Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este artigo explica como é possível melhorar o desempenho para os compartilhamentos de ficheiros do sistema de ficheiros de rede (NFS) do Azure.
Aplica-se a
| Modelo de gestão | Modelo de faturação | Nível de média | Redundância | SMB | NFS |
|---|---|---|---|---|---|
| Microsoft.Armazenamento | Provisionado v2 | SSD (de qualidade superior) | Localização (LRS) |
|
|
| Microsoft.Armazenamento | Provisionado v2 | SSD (de qualidade superior) | Zona (ZRS) |
|
|
| Microsoft.Armazenamento | Provisionado v2 | HDD (padrão) | Localização (LRS) |
|
|
| Microsoft.Armazenamento | Provisionado v2 | HDD (padrão) | Zona (ZRS) |
|
|
| Microsoft.Armazenamento | Provisionado v2 | HDD (padrão) | Geo (GRS) |
|
|
| Microsoft.Armazenamento | Provisionado v2 | HDD (padrão) | GeoZona (GZRS) |
|
|
| Microsoft.Armazenamento | Provisionado v1 | SSD (de qualidade superior) | Localização (LRS) |
|
|
| Microsoft.Armazenamento | Provisionado v1 | SSD (de qualidade superior) | Zona (ZRS) |
|
|
| Microsoft.Armazenamento | Pagamento conforme o consumo | HDD (padrão) | Localização (LRS) |
|
|
| Microsoft.Armazenamento | Pagamento conforme o consumo | HDD (padrão) | Zona (ZRS) |
|
|
| Microsoft.Armazenamento | Pagamento conforme o consumo | HDD (padrão) | Geo (GRS) |
|
|
| Microsoft.Armazenamento | Pagamento conforme o consumo | HDD (padrão) | GeoZona (GZRS) |
|
|
Aumente o tamanho da leitura antecipada para melhorar o desempenho de leitura
O read_ahead_kb parâmetro kernel no Linux representa a quantidade de dados que devem ser "lidos antecipadamente" ou pré-buscados durante uma operação de leitura sequencial. As versões do kernel Linux anteriores à 5.4 definem o valor de read-ahead como equivalente a 15 vezes o valor do rsize sistema de arquivos montado, que representa a opção de montagem do lado do cliente para o tamanho do buffer de leitura. Isso define o valor de leitura antecipada alto o suficiente para melhorar o desempenho de leitura sequencial do cliente na maioria dos casos.
No entanto, a partir da versão 5.4 do kernel Linux, o cliente NFS Linux usa um valor padrão read_ahead_kb de 128 KiB. Esse pequeno valor pode reduzir a quantidade de taxa de transferência de leitura para arquivos grandes. Os clientes que atualizam de versões do Linux com o maior valor de leitura antecipada para versões com o padrão de 128 KiB podem experimentar uma diminuição no desempenho de leitura sequencial.
Para kernels Linux 5.4 ou posteriores, recomendamos definir persistentemente read_ahead_kb para 15 MiB para um melhor desempenho.
Para alterar esse valor, defina o tamanho de leitura antecipada adicionando uma regra no udev, um gerenciador de dispositivos do kernel Linux. Siga estes passos:
Em um editor de texto, crie o arquivo /etc/udev/rules.d/99-nfs.rules inserindo e salvando o seguinte texto:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"Em um console, aplique a regra udev executando o comando udevadm como um superusuário e recarregando os arquivos de regras e outros bancos de dados. Você só precisa executar este comando uma vez, para tornar o udev ciente do novo arquivo.
sudo udevadm control --reload
NFS nconnect [en]
O NFS nconnect é uma opção de montagem do lado do cliente para compartilhamentos de arquivos NFS que permite usar várias conexões TCP entre o cliente e seu compartilhamento de arquivos NFS.
