Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Neste Guia de início rápido, você criará um espaço de trabalho Synapse e poderá acompanhar o restante dos tutoriais para criar um pool SQL dedicado e um pool Apache Spark sem servidor.
Pré-requisitos
- Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
- Para concluir as etapas deste tutorial, você precisa ter acesso a um grupo de recursos para o qual foi atribuída a função de Proprietário . Crie o espaço de trabalho Sinapse neste grupo de recursos.
Criar um espaço de trabalho Synapse no portal do Azure
Iniciar o processo
- Abra o portal do Azure, na barra de pesquisa digite Synapse sem pressionar enter.
- Nos resultados da pesquisa, em Serviços, selecione Azure Synapse Analytics.
- Selecione Criar para criar um espaço de trabalho.
Guia > Noções básicas Detalhes do projeto
Preencha os seguintes campos:
- Subscrição - Escolha qualquer subscrição.
- Grupo de recursos - Use qualquer grupo de recursos.
- Grupo de Recursos Gerenciados - Deixe isso em branco.
Guia > Noções básicas Detalhes do espaço de trabalho
Preencha os seguintes campos:
- Nome do espaço de trabalho - Escolha qualquer nome exclusivo globalmente. Neste tutorial, usaremos myworkspace.
- Região - Escolha a região onde você colocou seus aplicativos/serviços cliente (por exemplo, Máquina Virtual do Azure, Power BI, Azure Analysis Service) e armazenamentos que contêm dados (por exemplo, armazenamento do Azure Data Lake, armazenamento analítico do Azure Cosmos DB).
Nota
Um espaço de trabalho que não está co-localizado com as aplicações cliente ou o armazenamento pode ser a causa raiz de muitos problemas de desempenho. Se seus dados ou os clientes forem colocados em várias regiões, você poderá criar espaços de trabalho separados em diferentes regiões colocalizadas com seus dados e clientes.
Em Selecionar Data Lake Storage Gen 2:
Por Nome da conta, selecione Criar novo e nomeie a nova conta de armazenamento contosolake ou similar, pois o nome deve ser exclusivo.
Tip
Se você receber um erro lendo "O provedor de recursos do Azure Synapse (Microsoft.Synapse) precisa ser registrado com a assinatura selecionada", abra o portal do Azure e selecione Assinaturas. Selecione a sua subscrição. Na lista Configurações, selecione Provedores de recursos. Procure Microsoft.Synapse, selecione-o e selecione Registrar.
Por Nome do sistema de arquivos, selecione Criar novo e nomeie os usuários. Isso criará um contêiner de armazenamento chamado usuários. O espaço de trabalho usará essa conta de armazenamento como a conta de armazenamento "principal" para tabelas do Spark e logs de aplicativos do Spark.
Marque a caixa Atribuir a mim mesmo a função de Colaborador de Dados de Blobs de Armazenamento na conta do Data Lake Storage Gen2.
Conclusão do processo
Selecione Revisar e criar>Criar. Seu espaço de trabalho fica pronto em poucos minutos.
Nota
Para habilitar recursos de espaço de trabalho de um pool SQL dedicado existente (anteriormente SQL DW), consulte Como habilitar um espaço de trabalho para seu pool SQL dedicado (anteriormente SQL DW).
Abra o Synapse Studio
Depois que seu espaço de trabalho do Azure Synapse for criado, você terá duas maneiras de abrir o Synapse Studio:
Abra seu espaço de trabalho Synapse no portal do Azure, na seção Visão geral do espaço de trabalho Synapse, selecione Abrir na caixa Abrir Synapse Studio.
