Resolver erros ao efetuar a ativação pós-falha da VM VMware ou da máquina física do Azure
Você pode receber um dos seguintes erros ao fazer failover de uma máquina virtual para o Azure. Para solucionar problemas, use as etapas descritas para cada condição de erro.
A ativação pós-falha falhou com o ID de Erro 28031
A Recuperação de Site não conseguiu criar uma máquina virtual com failover no Azure. Pode acontecer por uma das seguintes razões:
Não há cota suficiente disponível para criar a máquina virtual: você pode verificar a cota disponível acessando Assinatura -> Uso + cotas. Você pode abrir uma nova solicitação de suporte para aumentar a cota.
Você está tentando fazer failover de máquinas virtuais de famílias de tamanhos diferentes no mesmo conjunto de disponibilidade. Certifique-se de escolher a mesma família de tamanho para todas as máquinas virtuais no mesmo conjunto de disponibilidade. Altere o tamanho indo para Configurações de computação da máquina virtual e, em seguida, tente novamente o failover.
Há uma política na assinatura que impede a criação de uma máquina virtual. Altere a política para permitir a criação de uma máquina virtual e, em seguida, tente novamente o failover.
A ativação pós-falha falhou com o ID de Erro 28092
O Site Recovery não conseguiu criar uma interface de rede para a máquina virtual com failover. Verifique se você tem cota suficiente disponível para criar interfaces de rede na assinatura. Pode verificar a quota disponível acedendo a Subscrição -> Utilização + quotas. Você pode abrir uma nova solicitação de suporte para aumentar a cota. Se você tiver cota suficiente, isso pode ser um problema intermitente, tente a operação novamente. Se o problema persistir mesmo após as tentativas, deixe um comentário no final deste documento.
A ativação pós-falha falhou com o ID de Erro 70038
A Recuperação de Site não conseguiu criar uma máquina virtual Clássica com failover no Azure. Pode acontecer porque:
- Um dos recursos, como uma rede virtual, necessário para que a máquina virtual seja criada, não existe. Crie a rede virtual conforme fornecido em Configurações de rede da máquina virtual ou modifique a configuração para uma rede virtual que já existe e, em seguida, tente failover novamente.
Falha de failover com a ID de erro 170010
A Recuperação de Site não conseguiu criar uma máquina virtual com failover no Azure. Isso pode acontecer porque uma atividade interna de hidratação falhou para a máquina virtual local.
Para abrir qualquer máquina no Azure, o ambiente do Azure requer que alguns dos drivers estejam no estado de início de inicialização e serviços como DHCP estejam no estado de início automático. Assim, a atividade de hidratação, no momento do failover, converte o tipo de inicialização dos drivers atapi, intelide, storflt, vmbus e storvsc para iniciar a inicialização. Ele também converte o tipo de inicialização de alguns serviços, como DHCP, para inicialização automática. Esta atividade pode falhar devido a problemas específicos do ambiente.
Para alterar manualmente o tipo de inicialização de drivers para o sistema operacional convidado do Windows, siga as etapas abaixo:
Faça o download do script sem hidratação e execute-o da seguinte forma. Este script verifica se a VM requer hidratação.
.\Script-no-hydration.ps1Dá o seguinte resultado se for necessária hidratação:
REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 3 expected value = 0 This system doesn't meet no-hydration requirement.Caso a VM cumpra o requisito de não hidratação, o script dá o resultado "Este sistema cumpre o requisito de não hidratação". Nesse caso, todos os drivers e serviços estão no estado exigido pelo Azure e a hidratação na VM não é necessária.
Execute o script no-hydration-set da seguinte forma se a VM não atender aos requisitos de no-hydration.
.\Script-no-hydration.ps1 -setIsso converte o tipo de inicialização de drivers e dará o resultado como abaixo:
REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 3 expected value = 0 Updating registry: REGISTRY::HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\services\storvsc start = 0 This system is now no-hydration compatible.
Failover falhou com um erro informando que os endereços IP de réplica para o adaptador de rede da máquina virtual são inválidos
A operação de failover ou failover de teste pode falhar para uma máquina com o erro "Um ou mais endereços IP de réplica para o adaptador de rede da máquina virtual é inválido", se a limpeza adequada de uma operação de failover de teste anterior não tiver ocorrido. Devido a isso, a máquina de teste ainda pode estar presente no ambiente do Azure e pode estar usando o mesmo endereço IP. Isso faz com que a configuração de destino da máquina virtual se torne crítica.
Para resolver esse problema, verifique se uma limpeza completa de failover de teste foi executada, para que a operação de failover ou failover de teste possa ser bem-sucedida.