Benefícios
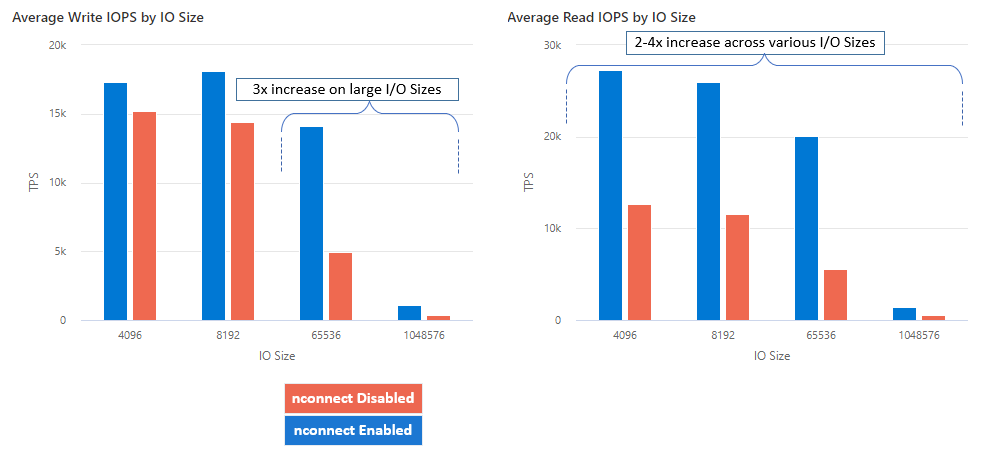
Com o nconnect, você pode aumentar o desempenho em escala usando menos máquinas cliente para reduzir o custo total de propriedade (TCO). O recurso nconnect aumenta o desempenho usando vários canais TCP em uma ou mais NICs, usando um ou vários clientes. Sem o nconnect, você precisaria de cerca de 20 máquinas clientes para atingir os limites de escala de largura de banda (10 GiB / seg) oferecidos pelo maior tamanho de provisionamento de compartilhamento de arquivos SSD. Com o nconnect, você pode atingir esses limites usando apenas 6 a 7 clientes, reduzindo os custos de computação em quase 70% enquanto fornece melhorias significativas nas operações de E/S por segundo (IOPS) e na taxa de transferência em escala. Consulte a seguinte tabela.
| Métrica (operação) | Tamanho de E/S | Melhoria do desempenho |
|---|---|---|
| IOPS (gravação) | 64 KiB, 1.024 KiB | 3x |
| IOPS (ler) | Todos os tamanhos de E/S | 2 a 4 vezes |
| Taxa de transferência (gravação) | 64 KiB, 1.024 KiB | 3x |
| Taxa de processamento (leitura) | Todos os tamanhos de E/S | 2 a 4 vezes |
Pré-requisitos
- As mais recentes distribuições Linux suportam totalmente nconnect. Para distribuições Linux mais antigas, certifique-se de que a versão do kernel Linux é 5.3 ou superior.
- A configuração por montagem só é suportada quando uma única partilha de ficheiros é usada por cada conta de armazenamento num ponto de extremidade privado.
Impacto no desempenho
Obtivemos os seguintes resultados de desempenho ao usar a opção de montagem nconnect com partilhas de ficheiros do Azure NFS em larga escala em clientes Linux. Para obter mais informações sobre como obtivemos esses resultados, consulte Configuração do teste de desempenho.

Recomendações
Siga estas recomendações para obter os melhores resultados do nconnect.
Conjunto nconnect=4
Embora o Azure Files ofereça suporte à configuração de nconnect com um valor máximo permitido de 16, recomendamos configurar as opções de montagem com a configuração ideal de nconnect=4. Atualmente, não há ganhos além de quatro canais para a implementação do nconnect no Azure Files. Na verdade, exceder quatro canais para um único compartilhamento de arquivos do Azure de um único cliente pode afetar negativamente o desempenho devido à saturação da rede TCP.
Dimensione máquinas virtuais com cuidado
Dependendo dos requisitos de carga de trabalho, é importante dimensionar corretamente as máquinas virtuais (VMs) cliente para evitar restrições pela largura de banda de rede esperada. Você não precisa de vários controladores de interface de rede (NICs) para atingir a taxa de transferência de rede esperada. Embora seja comum usar VMs de uso geral com Arquivos do Azure, vários tipos de VM estão disponíveis, dependendo das suas necessidades de carga de trabalho e da disponibilidade da região. Para obter mais informações, consulte Azure VM Seletor.
Manter a profundidade da fila menor ou igual a 64
A profundidade da fila é o número de solicitações de E/S pendentes que um recurso de armazenamento pode atender. Não recomendamos exceder a profundidade de fila ideal de 64 porque você não verá mais ganhos de desempenho. Para obter mais informações, consulte Profundidade da fila.
Por configuração de montagem
Se uma carga de trabalho exigir montar vários compartilhamentos com uma ou mais contas de armazenamento e com diferentes configurações de nconnect a partir de um único cliente, não podemos garantir que essas configurações persistam quando montadas através do ponto de extremidade público. A configuração por montagem só é suportada quando um único compartilhamento de arquivos do Azure é usado por conta de armazenamento no ponto de extremidade privado, conforme descrito no Cenário 1.
