial replication (Mbps) [Largura de banda mínima necessária para a replicação inicial (Mbps)]: a largura de banda mínima necessária para a replicação inicial para a VM.
Minimum bandwidth required for delta replication (Mbps) (Largura de banda mínima necessária para a replicação delta [Mbps]): a largura de banda mínima necessária para a replicação delta para a VM.
Detalhes de utilização de rede para cada batch
Cada tabela de batch fornece um resumo da utilização de rede do batch.
Bandwidth available for Batch (Largura de banda disponível para o Batch): a largura de banda disponível para o batch depois de considerar a largura de banda da replicação delta do batch anterior.
Approximate bandwidth available for initial replication of batch (Largura de banda aproximada disponível para a replicação inicial do batch): a largura de banda disponível para a replicação inicial das VMs do batch.
Approximate bandwidth consumed for delta replication of batch (Largura de banda aproximada consumida para a replicação de diferenças do batch): a largura de banda necessária para a replicação de diferenças das VMs do batch.
Estimated Initial Replication time for Batch (HH:MM) (Tempo de replicação inicial estimado para o batch [HH:MM]): o tempo estimado da replicação inicial em Horas:Minutos.
Próximos passos
Saiba mais sobre a estimativa de custos.