Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O Azure Vision no Foundry Tools é uma ferramenta Microsoft Foundry que lhe permite processar imagens e devolver informações com base nas características visuais. Neste tutorial, vais aprender a usar o Vision para analisar imagens no Azure Synapse Analytics.
Este tutorial demonstra o uso da análise de texto com SynapseML para:
- Extrair recursos visuais do conteúdo da imagem
- Reconhecer caracteres de imagens (OCR)
- Analise o conteúdo da imagem e gere miniaturas
- Detetar e identificar conteúdo específico do domínio em uma imagem
- Gerar tags relacionadas a uma imagem
- Gerar uma descrição de uma imagem inteira em linguagem legível por humanos
Analisar imagem
Extrai um rico conjunto de recursos visuais com base no conteúdo da imagem, como objetos, rostos, conteúdo adulto e descrições de texto geradas automaticamente.
Exemplo de entrada

# Create a dataframe with the image URLs
df = spark.createDataFrame([
("<replace with your file path>/dog.jpg", )
], ["image", ])
# Run the Vision service. Analyze Image extracts information from/about the images.
analysis = (AnalyzeImage()
.setLinkedService(ai_service_name)
.setVisualFeatures(["Categories","Color","Description","Faces","Objects","Tags"])
.setOutputCol("analysis_results")
.setImageUrlCol("image")
.setErrorCol("error"))
# Show the results of what you wanted to pull out of the images.
display(analysis.transform(df).select("image", "analysis_results.description.tags"))
Resultados esperados
["dog","outdoor","fence","wooden","small","brown","building","sitting","front","bench","standing","table","walking","board","beach","holding","bridge"]
Reconhecimento ótico de carateres (OCR)
Extraia texto impresso, texto manuscrito, dígitos e símbolos de moeda de imagens, como fotos de placas de rua e produtos, bem como de documentos — faturas, contas, relatórios financeiros, artigos e muito mais. É otimizado para extrair texto de imagens com grande quantidade de texto e documentos PDF de múltiplas páginas com línguas mistas. Ele suporta a deteção de texto impresso e manuscrito na mesma imagem ou documento.
Exemplo de entrada

df = spark.createDataFrame([
("<replace with your file path>/ocr.jpg", )
], ["url", ])
ri = (ReadImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("ocr"))
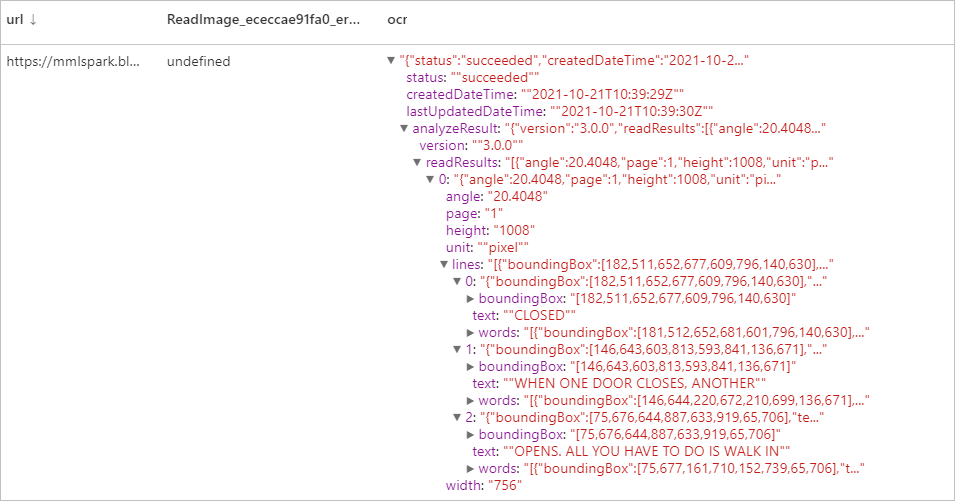
display(ri.transform(df))
Resultados esperados
Gerar miniaturas
Analise o conteúdo de uma imagem para gerar uma miniatura adequada dessa imagem. O serviço Visão primeiro gera uma miniatura de alta qualidade e, em seguida, analisa os objetos dentro da imagem para determinar a área de interesse. Em seguida, o sistema recorta a imagem para se adequar aos requisitos da área de interesse. A miniatura gerada pode ser apresentada com uma proporção diferente da proporção da imagem original, consoante as suas necessidades.
Exemplo de entrada

df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
gt = (GenerateThumbnails()
.setLinkedService(ai_service_name)
.setHeight(50)
.setWidth(50)
.setSmartCropping(True)
.setImageUrlCol("url")
.setOutputCol("thumbnails"))
thumbnails = gt.transform(df).select("thumbnails").toJSON().first()
import json
img = json.loads(thumbnails)["thumbnails"]
displayHTML("<img src='data:image/jpeg;base64," + img + "'>")
Resultados esperados