Não é possível ligar ou fazer RDP/SSH na máquina virtual com ativação pós-falha porque o botão Ligar está desativado na máquina virtual
Para obter instruções detalhadas de solução de problemas sobre problemas de RDP, consulte nossa documentação aqui.
Para obter instruções detalhadas de solução de problemas sobre problemas de SSH, consulte nossa documentação aqui.
Se o botão Conectar na VM com failover no Azure estiver acinzentado e você não estiver conectado ao Azure por meio de uma Rota Expressa ou conexão VPN Site a Site,
- Vá para Rede de máquina>virtual, clique no nome da interface de rede necessária.
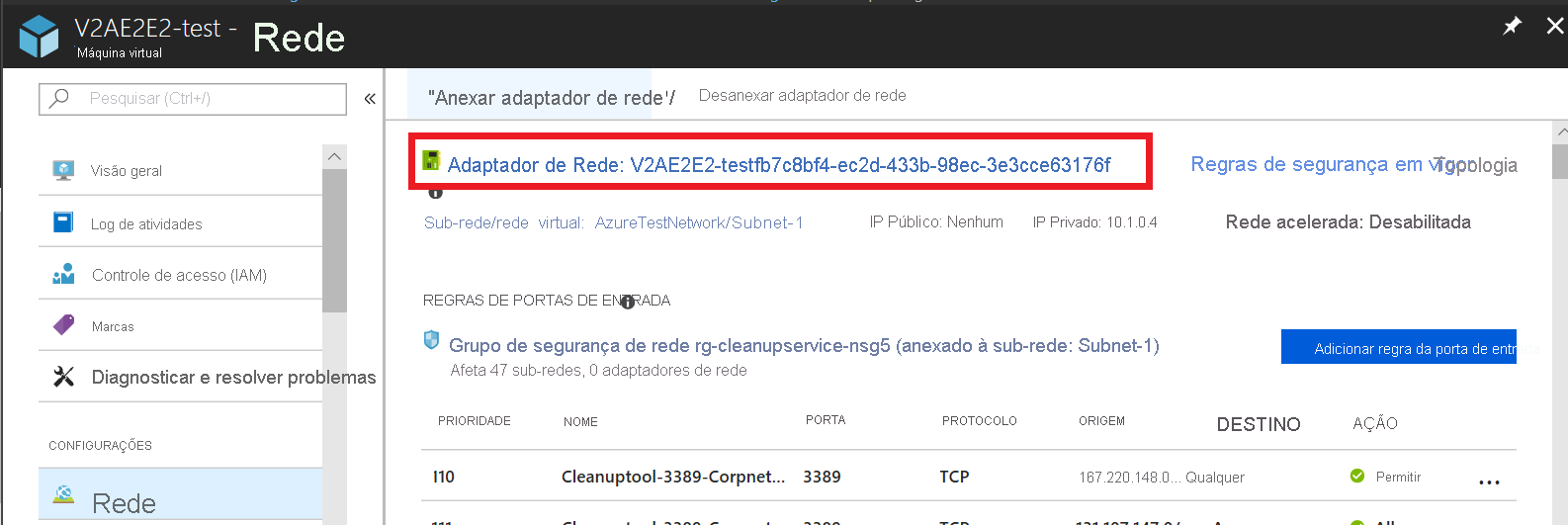
- Navegue até Configurações de IP e, em seguida, selecione no campo de nome da configuração de IP necessária.