Aceda ao
https://web.azuresynapse.nete inicie sessão no seu espaço de trabalho.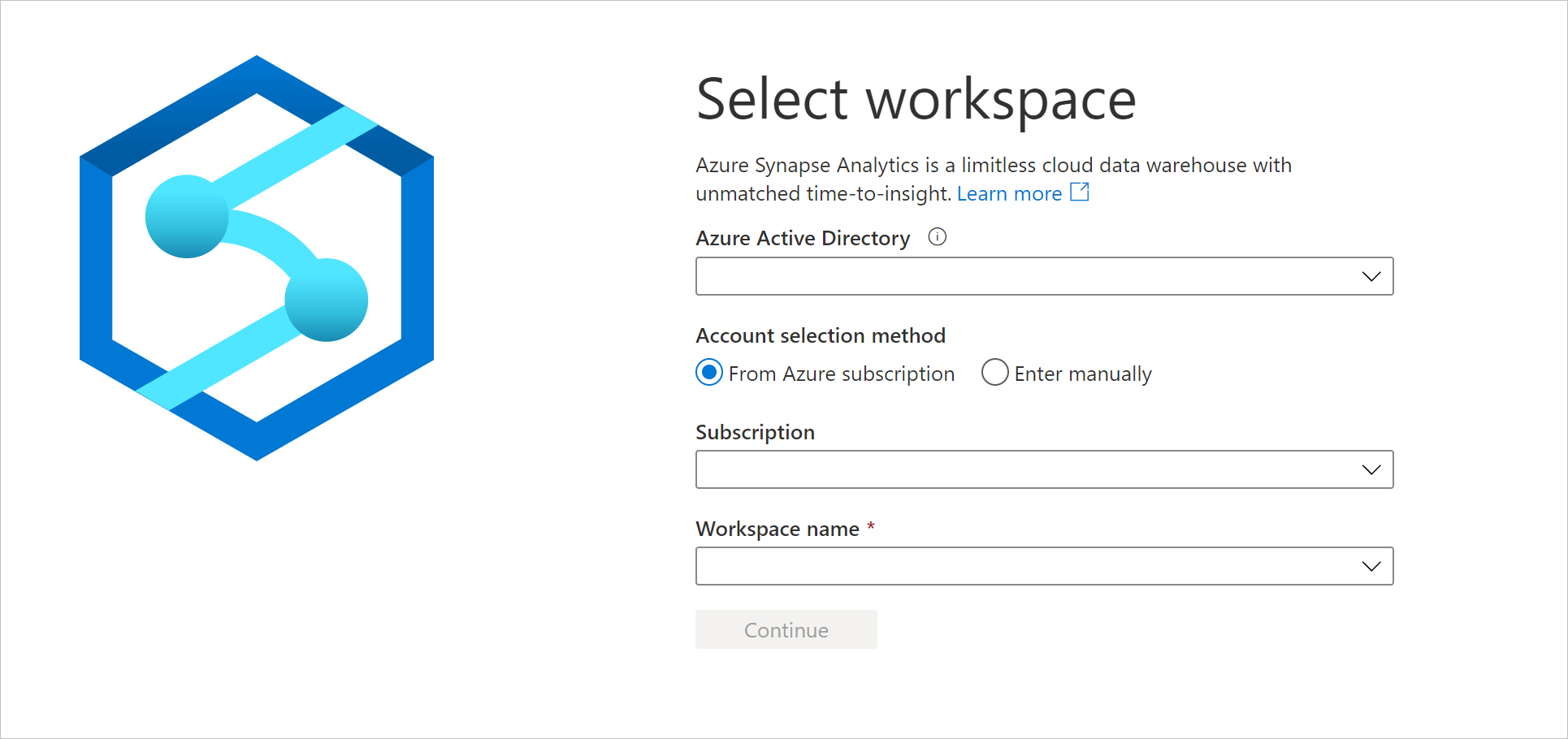
Nota
Para entrar em seu espaço de trabalho, há dois métodos de seleção de conta. Um é da assinatura do Azure, o outro é de Introduzir manualmente. Se você tiver a função Synapse Azure ou funções do Azure de nível superior, poderá usar ambos os métodos para fazer logon no espaço de trabalho. Se não tiver as funções relacionadas do Azure e lhe tiver sido atribuída a função Synapse RBAC, Introduzir manualmente será a única maneira de iniciar sessão na área de trabalho. Para saber mais sobre o Synapse RBAC, consulte O que é o RBAC (controle de acesso baseado em função) do Synapse.
Coloque dados de amostra na conta de armazenamento principal
Vamos usar um pequeno conjunto de dados de amostra de 100 mil linhas de dados do NYC Taxi Cab para muitos exemplos neste guia de introdução. Começamos colocando-o na conta de armazenamento principal que você criou para o espaço de trabalho.
- Faça o download do NYC Taxi - green trip dataset para o seu computador.
- Navegue até a localização original do conjunto de dados através do link, escolha um ano específico e faça o download dos registos de viagem de táxi verde no formato Parquet.
- Renomeie o arquivo baixado para NYCTripSmall.parquet.
- No Synapse Studio, navegue até o hub de Dados.
- Selecione Vinculado.
- Na categoria Azure Data Lake Storage Gen2, você verá um item com um nome como myworkspace ( Primary - contosolake ).
- Selecione o contêiner chamado usuários (Principal).
- Selecione Carregar e selecione o
NYCTripSmall.parquetarquivo que você baixou.
Uma vez que o arquivo parquet é carregado, ele está disponível através de dois URIs equivalentes:
https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquetabfss://users@contosolake.dfs.core.windows.net/NYCTripSmall.parquet
Tip
Nos exemplos a seguir neste tutorial, certifique-se de substituir contosolake na interface do usuário pelo nome da conta de armazenamento principal que você selecionou para seu espaço de trabalho.