Cenário 1: configuração de montagem por ponto de extremidade privado com várias contas de armazenamento (suportado)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Cenário 2: por configuração de montagem sobre ponto de extremidade público (não suportado)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Nota
Mesmo que a conta de armazenamento seja resolvida para um endereço IP diferente, não podemos garantir que esse endereço persista porque os pontos de extremidade públicos não são endereços estáticos.
Cenário 3: configuração por montagem em cada ponto de extremidade privado com várias partilhas numa única conta de armazenamento (não suportado)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Configuração de teste de desempenho
Utilizamos os seguintes recursos e ferramentas de benchmarking para alcançar e medir os resultados descritos neste artigo.
- Cliente único: VM do Azure (DSv4-Series) com NIC única
- SO: Linux (Ubuntu 20.40)
-
Armazenamento NFS: Partilha de ficheiros SSD (atribuído 30 TiB, configuração
nconnect=4)
| Tamanho | vCPU | Memória | Armazenamento temporário (SSD) | Máximo de discos de dados | Máximo de NICs | Largura de banda da rede esperada |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Apenas armazenamento remoto | 32 | 8 | 12.500 Mbps |
Ferramentas e testes de avaliação comparativa
Usamos o Flexible I/O Tester (FIO), uma ferramenta de E/S de disco gratuita e de código aberto usada tanto para benchmark quanto para verificação de estresse/hardware. Para instalar o FIO, siga a seção Pacotes binários no arquivo FIO README para instalar na plataforma de sua escolha.
Embora esses testes se concentrem em padrões de acesso de E/S aleatórios, você obtém resultados semelhantes ao usar E/S sequencial.
IOPS alto: 100% de leituras
Tamanho de E/S 4k - leitura aleatória - profundidade da fila 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Tamanho de E/S de 8k - leitura aleatória - profundidade de fila de 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Alta capacidade: 100% leitura
Tamanho de E/S de 64 KiB - leitura aleatória - profundidade da fila de 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Tamanho de E/S de 1,024 KiB - 100% leitura aleatória - profundidade da fila 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Elevado IOPS: 100% de gravações
Tamanho de E/S de 4 KiB - 100% escrita aleatória - 64 profundidade da fila
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Tamanho de entrada/saída de 8 KiB - 100% escrita aleatória - profundidade de fila de 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Alta taxa de transferência: 100% escritas
Tamanho de E/S de 64 KiB - escrita aleatória% 100 - profundidade de fila de 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Tamanho de E/S de 1024 KiB - 100% escrita aleatória - profundidade de fila 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Considerações de desempenho para nconnect
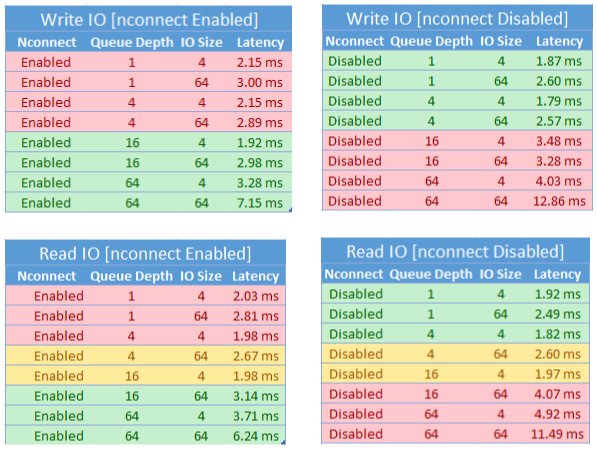
Ao usar a nconnect opção de montagem, você deve avaliar de perto as cargas de trabalho que têm as seguintes características:
- Cargas de trabalho de gravação sensíveis à latência que são monothread e/ou usam uma profundidade de fila baixa (inferior a 16)
- Cargas de trabalho de leitura sensíveis à latência que são de thread único e/ou usam uma profundidade de fila baixa em combinação com tamanhos de E/S menores
Nem todas as cargas de trabalho exigem IOPS de alta escala ou durante todo o desempenho. Para cargas de trabalho de menor escala, nconnect pode não fazer sentido. Use a tabela a seguir para decidir se nconnect é vantajoso para sua carga de trabalho. Cenários realçados em verde são recomendados, enquanto cenários realçados em vermelho não são. Os cenários destacados a amarelo são neutros.