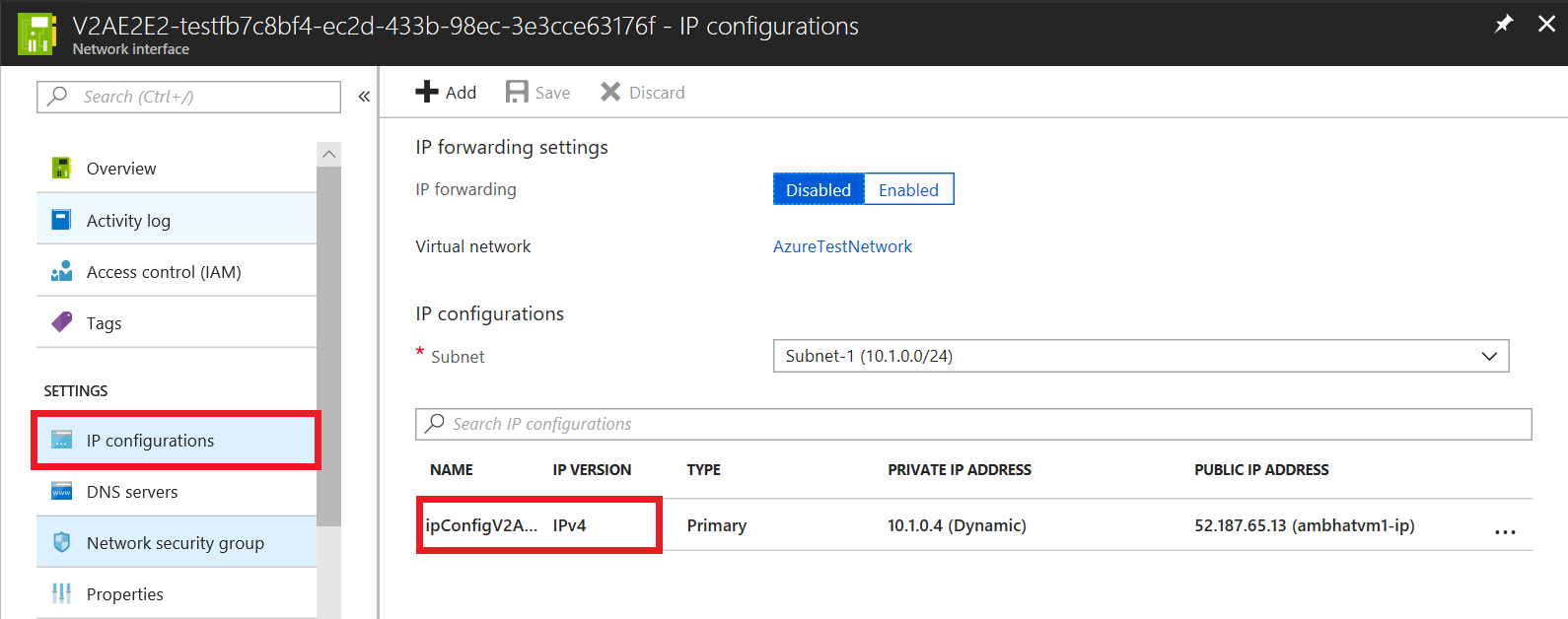
- Para ativar o endereço IP público, selecione Ativar.
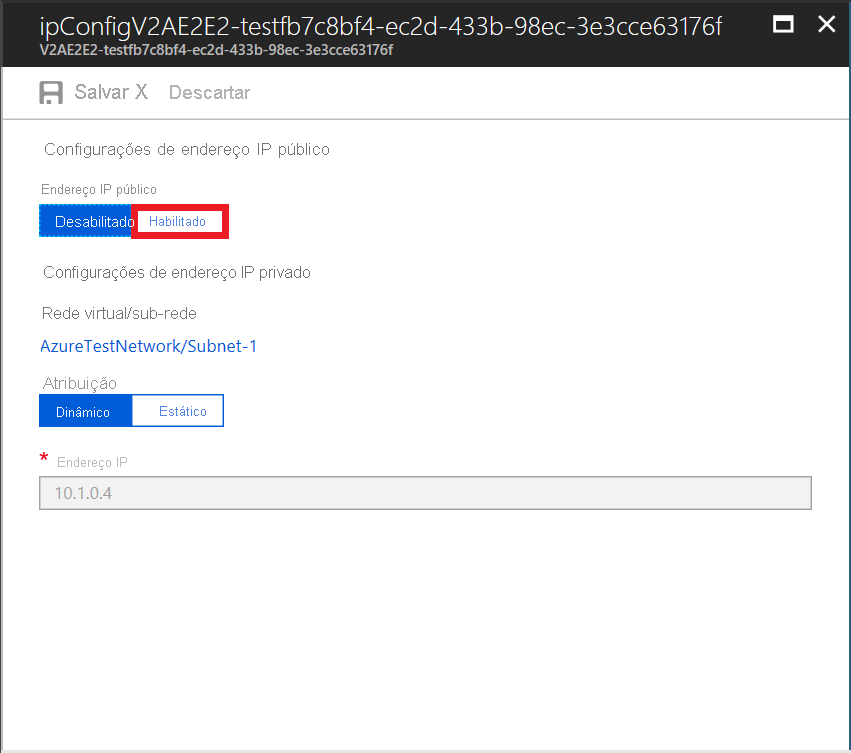
- Clique em Configurar configurações>necessárias Criar novo.