Etiquetar imagem
Gera uma lista de palavras, ou tags, que são relevantes para o conteúdo da imagem fornecida. As tags são retornadas com base em milhares de objetos reconhecíveis, seres vivos, cenários ou ações encontradas em imagens. As tags podem conter dicas para evitar ambiguidade ou fornecer contexto, por exemplo, a tag "ascomicete" pode ser acompanhada pela dica "fungo".
Vamos continuar usando a imagem de Satya como exemplo.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
ti = (TagImage()
.setLinkedService(ai_service_name)
.setImageUrlCol("url")
.setOutputCol("tags"))
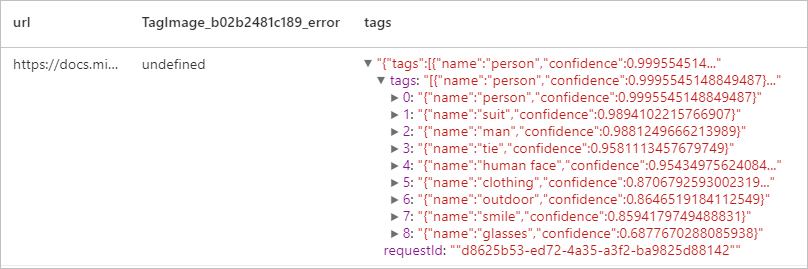
display(ti.transform(df))
Resultado esperado
Descrever imagem
Gere uma descrição de uma imagem inteira numa linguagem legível por humanos, com frases completas. Os algoritmos do serviço Visão geram várias descrições com base nos objetos identificados na imagem. Cada uma das descrições é avaliada e é gerada uma pontuação de confiança. Em seguida, é devolvida uma lista ordenada da pontuação de confiança mais alta para a mais baixa.
Vamos continuar usando a imagem de Satya como exemplo.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
di = (DescribeImage()
.setLinkedService(ai_service_name)
.setMaxCandidates(3)
.setImageUrlCol("url")
.setOutputCol("descriptions"))
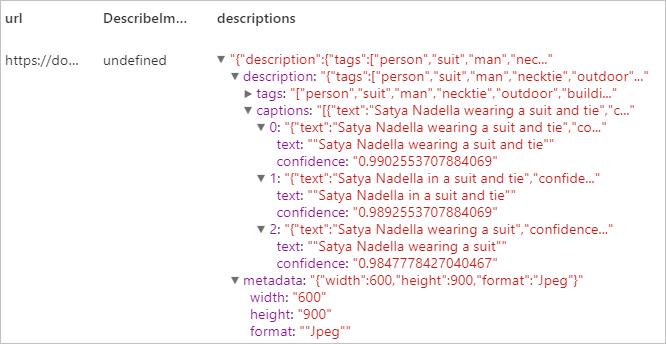
display(di.transform(df))
Resultado esperado
Reconhecer conteúdo específico do domínio
Utilize modelos de domínio para detetar e identificar conteúdo específico de um domínio numa imagem, como celebridades e marcos de referência. Por exemplo, se uma imagem contiver pessoas, a Visão pode usar um modelo de domínio para celebridades para determinar se as pessoas detetadas na imagem são celebridades conhecidas.
Vamos continuar usando a imagem de Satya como exemplo.
df = spark.createDataFrame([
("<replace with your file path>/satya.jpeg", )
], ["url", ])
celeb = (RecognizeDomainSpecificContent()
.setLinkedService(ai_service_name)
.setModel("celebrities")
.setImageUrlCol("url")
.setOutputCol("celebs"))
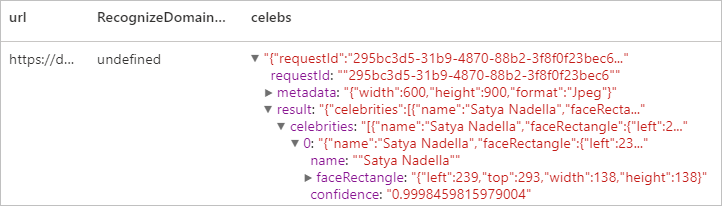
display(celeb.transform(df))
Resultado esperado
Limpar recursos
Para garantir que a instância do Spark seja desligada, encerre todas as sessões conectadas (blocos de anotações). O pool é desligado quando o tempo de inatividade especificado no pool do Apache Spark é atingido. Também pode selecionar Parar sessão na barra de estado no canto superior direito do bloco de notas.