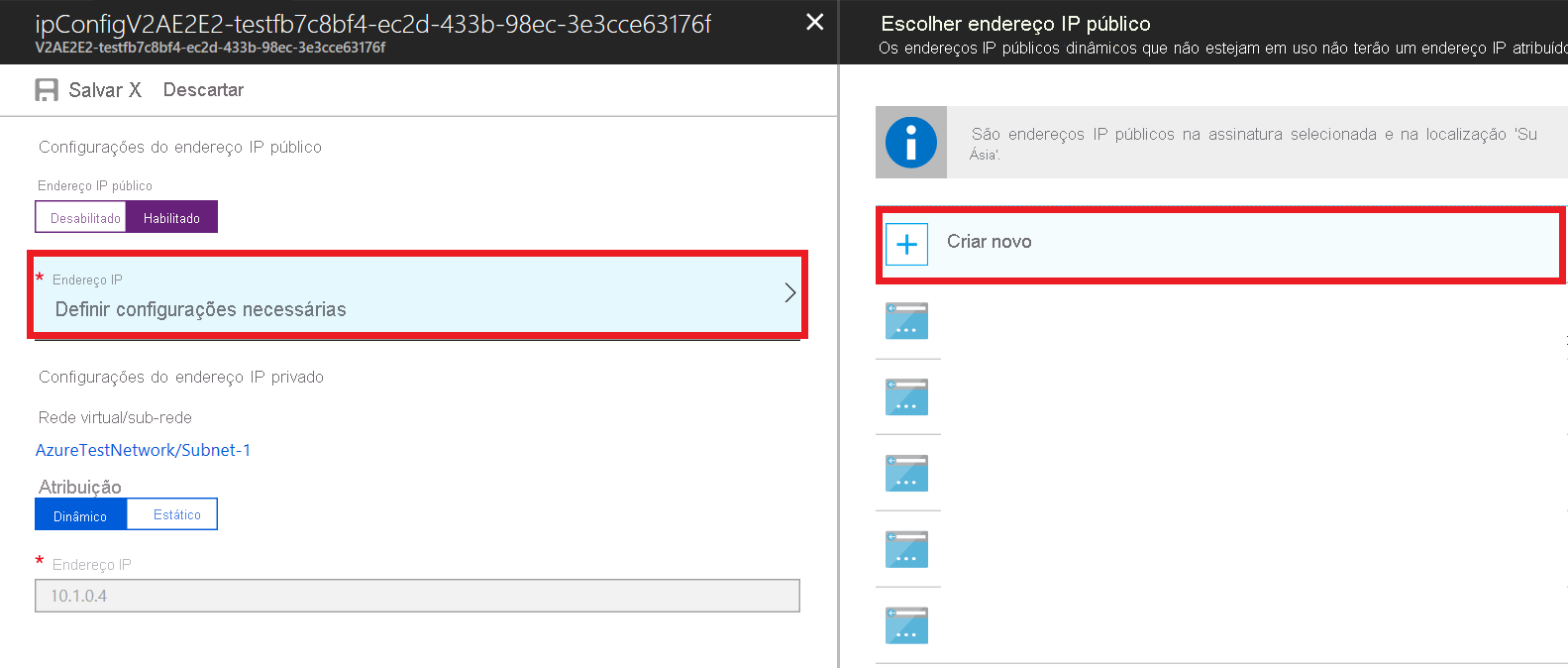
- Digite o nome do endereço público, escolha as opções padrão para SKU e atribuição e selecione OK.
- Agora, para salvar as alterações feitas, selecione Salvar.
- Feche os painéis e navegue até a seção Visão geral da máquina virtual para conectar/RDP.
Não é possível conectar/RDP/SSH - botão VMConnect disponível
Se o botão Conectar na VM com failover no Azure estiver disponível (não acinzentado), verifique o diagnóstico de inicialização em sua máquina virtual e verifique se há erros, conforme listado neste artigo.
Se a máquina virtual não tiver sido iniciada, tente fazer failover para um ponto de recuperação mais antigo.
Se o aplicativo dentro da máquina virtual não estiver ativo, tente fazer failover para um ponto de recuperação consistente com o aplicativo.
Se a máquina virtual estiver associada ao domínio, verifique se o controlador de domínio está funcionando com precisão. Isto pode ser feito seguindo os seguintes passos:
a. Crie uma nova máquina virtual na mesma rede.
b. Certifique-se de que ele seja capaz de ingressar no mesmo domínio no qual se espera que a máquina virtual com failover apareça.
c. Se o controlador de domínio não estiver funcionando corretamente, tente fazer login na máquina virtual com failover usando uma conta de administrador local.
Se estiver a utilizar um servidor DNS personalizado, certifique-se de que está acessível. Isto pode ser feito seguindo os seguintes passos:
a. Crie uma nova máquina virtual na mesma rede e
b. Verifique se a máquina virtual é capaz de fazer a resolução de nomes usando o servidor DNS personalizado
Nota
Habilitar qualquer configuração diferente do Diagnóstico de Inicialização exigiria que o Agente de VM do Azure fosse instalado na máquina virtual antes do failover
Não é possível abrir o console serial após o failover de uma máquina baseada em UEFI no Azure
Se você conseguir se conectar à máquina usando RDP, mas não conseguir abrir o console serial, siga as etapas abaixo:
Se o sistema operacional da máquina for Red Hat ou Oracle Linux 7.*/8.0, execute o seguinte comando na VM do Azure de failover com permissões de raiz. Reinicialize a VM após o comando.
grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
Mensagem de desligamento inesperado (ID de evento 6008)
Ao inicializar um failover pós-failover de VM do Windows, se você receber uma mensagem de desligamento inesperada na VM recuperada, isso indica que um estado de desligamento da VM não foi capturado no ponto de recuperação usado para failover. Isso acontece quando você se recupera até um ponto em que a VM não foi totalmente desligada.
Isso normalmente não é motivo de preocupação e geralmente pode ser ignorado para failovers não planejados. Se o failover for planejado, certifique-se de que a VM seja encerrada corretamente antes do failover e forneça tempo suficiente para que os dados de replicação pendentes no local sejam enviados para o Azure. Em seguida, use a opção Mais recente na tela Failover para que todos os dados pendentes no Azure sejam processados em um ponto de recuperação, que é usado para failover de VM.
Não é possível selecionar o Datastore
Esse problema é indicado quando você não consegue ver o armazenamento de dados no portal do Azure ao tentar proteger novamente a máquina virtual que sofreu um failover. Isso ocorre porque o destino Master não é reconhecido como uma máquina virtual em vCenters adicionados ao Azure Site Recovery.
Para obter mais informações sobre como reproteger uma máquina virtual, consulte Reproteger e fazer failback de máquinas para um site local após failover para o Azure.
Para resolver o problema:
Crie manualmente o destino Master no vCenter que gerencia sua máquina de origem. O armazenamento de dados estará disponível após as próximas operações de descoberta e atualização de malha do vCenter.
Nota
As operações de descoberta e atualização da malha podem levar até 30 minutos para serem concluídas.
O registro do Linux Master Target com CS falha com um erro TLS 35
O registro do Destino Mestre do Azure Site Recovery com o servidor de configuração falha devido ao Proxy Autenticado estar habilitado no Destino Mestre.
Este erro é indicado pelas seguintes cadeias de caracteres no log de instalação:
RegisterHostStaticInfo encountered exception config/talwrapper.cpp(107)[post] CurlWrapper Post failed : server : 10.38.229.221, port : 443, phpUrl : request_handler.php, secure : true, ignoreCurlPartialError : false with error: [at curlwrapperlib/curlwrapper.cpp:processCurlResponse:231] failed to post request: (35) - SSL connect error.
Para resolver o problema:
Na VM do servidor de configuração, abra um prompt de comando e verifique as configurações de proxy usando os seguintes comandos:
cat /etc/ambiente echo $http_proxy echo $https_proxy
Se a saída dos comandos anteriores mostrar que as configurações de http_proxy ou https_proxy estão definidas, use um dos seguintes métodos para desbloquear as comunicações do Master Target com o servidor de configuração:
Faça o download da ferramenta PsExec.
Use a ferramenta para acessar o contexto de usuário do sistema e determinar se o endereço proxy está configurado.
Se o proxy estiver configurado, abra o Internet Explorer em um contexto de usuário do sistema usando a ferramenta PsExec.
psexec -s -i "%programfiles%\Internet Explorer\iexplore.exe"
Para garantir que o servidor de destino mestre possa se comunicar com o servidor de configuração:
- Modifique as configurações de proxy no Internet Explorer para ignorar o endereço IP do servidor de destino mestre por meio do proxy.
Ou - Desative o proxy no servidor Master Target.
- Modifique as configurações de proxy no Internet Explorer para ignorar o endereço IP do servidor de destino mestre por meio do proxy.
Próximos passos
- Solucionar problemas de conexão RDP com VM do Windows
- Solucionar problemas de conexão SSH com VM Linux
Se precisar de mais ajuda, publique sua consulta na página de perguntas e respostas da Microsoft para Recuperação de Site ou deixe um comentário no final deste documento. Temos uma comunidade ativa que deve ser capaz de ajudá-lo.